Python中随机森林的实现与解释
使用像Scikit-Learn这样的库,现在很容易在Python中实现数百种机器学习算法。这很容易,我们通常不需要任何关于模型如何工作的潜在知识来使用它。虽然不需要了解所有细节,但了解机器学习模型是如何工作的仍然有用。这使我们可以在模型表现不佳时进行诊断,或者解释模型如何做出决策,如果我们想让别人相信我们的模型,这是至关重要的。
在本文中,我们将介绍如何在Python中构建和使用Random Forest。除了查看代码之外,我们还将尝试了解此模型的工作原理。因为由许多决策树组成的随机森林,我们首先要了解单个决策树如何对一个简单的问题进行分类。然后,我们将努力使用随机森林来解决现实世界的数据科学问题。本文的完整代码在GitHub上以Jupyter Notebook的形式提供【1】。
理解决策树
一个决策树是一个随机森林的基石,是一个直观的模型。我们可以将决策树视为一系列是/否问题,询问我们的数据最终导致预测类(或回归情况下的连续值)。这是一个可解释的模型,因为它可以像我们一样进行分类:(在理想世界中)在我们做出决定之前,我们会询问有关可用数据的一系列问题。
决策树的技术细节是如何形成有关数据的问题。在CART算法中,通过确定问题(称为节点的分裂)来构建决策树,这些问题在被回答时导致基尼杂质的最大减少。这意味着决策树试图通过在将数据干净地划分为类的特征中查找值来形成包含来自单个类的高比例样本(数据点)的节点。
我们稍后将讨论关于Gini杂质的低级细节,但首先,让我们构建一个决策树,以便我们能够在高层次上理解它。
关于简单问题的决策树
我们将从一个非常简单的二进制分类问题开始,如下所示:
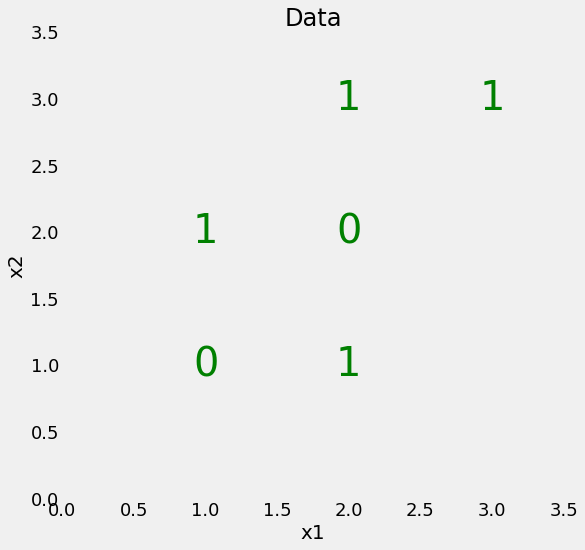
我们的数据仅具有两个特征(预测变量),具有6个数据点,分成2个不同的标签。虽然这个问题很简单,但它不是线性可分的,这意味着我们不能通过数据绘制一条直线来对点进行分类。
然而,我们可以绘制一系列直线,将数据点划分为多个框,我们称之为节点。实际上,这就是决策树在训练期间所做的事情。有效地,决策树是通过构造许多线性边界而构建的非线性模型。
要创建决策树并对数据进行训练(fit),我们使用Scikit-Learn。
from sklearn.tree import DecisionTreeClassifier# Make a decision tree and traintree = DecisionTreeClassifier(random_state=RSEED)tree.fit(X, y)
在训练过程中,我们为模型提供特征和标签,以便学习根据特征对点进行分类。(我们没有针对这个简单问题的测试集,但在测试时,我们只为模型提供功能并让它对标签进行预测。)
