scala程序开发入门
scala程序开发入门,快速步入scala的门槛:
1、Scala的特性:
A、纯粹面向对象(没有基本类型,只有对象类型)、Scala的安装与JDK相同,只需要解压之后配置环境变量即可;
B、Scala在安装之前必须先安装JDK,因为Scala的编译结果是中间字节码文件,它需要在JVM上运行,Scala可以调用Java类库来完成某些功能;
C、Scala类似于python,一半面向过程一半面向对象,还可以基于shell的命令行进行操作,当然也可以像Java那样先使用scalac编译成中间字节码之后再使用scala解释执行它,注意保存的Scala源文件名称必须以scala作为扩展名,且文件名必须与对象名完全匹配;
D、Scala类似于JS脚本,区分大小写,以换行符为单位来定义语句,但是如果需要在同一行定义多条语句则必须使用分号隔开;
E、执行速度对比:C(C++)>Java(Scala)>Python(Ruby);
F、Scala数据类型:
Byte(1byte)、Short(2byte)、Int(4byte)、Long(8byte)、Float(4byte)、Double(8byte)、Char(2byte)、String(取决于字符数量)、Boolean(1byte)、Unit(相当于void)、Null(相当于null)、Nothing(所有类的子类型)、Any(所有基本类型和引用类型的根类型)、AnyVal(所有基本类型的超类型)、AnyRef(所有引用类型的超类型)。
//null值只能被推断为Null类型,null代表空值,它可以被赋值给任何AnyRef类型的常量或变量
scala> var kk=null
kk: Null = null //定义Boolean类型
scala> val flag=true
flag: Boolean = true //定义Char类型
scala> val flag='A'
flag: Char = A //小数默认推断为Double类型
scala> val height=1.67
height: Double = 1.67 //整数默认推断为Int类型
scala> val age=30
age: Int = 30 //定义字符串类型(字串常量必须使用双引号),显示的结果类型为String,它是java.lang.String的缩写形式
scala> val name="mmzs"
name: String = mmzs //Int类型可以自动向上转型为超类型AnyVal
scala> val age2:AnyVal=age
age2: AnyVal = 30
//String类型为引用类型,不能上转型到AnyVal,因为它们之间没有继承关系
scala> val name2:AnyVal=name
<console>:12: error: the result type of an implicit conversion must be more specific than AnyVal
val name2:AnyVal=name
^
//但是可以自动上转型为超类型AnyRef,因为AnyRef是所有引用类型的超类型
scala> val name2:AnyRef=name
name2: AnyRef = mmzs
//同样的,Int为基本类型,也不能上转型到AnyRef,因为它们之间没有继承关系
scala> val age2:AnyRef=age
<console>:12: error: the result type of an implicit conversion must be more specific than AnyRef
val age2:AnyRef=age
^
//但是所有的基本类型(AnyVal)和引用类型(AnyRef)都可以自动上转型为根类型Any
scala> val kkm:Any=age
kkm: Any = 30
scala> val kkm:Any=name
kkm: Any = mmzs
scala> val kkm:Any=age2
kkm: Any = 100
scala> val kkm:Any=name2
kkm: Any = mmzs
scala>:quit //也可以直接:q
注意:
对任何Scala对象的显式类型定义其前面都有一个以英文冒号作为前缀的类型标注,这是Scala的语法所决定的,如:val abc:Int=123、def getName():String={............}
8中基本类型都是scala核心包中的,scala包相当于Java中的java.lang包
Scala是强类型的语言,并不是弱类型语言,虽然你并没有显式指定变量的类型,但是Scala会根据你赋的值自动进行类型推断,一旦推断出变量的类型,后续使用该变量就必须符合类型兼容原则
定义变量或函数的通式是:val[var|def] varName|funName(...):type=value|{.....}
G、字面常量:
单引号:表示单个字符
双引号:表示字符串
三双引号:表示具备可换行的多行字符串
//三双引号实例
scala> val info="""my name is mmzs
| my age is 30"""
info: String =
my name is mmzs
my age is 30
H、字符串之间以及字符串与变量、表达式之间的拼接直接使用重载的加号("+")
I、Scala中没有static的概念,所有处于object定义对象中的成员都是静态的,入口方法main必须被定义在object定义的类中,同时源文件的名字必须与object定义的对象名同名,一个源文件中可以使用class定义多个类,
也可以使用object定义多个对象,但是作为运行的入口main方法永远都是处于与源文件名相同的对象体内
J、Scala中的所有常量和变量(包括成员常量、变量和局部常量、变量)都必须先定义和初始化然后才能被使用,暂时不能确定值的常量、变量可以被初始化为空值(即0,初始化为0意味着数字类型被赋值为0,字符类型被赋值为空格、布尔类型被赋值为false,引用类型全部被赋值为null),如:
scala> var age:Int=0
age: Int = 0
scala> var height:Double=0
height: Double = 0.0
scala> var code:Char=0
code: Char = ?
