MHA高可用
MHA(Master High Availability)目前在 MySQL 高可用方面是一个相对成熟的解决方案,它由
日本 DeNA 公司 youshimaton(现就职于 Facebook 公司)开发,是一套优秀的作为 MySQL
高可用性环境下故障切换和主从提升的高可用软件。在 MySQL 故障切换过程中, MHA 能做
到在 0~30 秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中, MHA 能
在最大程度上保证数据的一致性,以达到真正意义上的高可用。
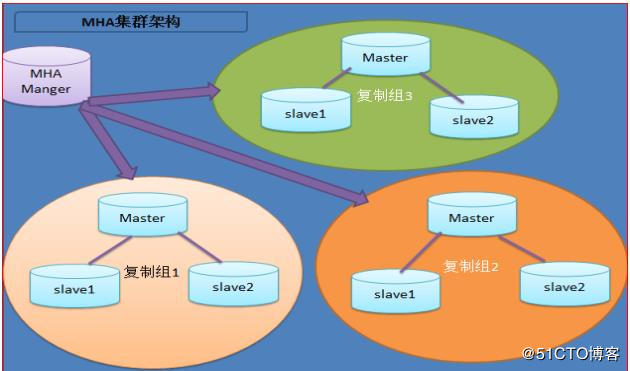
MHA 里有两个角色一个是 MHA Node(数据节点) 另一个是 MHA Manager(管理节点)。
MHA Manager 可以单独部署在一台独立的机器上管理多个 master-slave 集群,也可以部署在
一台 slave 节点上。 MHA Node 运行在每台 MySQL 服务器上, MHA Manager 会定时探测集群
中的 master节点,当 master出现故障时,它可以自动将最新数据的 slave提升为新的 master,
然后将所有其他的 slave 重新指向新的 master。整个故障转移过程对应用程序完全透明。
在 MHA 自动故障切换过程中, MHA 试图从宕机的主服务器上保存二进制日志,最大程度的
保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过 ssh 访
问, MHA 没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用 MySQL 5.5 的
半同步复制,可以大大降低数据丢失的风险。 MHA 可以与半同步复制结合起来。如果只有
一个 slave 已经收到了最新的二进制日志, MHA 可以将最新的二进制日志应用于其他所有的
slave 服务器上,因此可以保证所有节点的数据一致性。
注: 从 MySQL5.5 开始, MySQL 以插件的形式支持半同步复制。如何理解半同步呢?首先我
们来看看异步,全同步的概念:
异步复制(Asynchronous replication)
MySQL 默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客
户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果 crash 掉了,此时
主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上
的数据不完整。
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有
从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
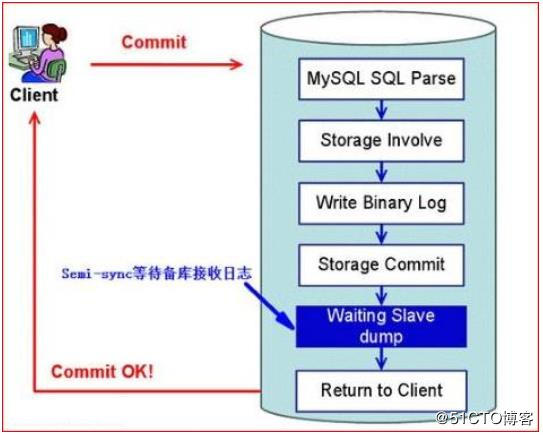
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到 relay log 中才返回给客户端。相对于异步复制,半同步
复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个 TCP/IP
往返的时间。所以,半同步复制最好在低延时的网络中使用。
下面来看看半同步复制的原理图:
总结: 异步与半同步异同
默认情况下 MySQL 的复制是异步的, Master 上所有的更新操作写入 Binlog 之后并不确保所
有的更新都被复制到 Slave 之上。异步操作虽然效率高,但是在 Master/Slave 出现问题的时
候,存在很高数据不同步的风险,甚至可能丢失数据。
MySQL5.5 引入半同步复制功能的目的是为了保证在 master 出问题的时候,至少有一台 Slave
的数据是完整的。在超时的情况下也可以临时转入异步复制,保障业务的正常使用,直到一
台 salve 追赶上之后,继续切换到半同步模式。
工作原理
相较于其它 HA 软件, MHA 的目的在于维持 MySQL Replication 中 Master 库的高可用性,其
最大特点是可以修复多个 Slave 之间的差异日志,最终使所有 Slave 保持数据一致,然后从
中选择一个充当新的 Master,并将其它 Slave 指向它。
-从宕机崩溃的 master 保存二进制日志事件(binlogevents)。
-识别含有最新更新的 slave。
-应用差异的中继日志(relay log)到其它 slave。
-应用从 master 保存的二进制日志事件(binlogevents)。
-提升一个 slave 为新 master。
-使其它的 slave 连接新的 master 进行复制。
目前 MHA 主要支持一主多从的架构, 要搭建 MHA,要求一个复制集群中必须最少有三台数
据库服务器, 一主二从,即一台充当 master,一台充当备用 master,另外一台充当从库,因为至少需要三台服务器。
接下来部署 MHA,具体的搭建环境如下
| 角色 | IP地址 | 主机名 | server-id | 类型 |
