【初识Redis】
1. 前言
1.1 Reis是什么
Redis 是 C 语言开发的一个开源的(遵从 BSD 协议)高性能键值对(key-value)的 NoSQL的内存数据库,可以用作缓存、消息中间件等;具有以下特点:
1. 性能优秀,数据在内存中,读写速度非常快,支持并发 10W QPS;
2. 单进程单线程,是线程安全的,采用 IO 多路复用机制;
3. 丰富的数据类型,支持字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)等;
4. 支持数据持久化。可以将内存中数据保存在磁盘中,重启时加载;
5. 主从复制,哨兵,高可用;
可以用作分布式锁。可以作为消息中间件使用,支持发布订阅;
1.2 Redis支持的功能
1. 缓存: 提升数据的访问性能
2. 可用作低配版的消息中间件,支持发布订阅
3. 可用做分布式锁
4. 可以实现session共享
1.3 与memoryCache对比
| 对比内容 |
Redis |
memoryCache |
| 存储方式 | Redis 支持持久化 | Memcache不支持持久化,会把数据全部存在内存,很难解决缓存雪崩的问题 |
| 数据类型 | Redis 支持五种数据类型 | Memcache 对数据类型的支持简单,只支持简单的 key-value |
| 底层模型 |
Redis 直接自己构建了 VM 机制 因为一般的系统调用系统函数的话 会浪费一定的时间去移动和请求 |
调用系统 |
| Value大小 | Redis 可以达到 1GB | Memcache 只有 1MB |
2. Redis内存管理
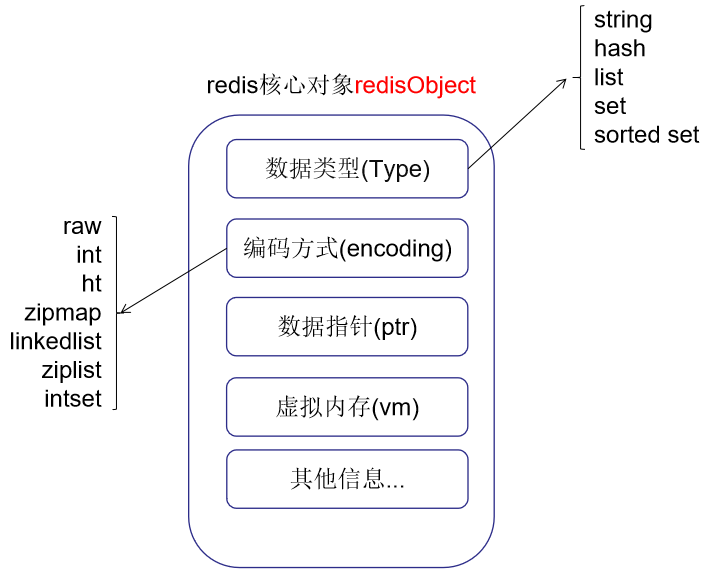
2.1 redisObject
Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持
这样设计的好处:可以针对不同场景,对5种常用的数据类型设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率;
type: 代表一个 value 对象具体是何种数据类型。
encoding: 不同数据类型在 redis 内部的存储方式。
比如:type=string 代表 value 存储的是一个普通字符串,那么对应的 encoding 可以是 raw 或者是 int。
如果是 int 则代表实际 redis 内部是按数值型类存储和表示这个字符串的。
当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
vm字段: 只有打开了 Redis 的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。
Redis 使用 redisObject 来表示所有的 key/value 数据是比较浪费内存的
当然这些内存管理成本的付出主要也是为了给 Redis 不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用。
2.2 基础命令
服务端启动:redis-server redis.config
客户端启动: redis-cli -p [服务器端口] -h [服务端ip]
1. 查看所有的key:keys *
2. 设置过期时间:set username nick EX 10 // ttl username 查看key剩余时间

3. 选择库:select 1 // redis有16个库0~15,可以选择不同的库存储数据,redis集群默认用0号库
4. 判断key是否存在:exits username
5. 删除key:del username
6. 查看key类型: type username
7. 数据持久化: save //保存在dump.rdb文件
