如何定位那些SQL产生了大量的redo日志
在ORACLE数据库的管理、维护过程中,偶尔会遇到归档日志暴增的情况,也就是说一些SQL语句产生了大量的redo log,那么如何跟踪、定位哪些SQL语句生成了大量的redo log日志呢? 下面这篇文章结合实际案例和官方文档“How to identify the causes of High Redo Generation (文档 ID 2265722.1)”来实验验证一下。
首先,我们需要定位、判断那个时间段的日志突然暴增了,注意,有些时间段生成了大量的redo log是正常业务行为,有可能每天这个时间段都有大量归档日志生成,例如,有大量作业在这个时间段集中运行。 而要分析突然、异常的大量redo log生成情况,就必须有数据分析对比,找到redo log大量产生的时间段,缩小分析的范围是第一步。合理的缩小范围能够方便快速准确定位问题SQL。下面SQL语句分别统计了redo log的切换次数的相关数据指标。这个可以间接判断那个时间段产生了大量归档日志。
/******统计每天redo log的切换次数汇总,以及与平均次数的对比*****/
WITH T AS
(
SELECT TO_CHAR(FIRST_TIME, 'YYYY-MM-DD') AS LOG_GEN_DAY,
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME, 'YYYY-MM-DD'),
TO_CHAR(FIRST_TIME, 'YYYY-MM-DD'), 1, 0))
, '999') AS "LOG_SWITCH_NUM"
FROM V$LOG_HISTORY
WHERE FIRST_TIME < TRUNC(SYSDATE) --排除当前这一天
GROUP BY TO_CHAR(FIRST_TIME, 'YYYY-MM-DD')
)
SELECT T.LOG_GEN_DAY
, T.LOG_SWITCH_NUM
, M.AVG_LOG_SWITCH_NUM
, (T.LOG_SWITCH_NUM-M.AVG_LOG_SWITCH_NUM) AS DIFF_SWITCH_NUM
FROM T CROSS JOIN
(
SELECT TO_CHAR(AVG(T.LOG_SWITCH_NUM),'999') AS AVG_LOG_SWITCH_NUM
FROM T
) M
ORDER BY T.LOG_GEN_DAY DESC;
SELECT TO_CHAR(FIRST_TIME,'YYYY-MM-DD') DAY,
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'00',1,0)),'999') "00",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'01',1,0)),'999') "01",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'02',1,0)),'999') "02",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'03',1,0)),'999') "03",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'04',1,0)),'999') "04",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'05',1,0)),'999') "05",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'06',1,0)),'999') "06",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'07',1,0)),'999') "07",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'08',1,0)),'999') "08",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'09',1,0)),'999') "09",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'10',1,0)