Scrapy爬取猫眼《复仇者联盟4终局之战》影评
一.分析
首先简单介绍一下Scrapy的基本流程: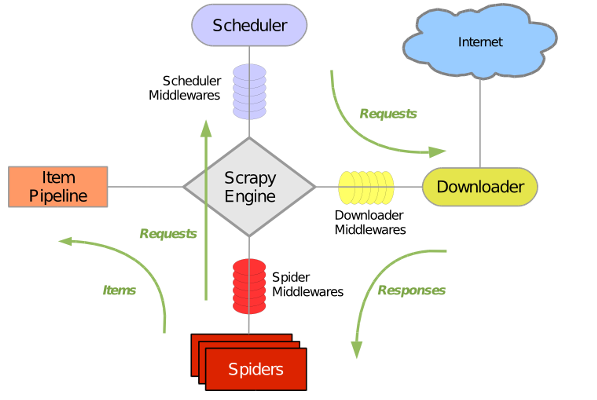
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
在网上找到了接口:http://m.maoyan.com/mmdb/comments/movie/248172.json?_v_=yes&offset=0&startTime=2019-02-05%2020:28:22,可以把offset的值设定为0,通过改变startTime的值来获取更
多的评论信息(把每页评论数据中最后一次评论时间作为新的startTime并构造url重新请求)(startTime=2019-02-05%2020:28:22这里的%20表示空格)
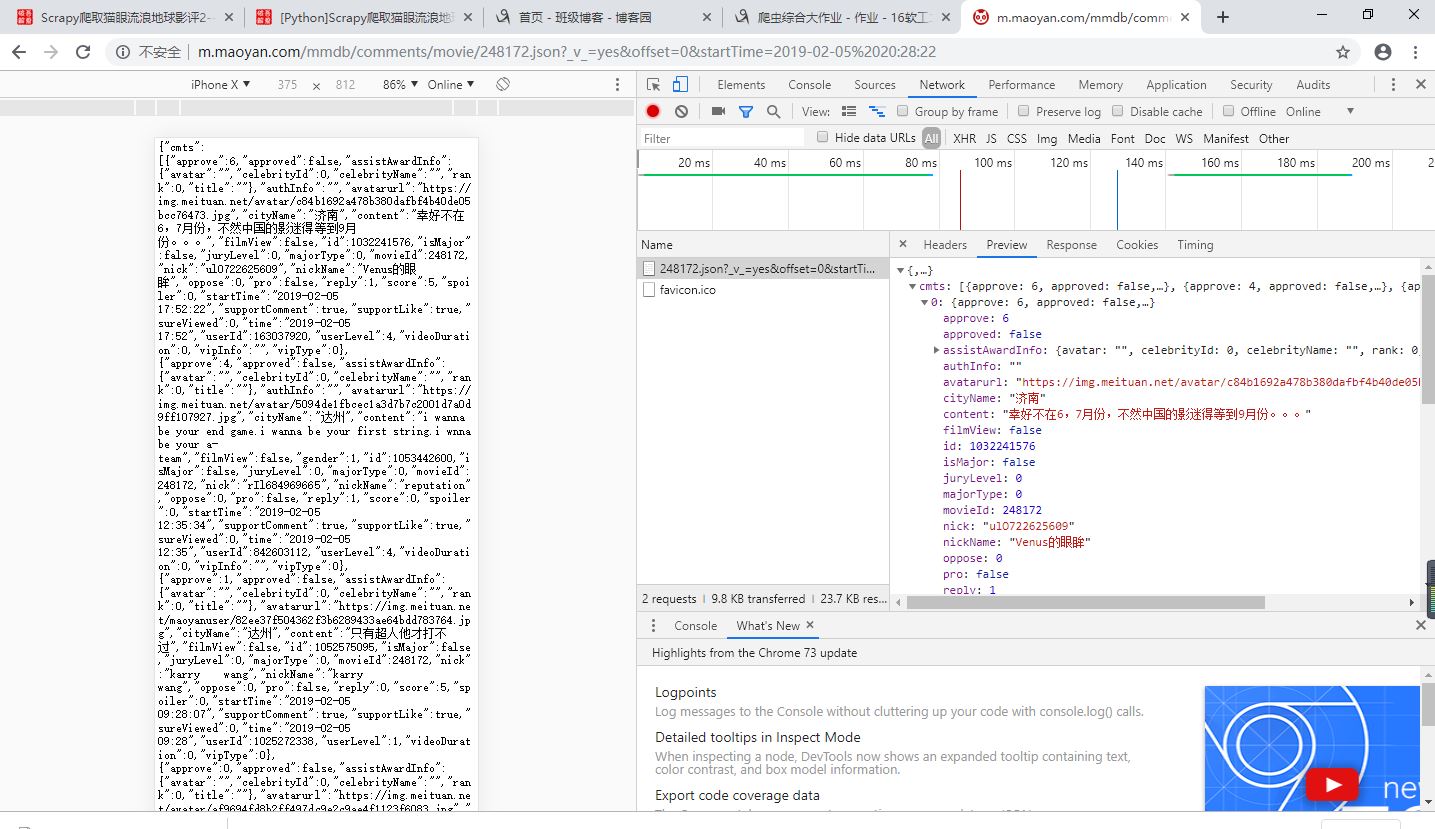
二.主要代码
items.py
import scrapy class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
city = scrapy.Field() # 城市
content = scrapy.Field() # 评论
user_id = scrapy.Field() # 用户id
nick_name = scrapy.Field() # 昵称
score = scrapy.Field() # 评分
time = scrapy.Field() # 评论时间
user_level = scrapy.Field() # 用户等级
comment.py
import scrapy
import random
from scrapy.http import Request
import datetime
import json
from maoyan.items import MaoyanItem class CommentSpider(scrapy.Spider):
name = 'comment'
allowed_domains = ['maoyan.com']
uapools = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB7.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.472.33 Safari/534.3 SE 2.X MetaSr 1.0',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.41 Safari/535.1 QQBrowser/6.9.11079.201',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E) QQBrowser/6.9.11079.201',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0'
]
thisua = random.choice(uapools)
header = {'User-Agent': thisua}
current_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
current_time = '2019-04-24 18:50:22'
