Python_数据类型的补充、集合set、深浅copy
1、数据类型的补充
1、1 元组
当元组里面只有一个元素且没有逗号时,则该数据的数据类型与括号里面的元素相同。
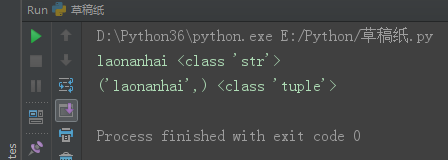
tu1 = ('laonanhai')
tu2 = ('laonanhai')
print(tu1, type(tu1))
print(tu2, type(tu2),)
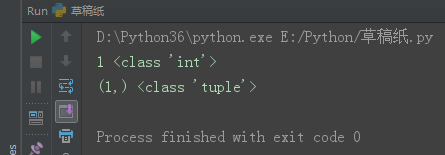
tu1 = (1)
tu2 = (1,)
print(tu1, type(tu1))
print(tu2, type(tu2))
tu1 = ([1, 2, 3])
tu2 = ([1, 2, 3],)
print(tu1, type(tu1))
print(tu2, type(tu2))

1、2 list 列表
在循环一个列表时,最好不要改变列表的大小,会影响你的最终结果。
li = [111, 222, 333, 444, 555,],索引为奇数的所有元素全部删除。
方法一:
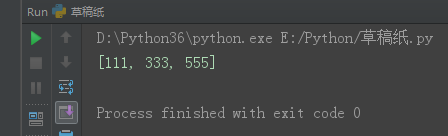
l1 = [111, 222, 333, 444, 555, ]
del l1[1::2]
print(l1)
方法二(错误展示):
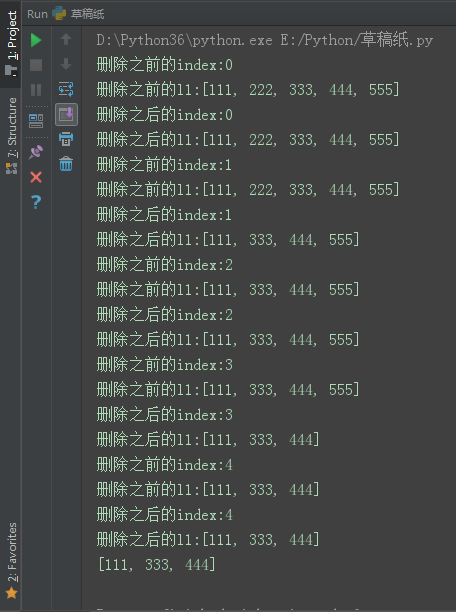
l1 = [111, 222, 333, 444, 555, ]
for index in range(len(l1)):
print('删除之前的index:%s' % index)
print('删除之前的l1:%s' % l1)
if index % 2 == 1:
del l1[index]
print('删除之后的index:%s' % index)
print('删除之后的l1:%s' % l1)
print(l1)
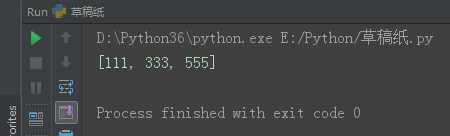
方法三(倒着删):
l1 = [111, 222, 333, 444, 555, ]
for index in range(len(l1) - 1, -1, -1):
if index % 2 == 1:
del l1[index]
print(l1)
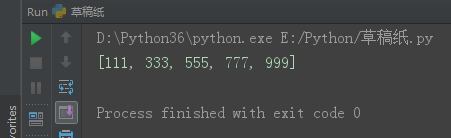
方法四(自己做的):
l1 = [111, 222, 333, 444, 555, 666, 777, 888, 999, ]
i = len(l1)
count = 1
s = int(len(l1)/2)
for j in range(s):
del l1[count]
count += 1
print(l1)
1、3 字典
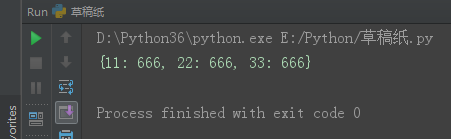
1、3、1 dict.fromkeys(A, B) A为可迭代对象,B任意。创建一个字典,迭代A的最小元素为键,B为值。
dic = dict.fromkeys('abc', 666)
print(dic)