8. 清空redis所有数据:flushall //flushdb为清空分库的数据,不删除dump.rdb
9. 单节点批量操作:mset/mget //mset username nick mset address dg
10. 冷点数据设置超时清除:expire username 100 // expire为秒维度,pexpire为毫秒维度
11. 追加数据:如果 key 已经存在并且是一个字符串,append key value
2.3 五种数据类型
2.3.1 String

String类型的数据结构,是key-value形式,value为字符串/json串
1. 增(原生redis命令):set user1 {name:nick, age:15, gender:male}
2. 查(原生redis命令):get user1
3. 改(原生redis命令):set user1 {name:nick, age:, gender:male}
4. 删(原生redis命令):del user1
5. 记步器:incrby/decrby key //对value进行自增/自减,例如统计在线人数;
2.3.2 Hash
Hash类型的数据结构是key-value形式,每一条value有是key-value形式

1. 增(原生redis命令):
hset user1 name nick age 10 gender male //name age gender单条添加
hmset user1 name nick age 10 gender male //3个属性批量添加
hincrby user1 age //age自增
2. 查(原生redis命令):
hget user1 name //获取key为user1指向的name这个key指向的数据
hmget user1 name age gender //批量获取数据
hgetall user1 // 获取key为user1指向的所有数据
hkeys user1 // 获取key为user1指向的所有的hkey字段
hlen user1 //获取key为user1指向的数据的个数
3. 改(原生redis命令):hset user1 name nick1
4. 删(原生redis命令):hdel user1 name
2.3.3 List
List类型字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)
1. 增(原生redis命令):
LPUSH key value [value ...] // lpush nameList jack // 从左侧push
LINSERT key BEFORE|AFTER pivot value // linsert nameList before jerry tom//从左边,在jerty前面插入tom
LTRIM key begin end // 保留链表范围内的数据元素
rpoplpush key1 key2 // 原子级操作,两个链表数据交互,从key1删除,key2备份
2. 查(原生redis命令):
LPOP key // lpop key 从链表中获取数据
LRANGE key start stop // lrange nameList 0 -1 查看nameList中所有元素的个数
3. 改(原生redis命令):LSET key index value // lset nameList 1 nick2,修改nick->nick2
4. 删(原生redis命令):LREM key count value // lrem key count value 删除count个 数据为value的元素 count取0时,全部删除value
2.3.4 Set
Set集合用来保存多个字符串元素,和list不用的是不允许有重复元素,并且无序
应用场景:用户的兴趣、爱好、关注人列表、粉丝列表等
1. 增(原生redis命令):