end_time = '2019-04-24 00:05:00' # 电影上映时间
url = 'http://m.maoyan.com/mmdb/comments/movie/248172.json?_v_=yes&offset=0&startTime=' +current_time.replace(' ','%20') def start_requests(self):
current_t = str(self.current_time)
if current_t > self.end_time:
try:
yield Request(self.url, headers=self.header, callback=self.parse)
except Exception as error:
print('请求1出错-----' + str(error))
else:
print('全部有关信息已经搜索完毕') def parse(self, response):
item = MaoyanItem()
data = response.body.decode('utf-8', 'ignore')
json_data = json.loads(data)['cmts']
count = 0
for item1 in json_data:
if 'cityName' in item1 and 'nickName' in item1 and 'userId' in item1 and 'content' in item1 and 'score' in item1 and 'startTime' in item1 and 'userLevel' in item1:
try:
city = item1['cityName']
comment = item1['content']
user_id = item1['userId']
nick_name = item1['nickName']
score = item1['score']
time = item1['startTime']
user_level = item1['userLevel']
item['city'] = city
item['content'] = comment
item['user_id'] = user_id
item['nick_name'] = nick_name
item['score'] = score
item['time'] = time
item['user_level'] = user_level
yield item
count += 1
if count >= 15:
temp_time = item['time']
current_t = datetime.datetime.strptime(temp_time, '%Y-%m-%d %H:%M:%S') + datetime.timedelta(
seconds=-1)
current_t = str(current_t)
if current_t > self.end_time:
url1 = 'http://m.maoyan.com/mmdb/comments/movie/248172.json?_v_=yes&offset=0&startTime=' + current_t.replace(
' ', '%20')
yield Request(url1, headers=self.header, callback=self.parse)