| Manager | 192.168.41.10 | centos1 | 节点管理 | |
| Master | 192.168.41.11 | centos2 | 1 | 主mysql(write) |
| Candicate\Master | 192.168.41.12 | centos3 | 2 | 从(read) |
| Slave | 192.168.41.13 | centos4 | 3 | 从(read) |
其中 master 对外提供写服务,备选 master(实际的 slave,主机名 centos3)提供读服务, slave
也提供相关的读服务,一旦 master 宕机,将会把备选 master 提升为新的 master, slave 指向
新的 master, manager 作为管理服务器。
一、基础环境准备
1、 在配置好 IP 地址后检查 selinux, iptables 设置, 关闭 selinux , iptables 服务以便后期主
从同步不出错
注:时间要同步
2、 在四台机器都配置 epel 源
#rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
3、 建立 ssh 无交互登录环境
在所有主机ssh-keygen -t rsa
在所有主机把公钥传给对方 for i in centos1 centos1 centos2 centos3 centos4;do ssh-copy-id -i ~/.ssh/id_rsa.pub $i;done
二、 配置 mysql 半同步复制
为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置 MHA 的同时建议配置成
MySQL 的半同步复制。
注: mysql 半同步插件是由谷歌提供,具体位置/usr/local/mysql/lib/plugin/下,一个是 master
用的 semisync_master.so,一个是 slave 用的 semisync_slave.so,下面我们就来具体配置一下。
如果不清楚 Plugin 的目录,用如下查找:
mysql> mysql> show variables%plugin_dir%';
+---------------+------------------------------+
| Variable_name | Value |
+---------------+------------------------------+
| plugin_dir | /usr/local/mysql/lib/plugin/ |
+---------------+------------------------------+
1 row in set (0.00 sec)
1、 分别在主从节点上安装相关的插件(master, Candicate master,slave)
在 MySQL 上安装插件需要数据库支持动态载入。检查是否支持,用如下检测:
mysql> show variables like '%have_dynamic_loading%';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| have_dynamic_loading | YES |
+----------------------+-------+
1 row in set (0.00 sec)
所有 mysql 数据库服务器,安装半同步插件(semisync_master.so,semisync_slave.so)
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.07 sec)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.03 sec)
其他 mysql 主机采用同样的方法安装
检查 Plugin 是否已正确安装:
mysql> show plugins;
或
mysql> select * from information_schema.plugins;
查看半同步相关信息
mysql> show variables like '%rpl_semi_sync%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | OFF |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32 |
+-------------------------------------------+------------+
8 rows in set (0.00 sec)
上图可以看到半同复制插件已经安装,只是还没有启用,所以是 off
2、 修改 my.cnf 文件,配置主从同步:
注: 若主 MYSQL 服务器已经存在,只是后期才搭建从 MYSQL 服务器,在置配数据同步前应
先将主 MYSQL 服务器的要同步的数据库拷贝到从 MYSQL 服务器上(如先在主 MYSQL 上备
份数据库,再用备份在从 MYSQL 服务器上恢复)
master mysql 主机:
server-id =
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
