python高级(1)—— 基础回顾1
Python基础回顾
认识变量
在学习了之前的Python零基础入门系列【洗礼灵魂,修炼Python】(说明一下,这个系列现在回过来再来看这个名字确实好土啊,然后有些知识点感觉还不太精准,后期看如果有时间再调整下,名字的话就这样了,不想改了,要改的话起码得改大半天),相信你已经对Python有了一个大概的了解了。本系列是Python高级,所以先简单回顾一下
变量及变量的作用
变量,顾名思义,变量,那当然是会变的量了。当然这么说感觉有点枯燥,好,先看个例子:
计算某人每天的总支出,已知,早餐6块,中餐15块,晚餐15块,交通费6块,如果天气炎热,饮料费6块
好的以上的价格按照生活常识的话都是不固定的,所以我们只是算个大概,打开Python自带的IDLE交互式工具(当然你也可以打开pycharm之类的编辑器):

这样,就计算出了结果了。
那么问题来了,一个正常的人,每天遇到的情况也肯定有很多种,比如今天早上这人起得晚,没吃早饭(早餐则成了0),然后因为赶时间去公司打了个车(交通费变得更多了),那么这每天的支出就又要重新算一下了,又要重复上面的操作一次,这样算多了则会带来一系列的问题,比如中间有个式子算错了,那么全盘皆错,而且还不方便后期进行修改和删除一些数据,那这个问题有没有个好点方法来节省下我们的运算量呢?
答案当然是有的,想一下,我们在学生时代,学解方程的时候是怎么做的?设未知数为X对吧?然后根据条件写出一个式子,然后就可以计算这个未知数真实的值了对吧?而在编程语言里,也是有这个设未知数概念的,不过稍微有些不同,我们不会永远都只用X,会用到很多,而这个设定的未知数则叫变量。
在上面这个晚起的情景里,我们先设定breakfast = 0(即晚起没吃到早餐),打车费为trans = 20,然后依次操作依次设定变量,最后我们再加起来:

结果计算出来了对吧?相信有朋友看到这里还感觉不到变量的强大,那么假如这个人没有晚起,然后一切正常的,我们再用变量计算一次:

有朋友会觉得有点奇怪对吧?怎么没有把午餐,晚餐,饮料之类再加上呢?而且还算出来了,结果还是对的?
这就是变量的作用了,它可以临时存储值,并且这里按照正常情况,我只需要改下breakfast 和trans 值,其他都不变就行了。所以到现在发现变量的作用了吧?如果你还不太懂,不急,后面开始通篇都会大量的使用变量,到时候自然会意会的。
上面的这种 breakfast(中文意思即为早餐)= 6 (这里的符号“=”是赋值符号,不等同于数学里的等于符号)到底是什么意思呢,就是指把6这个值赋值给breakfast这个变量上,图解:

我们可以直接调用变量访问它的值,也可以用print打印它的值:

当然你也可以用del语句来删除你定义的变量:

当用del语句删除之后,再次调用这个变量时就会报错提示该变量名未定义
那么在所有的编程语言里,把这个breakfast =6这个操作都称为把6赋值给breakfast,这个操作其实在所有的编程语言里都是两个步骤:
声明变量
定义变量
不过在Python中,您可能要注意两点:
Python定义变量的同时则会把声明变量和定义变量两个步骤同时进行
Python的定义变量时,并不是简单意义上的赋值,而是引用变量
什么是变量引用
先看个例子:

这几行的意思是,a=4,那么此时a的值即为4,接下来我又让a=6,此时a的值即为6,但b还是4,并没有跟着a一起改变值,b重新等于8,a也不会跟着b改变,图解:

注:当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,这个对象不久会被回收,回收这个对象的机制就是内存管理机制
这就是变量引用的特性,那么通过以上,相信您应该理解什么是变量了,变量的作用自然就是临时存储数据了
然而这变量定义是否是随便我们定义的呢?好像看起来很随意对吧?其实还是有个规范的,没有规矩不成方圆
变量定义的规范
变量名可以是字母,数字,下划线,但变量不能以数字开头
严格区分大小写
变量的名字尽量取专业的名字,做到顾名思义
其实定义变量还有个不成文的规定,不能使用中文和拼音命名,虽然也可以用中文或者拼音来命名,但是请您千万不要这么做,这是很low的表现:

上面的变量规范如果您不相信,那么你可以试试:

这个红色不是我把它标红的,它自己红的,出现这个相信您已经知道这是报错的意思,那么定义变量时真的不可以这么操作的,你就记住定义变量只能是字母数字下划线,而且字母不能作为开头就行了:

数字和运算
前面我们用breakfast = 6定义变量并赋值,那么你有没有想,这里的6有没有什么特殊的含义呢?当然是有的
数字/常量
前面的变量定义breakfast = 6,这个6就是数字,它还有另一个名字——常量
那么这个常量有什么可说的呢?首先大家都知道这个6是整数对吧,那么肯定还有带小数的或者分数,负数,复数之类的。而在Python中,这些数都有什么名字呢?
数据类型:
整形数(int): 即整数,如1,2,-1,-2
浮点型(float): 即带小数的数,如1.2,3.1415,-1.2,-3.1415
布尔型(bool): 即1(True)和0(False)。(这个在流程控制会详细讲到,这里暂且不提)
- 复数型:即带“j”的数字就是复数型(其实复数用得不多,作为了解即可)

其实数据类型还有长整型(long)和定点型(double),长整型是Python2里特有的概念,实质上它还是整数,因为Python2当时可表示的数值位数有限,所以有长整型的概念,而现在Python3里都通称为整型了。
定点型其实也是带小数的数,实质上和浮点型没多大区别,并且几乎用不到的。
那么,我们知道这些数据类型之后,怎么查看一个数或者一个变量的数据类型呢?
Python给我们分配了两元大将——type函数和instance函数
type函数:

所以我们可以得出结论:type函数会返回变量的数据类型
instance函数:

报错提示,指这个isinstance需要传入两个参数,而我们只传入了一个参数,所以报错,那么我们这里只有一个参数啊,为了查看变量类型的,查阅帮助文档得:

那么根据这个帮助文档,isinstance后面传入的参数是数据类型(int,float等)
好我们再试试看:

那么这里我们又可以得出结论:isinstance它会返回一个bool类型,如果是对的,那么就是true,否则就是false。
简单运算(运算操作符)
1).算术操作符:
有了以上的知识,相信各位已经摩拳擦掌准备体验一下了,好的,我们随便测试几个看看:

以上这些就是简答的加(+)减(-)乘(*)除(/)了
2).比较操作符 (> 大于,>= 大于等于,< 小于,<= 小于等于,== 等于,!= 不等于)
3).逻辑操作符 (in 属于,or 或,and 且,not in 不属于,is 等同于)
4).幂运算/开根运算 (**,sqrt)

上面这个就是幂运算了。那么开根运算是什么呢?
这里就需要导入一个math模块里的sqrt函数,这个sqrt函数就是开根的作用,它是Python自带的模块,我们只需要import导入就行了,好的我们开始用这个模块来开根:


5).按位运算
按位运算,那么什么是位呢?
这里的位指的是二进制位,按位运算就按位是指将一个数字转换为标准的8位二进制,然后这些二进制按位操作运算。
&:按位与运算:按位相同则取1,不同取0
例:
a=7&18
7 二进制为111 转为标准8位二进制 00000111
18 二进制为10010 转为标准8位二进制 00010010
两个作与运算得: 00000010
最终结果为2
|:按为或运算:按位其中一位位1则取1,都不为1则取0
例:
a=7|18
7 二进制为111 转为标准8位二进制 00000111
18二进制为10010 转为标准8位二进制 00010010
两个作与运算得: 00010111
最终结果为23
^:按位异或运算:按位不同则取1,相同取0
例:
a=7^18
7 二进制为111 转为标准8位二进制 00000111
18二进制为10010 转为标准8位二进制 00010010
两个作与运算得: 00010101
最终结果为21
~:按位翻转,即~x=-(x+1)
例: a=~18 ~18=-(18+1)
结果为-19
<<:按位左移,比如18即为00010010,左移一个单位00100100
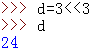
>>:按位左移,比如18即为00010010,左移一个单位00001001
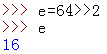
其他操作符:就是小括号和正负号(+,-,注意这里不等同于加减号),但是他们的优先级很高
好的,以上就是各种运算了,那么相信聪明的你一定想到一个问题,现在这么多种不同的操作符,如果都放在一起计算,怎么知道先算谁后算谁呢?这个确实是个问题,所以这就有了运算优先级了
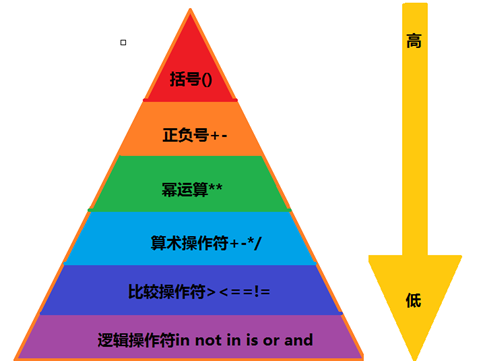
运算优先级
这里直接用一个图来解释,三角形由上到下,依次优先级由高到底
这里用一个例子说一下为什么正负号在幂运算优先级之上:

字符串和输入输出
什么是字符串
凡是用‘’(引号)引起来的都叫字符串,比如:

这个引号可以是单引号(’’),也可以是双引号(“”),也可以是三引号(’’’’’’)
注意:三种形式的引号必须成对出现,不然报错:

报错提示就是说你的符号没有一个合理的结尾,换句话就是你的符号没有成对出现。
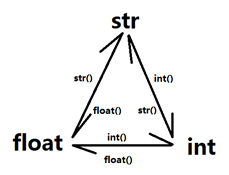
并且字符串也是数据类型的一种,所以数据类型到现在我们学的数据类型有:int,str,float
那么这里就有个很重要的知识点
数据类型转换:
1).整形转字符串:用str函数转换

2).整形转浮点型:用float函数

3).字符串转整形:用int函数
注意:字符串转整形有个前提,字符串里本身是个数字,不然报错

三种不同数据类型之间的转换图解:
创建字符串的方法:
1).直接使用引号:
这个上面已经说了 例:’python’
2).用函数str()

利用str函数来创建函数,括号内可以是数字,也可以是字符串,但不能是未定义的变量:

字符串操作
字符串是什么前面大家都了解了吧,字符串在Python中是个很重要的概念,它是一个数据类型(前面的int,float,str),又是一个数组类型(即一个容器,可以存放多个数据的类型),还是一个对象,既然是一个对象,则会有很多方法、属性操作
以下是Python3下字符串的所有方法

注:由于字符串的方法太多,下面就简单讲解几个非常常用的方法就行,望各位看官耐心看下去
captalize:把整个字符串的第一个单词的首字母大写并返回

注意:
1).这里使用了字符串的方法后,其实并不会修改test自身,只是返回了一个结果,如果需要修改test,则将修改后的结果重新赋值:

2).使用字符串的方法是最后要加“()”,没有什么特别的意思,这就是Python规定的
casefold:把整个字符串的所有字符改为小写,python3里特有的

center(width):把字符串居中,并使用空格填充至长度 width 的新字符串

count(sub[, start[, end]]):返回 sub 在字符串里边出现的次数,start 和 end 参数表示索引范围
索引即下标,从0开始。

上面这个test,其值对应索引就是下面的数字
比如这里test = "abcdfjack":通过索引就可以单独取出数据


这里count方法里的1,4就是索引为止,由于索引1到4并没有‘a’,所以返回0
decode(decode='strict'):把已知的编码方式解码为Unicode
encode(encoding='utf-8',
errors='strict'):以 encoding 指定的编码格式对字符串进行编码
endswith(sub[, start[,
end]]):检查字符串是否以 sub 子字符串结束,如果是返回
True,否则返回 False。start 和 end 参数表示范围

startswith(prefix[,
start[, end]]):检查字符串是否以 prefix 开头,是则返回 True,否则返回 False。start 和 end 参数可以指定范围检查

expandtabs([tabsize=8]):把字符串中的制表符(即一个tab键位置,相信前面第一章里Python的语法规则你已经学过了),\t转换为空格,如不指定参数,默认的空格数是 tabsize=8