else:
print('全部有关信息已经搜索完毕')
except Exception as error:
print('提取信息出错1-----' + str(error))
else:
print('信息不全,已滤除')
pipelines文件
import pandas as pd
class MaoyanPipeline(object):
def process_item(self, item, spider):
dict_info = {'city': item['city'], 'content': item['content'], 'user_id': item['user_id'],
'nick_name': item['nick_name'],
'score': item['score'], 'time': item['time'], 'user_level': item['user_level']}
try:
data = pd.DataFrame(dict_info, index=[0]) # 为data创建一个表格形式 ,注意加index = [0]
data.to_csv('G:\info.csv', header=False, index=True, mode='a',
encoding='utf_8_sig') # 模式:追加,encoding = 'utf-8-sig'
except Exception as error:
print('写入文件出错-------->>>' + str(error))
else:
print(dict_info['content'] + '---------->>>已经写入文件')
最后爬完的数据12M左右,65000条数据左右
三.数据可视化
1.主要代码
用到的模块:pandas数据处理,matplotlib绘图,jieba分词,wordcloud词云,地图相关模块(echarts-countries-pypkg,echarts-china-provinces-pypkg, echarts-china-cities-pypkg)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pandas as pd
from collections import Counter
from pyecharts import Geo, Bar, Scatter
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
import time #观众地域图中部分注释
#attr:标签名称(地点)
#value:数值
#visual_range:可视化范围
#symbol_size:散点的大小
#visual_text_color:标签颜色
#is_visualmap:是否映射(数量与颜色深浅是否挂钩)
#maptype:地图类型 #读取csv文件(除了词云,其它图表用的源数据)
def read_csv(filename, titles):
comments = pd.read_csv(filename, names = titles, low_memory = False) return comments #词云用的源数据(比较小)
def read_csv1(filename1, titles):