rpl_semi_sync_master_enabled=
rpl_semi_sync_master_timeout=
rpl_semi_sync_slave_enabled=
relay_log_purge=
relay-log = relay-bin
relay-log-index = slave-relay-bin.index 注:
rpl_semi_sync_master_enabled=1 1 表是启用, 0 表示关闭
rpl_semi_sync_master_timeout=10000: 毫秒单位 , 该参数主服务器等待确认消息 10 秒后,
不再等待,变为异步方式。
Candicate master 主机:
server-id =
log-bin=mysql-bin
binlog_format=mixed
log-bin-index=mysql-bin.index
relay_log_purge=
relay-log = relay-bin
relay-log-index = slave-relay-bin.index
rpl_semi_sync_master_enabled=
rpl_semi_sync_master_timeout=
rpl_semi_sync_slave_enabled= 注: relay_log_purge=,禁止 SQL 线程在执行完一个 relay log 后自动将其删除, 对于 MHA
场景下,对于某些滞后从库的恢复依赖于其他从库的 relay log,因此采取禁用自动删除功能
Slave 主机:
Server-id =
log-bin = mysql-bin
relay-log = relay-bin
relay-log-index = slave-relay-bin.index
read_only =
rpl_semi_sync_slave_enabled=
查看半同步相关信息
mysql>show variables like ‘%rpl_semi_sync%’;
查看半同步状态:
mysql>show status like ‘%rpl_semi_sync%’;
有几个状态参数值得关注的:
rpl_semi_sync_master_status :显示主服务是异步复制模式还是半同步复制模式
rpl_semi_sync_master_clients :显示有多少个从服务器配置为半同步复制模式
rpl_semi_sync_master_yes_tx :显示从服务器确认成功提交的数量
rpl_semi_sync_master_no_tx :显示从服务器确认不成功提交的数量
rpl_semi_sync_master_tx_avg_wait_time :事务因开启 semi_sync ,平均需要额外等待的时间
rpl_semi_sync_master_net_avg_wait_time :事务进入等待队列后,到网络平均等待时间
master 主机:
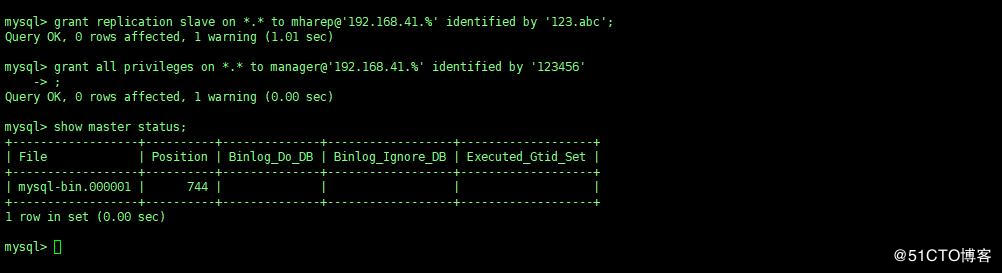
第一条 :grant 命令是创建一个用于主从复制的帐号,在 master 和 candicate master 的主机上创建即可。
第二条 :grant 命令是创建 MHA 管理账号, 所有 mysql 服务器上都需要执行。 MHA 会在配置
文件里要求能远程登录到数据库,所以要进行必要的赋权。
Candicate master 主机:
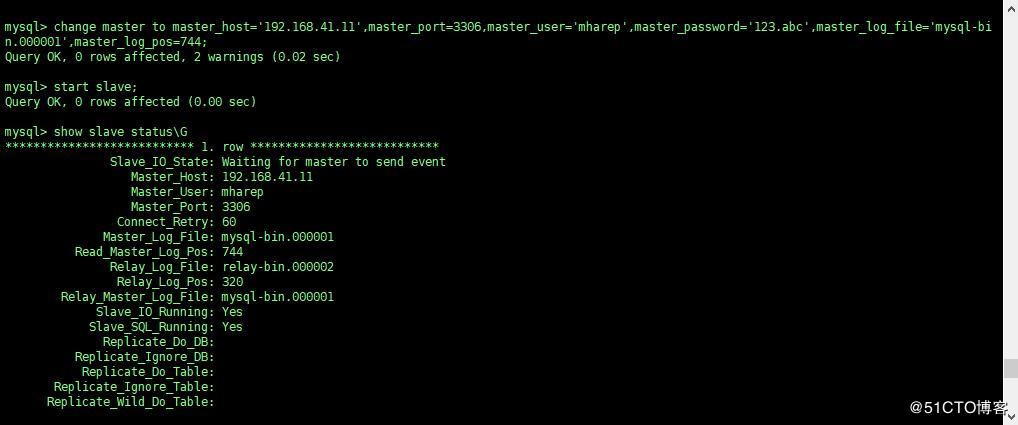
查看从的状态,以下两个值必须为 yes,代表从服务器能正常连接主服务器
Slave_IO_Running:Yes
Slave_SQL_Running:Yes
Slave 主机:

查看从的状态,以下两个值必须为 yes,代表从服务器能正常连接主服务器
Slave_IO_Running:Yes
Slave_SQL_Running:Yes
查看 master 服务器的半同步状态:
mysql>show status like ‘%rpl_semi_sync%’;

三、配置 mysql-mha
mha 包括 manager 节点和 data 节点, data 节点包括原有的 MySQL 复制结构中的主机,至少
3台,即 1主 2从,当 masterfailover后,还能保证主从结构;只需安装 node包。manager server:
运行监控脚本,负责 monitoring 和 auto-failover;需要安装 node 包和 manager 包。
1、 在所有主机上安装 mha 所依赖的软件包(需要系统自带的 yum 源并联网)
#yum -y install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager
perl-Config-IniFiles ncftp perl-Params-Validate perl-CPAN perl-Test-Mock-LWP.noarch
perl-LWP-Authen-Negotiate.noarch perl-devel perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker
2、 以下操作管理节点需要两个都安装, 在 3 台数据库节点只要安装 MHA 的 node 节点:
在所有数据库节点上安装 mha4mysql-node-0.56.tar.gz
其他两个数据节点也安装 mha4mysql-node-0.56.tar.gz(过程略)
在管理节点需要两个都安装: mha4mysql-node-0.56.tar.gz 和 mha4mysql-manager-0.56.tar.gz
安装 mha4mysql-node-0.56.tar.gz
tar xzf mha4mysql-node-0.56.tar.gz
tar xzf mha4mysql-manager-0.56.tar.gz
cd mha4mysql-node-0.56/
perl Makefile.PL
make && make install
cd ../mha4mysql-manager-0.56/
perl Makefile.PL
make && make install
根据提示输入
[root@centos1 mha4mysql-manager-0.56]# mkdir /etc//masterha
[root@centos1 mha4mysql-manager-0.56]# mkdir -p /etc//masterha/app1
[root@centos1 mha4mysql-manager-0.56]# mkdir /scripts
[root@centos1 mha4mysql-manager-0.56]# cp samples/conf/ /etc/masterha/
[root@centos1 mha4mysql-manager-0.56]# cp samples/scripts/ /scripts/
3、 配置 mha
与绝大多数 Linux 应用程序类似, MHA 的正确使用依赖于合理的配置文件。 MHA 的配置文
件与 mysql 的 my.cnf 文件配置相似,采取的是 param=value 的方式来配置,配置文件位于管
理节点,通常包括每一个 mysql server 的主机名, mysql 用户名,密码,工作目录等等。
编辑/etc/masterha/app1.cnf,内容如下:

#> /etc/masterha/masterha_default.cnf
配关配置项的解释:
manager_workdir=/masterha/app1 //设置 manager 的工作目录
manager_log=/masterha/app1/manager.log //设置 manager 的日志
user=manager //设置监控用户 manager
password= //监控用户 manager 的密码
ssh_user=root //ssh 连接用户
repl_user=mharep //主从复制用户
repl_password=.abc //主从复制用户密码
ping_interval= //设置监控主库,发送 ping 包的时间间隔, 默认是 3 秒,尝试三次没有回
应的时候自动进行 railover
master_binlog_dir=/usr/local/mysql/data //设置 master 保存 binlog 的位置,以便 MHA 可
以找到 master 的日志,我这里的也就是 mysql 的数据目录
candidate_master= //设置为候选 master,如果设置该参数以后,发生主从切换以后将会
将此从库提升为主库。
SSH 有效性验证:
集群复制的有效性验证:
mysql 必须都启动
masterha_check_repl --global_conf=/etc/masterha/masterha_default.cnf --conf=/etc/masterha/app1.cnf
验证成功的话会自动识别出所有服务器和主从状况
注: 验证成功的话会自动识别出所有服务器和主从状况
在验证时, 若遇到这个错误: Can't exec "mysqlbinlog" ......
解决方法是在所有服务器上执行:
ln -s /usr/local/mysql/bin/* /usr/local/bin/
启动 manager:
[root@centos1 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &> /tmp/mha_manager.log &
[1] 51919
注: 在应用 Unix/Linux 时,我们一般想让某个程序在后台运行,于是我们将常会用 & 在程
序结尾来让程序自动运行。 比如我们要运行 mysql 在后台: /usr/local/mysql/bin/mysqld_safe
–user=mysql &。 可是有很多程序并不想 mysqld 一样, 这样我们就需要 nohup 命令,
状态检查:
[root@centos1 masterha]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:52412) is running(0:PING_OK), master:192.168.41.11
故障转移验证: (自动 failover)
master dead 后, MHA 当时已经开启,候选 Master 库(Slave)会自动 failover 为 Master.
