第二十七节,IOU和非极大值抑制
你如何判断对象检测算法运作良好呢?在这一节中,你将了解到并交比函数,可以用来评价对象检测算法。
一 并交比(Intersection over union )

在对象检测任务中,你希望能够同时定位对象,所以如果实际边界框是这样的,你的算法给出这个紫色的边界框,那么这个结果是好还是坏?所以交并比(loU)函数做的是计算两个边界框交集和并集之比。两个边界框的并集是这个区域,就是属于包含两个边界框区域(绿色阴影表示区域),而交集就是这个比较小的区域(橙色阴影表示区域),那么交并比就是交集的大小,这个橙色阴影面积,然后除以绿色阴影的并集面积。
一般约定,在计算机检测任务中,如果IoU≥0.5,就说检测正确,如果预测器和实际边界框完美重叠, loU 就是 1,因为交集就等于并集。但一般来说只要loU≥ 0.5,那么结果是可以接受的,看起来还可以。一般约定,0.5 是阈值,用来判断预测的边界框是否正确。一般是这么约定,但如果你希望更严格一点,你可以将 loU 定得更高,比如说大于 0.6 或者更大的数字,但 loU 越高,边界框越精确。
所以这是衡量定位精确度的一种方式,你只需要统计算法正确检测和定位对象的次数,你就可以用这样的定义判断对象定位是否准确。再次, 0.5 是人为约定,没有特别深的理论依据,如果你想更严格一点,可以把阈值定为 0.6。 有时我看到更严格的标准,比如 0.6 甚至 0.7,但很少见到有人将阈值降到 0.5 以下。
人们定义 loU 这个概念是为了评价你的对象定位算法是否精准,但更一般地说, loU 衡量了两个边界框重叠地相对大小。如果你有两个边界框,你可以计算交集,计算并集,然后求两个数值的比值,所以这也可以判断两个边界框是否相似,我们将在后面再次用到这个函数,当我们讨论非最大值抑制时再次用到。
二 非极大值抑制
到目前为止你们学到的对象检测中的一个问题是,你的算法可能对同一个对象做出多次检测,所以算法不是对某个对象检测出一次,而是检测出多次。非极大值抑制这个方法可以确保你的算法对每个对象只检测一次,我们讲一个例子。

假设你需要在这张图片里检测行人和汽车,你可能会在上面放个 19×19 网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测。

实践中当你运行对象分类和定位算法时,对于每个格子都运行一次,所以这个格子(编号 1)可能会认为这辆车中点应该在格子内部,这几个格子(编号 2、 3)也会这么认为。对于左边的车子也一样,所以不仅仅是这个格子,如果这是你们以前见过的图像,不仅这个格(编号 4)子会认为它里面有车,也许这个格子(编号 5)和这个格子(编号 6)也会,也许其他格子也会这么认为,觉得它们格子内有车。
我们分步介绍一下非极大抑制是怎么起效的,因为你要在 361 个格子上都运行一次图像检测和定位算法,那么可能很多格子都会举手说我的,我这个格子里有车的概率很高,而不是 361 个格子中仅有两个格子会报告它们检测出一个对象。所以当你运行算法的时候,最后可能会对同一个对象做出多次检测,所以非极大值抑制做的就是清理这些检测结果。这样一辆车只检测一次,而不是每辆车都触发多次检测。

所以具体上,这个算法做的是,首先看看每次报告每个检测结果相关的概率pc,实际上是pc乘以c1、 c2或c3。现在我们就说,这个pc检测概率,首先看概率最大的那个,这个例子(右边车辆)中是 0.9,然后就说这是最可靠的检测,所以我们就用高亮标记,就说我这里找到了一辆车。这么做之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比,高度重叠的其他边界框,那么这些输出就会被抑制。所以这两个矩形pc分别是 0.6 和 0.7,这两个矩形和淡蓝色矩形重叠程度很高,所以会被抑制,变暗,表示它们被抑制了。