SADD key member [member ...] // sadd nameList jack nick tom jerry
2. 查(原生redis命令):
SRANDMEMBER key // srandmember nameList 随机获取一条数据,
SMEMBERS key // smembers nameList 查看nameList key的所有数据
3. 删(原生redis命令):
SREM key member // srem nameList nick
4. 判断元素是否在集合中:
SISMEMBER key member // sismember nameList jack
5. 不同集合间的交、并、差集
SINTER key [key ...] // sinter nameList nameList2
SUINON key [key ...] // sinter nameList nameList2
SDIFF key [key ...] // sinter nameList nameList2 以第一个key为主
2.3.5 ZSet
ZSet在Set集合的基础之上绑定了一个score作为排序的依据
1. 增(原生redis命令):
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
zadd result 100 jack //100为score
ZINCRBY key increment member // zincrby result 50 jack 增加jack成员的分数
2. 查(原生redis命令):
ZCARD key // 查看key里面数据的个数
ZSCORE key member // zscore result jack 查看成员的score
ZRANGE key start stop [WITHSCORES] // zrange result 0 -1 查看排名
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] //根据score筛选
ZRANK key member //计算成员的score排名
3. 删(原生redis命令):
ZREM key member [member ...] // zrem result jack 删除某个成员
ZREMRANGEBYRANK key start stop // 删除指定排名内的升序元素
ZREMRANGEBYSCORE key min max // 删除score在[min, max]范围的元素
4. 不同集合间的交、并、差集
ZINTERSTORE destination numkeys key [key ...] // zinterstore out 2 result result1,destination表示输出的ZSet 交集的score相加
3. Jedis客户端
3.1 redis配置文件
1. bind 127.0.0.1 ###指定redis只接收来自该IP地址的请求,如果不进行设置,将处理所有请求
2. protected-mode yes ###是否开启保护模式,默认开启;如果关闭,外部网络可以直接访问;如果开启,则需要bind ip或者设置访问密码(安全考虑)
3. port 6379 ###redis监听的端口
4. tcp-backlog 511 ###默认511,此参数标识确定了TCP连接中已完成队列(完成三次握手之后)的长度,可以理解为进程还没有accept的TCP连接的队列,tcp-backlog必须小于等于Linux系统定义的/proc/sys/net/somaxconn值
Linux的somaxconn默认为128,当系统并发量大,并且客户端速度缓慢的时候,可以将这两个参数一起参考设置,建议修改为2048,在/etc/sysctl.conf中添加 net.core.somaxconn=2048,然后终端执行sysctl -p命令生效