scala> var flag:Boolean=false
flag: Boolean = false
scala> var name:String=null
name: String = null
2、基础语法:
A、变量的声明:
//声明变量(变量的值可以被重新赋值以改变它的值)
var VariableName:DataType=Initial Value
//声明常量(常量的值不可以被重新赋值,值不能被改变)
val VariableName:DataType=Initial Value
//val定义的是常量,不能被重新赋值,但是可以使用val重新定义它,如:
scala> val ab=20
ab: Int = 20 //自动推断为Int类型
scala> ab=50 //此处常量ab不能被重新赋值
<console>:12: error: reassignment to val
ab=50
^
scala> val ab=50 //但是可以重新定义该常量
ab: Int = 50 //var定义的是变量,可以被重新赋值,如:
scala> var ab=220
ab: Int = 220
scala> ab=50 //此处ab变量被重新赋值
ab: Int = 50
scala> var ab=50.05 //也可以被重新定义
ab: Double = 50.05 //val与var定义的常量或变量都可以相互被对方重定义,重定义时可以被定义成其它类型
scala> val ab=100
ab: Int = 100
scala> var ab=true
ab: Boolean = true
scala> val ab='A'
ab: Char = A
scala> var ab=45.55
ab: Double = 45.55
scala> ab=true //变量的值可以被重新赋值,但是所赋的值必须与定义该变量时的类型匹配
<console>:12: error: type mismatch;
found : Boolean(true)
required: Double
ab=true
^
scala> ab='A' //隐式将Char类型按ASCII码转换成Double类型,这是符合自动类型转换规则的ab: Double = 65.0
B、变量的类型与赋值表达式
在 Scala 中声明变量和常量不一定要指明数据类型,在没有指明数据类型的情况下,其数据类型是通过变量或常量的初始值来进行推断,可以看出Scala语言实际上是一种强类型的编程语言,Scala声明变量的语法有点类似于JS但与JS也有区别,区别在于JS中的var关键字不是必须的,且JS中的每一个变量可以自由灵活的被赋值为任何类型的值;但是Scala语言中的var或val关键字是必须的,且一旦使用这些关键字定义了变量或常量的类型(根据定义时的初始值进行类型自动推断)之后,后续对该变量的赋值就必须符合类型兼容原则,如果该变量需要被赋值为其它类型则只能使用val或var对其重新定义
var myVar = 10;//声明变量
val myVal = "Hello,Scala!";//声明常量
//以上实例中,myVar 会被推断为Int类型,myVal会被推断为String类型
//使用枚举法同时声明多个相同类型和值的变量
scala> val a,b=100 //a,b都声明初始值为100,都被推断为Int类型
a: Int = 100
b: Int = 100
scala> a
res1: Int = 100
scala> b
res2: Int = 100
//使用元组法同时声明多个不同类型和值的变量
scala> val (a,b)=(100,"mmzs")
a: Int = 100
b: String = mmzs
//使用元组法时也可以显式指定类型
scala> val (a:Int,b:String)=(100,"mmzs")
a: Int = 100
b: String = mmzs
//注意下面这种方式实际上是枚举法的赋值方式,它表示将右边的元组对象同时赋值给左边的a和b两个变量
scala> val a,b=(100,"mmzs")
a: (Int, String) = (100,mmzs)
b: (Int, String) = (100,mmzs)
C、Scala命令行换行
C1、可以使用三双引号输入多行数据
C2、如果输入了错误的内容导致命令等待可以连续两次回车以结束输入
D、函数定义
def max(a:Int,b:Int):Int={
......
}
说明:
函数定义以def开始,函数参数名后面必须指定类型,因为Scala无法自动推断出函数的参数类型;
函数如果被设计为递归函数(在函数体中调用它自身)则函数的返回类型就不能被省略,即递归函数无法推断函数的返回类型;
函数体实际上也被称之为函数块,一个块中如果只有一条语句则可以省略块两端的大括号,如:def max2(x: Int, y: Int) = if (x > y) x else y
//函数的调用与表达式的调用类似,如下:
scala> def max2(x: Int, y: Int) = if (x > y) x else y
max2: (x: Int, y: Int)Int
scala> max2(3,5)
res4: Int = 5
//函数也可以被推断为Unit类型:
scala> def greet()=println("Hello, world!")
greet: ()Unit
//下面的函数定义返回Int类型,但是实际上函数被推断为不返回任何值,即Unit类型,
scala> def greet():Int=println("Hello, world!")
<console>:11: error: type mismatch; //实际返回的类型与定义的返回类型不匹配
found : Unit //实际的返回类型
required: Int //定义的返回类型
def greet():Int=println("Hello, world!")
E、Scala脚本编写与调用
#编写Scala脚本:
[root@CloudDeskTop install]# vi test.scala
[root@CloudDeskTop install]# cat test.scala
//使用args数组接收传入脚本的参数
println("Hello:"+args(0))
println("Hello:"+args(1))
[root@CloudDeskTop install]# scala test.scala liming zhangsan
Hello:liming
Hello:zhangsan
说明:
scala脚本(test.scala)中可以使用args数组来获得传入脚本(test.scala)的参数,注意取参数所用的是小括号,不是中括号;scala脚本中的注释与Java中的注释是相同的,使用双斜杠标记单行注释,使用/*......*/标记多行注释。
F、while循环
F1、Scala中没有++i、--i、i++、i--的运算模式,可以使用i=i+1、i+=1来予以代替
F2、Scala中默认一行一条语句,如果需要在同一行放置多条语句则应该使用英文分号隔开
F3、Scala与Java相同,if、switch、while、for等后面的条件表达式都需要使用小括号括起来,这与Python、Ruby是不同的
F、for循环
scala> val list=List("zhu","ge","liang")
list: List[String] = List(zhu, ge, liang)
scala> for(ele<-list) println(ele)
zhu
ge
liang
//说明:由于for循环体中就只有一条语句(println(arg))所以省略了大括号
for表达式中<-后面的参数是一个集合,前面的参数是一个迭代变量,该迭代变量是隐式的val声明常量,在循环块中不能改变它的值,但是每次迭代都将重新定义和初始化它的值
scala> for(ele<-list){ele="sdnj";println(ele)} //试图在循环体中对它赋值是错误的
<console>:13: error: reassignment to val //因为它被指定为常量,尽管如此,你不能显式的写成for(val ele<-list){println(ele)},这是语法规定所需
for(ele<-list){ele="sdnj";println(ele)}