我们可以在训练数据上测试我们模型的准确性:
print(fModel Accuracy: {tree.score(X, y)})Model Accuracy: 1.0
我们看到它获得100%的准确性,这是我们所期望的,因为我们提供了训练的答案(y)并没有限制树的深度。事实证明,完全学习训练数据的能力可能是决策树的缺点,因为它可能会导致过度拟合,我们稍后会讨论。
可视化决策树
那么当我们训练决策树时,实际上会发生什么?我找到了一种有用的方法来理解决策树是通过可视化来实现的,我们可以使用Scikit-Learn函数。
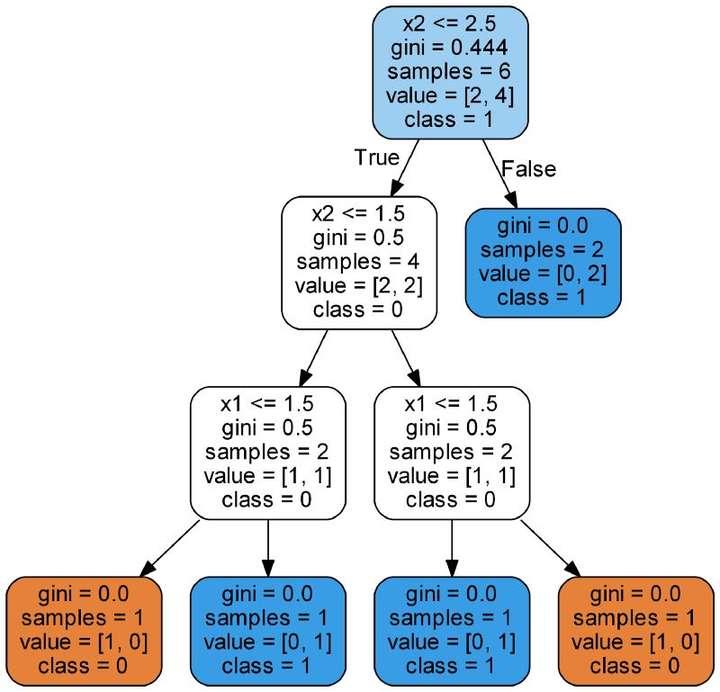
除叶子节点(彩色终端节点)外,所有节点都有5个部分:
问题基于特征的值询问了数据。每个问题都有一个分裂节点的真或假答案。根据问题的答案,数据点向下移动。
gini:节点的Gini杂质。当我们向下移动树时,平均加权基尼杂质值会减少。
samples:节点中的观察数。
value:每个类的样本数量。例如,顶部节点在类0中有2个样本,在类1中有4个样本。
class:节点中点的多数分类。在叶节点的情况下,这是对节点中所有样本的预测。
要对新点进行分类,只需向下移动树,使用点的特征来回答问题,直到到达class作为预测的叶节点。
为了以不同的方式查看树,我们可以在原始数据上绘制由决策树构建的分割。
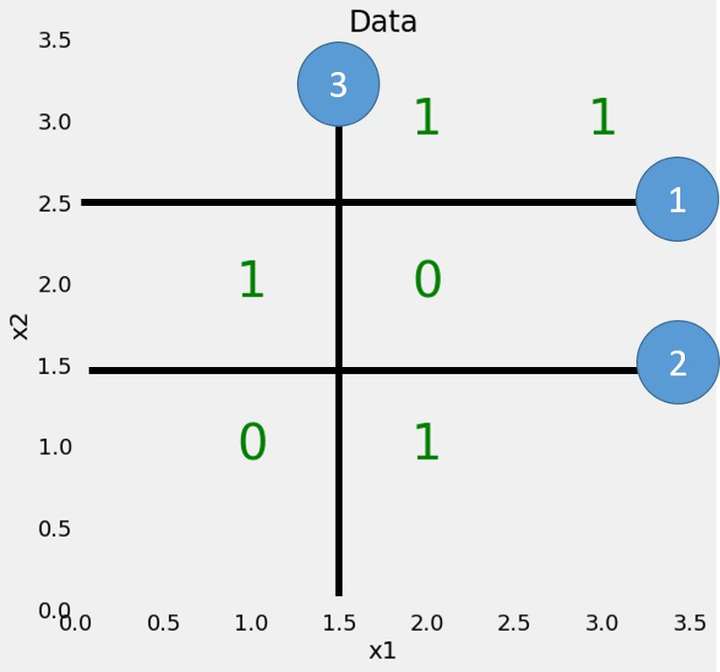
每个拆分都是一条线,它根据特征值将数据点划分为节点。对于这个简单的问题并且对最大深度没有限制,划分将节点中的每个点仅放置在同一类的点上。(再次,稍后我们将看到训练数据的这种完美划分可能不是我们想要的,因为它可能导致过度拟合。
基尼杂质
现在深入了解基尼杂质的概念(数学并不令人生畏!)。节点的基尼杂质是指节点中随机选择的样本如果被标记的错误标记的概率。节点中样本的分布。例如,在顶部(根)节点中,有44.4%的可能性错误地根据节点中的样本标签对随机选择的数据点进行分类。我们使用以下等式得出这个值:
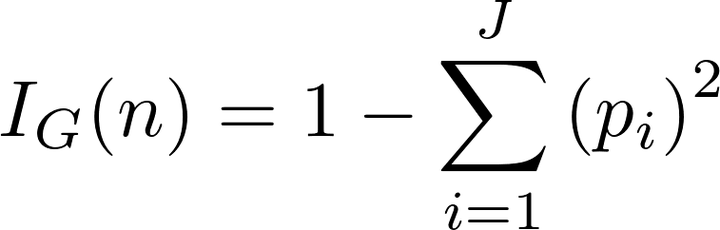
节点的Gini杂质是1减去每个类的p_i平方的总和(对于二分类任务,这是2)。这可能有点令人困惑,所以让我们计算出根节点的基尼杂质。

在每个节点处,决策树在要素中搜索要拆分的值,从而最大限度地减少基尼杂质。(拆分节点的替代方法是使用信息增益)。
然后,它以贪婪的递归过程重复此拆分过程,直到达到最大深度,或者每个节点仅包含来自一个类的样本。每层的加权总基尼杂质必须减少。在树的第二层,总加权基尼杂质值为0.333:
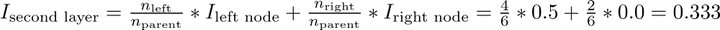