接下来,逐一审视剩下的矩形,找出概率最高, pc最高的一个,在这种情况下是 0.8,我们就认为这里检测出一辆车(左边车辆),然后非极大值抑制算法就会去掉其他 loU 值很高的矩形。所以现在每个矩形都会被高亮显示或者变暗,如果你直接抛弃变暗的矩形,那就剩下高亮显示的那些,这就是最后得到的两个预测结果。
所以这就是非极大值抑制,非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
我们来看看算法的细节,首先这个 19×19 网格上执行一下算法,你会得到 19×19×8 的输出尺寸。不过对于这个例子来说,我们简化一下,就说你只做汽车检测,我们就去掉c1、 c2或c3,然后假设这条线对于 19×19 的每一个输出,对于 361 个格子的每个输出,你会得到这样的输出预测,就是格子中有对象的概率(pc),然后是边界框参数(bx、 by、 bℎ和bw)。如果你只检测一种对象,那么就没有c1、 c2或c3这些预测分量。

现在要实现非极大值抑制,你可以做的第一件事是,我们就将所有的预测值,所有的边界框pc小于或等于某个阈值, 比如≤0.6 的边界框去掉。

我们就这样说,除非算法认为这里存在对象的概率至少有 0.6,否则就抛弃,所以这就抛弃了所有概率比较低的输出边界框。

接下来剩下的边界框,你就一直选择概率pc最高的边界框,然后把它输出成预测结果,这个过程就是上面所说的,取一个边界框,让它高亮显示,这样你就可以确定输出只出有一辆车的预测。

接下来去掉所有剩下的边界框,任何没有达到输出标准的边界框,之前没有抛弃的边界框,把这些和输出边界框有高重叠面积和上一步输出边界框有很高交并比的边界框全部抛弃。所以 while 循环的第二步是之前所说的变暗的那些边界框,和高亮标记的边界重叠面积很高的那些边界框抛弃掉。在还有剩下边界框的时候,一直这么做,把没处理的都处理完,直到每个边界框都判断过了.
上面只介绍了算法检测单个对象的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托,那么输出向量就会有三个额外的分量。事实证明,正确的做法是独立进行三次非极大值抑制,对每个输出类别都做一次。
这就是非极大值抑制,如果你能实现我们说过的对象检测算法,你其实可以得到相当不错的结果。 但结束我们对 YOLO 算法的介绍之前,最后我还有一个细节想给大家分享,可以进一步改善算法效果,就是 anchor box 的思路。
三 Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用 anchor box 这个概念,我们从一个例子开始讲吧。

假设你有这样一张图片,对于这个例子,我们继续使用 3×3 网格,注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。所以对于那个格子,如果y输出这个向量:

你可以检测这三个类别,行人、汽车和摩托车,它将无法输出检测结果,所以我必须从两个检测结果中选一个。

而 anchor box 的思路是,这样子,预先定义两个不同形状的 anchor box,你要做的是把预测结果和这两个 anchor box 关联起来。一般来说,你可能会用更多的 anchor box,可能要 5 个甚至更多,但在这里,我们就用两个 anchor box,这样介绍起来简单一些。

你要做的是定义类别标签 , 用的向量不再是上面这个:
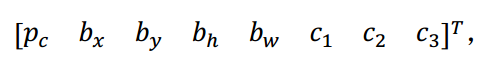
而是重复两次:
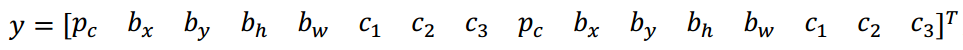
前面的pc,bx,by,bh,bw,c1,c2,c3(绿色方框标记的参数)是和 anchor box 1 关联的 8 个参数,后面的 8 个参数(橙色方框标记的元素)是和 anchor box 2 相关联。因为行人的形状更类似于anchor box 1 的形状,而不是 anchor box 2 的形状,所以你可以用这 8 个数值(前 8 个参数),这么编码pc=1,是的,代表有个行人,用bx,by,bh,bw来编码包住行人的边界框,然后用c1,c2,c3(c1=1,c2=0,c3=0)来说明这个对象是个行人。
然后是车子,因为车子的边界框比起 anchor box 1 更像 anchor box 2 的形状,你就可以这么编码,这里第二个对象是汽车,然后有这样的边界框等等,这里所有参数都和检测汽车相关(pc=1,bx,by,bh,bw,c1=0,c2=1,c3=0)。