5. timeout 0 ###设置客户端空闲超过timeout时,redis服务端会断开连接,为0时表示服务端不会主动断开连接,此值不能小于0
6. tcp-keepalive 300 ###redis3.2以后默认为300秒,配置上这个参数之后,对于一些没有正常关闭的客户端,也可以及时关闭,连接超时受tcp-keepalive和另外三个参数影响:
tcp_keepalive_time default 7200 seconds
tcp_keepalive_probes default 9
tcp_keepalive_intvl default 75 seconds
连接超时公式为:tcp_keepalive_time+tcp_keepalive_intvl*tcp_keepalive_probes=7895s=131.58min7. daemonize yes
8. pidfile /var/run/redis/redis.pid ####redis的进程文件
9. loglevel notice ###服务端日志级别,包括debug(很多信息,方便开发、测试),verbose(许多有用的信息,但是没有debug级别信息多),notice(适当的日志级别,适合生产环境),warn(只有非常重要的信息)
3.2. redis客户端、服务端启动
基于上述配置文件的修改项:bind、port
1. 启动redis服务端
redis-server redis.config
2. 启动客户端
redis-cli redis-cli -h [host_ip] -p [port]
3. 停止redis服务端
登录客户端执行:redis-cli -h [host_ip] -p [port] shutdown
3.3 Jedis代码实践
3.3.1 Jedis连接池连接
1. 添加maven依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
</dependencies>
2. application.properties配置
spring.redis.sharedpool.nodes=192.168.75.*:6739,192.168.75.*:6780,192.168.75.*:6381
spring.redis.sharedpool.maxTotal=200
spring.redis.sharedpool.maxIdle=10
spring.redis.sharedpool.minIdle=2
3. springboot管理redis连接池
@Configuration
@ConfigurationProperties("spring.redis.sharedpool")
@Setter
@Getter
public class SharedJedisConfigPool { private List<String> nodes; //[192.168.75.132:6739,192.168.75.132:6780,192.168.75.132:6381]
private Integer maxTotal;
private Integer maxIdle;
private Integer minIdle; @Bean
public ShardedJedisPool sharedPoolInit() {
List<JedisShardInfo> infoList = new ArrayList<>();
for (String node : nodes) {
String ip = node.split(":")[0];
int port = Integer.parseInt(node.split(":")[1]);
infoList.add(new JedisShardInfo(ip, port));