最终,最后一层的加权总Gini杂质变为0意味着每个节点都是纯粹的,并且从该节点随机选择的点不会被错误分类。虽然这似乎是好的,但这意味着模型可能过度拟合,因为节点仅使用训练数据构建。
过度拟合:或者为什么森林比一棵树更好
您可能会想问为什么不只使用一个决策树?它似乎是完美的分类器,因为它没有犯任何错误!要记住的关键点是树在训练数据上没有犯错。我们预计会出现这种情况,因为我们给树提供了答案,并没有限制最大深度(级别数)。机器学习模型的目标是很好地概括它以前从未见过的新数据。
当我们具有非常灵活的模型(模型具有高容量)时,过度拟合发生,其基本上通过紧密拟合来记忆训练数据。问题是模型不仅学习训练数据中的实际关系,还学习任何存在的噪声。据说灵活模型具有高方差,因为学习参数(例如决策树的结构)将随着训练数据而显着变化。
另一方面,据说一个不灵活的模型具有较高的偏差,因为它对训练数据做出了假设(它偏向于预先设想的数据思想。)例如,线性分类器假设数据是线性的,不具备适应非线性关系的灵活性。一个不灵活的模型可能无法适应训练数据,在这两种情况下 - 高方差和高偏差 - 模型无法很好地推广到新数据。
创建一个非常灵活的模型来记忆训练数据与不能学习训练数据的不灵活模型之间的平衡称为偏差 - 方差权衡,是机器学习的基本概念。
当我们不限制最大深度时决策树容易过度拟合的原因是因为它具有无限的灵活性,这意味着它可以保持增长,直到它为每个单独的观察只有一个叶节点,完美地对所有这些进行分类。如果您返回决策树的图像并将最大深度限制为2(仅进行一次拆分),则分类不再100%正确。我们减少了决策树的方差,但代价是增加了偏差。
作为限制树深度的替代方案,它可以减少方差(好)并增加偏差(差),我们可以将许多决策树组合成一个称为随机森林的单一集合模型。
随机森林
在随机森林是许多决策树组成的模型。这个模型不是简单地平均树的预测(这样的算法可以称为“森林”),而是使用两个关键概念,使其名称为随机森林:
①在构建树时对训练数据点进行随机抽样
②分割节点时考虑的随机特征子集
随机抽样训练观察
在训练时,随机森林中的每棵树都会从数据点的随机样本中学习。样本用可放回抽取,称为bootstraping,这意味着一些样本将在一棵树中多次使用。这个想法是通过对不同样本上的每棵树进行训练,尽管每棵树相对于特定训练数据集可能具有高度差异,但总体而言,整个森林将具有较低的方差,但不会以增加偏差为代价。
在测试时,通过平均每个决策树的预测来进行预测。这种在不同的数据bootstraped子集上训练每个学习器然后对预测求平均值的过程称为bagging,是bootstrap aggregating的缩写。
用于拆分节点的随机特征子集