comments = pd.read_csv(filename1, names = titles, low_memory = False) return comments #全国观众地域分布
def draw_map(comments):
attr = comments['city_name'].fillna('zero_token') #以'zero_token'代替缺失数据
data = Counter(attr).most_common(300) #Counter统计各个城市出现的次数,返回前300个出现频率较高的城市
# print(data)
data.remove(data[data.index([(i,x) for i,x in data if i == 'zero_token'][0])]) #检索城市'zero_token'并移除('zero_token', 578)
geo =Geo('《复联4》全国观众地域分布', '数据来源:Mr.W', title_color = '#fff', title_pos = 'center', width = 1000, height = 600, background_color = '#404a59')
attr, value = geo.cast(data) #data形式[('合肥',229),('大连',112)]
geo.add('', attr, value, visual_range = [0, 4500], maptype = 'china', visual_text_color = '#fff', symbol_size = 10, is_visualmap = True)
geo.render('G:\\影评\\观众地域分布-地理坐标图.html')
print('全国观众地域分布已完成') #观众地域排行榜单
def draw_bar(comments):
data_top20 = Counter(comments['city_name']).most_common(20) #前二十名城市
bar = Bar('《复联4》观众地域排行榜单', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data_top20)
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 4500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众地域排行榜单-柱状图.html')
print('观众地域排行榜单已完成') #观众评论数量与日期的关系
#必须统一时间格式,不然时间排序还是乱的
def draw_data_bar(comments):
time1 = comments['time']
time_data = []
for t in time1:
if pd.isnull(t) == False and 'time' not in t: #如果元素不为空
date1 = t.replace('/', '-')
date2 = date1.split(' ')[0]
current_time_tuple = time.strptime(date2, '%Y-%m-%d') #把时间字符串转化为时间类型
date = time.strftime('%Y-%m-%d', current_time_tuple) #把时间类型数据转化为字符串类型