总结一下, 用 anchor box 之前,你做的是这个,对于训练集图像中的每个对象,都根据那个对象中点位置分配到对应的格子中,所以输出y就是 3×3×8,因为是 3×3 网格,对于每个网格位置,我们有输出向量,包含pc,然后边界框参数bx,by,bh,bw,然后c1,c2,c3。
现在用到 anchor box 这个概念,是这么做的。现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的 anchor box 中。所以这里有两个 anchor box,你就取这个对象,如果你的对象形状是这样的(编号 1,红色框),你就看看这两个 anchor box, anchor box 1 形状是这样(编号 2,紫色框), anchorbox 2 形状是这样(编号 3,紫色框),然后你观察哪一个 anchor box 和实际边界框(编号1,红色框)的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,即(grid cell, anchor box)对,这就是对象在目标标签中的编码方式。所以现在输出 y就是 3×3×16,或者你也可以看成是3×3×2×8,因为现在这里有 2 个 anchor box,而 y是 8 维的。 y维度是 8,因为我们有 3 个对象类别,如果你有更多对象,那么y的维度会更高。

所以我们来看一个具体的例子,对于这个格子(编号 2),我们定义一下y=
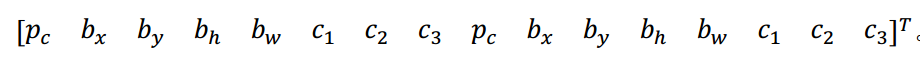
所以行人更类似于 anchor box 1 的形状,所以对于行人来说,我们将她分配到向量的上半部分。是的,这里存在一个对象,即pc = 1,有一个边界框包住行人,如果行人是类别 1,那么 c1 = 1, c2 =0, c3 = 0(编号 1 所示的橙色参数)。车子的形状更像 anchor box 2,所以这个向量剩下的部分是 pc = 1,然后和车相关的边界框,然后 c1 = 0, c2 =1, c3 = 0(编号 1 所示的绿色参数)。所以这就是对应中下格子的标签 y,这个箭头指向的格子(编号 2 所示)。
现在其中一个格子有车,没有行人,如果它里面只有一辆车,那么假设车子的边界框形状是这样,更像 anchor box 2,如果这里只有一辆车,行人走开了,那么 anchor box 2 分量还是一样的,要记住这是向量对应 anchor box 2 的分量和 anchor box 1 对应的向量分量,你要填的就是,里面没有任何对象,所以 pc = 0, 然后剩下的就是 don’t care-s(即? )(编号 3所示)。
现在还有一些额外的细节,如果你有两个 anchor box,但在同一个格子中有三个对象,这种情况算法处理不好,你希望这种情况不会发生,但如果真的发生了,这个算法并没有很好的处理办法,对于这种情况,我们就引入一些打破僵局的默认手段。还有这种情况,两个对象都分配到一个格子中,而且它们的 anchor box 形状也一样,这是算法处理不好的另一种情况,你需要引入一些打破僵局的默认手段,专门处理这种情况,希望你的数据集里不会出现这种情况,其实出现的情况不多,所以对性能的影响应该不会很大。
这就是 anchor box 的概念,我们建立 anchor box 这个概念,是为了处理两个对象出现在同一个格子的情况,实践中这种情况很少发生,特别是如果你用的是 19×19 网格而不是3×3 的网格,两个对象中点处于 361 个格子中同一个格子的概率很低,确实会出现,但出现频率不高。也许设立 anchor box 的好处在于 anchor box 能让你的学习算法能够更有征对性,特别是如果你的数据集有一些很高很瘦的对象,比如说行人,还有像汽车这样很宽的对象,这样你的算法就能更有针对性的处理,这样有一些输出单元可以针对检测很宽很胖的对象,比如说车子,然后输出一些单元,可以针对检测很高很瘦的对象,比如说行人。
最后,你应该怎么选择 anchor box 呢?人们一般手工指定 anchor box 形状,你可以选择 5 到 10 个 anchor box 形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,我就简单说一句,你们如果接触过一些机器学习,可能知道后期 YOLO 论文中有更好的做法,就是所谓的 k-平均算法,可以将两类对象形状聚类,如果我们用它来选择一组 anchor box,选择最具有代表性的一组 anchor box,可以代表你试图检测的十几个对象类别,但这其实是自动选择 anchor box 的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做。
第二十七节,IOU和非极大值抑制的更多相关文章
- IOU和非极大值抑制
如何判断对象检测算法运作良好呢? 一.交并比(Intersection over union,IoU) 是产生的候选框(candidate bound)与原标记框(ground truth bound ...
- IoU与非极大值抑制(NMS)的理解与实现
1. IoU(区域交并比) 计算IoU的公式如下图,可以看到IoU是一个比值,即交并比. 在分子中,我们计算预测框和ground-truth之间的重叠区域: 分母是并集区域,或者更简单地说,是预测框和 ...