随机林中的另一个主要概念是,只考虑所有特征的子集来分割每个决策树中的每个节点。通常,这被设置为sqrt(n_features)个用于分类,这意味着如果存在16个特征,则在每个树中的每个节点处,将仅考虑4个随机特征来分割节点。(随机林也可以考虑每个节点的所有特征,如回归中常见的那样。这些选项可以在Scikit-Learn 的Random Forest实现中控制)。
如果你能理解一个决策树,bagging的想法,以及随机的特征子集,那么你对随机森林的工作方式有了很好的理解:
随机森林将数百或数千个决策树组合在一起,在略微不同的观察集上训练每个决策树,考虑到有限数量的特征,在每棵树中分割节点。随机森林的最终预测是通过平均每棵树的预测来做出的。
要理解为什么随机森林优于单一决策树,请想象以下情况:您必须决定特斯拉股票是否会上涨,并且您可以访问十几位对该公司没有先验知识的分析师。每个分析师都有较低的偏见,因为他们没有任何假设,并且可以从新闻报道的数据集中学习。
这似乎是一个理想的情况,但问题是报告除了真实信号之外可能还包含噪声。因为分析师完全根据数据做出预测 - 他们具有很高的灵活性 - 他们可能会被无关的信息所左右。分析师可能会从同一数据集中得出不同的预测。此外,如果给出不同的报告训练集,每个分析师的差异很大,并且会得出截然不同的预测。
解决方案是不依赖于任何一个人,而是汇集每个分析师的投票。此外,就像在随机森林中一样,允许每个分析人员只访问报告的一部分,并希望通过采样取消噪声信息的影响。在现实生活中,我们依赖于多种来源,因此,决策树不仅直观,而且在随机森林中将它们组合在一起的想法也是如此。
随机森林实践
接下来,我们将使用Scikit-Learn在Python中构建一个随机林。我们将使用分为训练和测试集的真实数据集,而不是学习一个简单的问题。我们使用测试集作为模型对新数据的执行方式的估计,这也可以让我们确定模型过度拟合的程度。
数据集
我们要解决的问题是二元分类任务,目的是预测个人的健康状况。这些特征是个人的社会经济和生活方式特征,标签是0健康状况不佳和1身体健康。此数据集是来自中心疾病控制和预防【2】。
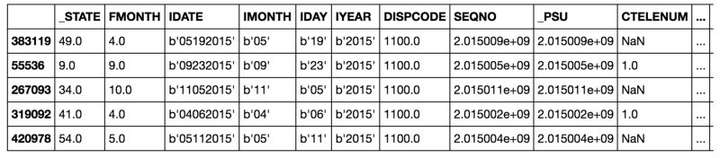
通常,80%的数据科学项目需要对数据进行清理,探索和特征生成【3】。但是,对于本文,我们将集中于建模。
这是一个不平衡的分类问题,因此准确性Accuracy不是一个合适的指标。相反,我们将测量 Receiver Operating Characteristic Area Under the Curve (ROC AUC),从0(最差)到1(最佳)的度量,随机猜测得分为0.5。我们还可以绘制ROC曲线以评估模型。
该notebook【4】包含了决策树和随机森林都实现,但在这里我们只专注于随机森林。在读取数据后,我们可以实例化和训练随机森林如下:
from sklearn.ensemble import RandomForestClassifier# Create the model with 100 treesmodel = RandomForestClassifier(n_estimators=100,bootstrap = True,max_features = sqrt)# Fit on training datamodel.fit(train, train_labels)
在训练几分钟后,模型准备好对测试数据进行如下预测:
# Actual class predictionsrf_predictions = model.predict(test)# Probabilities for each classrf_probs = model.predict_proba(test)[:, 1]
我们进行类预测(predict)以及预测概率(predict_proba)来计算ROC AUC。一旦我们有了测试预测,我们就可以计算出ROC AUC。
from sklearn.metrics import roc_auc_score# Calculate roc aucroc_value = roc_auc_score(test_labels, rf_probs)
结果
随机森林的最终测试ROC AUC为0.87,而具有无限最大深度的单一决策树的最终测试ROC AUC为0.67。如果我们查看训练分数,两个模型都达到1.0 ROC AUC,这也是预期的,因为我们给这些模型提供了训练答案,并没有限制每棵树的最大深度。
虽然随机森林过度拟合(在训练数据上比在测试数据上做得更好),但它能够比单一决策树更好地应用到测试数据。随机森林具有较低的方差(良好),同时保持决策树的相同低偏差(也良好)。
我们还可以绘制单个决策树(顶部)和随机森林(底部)的ROC曲线。顶部和左侧的曲线是更好的模型:
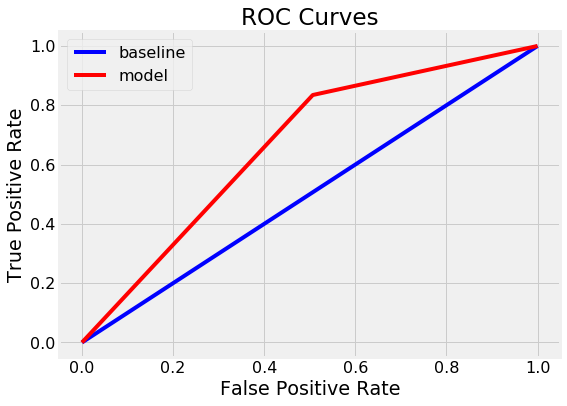
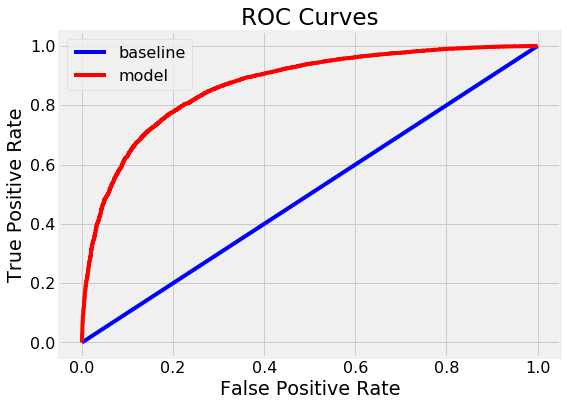
随机森林明显优于单一决策树。
我们可以采用的模型的另一个诊断措施是绘制测试预测的confusion矩阵
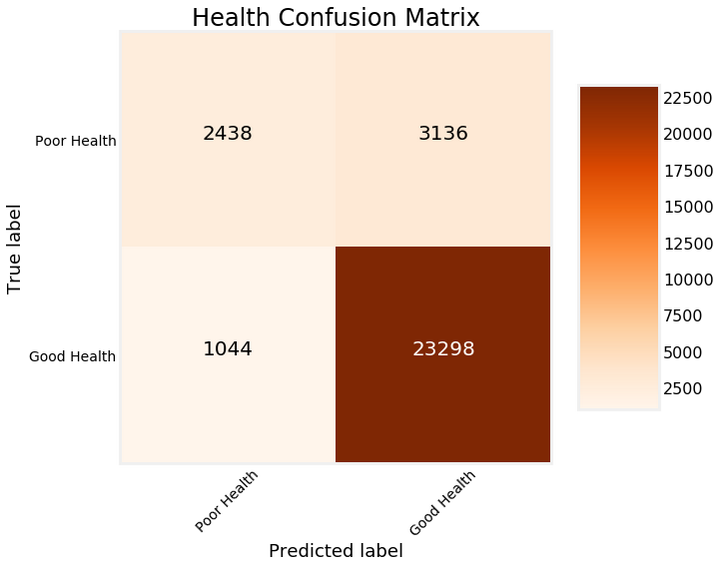
这显示了模型在左上角和右下角的正确预测以及模型在左下角和右上角错的预测。我们可以使用这些图来诊断我们的模型,并确定它是否表现良好,可以投入生产。
特征重要性
随机林中的特征重要性表示基于该特征上拆分的所有节点上Gini杂质减少的总和。我们可以使用这些来尝试找出随机森林认为最重要的预测变量。可以从训练好的随机森林中提取特征重要性,并将其放入Pandas的DataFrame中,如下所示:
import pandas as pd# Extract feature importancesfi = pd.DataFrame({feature: list(train.columns),importance: model.feature_importances_}).\sort_values(importance, ascending = False)# Displayfi.head()feature importanceDIFFWALK 0.036200QLACTLM2 0.030694EMPLOY1 0.024156DIFFALON 0.022699USEEQUIP 0.016922
通过告诉我们哪些变量在类之间最具辨别力,特征重要性可以让我们洞察问题。例如,这里DIFFWALK, 指示患者是否行走困难,是在问题环境中有意义的最重要的特征。
我们可以通过构建最重要的附加特征,将特征重要性用于特征工程。我们还可以通过删除低重要性特征,使用特征重要性来选择特征。
在森林中可视化树
最后,我们可以在森林中可视化单个决策树。这次,我们必须限制树的深度,否则它将太大而无法转换为图像。为了制作下图,我将最大深度限制为6.这仍然导致我们无法完全解析的大树!然而,鉴于我们深入研究了决策树,我们掌握了模型的工作原理。

下一步
进一步的步骤是使用Scikit-Learn的RandomizedSearchCV中的随机搜索来优化随机森林。优化是指在给定数据集上找到模型的最佳超参数。最佳超参数将在数据集之间变化,因此我们必须在每个数据集上单独执行优化(也称为模型调整)。
我喜欢将模型调整视为寻找机器学习算法的最佳设置。我们可以在随机林中优化的因素包括决策树的数量,每个决策树的最大深度,用于拆分每个节点的最大特征数,以及叶节点中所需的最大数据点数。
【参阅资料】
【2】https://www.kaggle.com/cdc/behavioral-risk-factor-surveillance-system
Python中随机森林的实现与解释的更多相关文章
- 用Python实现随机森林算法,深度学习
用Python实现随机森林算法,深度学习 拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩 ...
- 31 Python中 sys.argv[]的用法简明解释(转)
Python中 sys.argv[]的用法简明解释 因为是看书自学的python,开始后不久就遇到了这个引入的模块函数,且一直在IDLE上编辑了后运行,试图从结果发现它的用途,然而结果一直都是没结果, ...
- Python中 sys.argv的用法简明解释
Python中 sys.argv[]的用法简明解释 sys.argv[]说白了就是一个从程序外部获取参数的桥梁,这个“外部”很关键,所以那些试图从代码来说明它作用的解释一直没看明白.因为我们从外部取得 ...