}
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxTotal(maxTotal);
config.setMaxIdle(maxIdle);
config.setMinIdle(minIdle);
return new ShardedJedisPool(config, infoList);
}
}
4. 连接池测试
class DemoApplicationTests {
@Autowired
private ShardedJedisPool pool;
@Test
public void func4() {
ShardedJedis jedis = pool.getResource();
jedis.set("user", "nick");
}
}
3.3.2 redis缓存逻辑
class DemoApplicationTests {
@Autowired
private ShardedJedisPool pool;
@Test
public void func1() {
String key = "04f2c34c";
ShardedJedis jedis = pool.getResource();
if (jedis.exists(key)) { //redis缓存有数据
String value = jedis.get(key);
} else {
String key2 = "04f2c34c";//查询数据库
jedis.set(key2, "nick");
}
}
}
3.3.3 SharedJedis分片对象
1. 旧版redis中通常使用客户端分片来解决水平扩容问题,即启动多个redis服务端,客户端决定key交由哪个节点存储,下次客户端直接到该节点读取key
2. 可以实现将整个数据分布存储在N个数据库节点中,每个节点只存放总数据量的1/N。
3. 对于需要扩容的场景来说,在客户端分片后,如果想增加节点,需要对数据进行手工迁移,在迁移时为了保证数据一致性,需要将集群暂时下线,相对比较复杂
自定义简单版分片规则如下:
n个redis服务端几乎均匀存储,hash取余,散列,只要有散列就会有数据倾斜
key.hashCode()结果可正可负
key.hashCode()&Integer.MAX_VALUE结果一定为正数,key和结果唯一对应
key.hashCode()&Integer.MAX_VALUE%n
4. 分片计算
4.1 自定义分片
如3.3.3小节讨论,在使用redis集群时,可以通过自定义的简单版的hash散列方式分片,但是有以下两个缺点,因此引出hash一致性算法
1. 数据倾斜不可避免,只要有hash散列,就一定会有数据倾斜,不可能完全均匀;
2. 扩容、缩容时,数据迁移量巨大★
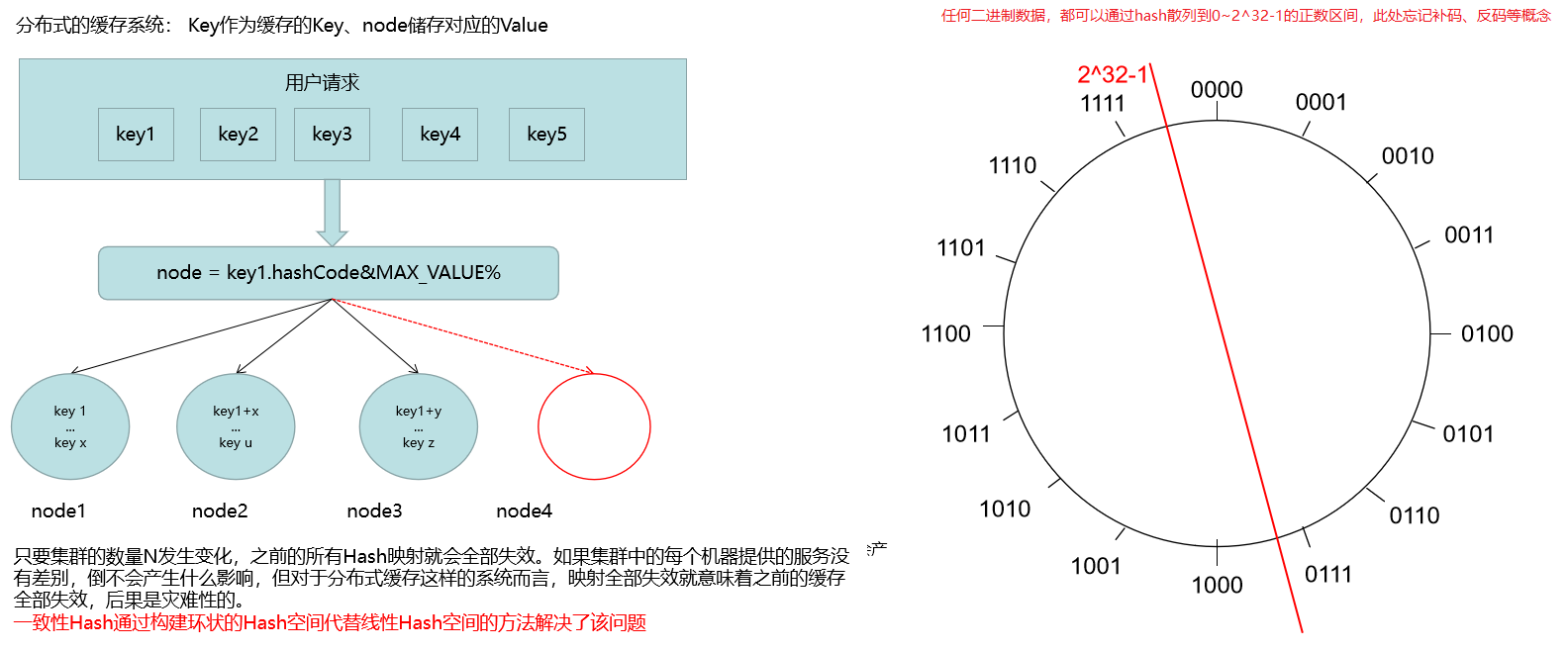
4.2 hash一致性
SharedJedis实现了分片底层的算法——hash一致性(解决了取余算法再扩缩容时,数据迁移量过大的问题);为什么?redis的hash逻辑为:将所有节点信息hash散列到0~2^32-1区间

4.2 hash一致性问题
引入问题:
1. 数据倾斜:
如果节点的数量很少,而hash环空间很大( 0 ~ 2^32),直接进行一致性hash会导致节点在环上的位置会很不均匀,挤在某个很小的区域。最终对分布式集群的每个实例上储存的缓存数据量不一致,会发生严重的数据倾斜;
2. 缓存雪崩
如果每个节点在环上只有一个节点,那么可以想象,当某一集群从环中消失时,它原本所负责的任务将全部交由顺时针方向的下一个集群处理。
例如当6379退出时,它原本所负责的缓存将全部交给6380处理。这就意味着6380的访问压力会瞬间增大。如果6380因为压力过大而崩溃,那么更大的压力又会向6381压过去,最终服务压力就像滚雪球一样越滚越大,最终导致雪崩