),'999') "10",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'11',1,0)),'999') "11",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'12',1,0)),'999') "12",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'13',1,0)),'999') "13",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'14',1,0)),'999') "14",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'15',1,0)),'999') "15",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'16',1,0)),'999') "16",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'17',1,0)),'999') "17",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'18',1,0)),'999') "18",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'19',1,0)),'999') "19",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'20',1,0)),'999') "20",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'21',1,0)),'999') "21",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'22',1,0)),'999') "22",
TO_CHAR(SUM(DECODE(TO_CHAR(FIRST_TIME,'HH24'),'23',1,0)),'999') "23"
FROM V$LOG_HISTORY
GROUP BY TO_CHAR(FIRST_TIME,'YYYY-MM-DD')
ORDER BY 1 DESC;
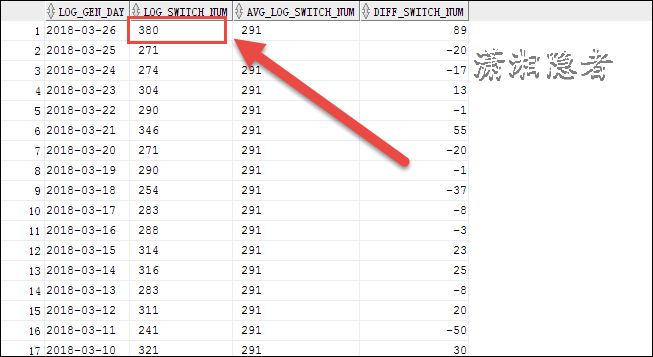
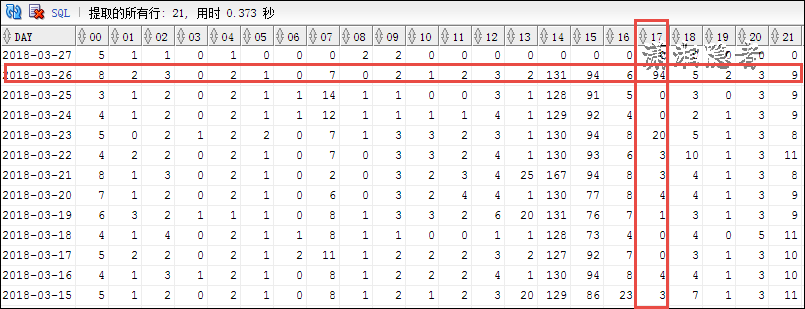
如下案例所示,2018-03-26日有一个归档日志暴增的情况,我们可以横向、纵向对比分析,然后判定在17点到18点这段时间出现异常,这个时间段与往常对比,生成了大量的redo log。
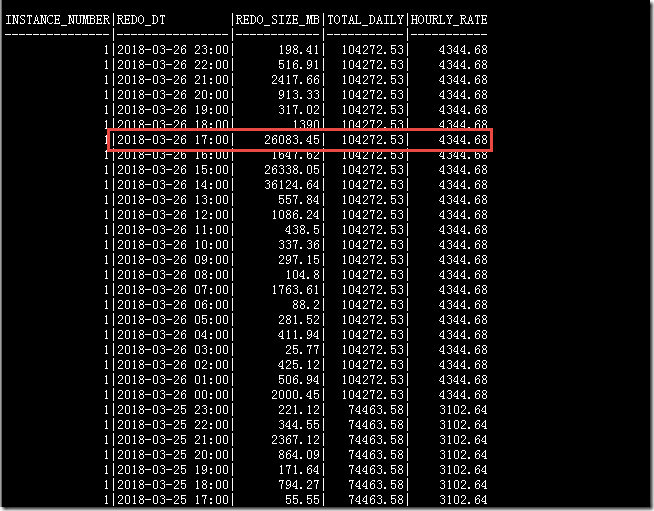
这里分享一个非常不错的分析redo log 历史信息的SQL
------------------------------------------------------------------------------------------------
REM Author: Riyaj Shamsudeen @OraInternals, LLC
REM www.orainternals.com
REM
REM Functionality: This script is to print redo size rates in a RAC claster
REM **************
REM
REM Source : AWR tables
REM
REM Exectution type: Execute from sqlplus or any other tool.
REM
REM Parameters: No parameters. Uses Last snapshot and the one prior snap
REM No implied or explicit warranty
REM
REM Please send me an email to rshamsud@orainternals.com, if you enhance this script :-)
REM This is a open Source code and it is free to use and modify.