dic = dict.fromkeys([11, 22, 33], 666)
print(dic)
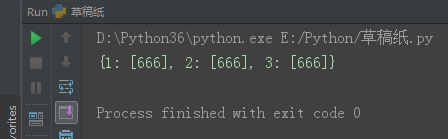
dic = dict.fromkeys([1, 2, 3], [])
dic[1].append(666)
print(dic)
1、3、2 在循环字典时,最好不要改变字典的大小,会影响结果或者报错。
错误示例:
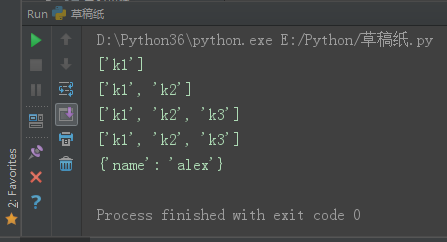
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
for i in dic:
if 'k' in i:
del dic[i]
print(dic)

dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
l1 = []
for key in dic:
if 'k' in key:
l1.append(key)
print(l1)
for key in l1:
del dic[key]
print(dic)
1、4 数据类型的转换
str ------> list:
split
list ----->str:
join
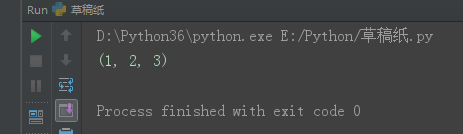
tuple ------> list:
tu1 = (1, 2, 3)
l1 = list(tu1)
print(l1)

list ------> tuple:
tu1 = (1, 2, 3)
l1 = list(tu1)
tu2 = tuple(l1)
print(tu2)
dic ------> list:
list(dic) 列表中只有key。
dic = {'k1': 'v1', 'k2': 'v2','k3': 'v3',}
l1 = list(dic)
print(l1)
print(list(dic.keys()))
print(list(dic.values()))
print(list(dic.items()))

0, '',[], {},() ------> bool都是False。
print(bool(0))
print(bool(''))
print(bool(()))
print(bool([]))
print(bool({}))

print(bool([0, 0, 0]))

2、set 集合
set1 = {1, 2, 3, 'abc', (1, 2, 3), True, }
print(set1)

2、1 去重
集合去重。
set2 = {11, 11, 11, 22}
print(set2)

列表的去重。
l1 = [11, 11, 22, 22, 33, 33, 33, 44]
l2 = list(set(l1))
l2.sort()
print(l2)

2、2 增
__.add('A') A为添加的内容,随机添加。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.add('太白')
print(set1)

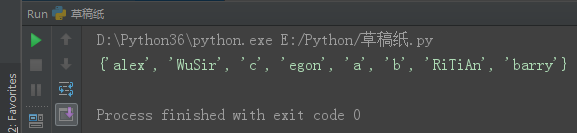
__.update('A') A为添加的可迭代内容,将A拆分为最小单元然后迭代添加。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.update('abc')
print(set1)
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.update([111, 2222, 333])
print(set1)

2、3 删
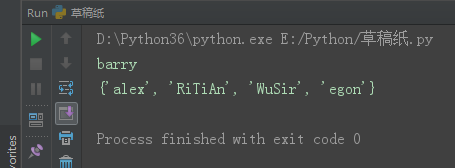
__.remove('A') 按元素删除。A为需要删除的内容。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.remove('RiTiAn')
print(set1)

__.pop() 随机删除,有返回值。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
print(set1.pop())
print(set1)
__.clear() 清空集合。 空集合为set()。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
set1.clear()
print(set1)

del __ 删除集合。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
del set1
print(set1)
2、4 查
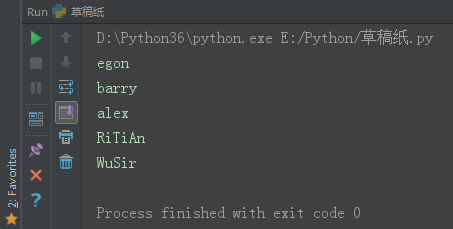
for循环。
set1 = {'alex', 'WuSir', 'RiTiAn', 'egon', 'barry'}
for i in set1:
print(i)
2、5 交集
交集:__ & __ 或者 __.intersection(__)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 & set2
print(set3)

set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.intersection(set2)
print(set3)