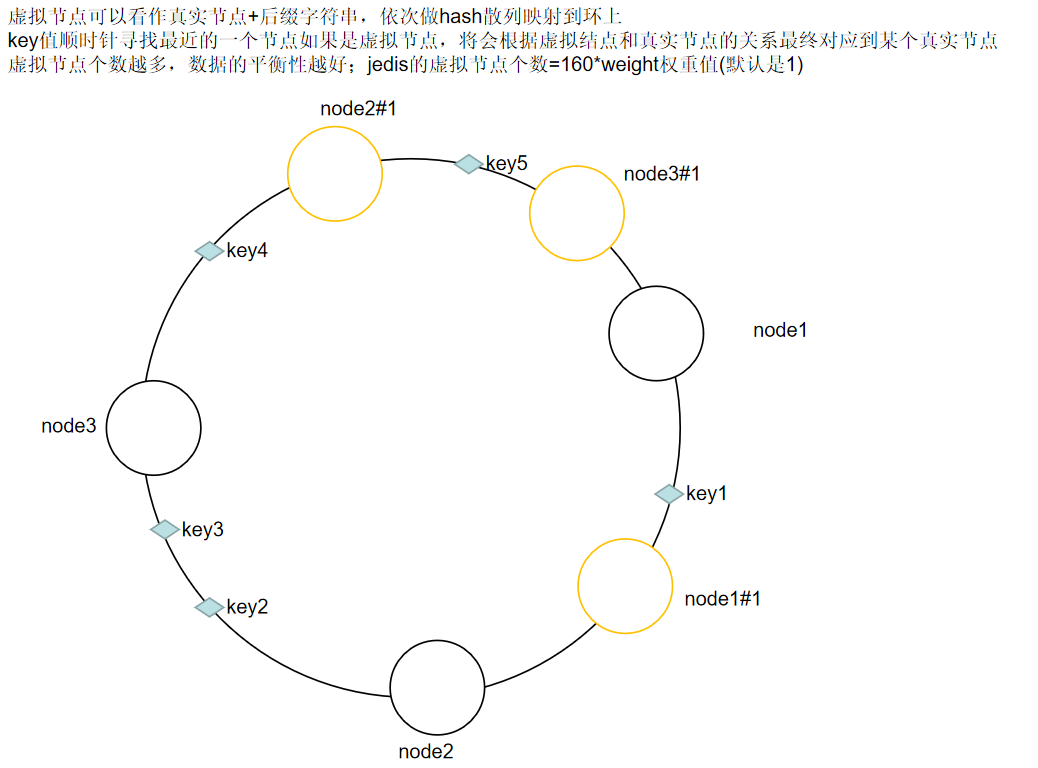
引入虚拟节点
解决上述两个问题最好的办法就是扩展整个环上的节点数量,因此我们引入了虚拟节点的概念。一个实际节点将会映射多个虚拟节点,多次hash,这样Hash环上的空间分割就会变得均匀。
5. 高可用
5.1 主从复制
在同一台虚拟机上构建1主3从的主从模式,一个主节点一般最多6个从节点;
0. 主节点redis配置文件bind要绑定0.0.0.0表示所有连接都可以访问,没有绑定的话,不可以访问主;
1. 创建从节点redis启动配置文件,redis02.config、redis03.config,并修改端口为6380、6381
2. 启动3个redis-server实例 redis-server redis.config、redis-server redis02.config、redis-server redis03.config
3. 主从关系创建,规定6379节点master、6380节点作为slave 、6381节点作为slave;
4. 登录查看节点状态的命令,以客户端登录6379节点为例:6379> info replication
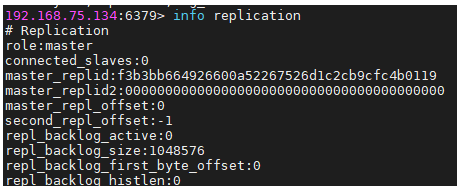
4. 通过配置文件定义主从关系

5. 通过命令挂在主节点,命令如下:从节点> slaveof masterip masterport
6. 本处通过命令方式指定主从关系,客户端登录6080、6081服务端,执行第五步命令

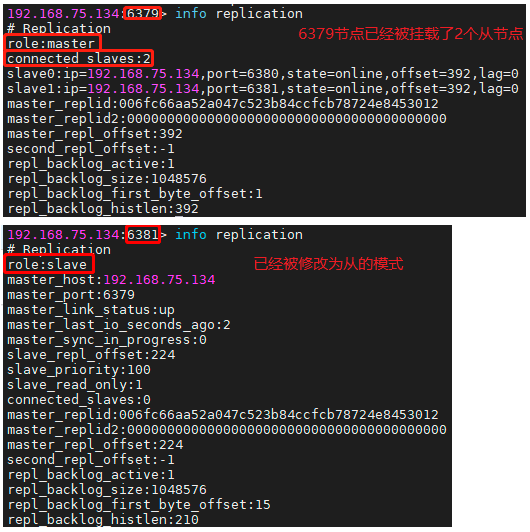
7. 查看6379、6381、6382节点的replicatinon信息,
5.1.1 主从关系测试
测试过程:
主节点6379写数据,从节点6380读数据
1. 登录主节点客户端 set name nick
2. 登录从节点客户端 get name
3. 登录从节点 flushal 执行失败
4. 主节点shutdown
测试结果:
★从节点配置默认为只读模式read-only,主节点宕机,从节点不会自动变为主节点,从节点info replication状态变为如下:
master_link_status:down
master_last_io_seconds_ago:-1
5.2 哨兵模式
5.2.1 什么是哨兵
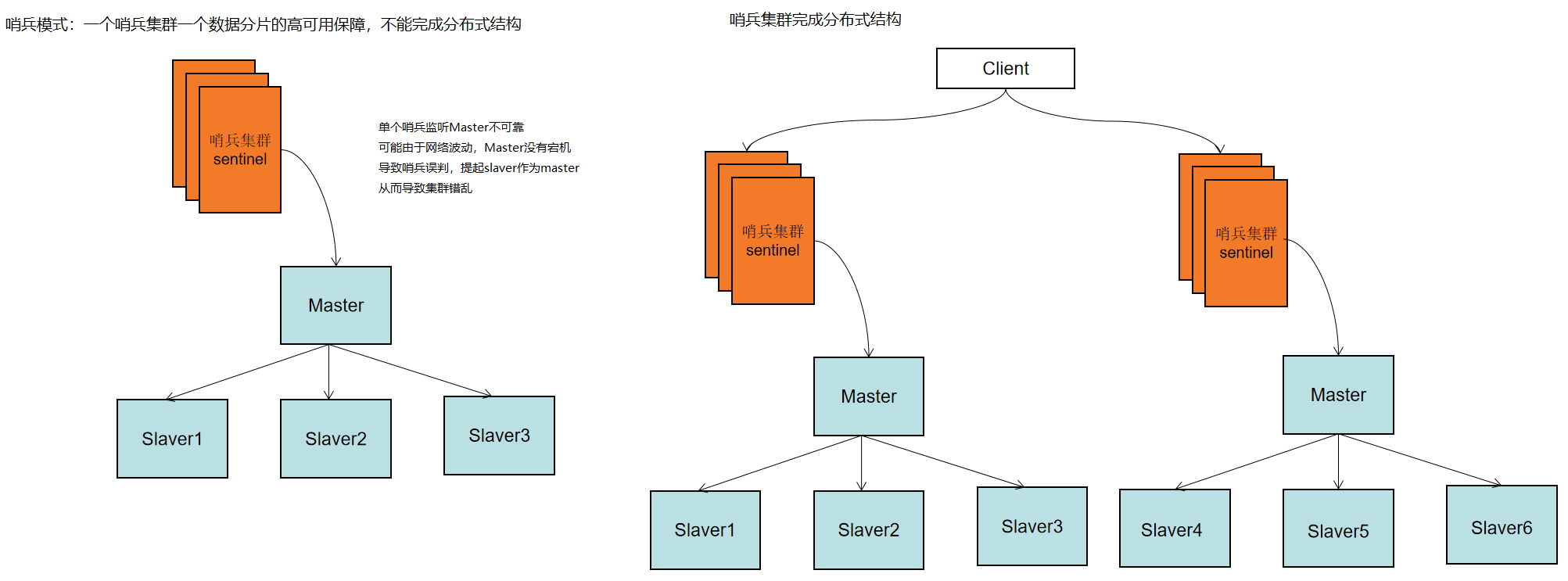
redis-cluster(redis 3.0)出现之前,redis的使用几乎都是围绕哨兵模式展开,哨兵过程如下:
1. 起单独线程(特殊的redis-cluster)开启对主从结构的监听
2. 监听主,从主节点调用命令info replication,获取主从结构的所有信息,保存在内存,每1秒钟发起一次心跳检测(RPC远程通信协议),一旦主节点宕机,哨兵集群发起投票选举,过半票数确定结果,增加可信;
3. 哨兵容忍度:允许宕机的个数是哨兵的容忍度,为了保障多票选取,5个哨兵集群节点的容忍度为2,6个哨兵集群的容忍度为2;2n-1个集群和2n个集群的容忍度是一样的,因此哨兵集群都是奇数个(少用一个资源)
5.2.2 搭建哨兵集群
模式:3个哨兵节点,管理6379,6380,6382主从结构,过程如下:
1. 修改哨兵的模板配置文件(sentinel.conf),配置3个哨兵端口:26379,26380,26381
2. 释放保护模式注释,修改为no
3. 修改监听主节点的配置核心内容:sentine monitor mymaster [master_ip] [master_port] [num]
3..1 mymaster是自定义名称 标识当前哨兵监听的主从结构的代号,多个哨兵监听同一个主从结构的话,此处要保持一致
3.2 num表示为主观下限票数,当哨兵集群不断宕机时,最少要剩下的节点数量,和宕机容忍度有关
4. 拷贝三份,分别做如上修改
