最近邻算法(KNN)
最近邻算法:
1.什么是最近邻是什么?
kNN算法全程是k-最近邻算法(k-Nearest Neighbor)
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数数以一个类型别,则该样本也属于这个类别,并具有该类别上样本的特征。该方法在确定分类决策上,只依据最近邻的一个或者几个样本的类别来决定待分样本所属的类别。
下面举例说明:

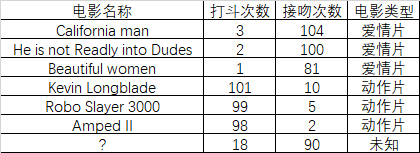
即使不知道未知电影属于哪个类型,我们也可以通过某种方式计算,如下图
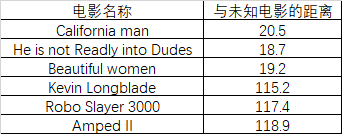
现在,我们得到了样本集中与未知电影的距离,按照距离的递增顺序,可以找到k个距离最近的电影,假设k=3,则三个最靠近的电影是he is not realy into Dudes,Beautiful women, California man , kNN 算法按照距离最近的三部电影类型决定未知电影的类型,这三部都是爱情片,所以未知电影的类型也是爱情片。
2:kNN算法的一般流程
- step.1---初始化距离为最大值
- step.2---计算未知样本和每个训练样本的距离dist
- step.3---得到目前K个最邻近样本中的最大距离maxdist
- step.4---如果dist小于maxdist, 则将训练样本作为K-最近邻样本
- step.5---重复步骤2,3,4,直到未知样本和所有训练样本的距离都算完
- step.6---统计K-最近邻样本中每个类标号出现的次数
- step.7---出现频率最大的类标号最为未知样本的类标号
3.距离公式
在KNN算法中,通过计算对象间距离作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧式距离或者曼哈顿距离:

对应代码如下
# kNN算法全称是k-最近邻算法(K-Nearest Neighbor)
from numpy import *
import operator # 创建数据函数
def createDataSet():
""" 创建数据集,array 创建数组
array数组内依次是打斗次数, 接吻次数
group小组, labels标签"""
group = array([[3, 104], [2, 100], [1, 81], [101, 10], [99, 5], [98, 2]])
labels = ["爱情片", "爱情片", "爱情片", "动作片", "动作片", "动作片"]
return group, labels # 归类函数
def classify(inX, dataSet, labels, k):
""" 获取维度,
inX 待测目标的数据,
dataSet 样本数据,
labels 标签,
k 设置比较邻近的个数"""
dataSetSize = dataSet.shape[0] # 训练数据集数据 行数
print(dataSetSize)
print(tile(inX, (dataSetSize, 1))) diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 测试数据,样本之间的数据 矩阵偏差
print(diffMat) sqDiffMat = diffMat**2 # 平方计算,得出每个距离的值
print(sqDiffMat) sqDistance = sqDiffMat.sum(axis=1) # 输出每行的值
print(sqDistance) distances = sqDistance**0.5 # 开方计算
print(distances) sortedDistances = distances.argsort() # 排序 按距离从小到大 输出索引
print(sortedDistances) classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistances[i]] + 1.0 # 按照排序,获取k个对应的标签
classCount[voteIlabel] = classCount.get(voteIlabel, 0) # 在字典中添加距离最近的k个对应标签
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] group, labels = createDataSet()
res = classify([18, 90], group, labels, 3)
print(res)
运行结果:

知识扩展:
python3字典中items()和python2.x中iteritems()有什么不同?
numpy中 array数组的shape属性
numpy 中 shape_base提供的tile方法
最近邻算法(KNN)的更多相关文章
- 转载: scikit-learn学习之K最近邻算法(KNN)
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- k最近邻算法(kNN)
from numpy import * import operator from os import listdir def classify0(inX, dataSet, labels, k): d ...
- 【udacity】机器学习-knn最近邻算法
Evernote Export 1.基于实例的学习介绍 不同级别的学习,去除所有的数据点(xi,yi),然后放入一个数据库中,下次直接提取数据 但是这样的实现方法将不能进行泛化,这种方式只能简单的 ...
- 机器学习【一】K最近邻算法
K最近邻算法 KNN 基本原理 离哪个类近,就属于该类 [例如:与下方新元素距离最近的三个点中,2个深色,所以新元素分类为深色] K的含义就是最近邻的个数.在sklearn中,KNN的K值是通过n ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- KNN(k-nearest neighbor的缩写)又叫最近邻算法
KNN(k-nearest neighbor的缩写)又叫最近邻算法 机器学习笔记--KNN算法1 前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的 ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 12、K最近邻算法(KNN算法)
一.如何创建推荐系统? 找到与用户相似的其他用户,然后把其他用户喜欢的东西推荐给用户.这就是K最近邻算法的分类作用. 二.抽取特征 推荐系统最重要的工作是:将用户的特征抽取出来并转化为度量的数字,然后 ...
- PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废, 所以在生产前需计划多投一定比例的板板, 例:订单 量是5000pcs,加投3%,那 ...
随机推荐
- Dream team: Stacking for combining classifiers梦之队:组合分类器
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Hbase学习04
3.2.4 反向时间戳 反向扫描API HBASE-4811(https://issues.apache.org/jira/browse/HBASE-4811)实现了一个API来扫描一个表或范围内的一 ...
- Sublime Text3 里使用MarkDown如何预览
安装需要的包: 1.markdown editing 2.markdown preview 具体的步骤是: 1.按住ctrl + shift + p 来调出一个弹出的输入框 :2.输入package ...
- [开源 .NET 跨平台 Crawler 数据采集 爬虫框架: DotnetSpider] 学习
http://www.cnblogs.com/jjg0519/p/6707513.html
- laravel 5.4 fopen(): Filename cannot be empty
1.出错的报错信息(我在用laravel5.4文件上传时候出错的) laravel 5.4 fopen(): Filename cannot be empty 2.解决的方法 在php.ini中修改临 ...
- a标签与js的冲突
如上图,需要做一个页面,点击左边的标题,右边就显示左边标题下的子标题的集合, html代码如下: <div id="newleft"> <ul> <l ...
- vue基于组件实现简单的todolist
把todolist拆分为header.footer.list三个模块 index文件 <!DOCTYPE html> <html lang="en"> &l ...
- 068、Calico的网络结构是什么?(2019-04-11 周四)
参考https://www.cnblogs.com/CloudMan6/p/7520164.html root@host1:~# docker run -itd --name bbox1 -- ...
- Java时间转换的一个特性
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm"); Date codedat ...
- C# UserControl集合属性使用
在UserControl中,定义集合属性时,如果直接使用List是检测不到在属性框中的列表修改变化的,可以通过 ObservableCollection() 实现 1.定义类 [Serializabl ...