- python实现随机森林、逻辑回归和朴素贝叶斯的新闻文本分类
实现本文的文本数据可以在THUCTC下载也可以自己手动爬虫生成, 本文主要参考:https://blog.csdn.net/hao5335156/article/details/82716923 nb ...
- sklearn中随机森林的参数
一:sklearn中决策树的参数: 1,criterion: ”gini” or “entropy”(default=”gini”)是计算属性的gini(基尼不纯度)还是entropy(信息增益),来 ...
- python的随机森林模型调参
一.一般的模型调参原则 1.调参前提:模型调参其实是没有定论,需要根据不同的数据集和不同的模型去调.但是有一些调参的思想是有规律可循的,首先我们可以知道,模型不准确只有两种情况:一是过拟合,而是欠拟合 ...
- Python学习-35.Python中的List Comprehensions(列表解释|列表生成式)
在某些情况下,我们需要对列表进行某些操作,例如对列表中的每一个元素都乘以2,这样一般来说就是遍历每个元素在乘以2.那么写下来就得两行了.而且这会修改原来的列表,如果要求不能修改原来的列表,又得多一行了 ...
- Python之随机森林实战
代码实现: # -*- coding: utf-8 -*- """ Created on Tue Sep 4 09:38:57 2018 @author: zhen &q ...
- Python中 sys.argv[]的用法简明解释
sys.argv[]就是一个从程序外部获取参数的桥梁,这个“外部”很关键.因为我们从外部取得的参数可以是多个,所以获得的是一个列表(list),也就是说sys.argv其实可以看作是一个列表,所以才能 ...
随机推荐
- C#中扩展方法的使用
MSDN中这样定义扩展方法:扩展方法使你能够向现有类型“添加”方法,而无需创建新的派生类型.重新编译或以其他方式修改原始类型. 扩展方法是一种特殊的静态方法,但可以像扩展类型上的实例方法一样进行调用. ...
- Including R code in perl
#example: use Statistics::R;#use R in perlmy $R = Statistics::R->new() ;$R->startR ;$R->sen ...
- Java基于opencv—透视变换矫正图像
很多时候我们拍摄的照片都会产生一点畸变的,就像下面的这张图 虽然不是很明显,但还是有一点畸变的,而我们要做的就是把它变成下面的这张图 效果看起来并不是很好,主要是四个顶点找的不准确,会有一些偏差,而且 ...
- basic knowledge
---恢复内容开始--- TCP/IP指的是利用IP通信时必须用到的协议群统称. 分层模型: 1.物理层:硬件. 2.数据链路层:网络接口层.当做NIC驱动程序. 3.网络层:互联网层.IP协议基于I ...
- 删除排序数组中的重复项-leetcode-26
public: int removeDuplicates(vector<int>& nums) { int size=nums.size(); i ...
- RABBITMQ too many heartbeats missed
执行rabbitmqctl status | grep -A 4 file_descriptors 显示socket_used 达到 socket_limited 的值 增加socket_limi ...
- 自己用的Xshell配色方案
[comfort]text=dce2e2cyan(bold)=2ad1b8text(bold)=dce2e2magenta=dd3682green=55bb55green(bold)=55bb55ba ...
- Python 限制线程的最大数量(Semaphore)
import threadingimport time sem = threading.Semaphore(4) # 限制线程的最大数量为4个 def gothread(): with sem: # ...
- Matlab高级绘图
http://blog.csdn.net/haizimin/article/details/50372630 图形是呈现数据的一种直观方式,在用Matlab进行数据处理和计算后,我们一般都会以图形的形 ...
- 2018-2019-2 网络对抗技术 20165308 Exp4 恶意代码分析
2018-2019-2 网络对抗技术 20165308 Exp4 恶意代码分析 实验过程 一.系统运行监控 (1)使用如计划任务,每隔一分钟记录自己的电脑有哪些程序在联网,连接的外部IP是哪里.运行一 ...