G、函数式编程(函数本身作为参数传递)
foreach迭代函数
foreach函数的参数接收一个函数对象,函数对象的=>符号左边是参数列表,右边是函数体,参数arg的类型没有指定则通过Scala来自动推断,而函数的返回类型没有指定也是通过函数体的返回值来进行自动推断,函数的参数函数是通过隐函数来定义的;
隐函数的特征:
A、隐函数的定义中没有关键字def和函数名
B、隐函数的参数类型并不是必须的,它可以通过实参值进行自动类型推断,这是与显函数定义不同的地方
C、隐函数的参数列表中如果只有一个参数则没有给定参数类型的情况下其参数两端的小括号可以省略,甚至
可以直接省略掉参数的定义和赋值符号,直接形成偏函数的定义
D、隐函数无需定义返回类型,返回类型根据函数体自动推断
D、函数体的赋值符号是=>,而不是=
[root@CloudDeskTop install]# vi test.scala
[root@CloudDeskTop install]# cat test.scala
args.foreach(arg=>println(arg))
[root@CloudDeskTop install]# scala test.scala zhu ge liang
zhu
ge
liang
小结:
所有变量、常量、函数在定义时其类型(对于函数而言是返回类型)是可选的(如果显式的给定类型则给定类型将作为自动化类型推断结果的一种校验),对于函数的参数类型分两种情况,在显式定义一个命名函数时其参数类型不可省略,在函数式编程领域中其参数函数的参数类型则是可选的(同样,如果显式的给定类型则给定类型将作为自动化类型推断结果的一种校验)
//如果需要显式指定参数类型则需要使用小括号将参数列表括起来:
scala> val list=List("zhu","ge","liang")
list: List[String] = List(zhu, ge, liang)
scala> list.foreach((ele:String)=>println(ele))//注意foreach不能对ArrayList集合遍历
zhu
ge
liang
//如果存在多个参数则函数定义格式如下:
(key:String,value:Object)=>println(key+":"+value)
小结:
在Scala中任何类型的变量在定义时都必须初始化(包括类),类在定义时使用类体初始化类的定义(但在Scala中官方并不认为这被称为初始化,因为它没有赋值符号),
函数在定义时使用函数体进行初始化,赋值符号是=(显函数定义)或=>(隐函数定义),常量和变量在定义时使用常量值或变量值进行初始化,赋值符号是=
//如果只有一个参数则可以省略参数定义和箭头部分(这种书写方式被称为偏应用函数)
scala> list.foreach(println)
zhu
ge
liang
注意:实际上foreach函数是for循环的变体,本质上都是相同的迭代方式,for循环的可读性更高,但foreach函数是标准的函数式编程写法
H、数组
H1、通用方式创建数组和使用数组
//当没有指定泛型参数时默认数组元素类型为Nothing类型,与Any类型相反,Nothing代表所有类的子类型,这意味着任何类型的数据不经过强制下转型将无法放入数组中去
//小括号中的参数2代表数组的长度(即数组中元素的个数),Scala根据此参数初始化数组的长度,这与Java不同,Scala中初始化数组的长度、下标的访问都是使用小括号,而不是方括号 scala> var arr=new Array(2);
arr: Array[Nothing] = Array(null, null) scala> arr(0)="zhugeliang"
<console>:13: error: type mismatch;
found : String("zhugeliang")
required: Nothing
arr(0)="zhugeliang"
^
注意: 从上面实例可以发现使用数组长度来初始化Scala数组时必须指定其泛型,否则数组中将无法放入任何元素
//指定了泛型之后就可以直接放入元素了
scala> var arr=new Array[String](3);
//如果需要显式指定变量类型可以像下面这样定义,可以看到泛型实际上是类型的一部分
scala> var arr:Array[String]=new Array[String](3);
arr: Array[String] = Array(null, null, null) scala> arr(0)="mmzs"
scala> arr(0)
res1: String = mmzs
scala> arr(1)="淼淼之森"
scala> arr(2)="mmzsblog" //foreach并传递隐函数遍历
scala> arr.foreach(ele=>println(ele))
mmzs
淼淼之森
mmzsblog //foreach并传递偏函数遍历
scala> arr.foreach(println)
mmzs
淼淼之森
mmzsblog //使用for循环遍历
scala> for(ele<-arr)println(ele)
mmzs
淼淼之森
mmzsblog //使用for循环并构建下标集合遍历,to关键字实际上是一个带一个Int参数的方法,0 to 2被解释成(0).to(2),to方法返回的是一个序列,arr.length描述集合的长度
scala> for(i<-0 to arr.length-1)println(arr(i))
mmzs
淼淼之森
mmzsblog
说明:
从技术上讲,Scala中没有操作符重载的概念,所有的操作符都将被视为方法然后实现对方法的调用,这也是因为Scala中的数组实际上就是一个普通Scala类的实现而已,
对数组类长度和下标的访问都是对该类中相应方法的调用,这也是下标的访问为什么是小括号而不是方括号的原因,比如对算术运算符+、-、*、/的访问也是视为方法来调用的:
scala> 1+2
res23: Int = 3
scala> 1.+(2)
res24: Int = 3
scala> (1).+(2)
res25: Int = 3
这个原则不仅仅局限于数组:任何对某些在括号中的参数的对象的应用将都被转换为对工厂方法apply(工厂方法apply是一个带可变长度参数的方法)的调用。当然前提是这个类型实际定义过apply方法。
所以这是一个通则,上面对数组的读写过程实际上被解释为:
scala> var arr:Array[String]=new Array[String](3);
arr: Array[String] = Array(null, null, null)
scala> arr.update(0,"zhu")
scala> arr.update(1,"ge")
scala> arr.update(2,"liang")
scala> for(i<-0.to(2))println(arr.apply(i))
zhu
ge
liang
H2、简洁方式创建数组和使用数组
//注意这种模式下不能再使用new关键字,同时也无需指定数组的泛型和长度,因为在创建数组的同时已经用实际的元素类型和值初始化了
scala> val arr=Array("zhu","ge","liang")
arr: Array[String] = Array(zhu, ge, liang)
scala> arr.apply(0)
res8: String = zhu
scala> arr.apply(1)
res9: String = ge
//也可以直接使用apply方法来创建数组(这种调用是直接对底层工厂方法的调用,效率或许更高,但是代码表现得有点啰嗦)
scala> val arr=Array.apply("zhuzhu","gege","liangliang")
arr: Array[String] = Array(zhuzhu, gege, liangliang)
scala> arr.apply(1)
res10: String = gege
scala> arr(1)
res11: String = gege
//由于数组元素的类型全部都是些基本类型,于是数组元素的类型被推断为AnyVal类型
scala> val arr=Array.apply(36,1.67,'A',true)