time_data.append(date)
data = Counter(time_data).most_common() #data形式[('2019/2/10', 44094), ('2019/2/9', 43680)]
data = sorted(data, key = lambda data : data[0]) #data1变量相当于('2019/2/10', 44094)各个元组 itemgetter(0)
bar =Bar('《复联4》观众评论数量与日期的关系', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data) #['2019/2/10', '2019/2/11', '2019/2/12'][44094, 38238, 32805]
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 3500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众评论日期-柱状图.html')
print('观众评论数量与日期的关系已完成') #观众评论数量与时间的关系
#这里data中每个元组的第一个元素要转化为整数型,不然排序还是乱的
def draw_time_bar(comments):
time = comments['time']
time_data = []
real_data = []
for t in time:
if pd.isnull(t) == False and ':' in t:
time = t.split(' ')[1]
hour = time.split(':')[0]
time_data.append(hour)
data = Counter(time_data).most_common()
for item in data:
temp1 = list(item)
temp2 = int(temp1[0])
temp3 = (temp2,temp1[1])
real_data.append(temp3)
data = sorted(real_data, key = lambda x : x[0])
bar = Bar('《复联4》观众评论数量与时间的关系', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data)
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 3500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众评论时间-柱状图.html')
print('观众评论数量与时间的关系已完成') #词云,用一部分数据生成,不然数据量有些大,会报错MemoryError(64bit的python版本不会)
def draw_word_cloud(comments):
data = comments['comment']
comment_data = []
print('由于数据量比较大,分词这里有些慢,请耐心等待')
for item in data:
if pd.isnull(item) == False:
comment_data.append(item)
comment_after_split = jieba.cut(str(comment_data), cut_all = False)