这里由于都是空白的看不出效果,它确实是已经把\t转为空格了
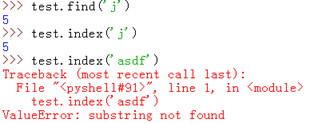
find(sub[, start[, end]]):检测 sub 是否包含在字符串中,如果有则返回索引值,否则返回 -1

rfind(sub[, start[, end]]):原理同 find() 方法,不过是从右边开始查找
foramt:格式化字符串

index(sub[, start[, end]]):跟 find 方法一样,不过如果 sub 不在 string 中会产生一个异常
rindex(sub[, start[,
end]]):同理index() 方法,不过是从右边开始
isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False

isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False

isdecimal():如果字符串只包含十进制数字则返回 True,否则返回 False,这是python3特有

isdigit():如果字符串只包含数字则返回 True,否则返回 False

isnumeric():如果字符串中只包含数字字符,则返回 True,否则返回 False,同理isdigit方法相同
islower():如果字符串中至少包含一个区分大小写的字符,并且这些字符都是小写,则返回 True,否则返回 False

isspace():如果字符串中只包含空格,则返回 True,否则返回 False

istitle():如果字符串是标题化(所有的单词都是以大写开始,其余字母均小写),则返回 True,否则返回 False

isupper():如果字符串中至少包含一个区分大小写的字符,并且这些字符都是大写,则返回 True,否则返回 False

join(sub):以字符串作为分隔符,插入到 sub 中所有的字符之间

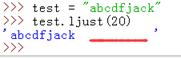
ljust(width):返回一个左对齐的字符串,并使用空格填充至长度为 width 的新字符串
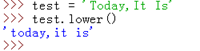
lower():转换字符串中所有大写字符为小写。
partition(sub):找到子字符串 sub,把字符串分成一个 3 元组 (pre_sub, sub, fol_sub),如果字符串中不包含 sub 则返回 ('原字符串', '',
'')

rpartition(sub):同理partition() 方法,不过是从右边开始查找
replace(old, new[, count]):把字符串中的 old 子字符串替换成 new 子字符串,如果 count 指定,则替换不超过 count 次

rjust(width):返回一个右对齐的字符串,并使用空格填充至长度为 width 的新字符串,同理ljust
split(sep=None,
maxsplit=-1):不带参数默认是以空格为分隔符切片字符串,如果 maxsplit 参数有设置,则仅分隔 maxsplit 个子字符串,返回切片后的子字符串拼接的列表

splitlines(([keepends])):按照 '\n' 分隔,返回一个包含各行作为元素的列表,如果 keepends 参数指定,则返回前 keepends 行

strip([chars]):删除字符串前边和后边所有的空格,chars 参数可以定制删除的字符,可选

lstrip():去掉字符串左边的所有空格
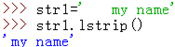
rstrip():去掉末尾(右边)的空格,同理lstrip(),strip()
swapcase():翻转字符串中的大小写

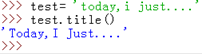
title():返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串
translate(table):根据 table 的规则(可以由 str.maketrans('a', 'b') 定制,maketrans方法是python特有,用的较少)转换字符串中的字符

这个方法和replace方法很类似,个人建议直接使用replace,这个translate步骤太多了。
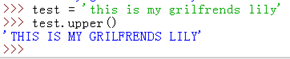
upper():转换字符串中的所有小写字符为大写
zfill(width):返回长度为 width 的字符串,原字符串右对齐,前边用 0 填充

以上就是常用的字符串方法了,当然还有很多字符串方法,感兴趣可以自己去研究了,掌握了上面的方法都够你处理日常任务了
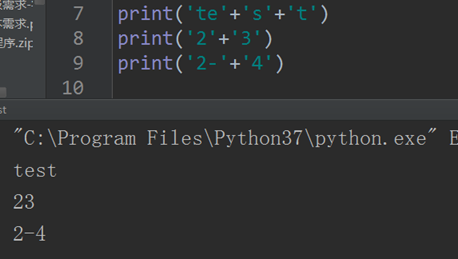
字符串拼接:+
字符串也可以拼接起来:
除了用“+”还可以用‘,’号,但并不是真正意义的拼接,且中间会有一个空格

但记住一定不是加起来,而且不同类型的是不能拼接的,会报错:

简单输入输出
1).print输出
当然就是前面你已经用到的print了。在Python2里,print是一个语句。在Python3里,print是一个函数了,既然是函数,自然就还有其他功能了。先看文档:

Sep参数很少用,你可以忽略不计,end参数倒是经常用。
不管在Python2还是3里面,都是作打印而已,但是在打印的同时,print会自动加一个换行符(\n)换行
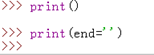
请看,我这什么都没打印,还是换了一行。(我用的是Python3)

好的,此时我用end参数就可以修改默认的换行符:
我把end参数等于一个空字符串后,print不再自动换行了,后期你可能还会遇到换成其他字符的,比如换成一个分隔符,占位符等等的。
说到,那不得不提一个知识——转义符“\”
这个转义符有什么用呢?它有两个作用:
逻辑断行
转义特殊字符
逻辑断行:
先看例子:

由于因为内容太多,一行放不完,这时我们就可以用\在结尾作逻辑断行:

但是对于Python而言,它发现你用了‘\’作逻辑断行它就知道这上下其实是一行。
转义特殊字符
我们先看个例子,打印一个文件路径:

乍一看好像没什么问题对吧?是的,这个它确实没问题,嘻嘻。
那么再看下这个路径呢:
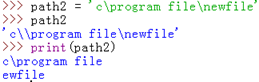
发现换行了对吧,因为什么呢?因为它把”file\newfile”里的”\n”当成一个换行符并转义成换行符了,所以会换行。
那么我们不想让它这样呢?办法是有的,换行符关键的就是这个反斜杠(\)嘛,它自身是一个换行符,那我让转义自己呢:

可行,问题已解决。
那么假如说我这个文件路径很长呢:path3 = 'c\now\now\now\new\new\now\new....'
这里你就可以使用原始字符串——‘r’了:

好的,这个问题解决了
那么如果这个字符串结尾处刚好是一个转义符又怎么样呢:

用原始字符串的方法不行,怎么办呢?除了结尾处,前面的我们都用原始字符串解决了对吧?那么把这结尾单独转义一下呗:

其他的转义符:(暂且不用记,用到的时候再回过来看,用多了就记住了)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
input输入
学完前面的知识,相信你已经越来越觉得上面那些功能不够你用了,总是很死板的设定一个变量值,然后做个运算或者转换处理然后输出,你可能渐渐觉得这样有点low了对吧,你想用更高级点的语法,因为你发现市面上很多软件或者网站都有让用户自己输入的选项,用户输入什么,这个数据它就永远是什么。那么Python里有没有这个功能呢?那当然是有的,这个功能就是Input函数的功能
当我们敲下input()时回车:
空白处就是需要用户自己输入,输入什么它就会返回什么:

那么这个值我们自然也可以用变量临时存储起来:

注意:在Python3中input函数会把你输入的任何数据自动转为字符串:

那么有朋友想到个问题,既然input会自动转为字符串,那么我就是要整形怎么办呢?简单,类型转换啊:

在Python2中,input输入什么这个值就是什么类型,也就是说你要提前设定数据类型:

为什么报错呢,是因为input它不识别你这“asdf”,发现“asdf”是未定义的值
所以要加引号才行:

所以如果你使用的时Python2的话怎么办?Python2里有个raw_input函数:

换句话说,Python2中的raw_input等同于Python3里的input
其实input函数还可以作提示的:
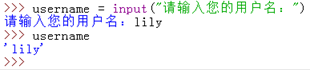
有提示也有输入,这才是真正的与用户达到交互式了。那么我们可以得出结论,input函数即有输入也有输出的功能
字符集编码
学完上面的字符数据操作,相信聪明的你想过这些字符数据是怎么存放在磁盘里的对吧?从第一章的计算机常识里你已经得知计算机只认二进制了,那么存放字符数据自然也是二进制,接着又带来一个新的问题,现在全国各地的程序员,由于语言的不同,存都是二进制,然而要用的时候,一定有一个大家默许的规则,不然会造成不堪的后果。这个规则就是编码了。
字符集编码介绍
什么是编码
编码是国际定义的标准,简单的理解就是计算机中存储数据的格式,在计算机中数据都是以二进制的0和1来进行存储,所以为了把二进制转换为人类可以理解的内容就需要编码来进行转换。而人类写的字符要让计算机识别,也需要转换编码。
并且高级开发语言,都需要解释器解释为机器可以认识的字符。
编码的起源历史
最早出现编码是美国的ASCII,但是ASCII只有26个英文字母以及一些标点符号,欧洲国家为了更方便的使用,也设计了一套EASCII,包含了拉丁字符,慢慢的中国计算机行业发展起来后也设计了一套编码GB2312,收录了大部分常用简体字,并且包括日韩文里使用的汉字,台湾同胞因为使用繁体字,也设计了一套编码big5。后面国人希望统一一下,在BG2312之上做了个升级版GBK,收录更多的简体字,包括了繁体字以及少数名族的使用的文字;日本和韩国也都各自设计了自己的一套编码。然后很多国家都有了自己的一套的编码。
所以市面上就有了一大批的编码,国与国之间交流也困难,那么既然我们人与人之间交流需要一个通用的语言,计算机界也有了这么一套通用语言,最后国际协会决定统一下编码,推出一套万国码——Unicode,整合了全球所有的编码,可以直接支持全球所有的语言,就像英语是全球通用的语言一样了,并且Unicode直接解决了字符与二进制之间的映射关系,不用再考虑不同语言的存取问题了。
不过Unicode还有一个问题,由于Unicode字符集是一个字符占2-4字节的,由于最开始使用ASCII时一个字母是只占一个字节的,这样就很浪费空间了(比如‘age’这个单词使用Unicode需要占6个字节,但使用ASCII码只占3个字节)。所以国际协会又想了一招,做了个优化,出现了一个新的编码——UTF-8,UTF-8默认使用1个字符,不够则增加,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个。
注意:
UTF-8还是属于Unicode,只是Unicode其中一个优化版本,其实还有其他UTF-16,Utf-32之类的。
UTF-8编码英文只占1一个字节,中文占三个字节
GBK、GB2312编码下中文仅占两个字节,所以国内很多公司或者网站还是使用的GBK或BG2312
python2和python3的编码
了解完字符集编码,是不是觉得很简单,先别这么认定,因为它可是最容易出问题的,并且在Python中这个编码问题一直是老生常谈的问题,很多程序员在工作之后好几年都没有真正理解字符编码,还有一部分程序员自认为自己理解了,当在开发中才发现其实并没有真正理解。
在Python3里是Unicode编码,Python2里是ASCII编码(当时Python2出现时还没有Unicode编码)
现在我们看下Python2和Python3下不同的编码,打开操作系统的终端进入python:
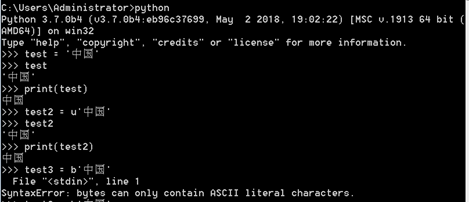

在声明字符串时在前面加u表示以Unicode形式,加b表示以bytes形式。Python3里用b转字节报错其实是对的,这里下面会解释
看到上面的简单例子,确实发现Python两个版本的编码不同了吧。'\xd6\xd0\xb9\xfa'这个是16进制的字节,这里要说一下,我们知道二进制由于太长比如00101110011之类,要表示一个数据的字节太长了不方便,所以存储是的的确确以二进制存储的,只是用十六进制来表示。那么这里有个问题,就算Python3默认是unicode但是不管怎么打印还是一样的,那么就可以肯定,Python3一定自动帮我们做了编码解码操作。而Python2里没有自动帮助我们,在Python两个版本里都有一个解码(decode)和编码(encode)方法,也就是前面字符串操作里的这两个方法,在这里就要派上用场了,我们就可以用这两个方法手动编码解码:
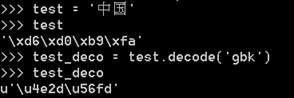
decode方法需要给一个参数,这个参数必须字符之前的字符编码匹配,所有的字节解码都会解码成Unicode
比如这里的‘中国’,我们用gbk就正确解码了。但是有朋友要问了,我们这里没有给字符集编码它怎么自己就存储成gbk编码了,因为我这里使用的是windows的cmd终端,这个终端默认是使用gbk的,所以给存成gbk了。使用chcp命令可以查看得知:936即代表gbk编码了