验证的方式是先停掉 master(centos2) ,因为之前的配置文件中,把 Candicate
master(centos3)作为了候选人,那么就到 slave(centos4) 上查看 master 的 IP 是否
变为了 centos3 的 IP
1)停掉 master
在 master(192.168.41.11) 上把 mysql 停掉
2)查看 MHA 日志
上面的配置文件中指定了日志位置为 /masterha/app1/manager.log
[root@centos1 ~]# cat /masterha/app1/manager.log
The latest slave 192.168.41.12(192.168.41.12:3306) has all relay logs for recovery.
Selected 192.168.41.12 as a new master.
192.168.41.12: OK: Applying all logs succeeded.
192.168.41.13: This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.41.13: OK: Applying all logs succeeded. Slave started, replicating from 192.168.41.12.
192.168.41.12: Resetting slave info succeeded.
Master failover to 192.168.41.12(192.168.41.12:3306) completed successfully.
从日志信息中可以看到 master failover 已经成功了,并可以看出故障转移的大体流程
3)检查 slave2 的复制
登录 slave(192.168.41.13) 的 Mysql, 查看 slave 状态
mysql> show slave status\G;
1. row
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.41.12
Master_User: mharep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 744
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
可以看到 master 的 IP 现在为 192.168.41.12, 已经切换到和 192.168.41.12 同步了, 本来是
和 192.168.41.11 同步的, 说明 MHA 已经把 Candicate master(centos2) 提升为了新的
master, IO 线程和 SQL 线程也正确运行, MHA 搭建成功
MHA Manager 端日常主要操作步骤
1) 检查是否有下列文件,有则删除。
发生主从切换后, MHAmanager 服务会自动停掉,且在 manager_workdir(/masterha/app1)
目录下面生成文件 app1.failover.complete,若要启动 MHA,必须先确保无此文件)
如果有这个提示,那么删除此文件/ masterha/app1/app1.failover.complete
[error][/usr/share/perl5/vendor_perl/MHA/MasterFailover.pm, ln298] Last failover was done at
2015/01/09 10:00:47. Current time is too early to do failover again. If you want to do failover,
manually remove / masterha/app1/app1.failover.complete and run this script again.
#ll /masterha/app1/app1.failover.complete
#ll /masterha/app1/app1.failover.error
2) 检查 MHA 复制检查:(需要把 master 设置成 candicatade 的从服务器)
mysql> change master to master_host='192.168.41.12',master_port=3306,master_user='mharep',master_password='123.abc',master_log_file='mysql-binn.000001',master_log_pos=744;
Query OK, 0 rows affected, 2 warnings (0.00 sec)
#masterha_check_repl --conf=/etc/masterha/app1.cnf
3) 停止 MHA: masterha_stop --conf=/etc/masterha/app1.cnf
4) 启动 MHA:
#nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/tmp/mha_manager.log &
当有 slave 节点宕掉时,默认是启动不了的,加上 --ignore_fail_on_start 即使有节点宕掉也
能启动 MHA,如下:
#nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_fail_on_start
&>/tmp/mha_manager.log &
5) 检查状态:
#masterha_check_status --conf=/etc/masterha /app1.cnf
6) 检查日志:#tail -f /masterha/app1/manager.log
7) 主从切换后续工作
重构:
重构就是你的主挂了, 切换到 Candicate master 上, Candicate master 变成了主, 因此重构的
一种方案原主库修复成一个新的 slave
主库切换后,把原主库修复成新从库,然后重新执行以上 5 步。原主库数据文件完整的情况
下,可通过以下方式找出最后执行的 CHANGE MASTER 命令
[root@centos1 masterha]# grep "CHANGE MASTER TO MASTER" /masterha/app1/manager.log | tail -1
Tue Jul 31 13:56:02 2018 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.41.12', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=744, MASTER_USER='mharep', MASTER_PASSWORD='xxx';
[root@centos1 masterha]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:52789) is running(0:PING_OK), master:192.168.41.12
注意:如果正常,会显示"PING_OK",否则会显示"NOT_RUNNING",这代表 MHA 监控没有
开启。
定期删除中继日志
在配置主从复制中, slave 上设置了参数 relay_log_purge=0,所以 slave 节点需要定期删除中
继日志,建议每个 slave 节点删除中继日志的时间错开。
corntab -e
0 5 * /usr/local/bin/purge_relay_logs - -user=root --password=123456 --port=3306 --disable_relay_log_purge >> /var/log/purge_relay.log 2>&1
MHA高可用的更多相关文章
- 搭建MySQL MHA高可用
本文内容参考:http://www.ttlsa.com/mysql/step-one-by-one-deploy-mysql-mha-cluster/ MySQL MHA 高可用集群 环境: Linu ...
