分库分表之后全局id怎么生成
数据库自增id:
这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id。拿到这个id之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单;缺点就是单库生成自增id,要是高并发的话,就会有瓶颈的;
适合的场景:你分库分表就俩原因,要不就是单库并发太高,要不就是单库数据量太大;除非是你并发不高,但是数据量太大导致的分库分表扩容,你可以用这个方案,因为可能每秒最高并发最多就几百,那么就走单独的一个库和表生成自增主键即可。
uuid:
好处就是本地生成,不要基于数据库来了;不好之处就是,uuid太长了,作为主键性能太差了,不适合用于主键。
适合的场景:如果你是要随机生成个什么文件名了,编号之类的,你可以用uuid,但是作为主键是不能用uuid的。
获取系统当前时间:
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,订单编号,时间戳 + 用户id + 业务含义编码
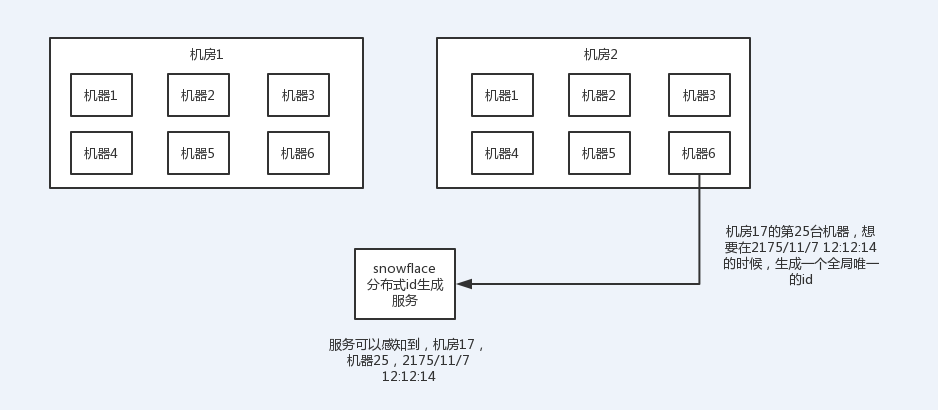
snowflake算法:
twitter开源的分布式id生成算法,就是把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号
1 bit:不用,为啥呢?因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0
41 bit:表示的是时间戳,单位是毫秒。41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间。
10 bit:记录工作机器id,代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器。但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。
12 bit:这个是用来记录同一个毫秒内产生的不同id,12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
64位的long型的id,64位的long -> 二进制
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 11001 | 0000 00000000
转自:中华石杉Java工程师面试突击
分库分表之后全局id怎么生成的更多相关文章
- 分库分表之后全局id咋生成?
1.面试题 分库分表之后,id主键如何处理? 2.面试官心里分析 其实这是分库分表之后你必然要面对的一个问题,就是id咋生成?因为要是分成多个表之后,每个表都是从1开始累加,那肯定不对啊,需要一个全局 ...
- SpringBoot 使用Sharding-JDBC进行分库分表及其分布式ID的生成
为解决关系型数据库面对海量数据由于数据量过大而导致的性能问题时,将数据进行分片是行之有效的解决方案,而将集中于单一节点的数据拆分并分别存储到多个数据库或表,称为分库分表. 分库可以有效分散高并发量,分 ...
- 分布式中的分库分表之后,ID 主键如何处理?
面试题 分库分表之后,id 主键如何处理?(唯一性,排序等) 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定 ...
- 面试官:分库分表之后,id 主键如何处理?
面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全 ...
- 分库分表之后,id 主键如何处理?
其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持.所以这都是你实际生产环境中必须考虑的 ...
- 分库分表之后,id 主键如何处理
基于数据库的实现方案 数据库自增 id 这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id.拿到这个 id 之后再往对应的分 ...
- 面试系列38 分库分表之后,id主键如何处理?
(1)数据库自增id 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案 ...
- 分库分表之后,id主键如何处理?
(1)数据库自增id 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
随机推荐
- python 实现神经网络算法
注: Scratch是一款由麻省理工学院(MIT) 设计开发的一款面向少年的简易编程工具.这里写链接内容 本文翻译自“IMPLEMENTING A NEURAL NETWORK FRO ...
- 【转】python模块分析之logging日志(四)
[转]python模块分析之logging日志(四) python的logging模块是用来写日志的,是python的标准模块. 系列文章 python模块分析之random(一) python模块分 ...
- 【转】Git超实用总结,再也不怕记忆力不好了
[转]Git超实用总结,再也不怕记忆力不好了 欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯工蜂发表于云+社区专栏 Git 是什么? Git 是一个分布式的代码管理容器,本地和 ...
- c++学习day2
1. 输入输出 1)控制符 2) 如果要读取所有输入的字符,包括空格和回车,可以有如下两种方法,其中EOF在windows里默认是 ctrl+Z 注:输入字符时,scanf不会跳过空格,输入其他类型数 ...
- Ajax 执行顺序
jQuery中各个事件执行顺序如下: 1.ajaxStart(全局事件) 2.beforeSend 3.ajaxSend(全局事件) 4.success 5.ajaxSuccess(全局事件) 6.e ...
- inode索引详解
理解inode inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础. 我觉得,理解inode,不仅有助于提高系统操作水平,还有助于体会Unix设计哲学,即如何把底层的复杂性抽 ...
- 玩转 lua in Redis
一.引言 Redis学了一段时间了,基本的东西都没问题了.从今天开始讲写一些redis和lua脚本的相关的东西,lua这个脚本是一个好东西,可以运行在任何平台上,也可以嵌入到大多数语言当中,来扩展其功 ...
- 洛谷P4705 玩游戏 [生成函数,NTT]
传送门 这是两个月之前写的题,但没写博客.现在回过头来看一下发现又不会了-- 还是要写博客加深记忆. 思路 显然期望可以算出总数再乘上\((nm)^{-1}\). 那么有 \[ \begin{alig ...
- js——class基础
js的类?其实还是原型! class Point{ constructor(x, y){ this.x = x; this.y = y; } toString(){ return '(' + this ...
- 在Ubuntu 15下搭建V/P/N服务器pptpd安装和配置
在Ubuntu 15下搭建VPN服务器pptpd安装和配置 在ubuntu下配置vpn的方式有很多种,其中比较常见的是pptpd,它配置简单,但是安全性不高,不过对于一般使用来说足够了,我按照程搭建了 ...