5. 启动哨兵(启动之前确定主从集群正常):redis-sentinel sentine.conf
6. 哨兵没有restart等操作
7. kill掉主节点,查看哨兵日志
8. 哨兵发现主节点宕机,开始投票,查看日志num,确定宕机,投票选取新的节点作为主节点,主节点一旦恢复,则会也从节点角色加入集群,继续提供服务
9. 重启哨兵日志时,删除尾部日志,避免影响本次启动
5.2.2 Jedis连接哨兵集群
1. application.properties配置
spring.redis.sentinel=192.168.75.132:26379,192.168.75.132:26380,192.168.75.132:26381
spring.redis.sharedpool.maxTotal=200
spring.redis.sharedpool.maxIdle=10
spring.redis.sharedpool.minIdle=2
2. springboot管理sentinel连接池
@Configuration
@ConfigurationProperties("spring.redis.sentinel")
@Getter
@Setter
public class SentinelConfig { private List<String> nodes;
private Integer maxTotal;
private Integer maxIdle;
private Integer minIdle; @Bean
public JedisSentinelPool sentinelPoolInit() {
//搜集哨兵集群信息
Set<String> sentinelSet = new HashSet<>();
for (String node : nodes) {
String ip = node.split(":")[0];
int port = Integer.parseInt(node.split(":")[1]);
sentinelSet.add(new HostAndPort(ip, port).toString());
}
//连接池配置对象
GenericObjectPoolConfig config = new GenericObjectPoolConfig();
config.setMaxTotal(maxTotal);
config.setMaxIdle(maxIdle);
config.setMinIdle(minIdle);
//构建哨兵管理对象
return new JedisSentinelPool("mymaster", sentinelSet, config);
}
}
3. 连接池测试
@SpringBootTest
class DemoApplicationTests {
@Autowired
private JedisSentinelPool sentinelPool; @Test
public void func5() {
HostAndPort masterIP = sentinelPool.getCurrentHostMaster();
Jedis jedis = sentinelPool.getResource(); //哨兵模式只能操作主节点
String name = jedis.get("name");
}
}
5.3. redis-cluster★
5.3.1 什么是redis集群模式
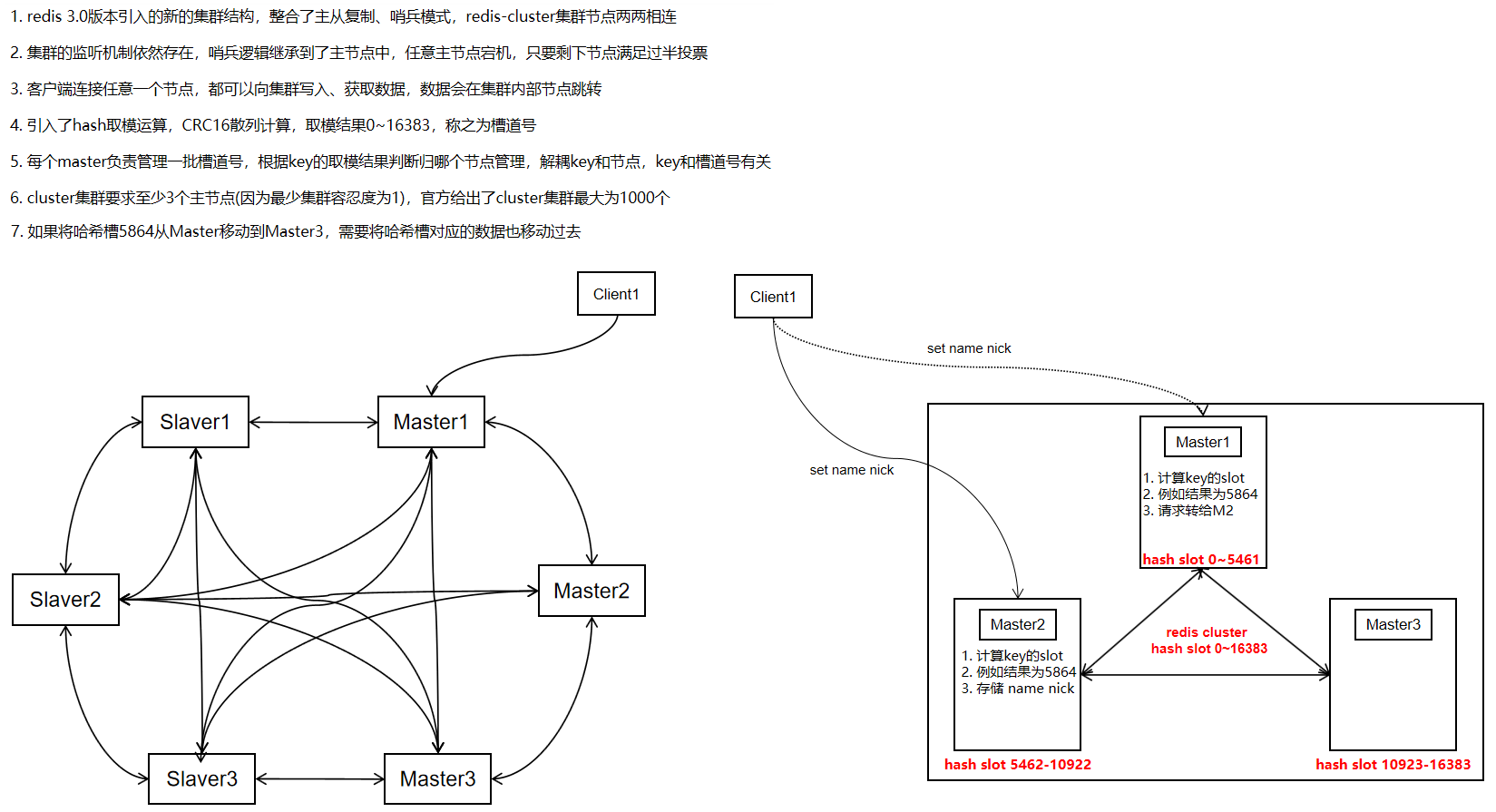
5.3.2 构建redis集群
【初识Redis】的更多相关文章
- 初识redis数据类型
初识redis数据类型 1.String(字符串) string是redis最基本的类型,一个key对应一个value. string类型是二进制安全的.意思是redis的string可以包含任何数据 ...
