Python 爬虫一 简介
什么是爬虫?
爬虫可以做什么?
爬虫的本质
爬虫的基本流程
什么是request&response
爬取到数据该怎么办
什么是爬虫?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据
爬虫可以做什么?
你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到。
爬虫的本质是什么?
上面关于爬虫可以做什么,定义了一个前提,是浏览器可以访问到的任何资源,特别是对于知晓web请求生命周期的学者来说,爬虫的本质就更简单了。爬虫的本质就是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
浏览器打开网页的过程:
1、在浏览器的输入地址栏,输入想要访问的网址。
2、经过DNS服务器找到服务器主机,向服务器发送一个请求
3、服务器经过解析处理后返回给用户结果(包括html,js,css文件等等内容)
4、浏览器接收到结果,进行解释通过浏览器屏幕呈现给用户结果
上面我们说了爬虫的本质就是模拟浏览器自动向服务器发送请求,获取、处理并解析结果的自动化程序。
爬虫的关键点:模拟请求,解析处理,自动化。
爬虫的基本流程
发起请求
通过HTTP库向目标站点发起请求(request),请求可以
包含额外的header等信息,等待服务器响应
获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型
解析内容
得到的内容可能是HTML,可以用正则表达式,页面解析库进行解析,可能是Json,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理
保存数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
Request & Response
浏览器发送消息给网址所在的服务器,这个过程就叫做HTPP Request
服务器收到浏览器发送的消息后,能够根据浏览器发送消息的内容,做相应的处理,然后把消息回传给浏览器,这个过程就是HTTP Response
浏览器收到服务器的Response信息后,会对信息进行相应的处理,然后通过显示器呈现给用户
我们以访问百度为例:
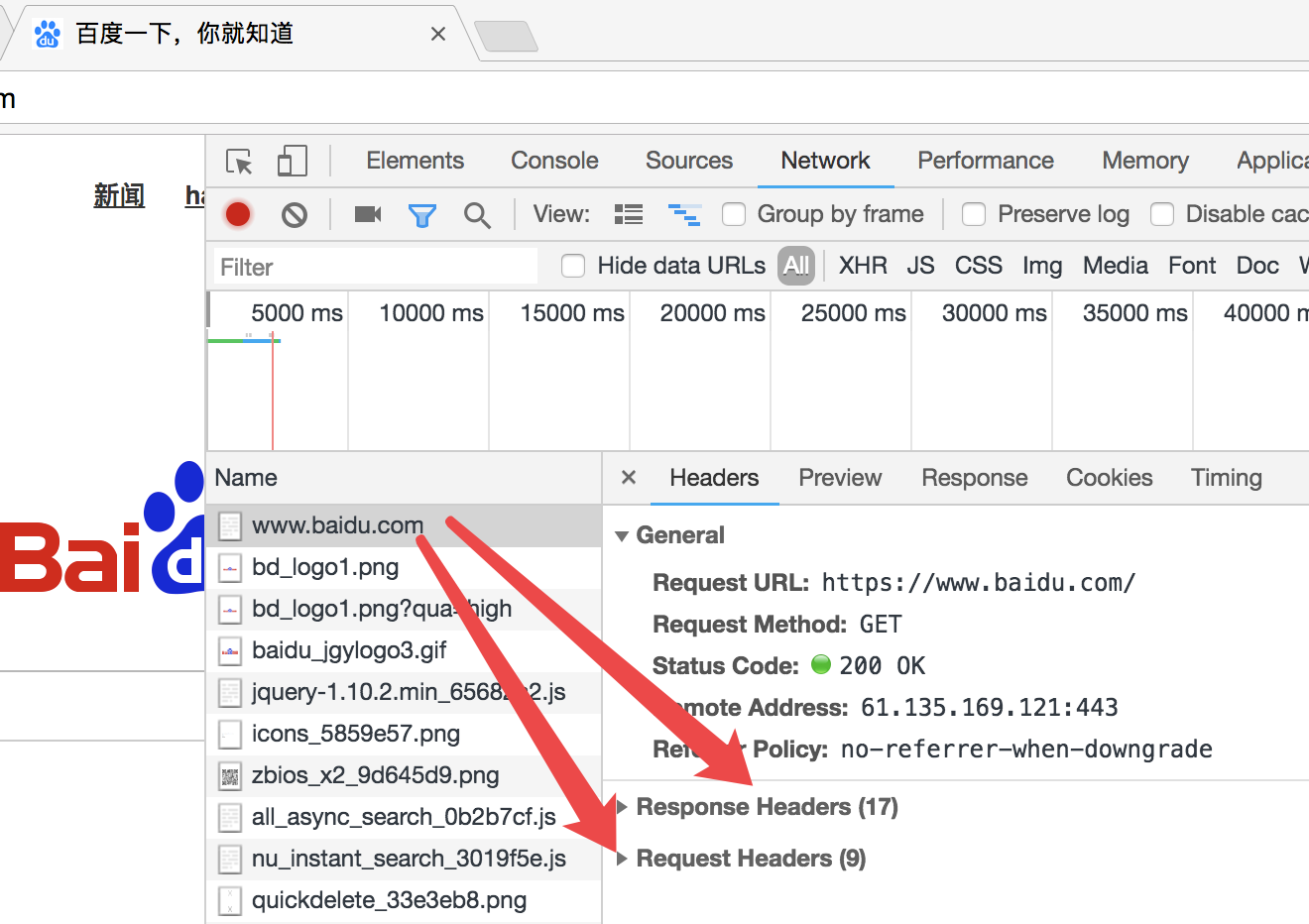
Request中包含什么?