REM Version 1.20
REM
------------------------------------------------------------------------------------------------
set colsep '|'
set lines 220
alter session set nls_date_format='YYYY-MM-DD HH24:MI';
set pagesize 10000
with redo_data as (
SELECT instance_number,
to_date(to_char(redo_date,'DD-MON-YY-HH24:MI'), 'DD-MON-YY-HH24:MI') redo_dt,
trunc(redo_size/(1024 * 1024),2) redo_size_mb
FROM (
SELECT dbid, instance_number, redo_date, redo_size , startup_time FROM (
SELECT sysst.dbid,sysst.instance_number, begin_interval_time redo_date, startup_time,
VALUE -
lag (VALUE) OVER
( PARTITION BY sysst.dbid, sysst.instance_number, startup_time
ORDER BY begin_interval_time ,sysst.instance_number
) redo_size
FROM sys.wrh$_sysstat sysst , DBA_HIST_SNAPSHOT snaps
WHERE sysst.stat_id =
( SELECT stat_id FROM sys.wrh$_stat_name WHERE stat_name='redo size' )
AND snaps.snap_id = sysst.snap_id
AND snaps.dbid =sysst.dbid
AND sysst.instance_number = snaps.instance_number
AND snaps.begin_interval_time> sysdate-30
ORDER BY snaps.snap_id )
)
)
select instance_number, redo_dt, redo_size_mb,
sum (redo_size_mb) over (partition by trunc(redo_dt)) total_daily,
trunc(sum (redo_size_mb) over (partition by trunc(redo_dt))/24,2) hourly_rate
from redo_Data
order by redo_dt, instance_number
/
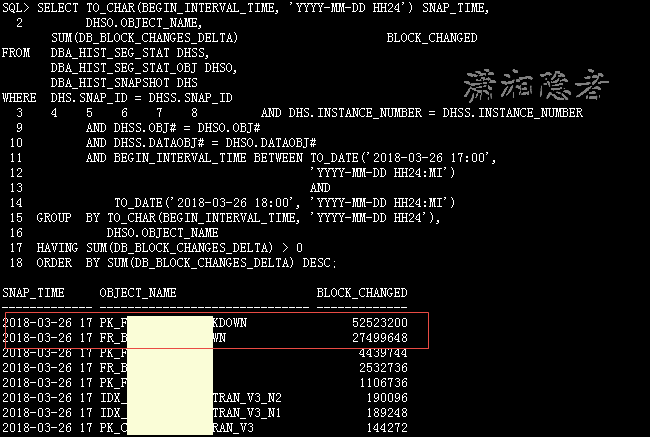
分析到这个阶段,我们还只获取了那个时间段归档日志异常(归档日志暴增),那么要如何定位到相关的SQL语句呢?我们可以用下面SQL来定位:在这个时间段,哪些对象有大量数据块变化情况。如下所示,这两个对象(当然,对象有可能是表或索引,这个案例中,这两个对象其实是同一个表和其主键索引)有大量的数据块修改情况。基本上我们可以判断是涉及这个对象的DML语句生成了大量的redo log, 当然有可能有些场景会比较复杂,不是那么容易定位。
SELECT TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24') SNAP_TIME,
DHSO.OBJECT_NAME,
SUM(DB_BLOCK_CHANGES_DELTA) BLOCK_CHANGED
FROM DBA_HIST_SEG_STAT DHSS,
DBA_HIST_SEG_STAT_OBJ DHSO,
DBA_HIST_SNAPSHOT DHS
WHERE DHS.SNAP_ID = DHSS.SNAP_ID
AND DHS.INSTANCE_NUMBER = DHSS.INSTANCE_NUMBER
AND DHSS.OBJ# = DHSO.OBJ#
AND DHSS.DATAOBJ# = DHSO.DATAOBJ#
AND BEGIN_INTERVAL_TIME BETWEEN TO_DATE('2018-03-26 17:00',