words = ' '.join(comment_after_split)
stopwords = STOPWORDS.copy()
stopwords.update({'电影', '非常', '这个', '那个', '因为', '没有', '所以', '如果', '演员', '这么', '那么', '最后', '就是', '不过', '这个', '一个', '感觉', '这部', '虽然', '不是', '真的', '觉得', '还是', '但是'})
wc = WordCloud(width = 800, height = 600, background_color = '#000000', font_path = 'simfang', scale = 5, stopwords = stopwords, max_font_size = 200)
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off')
plt.savefig('G:\\影评\\WordCloud.png')
plt.show() #观众评分排行榜单
def draw_score_bar(comments):
score_list = []
data_score = Counter(comments['score']).most_common()
for item in data_score:
if item[0] != 'score':
score_list.append(item)
data = sorted(score_list, key = lambda x : x[0])
bar = Bar('《复联4》观众评分排行榜单', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data)
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 4500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众评分排行榜单-柱状图.html')
print('观众评分排行榜单已完成') #观众用户等级排行榜单
def draw_user_level_bar(comments):
level_list = []
data_level = Counter(comments['user_level']).most_common()
for item in data_level:
if item[0] != 'user_level':
level_list.append(item)
data = sorted(level_list, key = lambda x : x[0])
bar = Bar('《复联4》观众用户等级排行榜单', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data)
# is_more_utils = True 提供更多的实用工具按钮
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 4500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众用户等级排行榜单-柱状图.html')
print('观众用户等级排行榜单已完成') if __name__ == '__main__':