请求方式
主要有:GET/POST两种类型常用,另外还有HEAD/PUT/DELETE/OPTIONS
GET和POST的区别就是:请求的数据GET是在url中,POST则是存放在头部
GET:向指定的资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中。其中一个原因是GET可能会被网络蜘蛛等随意访问
POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
HEAD:与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回资源的本文部分。它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据)。
PUT:向指定资源位置上传其最新内容。
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作。
DELETE:请求服务器删除Request-URI所标识的资源。
请求URL
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的格式由三个部分组成:
第一部分是协议(或称为服务方式)。
第二部分是存有该资源的主机IP地址(有时也包括端口号)。
第三部分是主机资源的具体地址,如目录和文件名等。
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
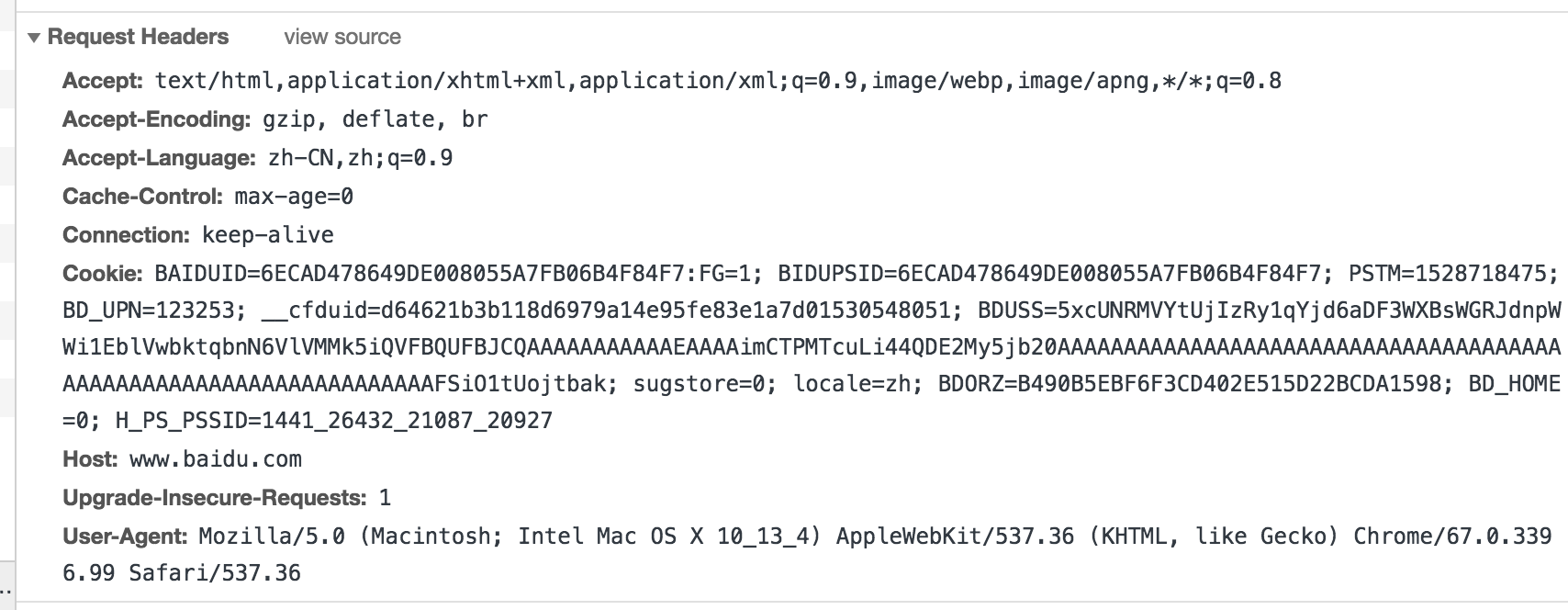
请求头
包含请求时的头部信息,如User-Agent,Host,Cookies等信息,下图是请求请求百度时,所有的请求头部信息参数
请求体
请求是携带的数据,如提交form表单数据时候的表单数据(POST)
Response中包含了什么
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
响应状态
有多种响应状态,如:200代表成功,301跳转,404找不到页面,502服务器错误