'YYYY-MM-DD HH24:MI')
AND
TO_DATE('2018-03-26 18:00', 'YYYY-MM-DD HH24:MI')
GROUP BY TO_CHAR(BEGIN_INTERVAL_TIME, 'YYYY-MM-DD HH24'),
DHSO.OBJECT_NAME
HAVING SUM(DB_BLOCK_CHANGES_DELTA) > 0
ORDER BY SUM(DB_BLOCK_CHANGES_DELTA) DESC;
此时,我们可以生成这个时间段的AWR报告,那些产生大量redo log的SQL一般是来自TOP Gets、TOP Execution中某个DML SQL语句或一些DML SQL语句,结合上面SQL定位到的对象和下面相关SQL语句,基本上就可以判断就是下面这两个SQL产生了大量的redo log。(第一个SQL是调用包,包里面有对这个表做大量的DELETE、INSERT操作)
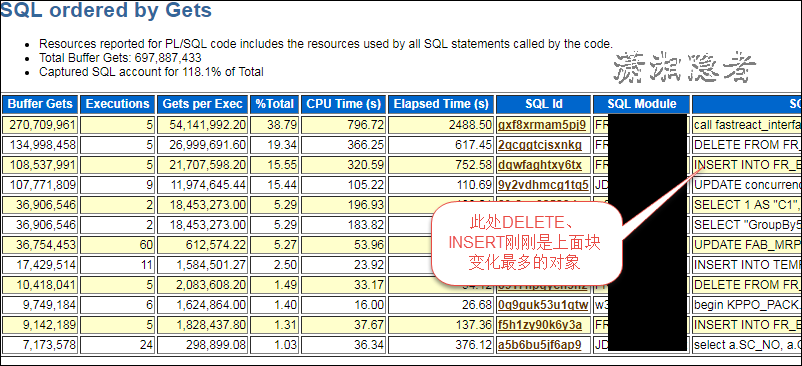
如果你此时还不能完全断定,也可以使用下面SQL来辅佐判断那些SQL生成了大量的redo log。 在这个案例中, 上面AWR报告中发现的SQL语句和下面SQL捕获的SQL基本一致。那么可以进一步佐证。
注意,该SQL语句执行较慢,执行时需要修改相关条件:时间和具体段对象。
SELECT TO_CHAR(BEGIN_INTERVAL_TIME,'YYYY_MM_DD HH24') WHEN,
DBMS_LOB.SUBSTR(SQL_TEXT,4000,1) SQL,
DHSS.INSTANCE_NUMBER INST_ID,
DHSS.SQL_ID,
EXECUTIONS_DELTA EXEC_DELTA,
ROWS_PROCESSED_DELTA ROWS_PROC_DELTA
FROM DBA_HIST_SQLSTAT DHSS,
DBA_HIST_SNAPSHOT DHS,
DBA_HIST_SQLTEXT DHST
WHERE UPPER(DHST.SQL_TEXT) LIKE '%<segment_name>%' --此处用具体的段对象替换
AND LTRIM(UPPER(DHST.SQL_TEXT)) NOT LIKE 'SELECT%'
AND DHSS.SNAP_ID=DHS.SNAP_ID
AND DHSS.INSTANCE_NUMBER=DHS.INSTANCE_NUMBER
AND DHSS.SQL_ID=DHST.SQL_ID
AND BEGIN_INTERVAL_TIME BETWEEN TO_DATE('2018-03-26 17:00','YYYY-MM-DD HH24:MI')
AND TO_DATE('2018-03-26 18:00','YYYY-MM-DD HH24:MI')
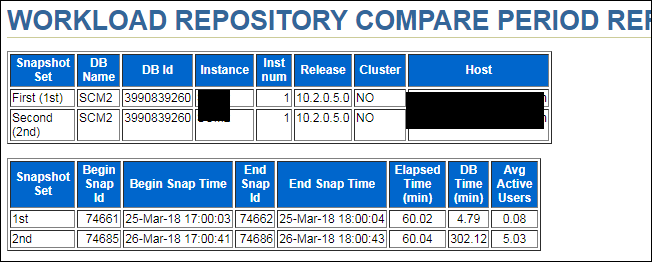
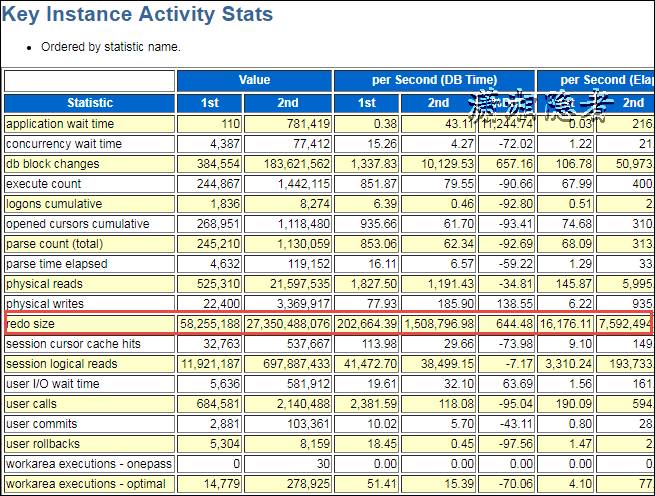
其实上面分析已经基本完全定位到SQL语句,剩下的就是和开发人员或Support人员沟通、了解是正常业务逻辑变更还是异常行为。如果需要进一步挖掘深入,我们可以使用日志挖掘工具Log Miner深入分析。在此不做展开分析。 其实个人在判断分析时生成了正常时段和出现问题时段的AWR对比报告(WORKLOAD REPOSITORY COMPARE PERIOD REPORT),如下所示,其中一些信息也可以供分析、对比参考。可以为复杂场景做对比分析(因为复杂场景,仅仅通过最上面的AWR报告可能无法准确定位SQL)
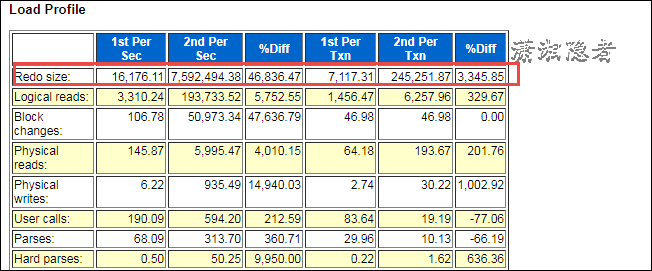
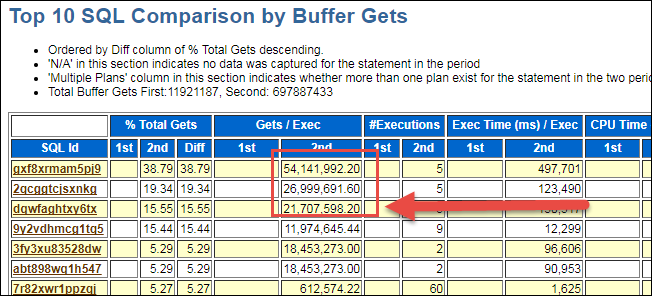
此次截图,没有截取相关SQL,其实就是最上面分析的SQL语句,如果复杂场景下,非常有用。
参考资料:
How to identify the causes of High Redo Generation (文档 ID 2265722.1)
如何定位那些SQL产生了大量的redo日志的更多相关文章
- MySQL如何定位慢sql
MySQL如何定位慢sql MySQL"慢SQL"定位 数据库调优我个人觉得必须要明白两件事 1.定位问题(你得知道问题出在哪里,要不然从哪里调优呢) 2.解决问题(这个没有基本的 ...