arr: Array[AnyVal] = Array(36, 1.67, A, true) //由于数组元素的类型全部都是些引用类型,于是数组元素的类型被推断为Object类型,在Java平台上,AnyRef是java.lang.Object类的别名,在.Net平台上,AnyRef是system.Object类的别名
scala> class User{}
defined class User scala> val arr=Array.apply("zhugeliang",new User())
arr: Array[Object] = Array(zhugeliang, User@c9cd85d) //由于初始化指定的类型既有引用类型又有基本类型,所以数组元素的类型被推断为Any类型
scala> val arr=Array.apply("liubei",39,1.77)
arr: Array[Any] = Array(liubei, 39, 1.77) //使用简洁方式创建数组时最好不要加泛型,这样可以使得Scala完成自动泛型推断,如果自定义了泛型则要求数组中的元素全部与泛型兼容,否则将抛出类型不匹配的异常
scala> val arr=Array[String]("ligang",23)
<console>:11: error: type mismatch;
found : Int(23)
required: String
val arr=Array[String]("ligang",23)
^
小结:
使用new关键字创建数组时,小括号中的参数是唯一的,且是必选参数,而且必须是一个代表数组长度的整型数据,使用简洁方式创建数组时小括号中的参数是0到多个可选的参数值,这些数据是数组中的元素值,由于创建数组时没有指定泛型则默认泛型为Nothing类型,所以对于泛型而言有以下建议:
a、如果使用new方式创建数组则必须指定泛型,否则后续无法为Nothing类型的数组元素赋值,使用new方式创建数组适合于数组中元素较多无法一次性枚举出来的情况使用
b、如果使用简洁方式创建数组则建议使用Scala的自动类型推断,但你也可以强制指定泛型,以保证初始化的枚举值类型都是准确无误的,使用简洁方式创建数组适合于数组中元素较少可以一次性枚举出来的情况使用
I、列表List
Scala中的List(全名是scala.List)不同于Java中的java.util.List类型,Scala中的List与字符串String的操作类似,它是一种完全不可变的列表,任何对列表的增、删、改操作都将产生一个新的列表对象返回,需要注意的是List与数组类型Array也不见得完全相同,虽然他们的长度都是不可以改变的,但是数组中的元素值则是可以改变的,而List集合中的元素值不能被改变,一旦改变将产生新的列表对象
a、合并两个列表并返回一个新的列表
//创建两个列表,泛型根据初始化的元素类型自动推断为Any
scala> val myinfo=List("zhugeliang",39,1.77)
myinfo: List[Any] = List(zhugeliang, 39, 1.77)
scala> val youinfo=List("lingang",50,1.68)
youinfo: List[Any] = List(lingang, 50, 1.68)
//合并两个列表中的元素(按顺序合并)
scala> val info=myinfo:::youinfo
info: List[Any] = List(zhugeliang, 39, 1.77, lingang, 50, 1.68)
//合并后产生新的列表,地址不再相同
scala> myinfo==info
res1: Boolean = false
scala> youinfo==info
res2: Boolean = false
b、在列表的首部插入数据,返回一个新的列表
scala> val list=List(68,86,99)
list: List[Int] = List(68, 86, 99) scala> val list2=100::list
list2: List[Int] = List(100, 68, 86, 99) scala> list==list2
res14: Boolean = false
说明:
不能使用new关键字实例化List对象,因为List.apply()方法被定义在scala.List伴生对象上;
以冒号结尾的方法名表示调用关系上的反转,即调用方法的对象是右边的操作数,像上面的myinfo:::youinfo表示的调用关系是youinfo.:::(myinfo),而100::list表示的调用关系是list.::(100),如:
scala> list2.::(200)
res15: List[Int] = List(200, 100, 68, 86, 99) scala> info.:::(myinfo)
res16: List[Any] = List(zhugeliang, 39, 1.77, zhugeliang, 39, 1.77, lingang, 50, 1.68)
而那些没有以英文冒号结尾的关键字表示的方法名则调用方法的对象是左边的操作数
c、串联离散数据成列表对象
//使用Nil关键字可以创建一个空列表
scala> Nil
res15: scala.collection.immutable.Nil.type = List()
scala> val list3="ligang"::27::1.67::Nil
list3: List[Any] = List(ligang, 27, 1.67)
//也可以使用成员运算符调用方法,但是表现的很啰嗦
scala> val list4=Nil.::("liubei").::(36).::(1.67)
list4: List[Any] = List(1.67, 36, liubei)
d、列表元素访问
//访问列表中索引为2的元素值
scala> list4(2)
res16: Any = liubei
//计算列表的尺寸,length属性几乎是所有集合所具备的属性,它用于表针集合的尺寸
scala> list4.length
res18: Int = 3
//返回列表的第一个元素或最后一个元素
scala> info.head
res19: Any = liubei
scala> info.last
res20: Any = 1.77
//列表是否为空列表
scala> Nil.isEmpty
res21: Boolean = true
scala> info.isEmpty
res22: Boolean = false
//返回除去第一个元素后的列表
scala> List(10,20,30,40).tail
res28: List[Int] = List(20, 30, 40)
//返回除去最后一个元素后的列表
scala> List(10,20,30,40).init
res27: List[Int] = List(10, 20, 30)
//删除左边的两个元素
scala> info
res43: List[String] = List(lingang, wangfang, changhua, zhangjin, guanyu)
scala> info.drop(2)
res46: List[String] = List(changhua, zhagjin, guanyu)
//删除右边的两个元素
scala> info.dropRight(2)
res47: List[String] = List(lingang, wangfang, changhua)
//反转元素列表
scala> List(10,20,30,40).reverse
res29: List[Int] = List(40, 30, 20, 10)
//转换列表为字符串
/*
mkString函数有两次重载:
(sep: String)String 使用一个分隔符串接列表中的所有元素为一个字符串
(start: String,sep: String,end: String)String 使用一个分隔符串接列表中的所有元素为一个字符串,同时在这个字串的起始和结束位置追加第一个参数字串和最后一个参数字串
*/
scala> List(10,20,30,40).mkString(",")
res39: String = 10,20,30,40
scala> List(10,20,30,40).mkString("(","|",")")
res42: String = (10|20|30|40)
e、列表过滤处理:
scala> val info=List("lingang","wangfang","changhua","zhangjin","guanyu")
info: List[String] = List(lingang, wangfang, changhua, zhangjin, guanyu)
/*
e1、count函数原型是:(p: Any => Boolean)Int,将集合中每一个元素放入隐函数计算,并返回集合中满足条件(参数函数返回true)的元素数量
*/
//使用隐函数计算info集合中元素的字符数为6的元素个数
scala> info.count(s=>6==s.length)
res26: Int = 1
//使用偏函数计算info集合中元素的字符数为6的元素个数
scala> info.count(6==_.length)
res1: Int = 1
/*
e2、exists函数原型是:(p: Any => Boolean)Boolean,只要集合中有一个元素满足条件(参数函数返回true)则exists函数返回true
*/
//判断集合info中是否存在元素的值为changhua的元素
//使用隐函数计算
scala> info.exists(s=>s=="changhua")
res3: Boolean = true
scala> info.exists(s=>s=="changshad")
res4: Boolean = false
//使用偏函数计算
scala> info.exists(_=="changhua")
res6: Boolean = true
/*
e3、forall函数原型是:(p: Any => Boolean)Boolean,集合中所有元素满足条件(参数函数返回true)则exists函数返回true;
该函数与exists函数是互补的,exists函数是描述or的关系,而forall是描述and的关系
*/
//判断集合info中的元素类型是否都是String类型
scala> info.forall(s=>s.getClass().getSimpleName()=="String")
res12: Boolean = true
scala> info.forall(_.getClass().getSimpleName()=="String")
res14: Boolean = true
scala> info.forall(s=>s.getClass().getSimpleName()=="Integer")
res13: Boolean = false
scala> List("lingang","chenghua").forall(_.getClass().getSimpleName()=="String")
res15: Boolean = true
scala> List("lingang","chenghua",50).forall(_.getClass().getSimpleName()=="String")
res16: Boolean = false
scala> List("lingang","chenghua").forall(_.getClass().getName=="java.lang.String")
res17: Boolean = true
scala> List("lingang","chenghua",100).forall(_.getClass().getName=="java.lang.String")
res19: Boolean = false
说明:
在Scala中比较字符串是否相同可以使用双等号,当然你使用equals方法来比较也是OK的:
scala> List("lingang","chenghua").forall(_.getClass().getName.equals("java.lang.String"))
res20: Boolean = true
/*
e4、filter函数原型是:(p: Any => Boolean)List[Any],过滤出满足条件(参数函数返回true)的所有元素并返回这些元素组成的子列表
*/
//过滤出字串长度为6的所有元素组成的子列表
scala> info.filter(s=>s.length==6)
res7: List[String] = List(guanyu)
scala> info.filter(_.length==6)
res9: List[String] = List(guanyu)
/*
e5、map函数原型是:(f: Any => B)(implicit bf: scala.collection.generic.CanBuildFrom[List[Any],B,That])That,将集合中的每一个元素使用map的参数函数处理并收集参数函数处理后的返回值组成的列表
*/
scala> List(10,20,30,40).map(s=>s+5)
res35: List[Int] = List(15, 25, 35, 45)
scala> List(10,20,30,40).map(_+5)
res37: List[Int] = List(15, 25, 35, 45)
/*
e6、foreach函数原型是:(f: Any => U)Unit,将集合中的每一个元素放入参数函数中去并调用参数函数处理,参数函数的返回类型根据参数函数体自动推断,foreach函数无返回值
*/
scala> info.foreach(s=>println(s))
lingang
wangfang
changhua
zhangjin
guanyu
scala> info.foreach(println(_))
lingang
wangfang
changhua
zhangjin
guanyu
J、元素Tuple
元组与列表相同也是不可改变的,任何对元组的增、删、改都将返回新的元组对象,元组与列表不同的是列表List中的类型都是相同的,使用列表时为了能够在其中容纳不同类型的元素,我们不得不使用与这些元素兼容的超类型,如:AnyVal、AnyRef或Any类型等,但是元组Tuple中的元素类型可以是不相同的,元组Tuple的实际类型取决于元组中元素的数量和各个元素的类型。
a、通用方式创建元组
//元组的泛型被自动推断为Tuple2[String,Int],下面的这条语句存在两次类型推断过程,首先是推断右边Tuple2的泛型为Tuple2[String,Int],然后在推断左边info变量的类型为Tuple2[String,Int]
//TupleX中的X代表元组中元素的数量,元组的泛型由元组中的各个元素类型来确定,元组中的元素数量和类型决定了元组自身的类型
scala> val info=new Tuple2("liubei",28)
info: (String, Int) = (liubei,28)
//访问元组的第一个元素
scala> info._1
res54: String = liubei
//访问元组的第二个元素
scala> info._2
res55: Int = 28
说明:
不能像访问List中元素那样去访问元组中的元素,因为List的apply方法返回的类型都是同一类型,然而元组的各个元素的类型不见得完全相同,访问元组中的元素只能使用成员运算符(.),其中元素格式为_N,N代表元素在元组中的下标
//显式指定元组的泛型,但是左边的info变量的类型需要Scala自动推断
scala> val info=new Tuple2[String,Int]("ligang",28)
info: (String, Int) = (ligang,28)
//显式指定变量的类型和元组的泛型
scala> val info:Tuple2[String,Int]=new Tuple2[String,Int]("ligang",28)
info: (String, Int) = (ligang,28)
b、简洁方式创建元组(无new关键字)
scala> val info=Tuple2("ligang",28)
info: (String, Int) = (ligang,28)
//也可以显式指定泛型和变量的类型
scala> val info=Tuple2[String,Int]("ligang",28)
info: (String, Int) = (ligang,28)
scala> val info:Tuple2[String,Int]=Tuple2[String,Int]("ligang",28)