filename = 'G:\\info.csv'
filename2 = 'G:\\info.csv'
titles = ['city_name','comment','user_id','nick_name','score','time','user_level']
comments = read_csv(filename, titles)
comments2 = read_csv1(filename2, titles)
draw_map(comments)
draw_bar(comments)
draw_data_bar(comments)
draw_time_bar(comments)
draw_word_cloud(comments2)
draw_score_bar(comments)
draw_user_level_bar(comments)
2.效果与分析
01.观众地域分布-地理坐标图
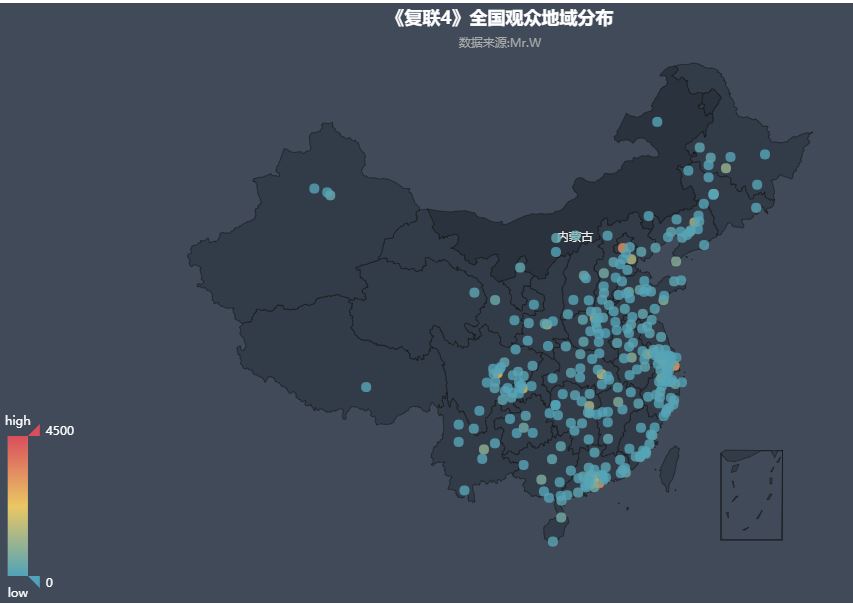
由全国地域热力图可见,观众主要分布在中部,南部,东部以及东北部,各省会城市的观众尤其多(红色代表观众最多),这与实际的经济、文化、消费水平基本相符.(ps:复联4的票价有点贵)
02.《复联4》观众地域排行榜单
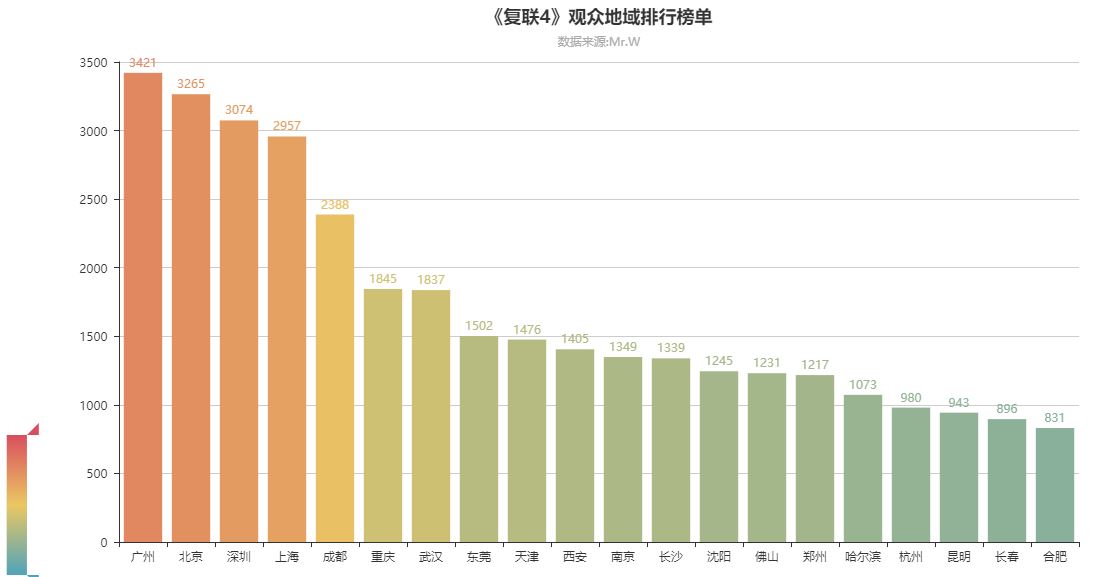
北上广深等一线城市,观众粉丝多,消费水平可以。观影数量非常多。
03.《复联4》观众评分排行榜单
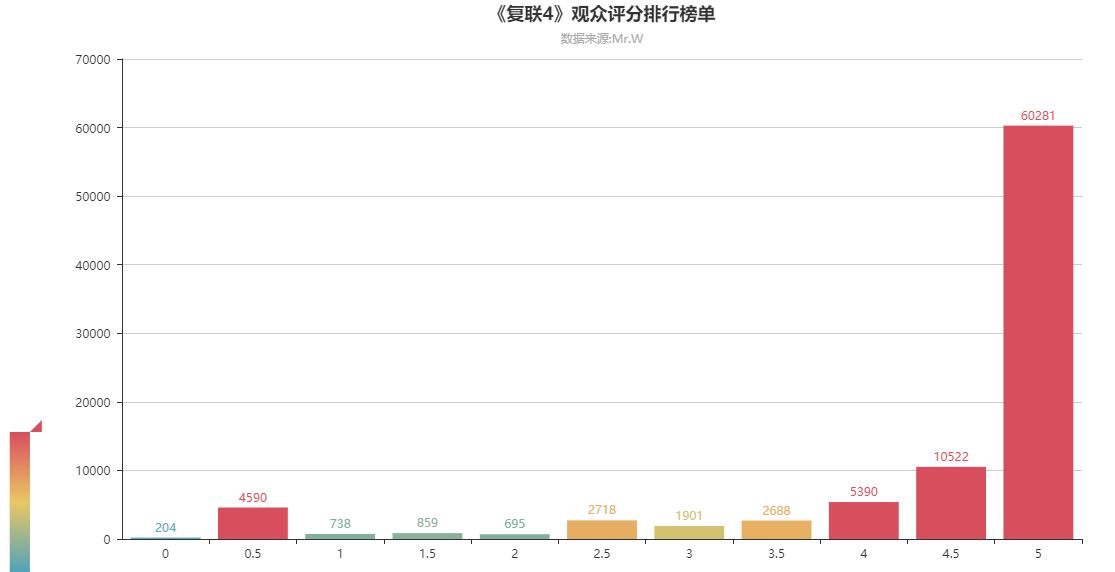
可以看到评分满分的用户几乎超过总人数的70%,可见观众看完电影之后很满足,也说明了电影的可看性很高
04.《复联4》观众评论数量与日期的关系
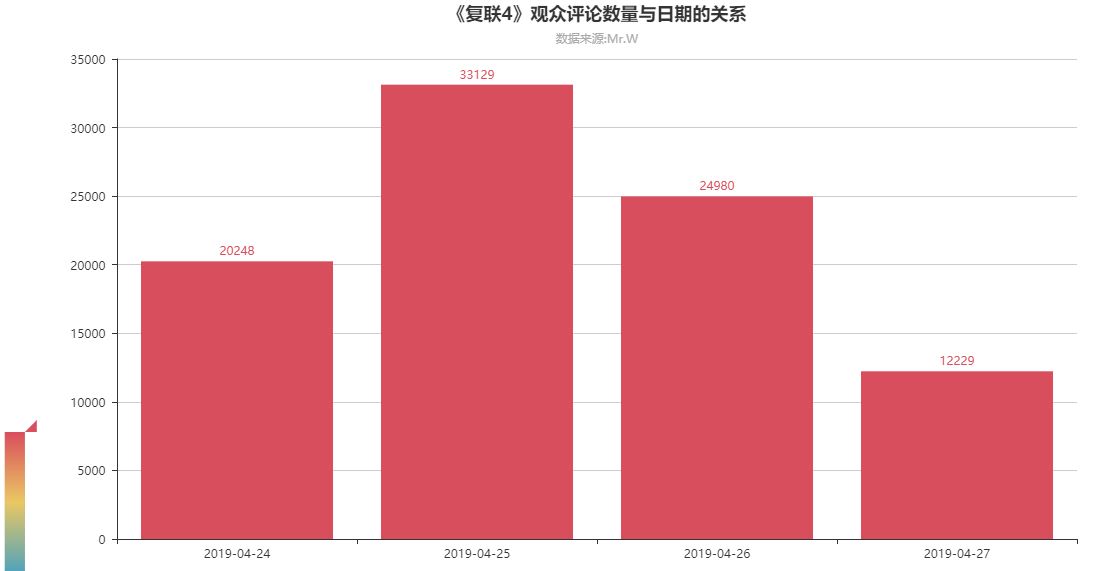
24号上映到现在已经三天,其中观影人数最多的是25号,可能大家觉得首映有点小贵吧,哈哈。
05.《复联4》观众评论数量与时间的关系
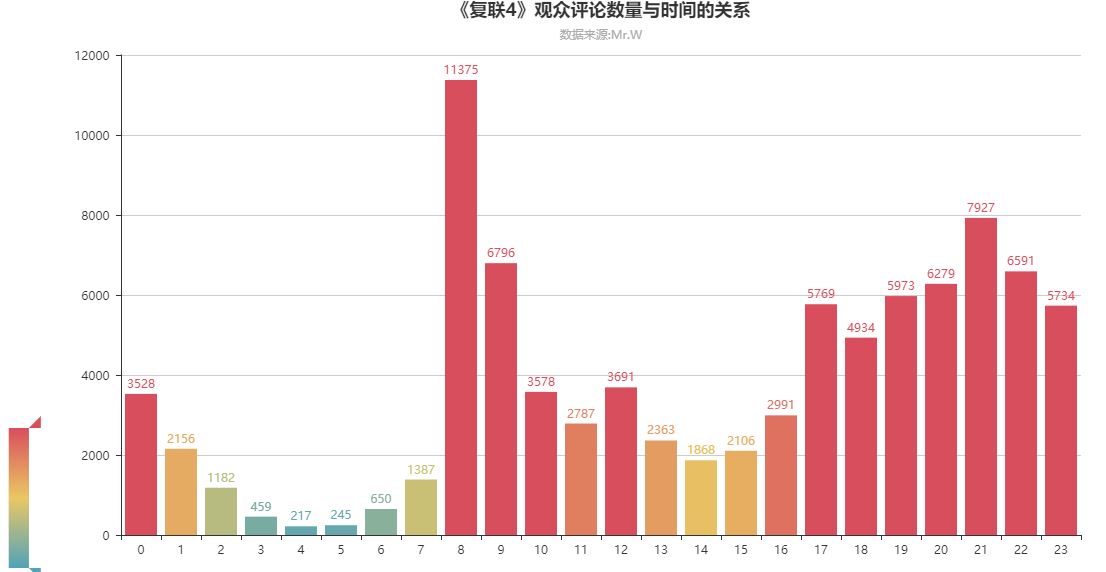
从图中可以看出,评论的数量主要集中在16-23点,因为这部电影时长为2小时,所以把评论时间往前移动2小时基本就是看电影时间。可以看出大家都是中午吃完饭(13点左右)和晚上吃完饭(19点左右)后再去看电影的,而且晚上看电影的人更多
06.《复联4》观众用户等级排行榜单
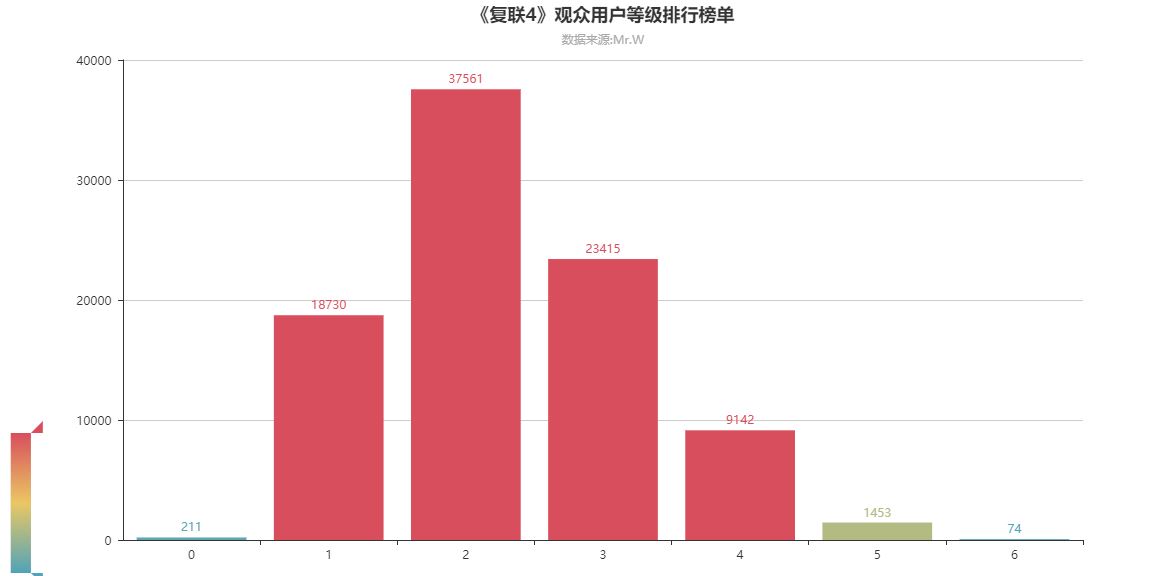
可见用户等级为0,5,6的用户基本没有,而且随着等级的提升,人数急剧变少。新用户可能是以年轻人为主,对科幻电影感兴趣,因而评论数量较多,而老用户主要偏向于现实剧情类的电影,评论数量较少
07.《复联4》词云图

在词云图中可以看到,“好看,可以,完美,精彩,情怀”等字眼,看来影片还是挺好看的。接着就是“钢铁侠,美队,灭霸”看来这几个人在影评中有重要的故事线。
Scrapy爬取猫眼《复仇者联盟4终局之战》影评的更多相关文章
- scrapy爬取猫眼电影排行榜
做爬虫的人,一定离不开的一个框架就是scrapy框架,写小项目的时候可以用requests模块就能得到结果,但是当爬取的数据量大的时候,就一定要用到框架. 下面先练练手,用scrapy写一个爬取猫眼电 ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- scrapy-redis分布式爬取猫眼电影