- sql server 2008中清除数据库日志的sql语句
第一步: Use 数据库名 Select NAME,size From sys.database_files 将“数据库名”改为需要清除日志的数据库名字,点击“执行”查询出需要清除的日志名称:**_ ...
- 2. SQL Server数据库状态监控 - 错误日志
原文:2. SQL Server数据库状态监控 - 错误日志 无论是操作系统 (Unix 或者Windows),还是应用程序 (Web 服务,数据库系统等等) ,通常都有自身的日志机制,以便故障时追溯 ...
- SQL Server 2005/2008压缩数据库日志的方法
适用于SQL Server 2005的方法 Backup Log DNName WITH no_log GO DUMP TRANSACTION DNName WITH no_log GO USE DN ...
- sql服务器第5级事务日志管理的阶梯:完全恢复模式下的日志管理
sql服务器第5级事务日志管理的阶梯:完全恢复模式下的日志管理 原文链接http://www.sqlservercentral.com/articles/Stairway+Series/73785/ ...
- perl 分析binlog 定位错误sql 思路
1. 获取需要的binlog 日志: [root@zjzc01 binlog]# mysqlbinlog --start-datetime='2016-08-01 00:00:00' --stop-d ...
- 快速定位MS Sql Server 数据库死锁进程
最近在做一个大型项目,由于数据设计采用离散型数据库设计,以方便需求变更及用户自定义流程要素,因为要素用户自定义,数据完整性靠代码约束变得不太现实,只能依靠表间关系来约束,结果因此导致数据的操作经常产生 ...
- mysql版本,根据经纬度定位排序sql
SELECT id,lng,lat,ROUND(6378.138*2*ASIN(SQRT(POW(SIN((lat1*PI()/180-lat*PI()/180)/2),2)+COS(lat1*PI( ...
- sql server 备份与恢复系列二 事务日志概述
1.1 日志文件与数据文件一致性 在上一章备份与恢复里了解到事务日志的重要性,这篇重点来了解事务日志. 事务日志记录了数据库所有的改变,能恢复该数据库到改变之前的任意状态.在sql server实例 ...
随机推荐
- mysql 开发基础系列19 触发器
触发器是与表有关的数据库对象,触发器只能是针对创建的永久表,而不能是临时表. 1.1 创建触发器 -- 语法: CREATE TRIGGER trigger_name trigger_time tri ...
- java~springboot~h2数据库在单元测试中的使用
单元测试有几点要说的 事实上springboot框架是一个tdd框架,你在进行建立项目时它会同时建立一个单元测试项目,而我们的代码用例可以在这个项目里完成,对于单元测试大叔有以下几点需要说明一下: 单 ...
- Salesforce Sales Cloud 零基础学习(一) Product 和 Price Book
以前的博客大部分都是基于force.com以及lightning展开的自定义开发,其实salesforce提供了很多的标准的功能以及平台, Sales Cloud便是作为Salesforce核心的平台 ...
- java与json,一篇就够了
本示例使用的json包为阿里的fastjson 首先写三个工具类(seter和geter方法省略,自行补上): /** * 屏幕实体类 */ public class Screen { private ...
- 痞子衡嵌入式:开源软件协议(MIT/BSD/Apache/LGPL/MPL/GPL)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家讲的是关于开源软件协议基本知识. 牛顿曾说过:"如果我比别人看得更远,那是因为我站在巨人的肩上".在软件开发中如果说也存在巨 ...
- Nacos系列:Nacos的Java SDK使用
Maven依赖 Nacos提供完整的Java SDK,便于配置管理和服务发现及管理,以 Nacos-0.8.0 版本为例 添加Maven依赖: <dependency> <group ...
- [转]bitcoin: 通过 rpc 请求节点数据
本文转自:https://laravel-china.org/index.php/articles/8919/bitcoin-requests-node-data-through-rpc 文章来自本人 ...
- .net 模拟登陆 post https 请求跳转页面
AllowAutoRedirect property is true, the Referer property is set automatically when the request is re ...
- C#操作DataReader类
一.常用属性 名称 说明 Depth 获取一个值,用于指示当前行的嵌套深度 FieldCount 获取当前行中的列数 HasRows 获取一个值,该值指示 SqlDataReader 是否有行 IsC ...
- SpringBoot2.0 redis生成组建和读写配置文件
@Component 生成组建 @ConfigurationProperties(prefix="redis") 读写redis配置文件 application.propertie ...