info: (String, Int) = (ligang,28)
c、最简方式创建元组(无Tuple关键字)
//info变量自动被推断为:Tuple2[String,Int]类型
scala> val info=("ligang",28)
info: (String, Int) = (ligang,28)
//也可以显式为变量指定类型
scala> val info:Tuple2[String,Int]=("ligang",28)
info: (String, Int) = (ligang,28)
小结:
元组Tuple具有比列表List更高一个层级的不可变型,元组Tuple相对于列表List的优势就是它的元素类型可以是不同的,然而元组Tuple的缺点是没有像列表List那样丰富的API操作,元组中的数据几乎是固定不变的。
K、Set集合
在Scala中,Set集合分为可变集合和不可变集合,其中的可变集合与Java中的Set集合是相似的,Set在Scala中被定义为一个Trait,它的具体实现是HashSet,HashSet仍然分为可变的HashSet和不可变的HashSet,所有可变的集合放置于scala.collection.mutable包中,而所有不可变的集合则放置于scala.collection.immutable包中,Set集合中的+=运算符在可变与不可变的具体集合实现中有着不同的实现,在可变的Set集合中,该运算相当于append,即直接往当前集合中追加元素,而在不可变的Set集合中,该运算相当于+产生的合并运算,这将导致产生新的Set集合对象,同时将合并后的新Set集合对象赋值给左边的变量;Set集合中的元素是自动去重的,即没有重复的元素,这个特征不同于Array和List;创建任何Set集合(包括HashSet集合)都只能使用简洁模式,不能使用new的方式来创建,从此你会发现规避使用new来创建对象在Scala中是一种更好的通用选择。
//创建一个Set集合,泛型被自动推断为Any类型,左边的set变量被自动推断为Set[Any]类型
scala> val set=Set("ligang",28,1.67)
set: scala.collection.immutable.Set[Any] = Set(ligang, 28, 1.67)
//也可以显式指定泛型和变量类型
scala> val set=Set[Any]("ligang",28,1.67)
set: scala.collection.immutable.Set[Any] = Set(ligang, 28, 1.67)
//追加一个元素到Set集合将返回一个新的Set集合对象
scala> val set02=set+"chenggang"
set02: scala.collection.immutable.Set[Any] = Set(ligang, 28, 1.67, chenggang)
scala> set==set02
res3: Boolean = false
//如果你希望将产生的新的Set集合对象再赋值回原来的变量,类似于字符串一样的去改变原有变量,可以使用+=运算符,由于需要改变原有变量的引用值,所以需要使用var来定义该变量,而不是val
scala> var set=Set("ligang",28,1.67)
set: scala.collection.immutable.Set[Any] = Set(ligang, 28, 1.67)
//下面的这步操作相当于:set=set+"chenggang",这显然是改变了原有set变量的值,这也是上面为什么要使用var来定义它的原因所在
scala> set+="chenglong"
scala> set
res5: scala.collection.immutable.Set[Any] = Set(ligang, 28, 1.67, chenglong)
//再次追加相同的元素则不会追加成功
scala> set+="chenglong"
scala> set
res3: scala.collection.immutable.Set[Any] = Set(ligang, 28, 1.67, chenglong)
说明:
上面的操作也许会考虑到使用val重新定义set变量(而坚持不使用var),但这种情况会发生递归错误,所以我们只能使用另一个变量set02来替换,或者使用var定义它然后使用+=运算符
scala> val set=set+"zhangsan"
<console>:12: error: recursive value set needs type
val set=set+"zhangsan"
^
从上面的Set集合创建过程可以看出Set集合默认创建为不可变的集合类型,如果你需要的是可变的集合类型则必须使用import显式的导入可变类型的Set
scala> import scala.collection.mutable.Set
import scala.collection.mutable.Set
scala> val set=Set("ligang",28,1.67)
set: scala.collection.mutable.Set[Any] = Set(ligang, 1.67, 28)
//下面这句相当于append操作,直接改变集合对象本身,并不会产生新的集合对象
scala> set+="zhangsan"
res5: set.type = Set(ligang, 1.67, 28, zhangsan)
//再次追加相同的元素值则不会追加成功
scala> set+="zhangsan"
res6: set.type = Set(ligang, 1.67, 28, zhangsan) /*
如果你想基于特定的实现类创建Set集合则必须使用import导入相应的类型,但实际生产上用的较少
*/
//导入可变的HashSet类型
scala> import scala.collection.mutable.HashSet
import scala.collection.mutable.HashSet
scala> val set=HashSet("ligang",28,1.67)
set: scala.collection.mutable.HashSet[Any] = Set(ligang, 1.67, 28)
//创建不可变的HashSet类型
scala> val set=scala.collection.immutable.HashSet("ligang",28,1.67)
set: scala.collection.immutable.HashSet[Any] = Set(28, ligang, 1.67)
Set小结:
对于不可变的Set集合类型变量应该使用var来进行定义以保证追加元素后产生的新集合对象能够被赋值回原来的变量,对于可变的Set集合类型通常是使用val来进行定义,此时追加元素将改变集合本身,而不会产生任何新的集合对象。
Array、List、Set、Tuple小结:
尺寸的可变性:
Array和Tuple是在实例化时定义长度的,实例化之后不可以改变它的长度;而List、Set则可以动态改变长度,如List可以通过::追加元素产生新的List对象,而Set可以通过+=追加元素产生新的Set对象或者直接改变集合本身;
集合中元素类型是否相同:
Array、List、Set集合中元素类型相同,Tuple集合中的元素类型可以相同、也可以不同;
集合中的元素值是否可以改变:
Array集合中的元素值可以改变,List和Tuple集合中的元素值不能被改变,Set集合中的元素有可变和不可变两种实现(分别使用val和var来定义);
元素是否可以重复:
Set集合中的元素不可以重复,Array、List、Tuple集合中的元素值可以重复;
泛型推断原理:
对于不可变集合而言必须在实例化时指定各个元素的值,此时Scala可以自动根据给定的元素值来推断其集合的泛型;而对于可变集合则可以延迟给定各个元素的值,此时的可变集合泛型在实例化时就会被自动推断为Nothing类型,此后需要添加到可变集合的各个元素不得不强制下转型为Nothing,否则将无法添加元素到可变集合中,对于Array之前我们就已经看到了,现在来看看可变集合Set,它将与Array遇到同样的情况:
scala> import scala.collection.mutable.Set
import scala.collection.mutable.Set scala> val set=Set()