不信的话可以用encode方法验证:

这里编码成gbk之后确实和最初的test一样的。
encode方法需要给一个参数,这个参数可以是任意字符集编码
既然可以编码成任意字符集编码,编译成utf-8和之前的对比:

这个“涓x浗”是啥啊?这个其实就是乱码了,为什么呢?因为Python2里的print语句会带有一点读取的意思,所以读取的时候由于“中国”本来就是gbK的(windows的cmd终端自动设置了),这里解码成unicode之后编码成utf-8肯定不识别啊,因为没有对应的编码集可以正确解码,只是刚好在编码集里有这些字符集被错误解释出来了,但是是毫无意义的字符。有朋友想到了,前面不是说已经支持中文了吗?确实支持了,但是支持的是Unicode啊,utf-8并不是支持,虽然utf-8也是unicode里的一个分支。而上面的test_deco就是unicode啊,print的时候是正常的。
那么Python2为什么会造成这种不可思议的问题呢?先看下类型看看呢:

这什么情况?test是gbk的字节,test_utf是utf-8的字节,怎么会显示的类型是字符串呢?答案是Python2里bytes = str,是的在Python2里居然把字节和字符等同了(前面我们说了字节和字符完全是不同的),这就是最根本的问题所在,而且还有一种新的字符类型unicode。这样也侧面说明了Python2里字符类型只有str和unicode
而Python3里:

由于Python3里字符串方法里已经不存在decode方法(因为已经默认是unicode编码了)
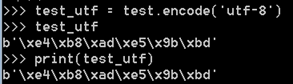
编码为utf-8之后看下类型:
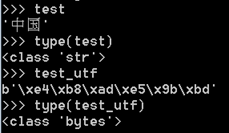
Python3里是一切正常的,因为编码本来就会变成字节,然后交给计算机处理,我们要查看和使用时再解码的,这里没有Python2那么特殊。
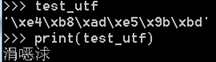
所以可以得出结论:Python3里的字符类型是str和bytes,python3里btyes就是bytes,并不像Python2里bytes等同于str,且python2里的Unicode等同于Python3里的str
总结
在python2里,本来存储的是字节,print时会成为str
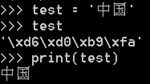
但转为元祖类型就显原型,在日后的操作时如果遇到这样的情况,使用for循环或者利用数组类型取数据的方法取出来就行:
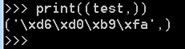
如果在后期遇到编码问题时你仍是无法理解,不知道怎么解决,你可以使用Python3操作,问题立马解决。
使用编辑器操作时,通常会在文件开头加一行此代码:# coding:utf-8定义一个统一编码,表示此文件里通用该编码:以防出现不可避免的问题
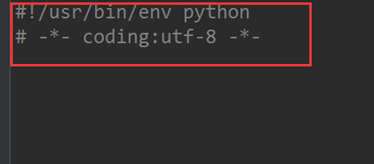
#!/usr/bin/env python 是linux操作系统下会使用的声明,表示告诉linux运行文件时这是Python文件,以Python形式运行。
python高级(1)—— 基础回顾1的更多相关文章
- Python高级语法-贯彻回顾-元类(4.99.1)
@ 目录 1.为什么要掌握元类 2.正文 关于作者 1.为什么要掌握元类 在django中编写models的时候遇到了元类的相关操作 并且在mini-web框架编写的时候也遇到了相关的问题 意识到深入 ...
- python 基础回顾 一
Python 基础回顾 可变类型:list ,dict 不可变类型:string,tuple,numbers tuple是不可变的,但是它包含的list dict是可变的. set 集合内部是唯一的 ...
- 一凡老师亲录视频,Python从零基础到高级进阶带你飞
如需Q群交流 群:893694563 不定时更新2-3节视频 零基础学生请点击 Python基础入门视频 如果你刚初入测试行业 如果你刚转入到测试行业 如果你想学习Python,学习自动化,搭建自动化 ...
- Python学习入门基础教程(learning Python)--5.6 Python读文件操作高级
前文5.2节和5.4节分别就Python下读文件操作做了基础性讲述和提升性介绍,但是仍有些问题,比如在5.4节里涉及到一个多次读文件的问题,实际上我们还没有完全阐述完毕,下面这个图片的问题在哪呢? 问 ...
- 老男孩Python高级全栈开发工程师三期完整无加密带课件(共104天)
点击了解更多Python课程>>> 老男孩Python高级全栈开发工程师三期完整无加密带课件(共104天) 课程大纲 1.这一期比之前的Python培新课程增加了很多干货:Linux ...
- 老男孩Python高级全栈开发工程师【真正的全套完整无加密】
点击了解更多Python课程>>> 老男孩Python高级全栈开发工程师[真正的全套完整无加密] 课程大纲 老男孩python全栈,Python 全栈,Python教程,Django ...
- Javascript基础回顾 之(二) 作用域
本来是要继续由浅入深表达式系列最后一篇的,但是最近团队突然就忙起来了,从来没有过的忙!不过喜欢表达式的朋友请放心,已经在写了:) 在工作当中发现大家对Javascript的一些基本原理普遍存在这里或者 ...
- Javascript基础回顾 之(一) 类型
本来是要继续由浅入深表达式系列最后一篇的,但是最近团队突然就忙起来了,从来没有过的忙!不过喜欢表达式的朋友请放心,已经在写了:) 在工作当中发现大家对Javascript的一些基本原理普遍存在这里或者 ...
- python高级之装饰器
python高级之装饰器 本节内容 高阶函数 嵌套函数及闭包 装饰器 装饰器带参数 装饰器的嵌套 functools.wraps模块 递归函数被装饰 1.高阶函数 高阶函数的定义: 满足下面两个条件之 ...
随机推荐
- 【原创】驱动加载之OpenService
SC_HANDLE WINAPI OpenService( _In_ SC_HANDLE hSCManager, _In_ LPCTSTR lpServiceName, _In_ DWORD dwDe ...
- mcrypt加密以及解密过程
Mcrypt库支持20多种加密算法和8种加密模式,具体可以通过函数mcrypt_list_algorithms()和mcrypt_list_modes()来显示 Mcrypt扩展库可以实现加密解密功能 ...
- 机器学习排序算法:RankNet to LambdaRank to LambdaMART
使用机器学习排序算法LambdaMART有一段时间了,但一直没有真正弄清楚算法中的所有细节. 学习过程中细读了两篇不错的博文,推荐给大家: 梯度提升树(GBDT)原理小结 徐博From RankNet ...
- awk知识点总结
find+xargs+grep+sed+awk系列文章:http://www.cnblogs.com/f-ck-need-u/p/7048359.html 0.学习资料推荐 1.awk入门:看视频.找 ...
- Redis主从复制、多实例、高可用(三)--技术流ken
Redis主从复制 在开始实现redis的高可用之前,首先来学习一下如何实现redis的主从复制,毕竟高可用也会依赖主从复制的技术. Redis的主从复制,可以实现一个主节点master可以有多个从节 ...
- MVC学习之路(1) EF 增删查改合集
首先再Model中创建一个类[WMBlogDB] public class WMBlogDB : DbContext { //连接字符串. public WMBlogDB() : base(" ...
- WPF DevExpress ChartControl用法
WPF常用的第三方控件集,DevExpress中ChartControl的使用 下面介绍如何生成Chart界面: <dxc:ChartControl AnimationMode="On ...
- 浅谈select for update 和select lock in share mode的区别
有些情况下为了保证数据逻辑的一致性,需要对SELECT的操作加锁.InnoDB存储引擎对于SELECT语句支持两种一致性的锁定读(locking read)操作. . SELECT …… FOR UP ...
- Java基础IO流(二)字节流小案例
JAVA基础IO流(一)https://www.cnblogs.com/deepSleeping/p/9693601.html ①读取指定文件内容,按照16进制输出到控制台 其中,Integer.to ...
- 你所不知道的JSON.stringify
译者按: 老司机们,你知道JSON.stringify还有第二个和第三个可选参数吗?它们是什么呢? 原文: What you didn’t know about JSON.Stringify 译者: ...