- Pytorch从0开始实现YOLO V3指南 part4——置信度阈值和非极大值抑制
本节翻译自:https://blog.paperspace.com/how-to-implement-a-yolo-v3-object-detector-from-scratch-in-pytorch ...
- 非极大值抑制(Non-Maximum Suppression,NMS)
概述 非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索.这个局部代表的是一个邻域,邻域有两个参数可变,一是邻域的维数,二 ...
- 非极大值抑制(NMS)
转自:https://www.cnblogs.com/makefile/p/nms.html 概述 非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的 ...
- 非极大值抑制Non-Maximum Suppression(NMS)
非极大值抑制(Non-Maximum Suppression,NMS) 概述 非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局 ...
- NMS(Non-Maximum Suppression) 非极大值抑制
NMS 非极大值抑制:找到局部最大值,并删除邻域内其他的值. 简单说一下流程: 首先剔除背景(背景无需NMS),假设有6个边界框,根据分类置信度对这6个边界框做降序排列,假设顺序为A.B.C.D.E ...
- 目标检测,主要问题发展,非极大值抑制中阈值也作为参数去学习更满足end2end,最近发展趋势和主要研究思路方向
目标检测,主要问题发展,非极大值抑制中阈值也作为参数去学习更满足end2end,最近发展趋势和主要研究思路方向 待办 目标检测问题时间线 特征金字塔加滑窗 对象框推荐 回归算法回归对象框 多尺度检测 ...
- Non-Maximum Suppression,NMS非极大值抑制
Non-Maximum Suppression,NMS非极大值抑制概述非极大值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极大值的元素,可以理解为局部最大搜索. ...
随机推荐
- 如何在mac下安装php
步骤如下: 1.下载php源码并解压 2.进入php源码并configure 3.安装openssl 4.sudo make及make test 5.sudo make install 具体命令如下: ...
- SQL 添加索引
使用CREATE 语句创建索引 CREATE INDEX index_name ON table_name(column_name,column_name) include(score) 普通索引 C ...
- react事件绑定,事件传参,input单向数据绑定
import React, { Component } from 'react'; class New extends Component { constructor(props){ super(pr ...
- Microsoft Azure Tutorial: Build your first movie inventory web app with just a few lines of code
Editor’s Note: The following is a guest post from Mustafa Mahmutović, a Microsoft Student Partner wh ...
- bzoj1206-[HNOI2005]虚拟内存
卡读的毒瘤题== 看懂之后用map模拟.或者线段树 #include<cstdio> #include<iostream> #include<cmath> #inc ...
- Centos安装python3
安装环境 系统:阿里云服务器centos7.5系统 看见好多博客对centos安装python3的方式各不相同且都不完整,今天我来完整的演示安装python3 1.下载python3源码包 命令 wg ...
- u盘中毒,启动显示找不到指定模块
u盘中毒,插入电脑,启动显示找不到指定模块,关闭杀毒软件还是这样: 小编经常是在学校教室的电脑上插入U盘再拔出就出现这样的情况,遇到N次了, 所以决定把方法记录下来: (演示使用的是win10系统,其 ...
- [Codeforces261D]Maxim and Increasing Subsequence——树状数组+DP
题目链接: Codeforces261D 题目大意:$k$次询问,每次给出一个长度为$n$的序列$b$及$b$中的最大值$maxb$,构造出序列$a$为$t$个序列$b$连接而成,求$a$的最长上升子 ...
- 洛谷P1007独木桥题解
题目 这个题看起来很难,但是只要理解了题目,一切都显得简单. 你只需想象出来每个人在碰撞之后仅仅是交换了灵魂, 这样一来,代码就好写了. 附代码: #include<iostream> # ...
- [USACO12MAR] 花盆Flowerpot
类型:二分+单调队列 传送门:>Here< 题意:给出$N$个点的坐标,要求根据$x$轴选定一段区间$[L,R]$,使得其中的点的最大与最小的$y$值之差$\geq D$.求$Min\{R ...