set: scala.collection.mutable.Set[Nothing] = Set() scala> set+="ligang"
<console>:14: error: type mismatch;
found : String("ligang")
required: Nothing
set+="ligang"
^
L、Map集合
a、->与<-的区别:
前者是被定义在Any根类中的方法,即任何对象调用该方法都将返回一个二元素元组,该元素中的第一个元素是当前对象,第二个元素是参数对象
scala> "name"->"ligang"
res1: (String, String) = (name,ligang)
scala> "age"->28
res2: (String, Int) = (age,28)
scala> "height"->1.64
res3: (String, Double) = (height,1.64)
scala> 100->"zhanghua"
res4: (Int, String) = (100,zhanghua)
//也可以使用成员运算符来调用该方法
scala> 150.->("zhanghua")
res5: (Int, String) = (150,zhanghua)
后者是被用在for循环中遍历集合之用:
scala> val info=List(20,60,80)
info: List[Int] = List(20, 60, 80)
scala> for(e<-info)println(e)
20
60
80
b、创建不可变的Map对象
Map集合中下标被称之为Key,元素值被称之为Value,Map集合中的每一个元素被称之为一个键值对的对象,这个键值对是一个包含了Key和Value的二元素元组
//首先创建三个键值对元组对象,它们是entry1、entry2和entry3
scala> val entry1="name"->"ligang"
entry1: (String, String) = (name,ligang)
scala> val entry2="age"->36
entry2: (String, Int) = (age,36)
scala> val entry3="height"->1.67
entry3: (String, Double) = (height,1.67)
//再创建不可变的Map对象,注意对不可变的Map应该使用var来定义,否则后续无法使用+=运算符追加键值对
scala> var info=Map(entry1,entry2,entry3)
info: scala.collection.immutable.Map[String,Any] = Map(name -> ligang, age -> 36, height -> 1.67)
//访问Map集合中的元素应根据Key来访问Value
scala> info("name")
res8: Any = ligang
scala> info("age")
res9: Any = 36
//追加键值对
val entry3="height"->1.67
scala> val info2=info+entry4
info2: scala.collection.immutable.Map[String,Any] = Map(name -> ligang, age -> 36, height -> 1.67, weight -> 118)
scala> info==info2
res13: Boolean = false
//也可以使用+=来追加键值对
scala> val entry5="birthday"->java.sql.Date.valueOf("1982-12-26")
entry5: (String, java.sql.Date) = (birthday,1982-12-26)
scala> info+=entry5
scala> info
res15: scala.collection.immutable.Map[String,Any] = Map(name -> liyongfu, age -> 36, height -> 1.67, birthday -> 1992-12-26)
c、创建可变的Map对象
scala> import scala.collection.mutable.Map
import scala.collection.mutable.Map
//注意对可变的Map应该使用val来定义,否则后续无法使用+=运算符追加键值对
scala> val info=Map(entry1,entry2,entry3) info: scala.collection.mutable.Map[String,Any] = Map(age -> 36, name -> ligang, height -> 1.67) scala> info+=entry5 res16: info.type = Map(birthday -> 1992-12-26, age -> 36, name -> ligang, height -> 1.67) scala> info res17: scala.collection.mutable.Map[String,Any] = Map(birthday -> 1992-12-26, age -> 36, name -> ligang, height -> 1.67)
说明:
Scala中的集合类型默认引用的是不可变的集合类型,如果需要使用可变的集合类型则需要手动使用import导入scala.collection.mutable._(这里的下划线相当于java中的*),如:
scala> import scala.collection.mutable._
import scala.collection.mutable._
scala> val info=Map[String,Any]()
info: scala.collection.mutable.Map[String,Any] = Map()
//直接追加键值对
scala> info+="name"->"ligang"
res0: info.type = Map(name -> ligang)
scala> info+="age"->28
res1: info.type = Map(age -> 28, name -> ligang)
在Java中通常创建的集合对象都是可变的,同时如果引用集合对象的变量没有使用final修改则该变量也是可变的,如果在Scala中需要像Java中的那种集合创建方式则应该是如下情况:
scala> import scala.collection.mutable._
import scala.collection.mutable._
scala> var info=Map[String,Any]()
info: scala.collection.mutable.Map[String,Any] = Map()
M、函数式风格编程与文件操作
M1、var与val的选择
通常情况下,如果使用var定义来实现编程,那么这种风格就是Scala中的指令式风格,指令式风格对于C/C++以及Java程序员都是司空见惯的一种模式,如果需要向函数式风格化推进,则应该尽可能的使用val编程,而不再是使用var来编程;其二,通常我们在编程中应该首先思考的是Scala的API,当我们考虑到有难度时再回退到Java的API中来实现,这是一种不错的思路。
M2、文件操作
//构建测试文件
[root@CloudDeskTop install]# vi testfile
[root@CloudDeskTop install]# cat testfile
01 lingang 2009-12-28
02 zhanghua 1998-10-12
03 chengqiang 1923-11-18
04 欢迎来到mmzs
05 觉得有用的话
06 点个赞呗
//编写脚本
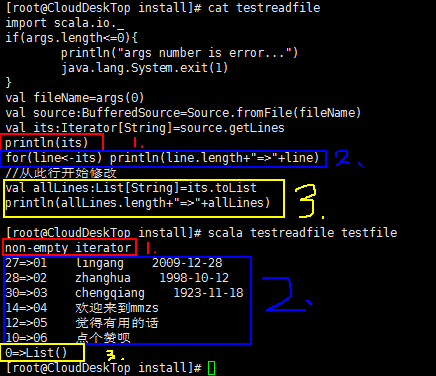
[root@CloudDeskTop install]# vi testreadfile
[root@CloudDeskTop install]# cat testreadfile
import scala.io._
if(args.length<=0){
println("args number is error...")