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误 常见代码: 200 OK 请求成功 400 Bad Request 客户端请求有语法错误,不能被服务器所理解 401 Unauthorized 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden 服务器收到请求,但是拒绝提供服务 404 Not Found 请求资源不存在,eg:输入了错误的URL 500 Internal Server Error 服务器发生不可预期的错误 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常 301 目标永久性转移 302 目标暂时性转移
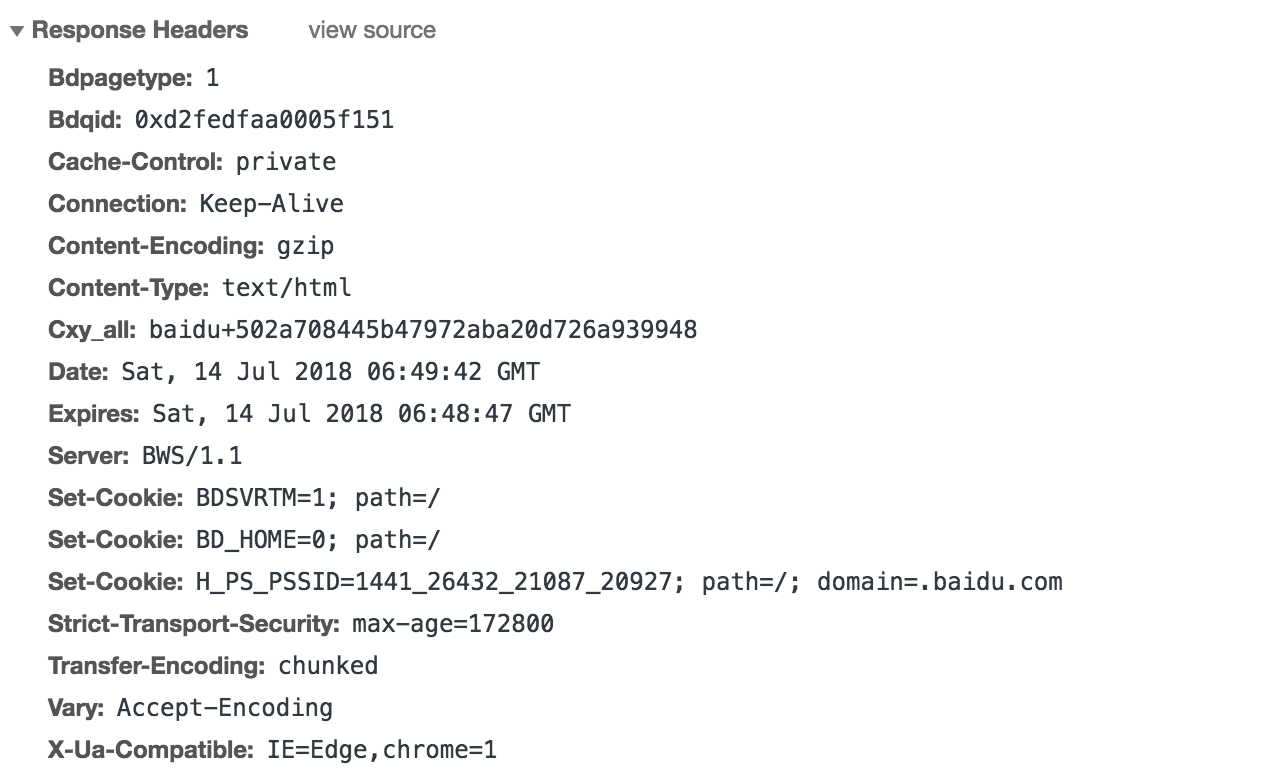
响应头
如内容类型,类型的长度,服务器信息,设置Cookie,如下图:
响应体
最主要的部分,包含请求资源的内容,如网页HTMl,图片,二进制数据等
爬取数据类型
网页文本:如HTML文档,Json格式化文本等
图片:获取到的是二进制文件,保存为图片格式
视频:同样是二进制文件
其他:只要请求到的,都可以获取
解析数据方法
直接处理
Json解析
正则表达式处理
BeautifulSoup解析处理
PyQuery解析处理
XPath解析处理
关于抓取的页面数据和浏览器里看到的不一样的问题
出现这种情况是因为,很多网站中的数据都是通过js,ajax动态加载的,所以直接通过get请求获取的页面和浏览器显示的不同。 如何解决js渲染的问题? 分析ajax
Selenium/webdriver
Splash
PyV8,Ghost.py
保存数据
文本:纯文本,Json,Xml等
关系型数据库:如mysql,oracle,sql server等结构化数据库
非关系型数据库:MongoDB,Redis等key-value形式存储
Python 爬虫一 简介的更多相关文章
- Python爬虫教程-04-response简介
Spider-04-response简介 本小节介绍urlopen的返回对象,和简单调试方法 案例v3 研究request的返回值,输出返回值类型,打印内容 geturl:返回请求对象的url inf ...