- MHA高可用架构与Atlas读写分离
1.1 MHA简介 1.1.1 MHA软件介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton ...
- Mysql MHA高可用集群架构
** 记得之前发过一篇文章,名字叫<浅析MySQL高可用架构>,之后一直有很多小伙伴在公众号后台或其它渠道问我,何时有相关的深入配置管理文章出来,因此,民工哥,也将对前面的各类架构逐一进行 ...
- MHA 高可用集群搭建(二)
MHA 高可用集群搭建安装scp远程控制http://www.cnblogs.com/kevingrace/p/5662839.html yum install openssh-clients mys ...
- MHA高可用 MHA+Keepalive
MHA高可用 MHA简介 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebo ...
- MySQL for OPS 08:MHA 高可用
写在前面的话 主从架构在一般情况下只能满足我们小公司业务并非一刻都不能中断服务.但是对于大型公司而言,对然数据丢失,数据库挂了,我们可以通过技术找回,修复.但是其中修复过程所消耗的时间是不被允许的.此 ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- MHA高可用配置及故障切换
MHA高可用配置及故障切换 目录 MHA高可用配置及故障切换 一.案例概述 二.案例前置知识点 1. MHA概述 2. MHA的组成 (1)MHA Manager(管理节点) (2)MHA Node( ...
- MySQL mha 高可用集群搭建
[mha] MHA作为MySQL故障切换和主从提升的高可用软件,在故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一 ...
随机推荐
- 如何利用Python实现自动打卡签到
需求描述 我们需要登录考勤系统(网页端,非手机端)进行签到,如果不想每天都早早起来打卡签到,就可以通过写程序实现这一功能. 业务梳理 通过长时间的早起打卡签到发现规律,我每天只是不停的点击,签到,都是 ...
- Minimum setup for Apache+AD SSO
参照: http://www.grolmsnet.de/kerbtut/ https://docs.typo3.org/typo3cms/extensions/ig_ldap_sso_auth/2.1 ...
- jdango
1.jdango的下载 命令行: pip install django ==1.11.18 pip install django ==1.11.18 -i https://pypi.douban.co ...
- 1.1.1 PROB Your Ride Is Here
=== /* ID: luopengting PROG: ride LANG: C++ */ #include <iostream> #include <cstdio> #in ...
- Docker 三剑客之 Docker Compose
Docker Compose 项目是 Docker 官方的开源项目,负责实现对 Docker 容器集群的快速编排,开源地址:https://github.com/docker/compose Dock ...
- SQL Server 深入解析索引存储(聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/堆/聚集索引 概述 最近要分享一个课件就重新把这块知识整理了一遍出来,篇幅有点长,想要理解的透彻还是要上机实践. 聚 ...
- 从零开始单排学设计模式「简单工厂设计模式」黑铁 III
阅读本文大概需要 2 分钟. 本篇是设计模式系列的第二篇,虽然之前也写过相应的文章,但是因为种种原因后来断掉了,而且发现之前写的内容也很渣,不够系统.所以现在打算重写,加上距离现在也有一段时间了,也算 ...
- Drools规则引擎入门指南(一)
最近项目需要增加风控系统,在经过一番调研以后决定使用Drools规则引擎.因为项目是基于SpringCloud的架构,所以此次学习使用了SpringBoot2.0版本结合Drools7.14.0.Fi ...
- [Postman]Postman导航(3)
Postman提供了一个多窗口和多标签界面,供您使用API. 此界面设计为您提供尽可能多的API空间. 侧边栏 邮差侧边栏可让您查找和管理请求和集合.侧边栏有两个主要选项卡: 历史记录 和 ...
- springboot2.0jar包启动异常
今天碰到一个异常: 08:44:07.214 [main] ERROR org.springframework.boot.SpringApplication - Application run fai ...