java.lang.System.exit(1)
}
val fileName=args(0)
val source:BufferedSource=Source.fromFile(fileName)
val its:Iterator[String]=source.getLines
for(line<-its) println(line.length+"=>"+line)
//调用脚本读取文件内容并打印到控制台
[root@CloudDeskTop install]# scala testreadfile testfile
27=>01 lingang 2009-12-28
28=>02 zhanghua 1998-10-12
30=>03 chengqiang 1923-11-18
14=>04 欢迎来到mmzs
12=>05 觉得有用的话
10=>06 点个赞呗
说明:
val its:Iterator[String]=source.getLines返回的是一个迭代器,迭代器指针指向磁盘文件的第一行,每循环一次都将从磁盘上读取下一行的数据到内存中;
如果需要一次性将磁盘文件中的内容读取到内存可以使用迭代器调用toList方法:
val its:Iterator[String]=source.getLines
val allLines:List[String]=its.toList
//代码如下
[root@CloudDeskTop install]# cat testreadfile
import scala.io._
if(args.length<=0){
println("args number is error...")
java.lang.System.exit(1)
}
val fileName=args(0)
val source:BufferedSource=Source.fromFile(fileName)
val its:Iterator[String]=source.getLines
//for(line<-its) println(line.length+"=>"+line)
//从此行开始修改
val allLines:List[String]=its.toList
println(allLines.length+"=>"+allLines)
//结果如下
[root@CloudDeskTop install]# scala testreadfile testfile
6=>List(01 lingang 2009-12-28, 02 zhanghua 1998-10-12, 03 chengqiang 1923-11-18, 04 欢迎来到mmzs, 05 觉得有用的话, 06 点个赞呗)
scala程序开发入门的更多相关文章
- 微信小程序开发入门教程
做任何程序开发要首先找到其官方文档,微信小程序目前还在邀请内测阶段,目前官方放出了部分开发文档,经过笔者一天的查看和尝试,感觉文档并不全面,但是通过这些文档已经能够看出其大概面貌了.闲话不多说,我们先 ...
- spark之scala程序开发(集群运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- Scala语言开发入门
在本系列的第一篇文章 <使用递归的方式去思考>中,作者并没有首先介绍 Scala 的语法,这样做有两个原因:一是由于过多的陷入语法的细节其中,会分散读者的注意力.反而忽略了对于基本概念,基 ...
- 微信小程序开发入门(一)
小程序学习入门--(一) 最近自己学习微信小程序的过程当中自己总结出来的知识点,我会不断地更新和完善! 小程序的开发工具 一台电脑 熟悉HTML.CSS.JS基本语法 开发工具: 微信web开发者工 ...
- 微信小程序开发入门与实践
基础知识---- MINA 框架 为方便微信小程序开发,微信为小程序提供了 MINA 框架,这套框架集成了大量的原生组件以及 API.通过这套框架,我们可以方便快捷的完成相关的小程序开发工作. MIN ...
- 微信小程序-开发入门
微信小程序已经火了一段时间了,之前一直也在关注,就这半年的发展来看,相对原生APP大部分公司还是不愿意将主营业务放到微信平台上,以免受制于腾讯,不过就小程序的应用场景(用完即走和二维码分发等)还是很值 ...
- 微信小程序开发入门篇
本文档将带你一步步创建完成一个微信小程序,并可以在手机上体验该小程序的实际效果. 开发准备工作 获取微信小程序的 AppID 登录 https://mp.weixin.qq.com ,就可以在网站的& ...
- 微信小程序开发入门:10分钟从0开始写一个hello-world
小程序开发需要三个描述整体程序的app文件 和 一个描述多个页面的 pages文件夹. (1)三个app文件分别是app.js,app.json,app.wxss. app.js文件是脚本文件处理一些 ...
- 程序开发入门工具之CodeBlocks
程序开发基础工具之CodeBlocks 作为程序开发工作者,我们会接触很多的程序开发软件:但实用以及容易掌握的程序开发软件对于初学者的学习能力是有一定的加成的.今天我就作为一个程序开发者给大家推荐一个 ...
随机推荐
- Catalog
Java SE EE| Hibernate | Struts2Spring/SpringMVC | MyBatis C# Python PHP C/C++ | STL 汇编语言 ...
- 【转载】 .NET框架设计—常被忽视的C#设计技巧
阅读目录: 1.开篇介绍 2.尽量使用Lambda匿名函数调用代替反射调用(走进声明式设计) 3.被忽视的特性(Attribute)设计方式 4.扩展方法让你的对象如虎添翼(要学会使用扩展方法的设计思 ...
- 利用Python+163邮箱授权码发送邮件
背景 前段时间写了个自动打卡的脚本,但是脚本不够完善,我需要知道,打卡到底成没成功,因此,我想到了用Python执行完代码之后,再执行一段发送邮件的代码.需求开始明确了,就开始分析和写代码实现吧. 分 ...
- 学习Python第六天
今天我们讲讲数据类型中的集合,博客写得有点糙,后续应该要进行优化优化了........ 集合:无序,不重复的数据组合,主要作用:去重,把一个列表变成集合,就自动去重了 基本语法:S = {1}类型为集 ...
- java holdsLock()方法检测一个线程是否拥有锁
http://blog.csdn.net/w410589502/article/details/54949506 java.lang.Thread中有一个方法叫holdsLock(),它返回true如 ...
- Android-获取Html元素
第一步导包: implementation 'org.jsoup:jsoup:1.10.3' 第二步:需获取解析的Html: <p> <myfont style="colo ...
- spring 装配
spring 3种装配方式: 支持混合配置:不管使用JavaConfig还是使用XML进行装配,通常都会创建一个根配置(root configuration), 这个配置会将两个或更多的装配类和/或X ...
- Android 监听屏幕锁屏&用户解锁
在做视频播放器的时候,遇到一个问题,在用户播放视频然后锁屏之后,视频播放器仍然在继续播放,遇到类似手机系统状态改变的问题的时候,首先想到了广播,下面做个总结: public class ScreenL ...
- Java与Python比较心得01
Java 可以int + 字符串(str)输出,python则只可以用逗号 , 连接,或者字符串 + 字符串或int + int否则python会报错如下图:
- Handshake failed due to invalid Upgrade header: null 解决方案
Handshake failed due to invalid Upgrade header: null 解决方案 解决方案,在 Nginx ,location 中添加以下代码: proxy_set_ ...