- Python爬虫教程-20-xml 简介
本篇简单介绍 xml 在python爬虫方面的使用,想要具体学习 xml 可以到 w3school 查看 xml 文档 xml 文档链接:http://www.w3school.com.cn/xmld ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- python 爬虫简介
初识Python爬虫 互联网 简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML.JS.CSS代码返回给浏览器,这些代码经过浏览器解析.渲染,将丰富多彩的网页呈现 ...
- Python 爬虫与HTTP协议简介
爬虫的实际例子: 搜索引擎(百度.谷歌.360搜索等). 伯乐在线. 惠惠购物助手. 数据分析与研究(数据冰山知乎专栏). 抢票软件等. 什么是网络爬虫: 通俗理解:爬虫是一个模拟人类请求网站行为的程 ...
- Python爬虫入门
Python爬虫简介(来源于维基百科): 网络爬虫始于一张被称作种子的统一资源地址(URLs)列表.当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张"待访列表",即 ...
- python爬虫利器Selenium使用详解
简介: 用pyhon爬取动态页面时普通的urllib2无法实现,例如下面的京东首页,随着滚动条的下拉会加载新的内容,而urllib2就无法抓取这些内容,此时就需要今天的主角selenium. Sele ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
随机推荐
- python基础之IO编程
读文件 with open('/path/to/file', 'r') as f: print(f.read()) 调用read()会一次性读取文件的全部内容,read()函数里面可以传入每次最多读取 ...
- Spring MVC 架构的java web工程如何添加登录过滤器
发布到外网的web工程必须添加登录过滤器来阻挡一些非法的请求,即只有登录的用户才能对web工程进行请求,否则无论请求什么资源都需要调整到登录页面进行登录操作.这时就需要用到过滤器,其实非常简单,只需要 ...
- io系列之字符流
java中io流系统庞大,知识点众多,作为小白通过五天的视频书籍学习后,总结了io系列的随笔,以便将来复习查看. 本篇为此系列随笔的第一篇:io系列之字符流. IO流 :对数据的传输流向进行操作,ja ...
- adb导出安卓 把手机内存文件导入到电脑里 adb安装软件
记得先找对路劲adb shellls 最上面的ls: ./ 打头的没有权限.而下面的这些acct sdcard等 都有权限. 然后cd sdcardls 看下目录,发现gxm文件夹在sdcard下面. ...
- Android app:transformNativeLibsWithStripDebugSymbolForDebug错误分析
升级NDK解决问题: 先清除 Android/Sdk/ndk-bundle/ 下的内容从 https://developer.android.google.cn/ndk/downloads/older ...
- Redis的主从复制的原理介绍
redis主从复制 和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或 ...
- (字典序问题) nyoj1542-最小字符串
题目描述: 给你一个由小写字母组成的字符串,最多删除其中一个字符,使其字典序最小. 字典序概念在数学中,字典或词典顺序(也称为词汇顺序,字典顺序,字母顺序或词典顺序)是基于字母顺序排列的单词按字母顺序 ...
- tcpdump高级过滤
一:查看帮助选项 tcpdump --help Usage: tcpdump [-aAbdDefhHIJKlLnNOpqStuUvxX#] [ -B size ] [ -c count ] [ -C ...
- [NIO-4]选择器
选择器 最后,我们探索一下选择器.由于选择器内容比较多,所以本篇先偏理论地讲一下,后一篇讲代码,文章也没有什么概括.总结的,写到哪儿算哪儿了,只求能将选择器写明白,并且将一些相对重要的内容加粗标红. ...
- C#与 微信小程序 互为加解密方案
CryptoJS下载地址: https://code.google.com/archive/p/crypto-js/downloads http://download.csdn.net/detail/ ...