- Redis——学习之路三(初识redis config配置)
我们先看看config 默认情况下系统是怎么配置的.在命令行中输入 config get *(如图) 默认情况下有61配置信息,每一个命令占两行,第一行为配置名称信息,第二行为配置的具体信息. ...
- Redis——学习之路二(初识redis服务器命令)
上一章我们已经知道了如果启动redis服务器,现在我们来学习一下,以及如何用客户端连接服务器.接下来我们来学习一下查看操作服务器的命令. 服务器命令: 1.info——当前redis服务器信息 s ...
- 01:初识Redis
付磊和张益军两位大咖写的葵花宝典(Redis开发和运维)学习笔记. 一.初识Redis 1.redis简介 Redis是一种基于键值对(key-value)的NoSQL数据库,与很多键值对数据库不同的 ...
- redis实战笔记(1)-第1章 初识Redis
第1章 初识Redis 注:本书在redis3.0版本的,比如redis3.0以后支持服务端集群.3.0之前只能客户端分片. 本章主要内容 1.Redis与其他软件的相同之处和不同之处 2.Re ...
- Linux(5)- MariaDB、mysql主从复制、初识redis
一.MYSQL(mariadb) MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可. 开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL ...
- 分布式数据存储 之 Redis(一) —— 初识Redis
分布式数据存储 之 Redis(一) -- 初识Redis 为什么要学习并运用Redis?Redis有什么好处?我们步入Redis的海洋,初识Redis. 一.Redis是什么 Redis 是一个 ...
- [转]Redis之(一)初识Redis
原文地址:http://blog.csdn.net/u012152619/article/details/52550315 Redis之(一)初识Redis 标签: Redisredis-server ...
- 1.初识Redis
作者 微信:tangy8080 电子邮箱:914661180@qq.com 更新时间:2019-08-14 20:35:36 星期三 欢迎您订阅和分享我的订阅号,订阅号内会不定期分享一些我自己学习过程 ...
- Redis——学习之路一(初识redis)
在接下来的一段时间里面我要将自己学习的redis整理一遍,下面是我整理的一些资料: Redis是一款依据BSD开源协议发行的高性能Key-Value存储系统(cache and store),所以re ...
随机推荐
- 一文带你深入理解JVM,看完之后你还敢说你懂JVM吗?颠覆you认知
前言 今天带大家深入理解JVM,从入门到精通,希望大家能够喜欢~~~ 概念 JVM是可运行 Java 代码的假想计算机 ,包括一套字节码指令集.一组寄存器.一个栈.一个垃圾回收,堆 和 一个存储方法域 ...
- 【Flume】安装与测试
1.下载安装包http://archive.apache.org/dist/flume/ 2.解压命令tar -zxvf 压缩包 -C 路径 3.配置环境变量 export FLUME_HOME=/o ...
- Java实现 LeetCode 784 字母大小写全排列(DFS)
784. 字母大小写全排列 给定一个字符串S,通过将字符串S中的每个字母转变大小写,我们可以获得一个新的字符串.返回所有可能得到的字符串集合. 示例: 输入: S = "a1b2" ...
- Java实现 LeetCode 775 全局倒置与局部倒置(分析题)
775. 全局倒置与局部倒置 数组 A 是 [0, 1, -, N - 1] 的一种排列,N 是数组 A 的长度.全局倒置指的是 i,j 满足 0 <= i < j < N 并且 A ...
- Java实现 蓝桥杯VIP 算法训练 王后传说
问题描述 地球人都知道,在国际象棋中,后如同太阳,光芒四射,威风八面,它能控制横.坚.斜线位置. 看过清宫戏的中国人都知道,后宫乃步步惊心的险恶之地.各皇后都有自己的势力范围,但也总能找到相安无事的办 ...
- Java实现 洛谷 P1103 书本整理
题目描述 Frank是一个非常喜爱整洁的人.他有一大堆书和一个书架,想要把书放在书架上.书架可以放下所有的书,所以Frank首先将书按高度顺序排列在书架上.但是Frank发现,由于很多书的宽度不同,所 ...
- Java实现 LeetCode 30 串联所有单词的子串
30. 串联所有单词的子串 给定一个字符串 s 和一些长度相同的单词 words.找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置. 注意子串要与 words 中的单词完全匹配, ...
- 【大厂面试06期】谈一谈你对Redis持久化的理解?
Redis持久化是面试中经常会问到的问题,这里主要通过对以下几个问题进行分析,帮助大家了解Redis持久化的实现原理. 1.Redis持久化是什么? 2.Redis持久化有哪些策略?各自的实现原理是怎 ...
- Spring事务之@Transactional
参考源API : https://docs.spring.io/spring/docs/current/javadoc-api/ org.springframework.transaction.ann ...
- Java StringTokenizer 类使用方法,字符串分割
Java StringTokenizer 属于 java.util 包,用于分隔字符串. StringTokenizer 构造方法: StringTokenizer(String str) :构造一个 ...