能够利用redis缓存数据库的优点去重来避免数据的大面积冗余 1.首先就是要创建猫眼爬虫项目 2.进入项目内部创建一个爬虫文件 创建完文件之后就是要爬取的内容,我这边以爬取猫眼电影的title和lin ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- scrapy爬取极客学院全部课程
# -*- coding: utf-8 -*- # scrapy爬取极客学院全部课程 import scrapy from pyquery import PyQuery as pq from jike ...
随机推荐
- Layout-2相关代码:3列布局代码演化[一]
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- for update 与where current of的问题
在刚学oracle时一直不明白for update 的作用,今天考试又遇到郁闷半天,所以加以整理. 一: 1>首先for update是对表的行进行锁定.锁定就好比我们学java Thread那 ...
- 三、CSS样式——列表
概念: CSS列表属性允许你放置.改变列表标志,或者将图像作为列表项标志 属性 描述 list-style 简写列表项 list-style-image 列表项图像 list-style-positi ...
- [Vue warn]: Duplicate keys detected: '1'. This may cause an update error
今天遇到这个问题,遇到这个问题多数因为:key值的问题 第一种情况(key重复) <div class="name-list" v-for="(item,index ...
- jmeter多sql查询
背景:实现多条sql语句,取多个值的情况 步骤:1.JDBC Connection Configuration配置添加?allowMultiQueries=true 2.增加sql语句 ,查询或修改语 ...
- Redis Sentinel实现高可用配置
一般情况下yum安装redis的启动目录在:”/usr/sbin” :配置目录在”/etc/redis/”在其目录下会有默认的redis.conf和redis-sentinel.conf redis高 ...
- ajax调用.net API项目跨域问题解决
ajax调用.net API项目,经常提示跨域问题.添加如下节点代码解决:httpProtocol <system.webServer> <handlers> <remo ...
- QT与opencv(二)开启摄像头
OpenCV中的VideoCapture不仅可以打开视频.usb摄像头,还可以做很多事,例如读取流媒体文件,网络摄像头,图像序列等. 下面我简单介绍一个在Qt中用VideoCapture类打开笔记本电 ...
- spring boot项目配置跨域
1.在项目启动入口类实现 WebMvcConfigurer 接口: @SpringBootApplication public class Application implements WebMvcC ...
- Xcode中编译iOS程序,运行出错:Thread 1: signal SIGABRT
添加一个全局Exception Breakpoint 就检测出来了 导航栏里面 Debug 菜单里面