2、6 并集
并集:__ | __ 或者 __.union(__)
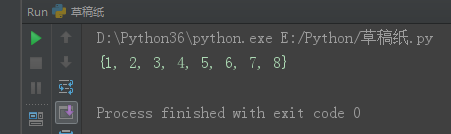
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 | set2
print(set3)
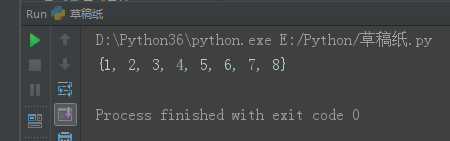
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.union(set2)
print(set3)
2、7 差集
差集:__ - __ 或者 __.difference(__)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 - set2
print(set3) # set1独有的
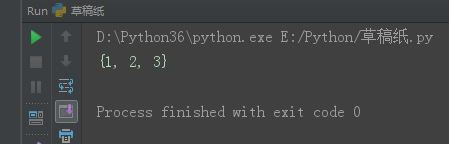
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.difference(set2) # set1独有的
print(set3)

2、8 反交集
反交集:__ ^ __ 或者 __.symmetric_difference(__)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1 ^ set2
print(set3)
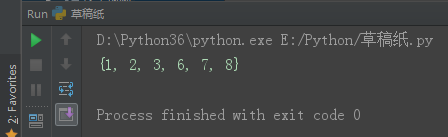
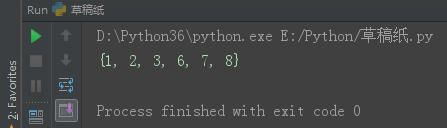
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
set3 = set1.symmetric_difference(set2)
print(set3)
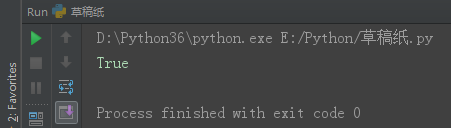
2、9 子集
子集:__ < __ 或者 __.issubset(__)
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 < set2) # True set1 是set2 的子集
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set1.issubset(set2)) # True set1是set2的子集

2、10 超集
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set2 > set1) # set2 是 set1 的超集
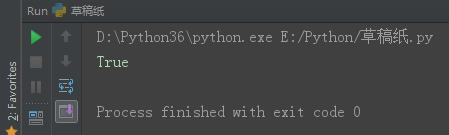
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set2.issuperset(set1)) # set2 是 set1 的超集
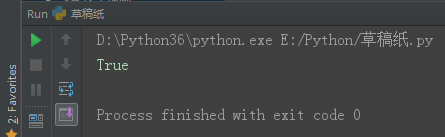
frozenset() frozenset是冻结的集合,它是不可变的,存在哈希值,好处是它可以作为字典的key,也可以作为其它集合的元素。缺点是一旦创建便不能更改,没有add,remove方法。
set1 = frozenset({1, 2, 3, 'alex'})
print(set1)
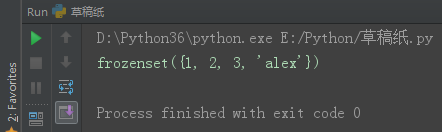
3、深浅copy
对于赋值运算来说,指向的都是同一个内存地址,一变都变。
l1 = [1, 2, 3]
l2 = l1
l3 = l2
l3.append(666)
print(l1, l2, l3)
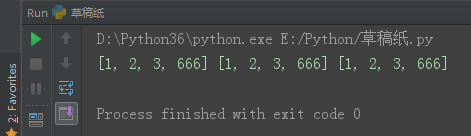
3、1 浅copy
copy.() 浅copy
l1 = [11, 22, 33]
l2 = l1.copy()
l1.append(666)
print(l1, id(l1))
print(l2, id(l2))
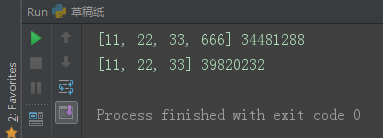
当列表内层列表增加元素时,浅copy跟随变化。内层的列表同样是同一个地址。
对于浅copy来说,第一层创建的是新的内存地址,从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
l1 = [11, 22, ['barry', [55, 66]], [11, 22]]
l2 = l1.copy()
l1[2].append('alex')
print(l1, id(l1))
print(l2, id(l2))
print(l1, id(l1[-1]))
print(l2, id(l2[-1]))

3、2 深copy
import copy
import copy
l1 = [11, 22, 33]
l2 = copy.deepcopy(l1)
l1.append(666)
print(l1, id(l1))
print(l2, id(l2))
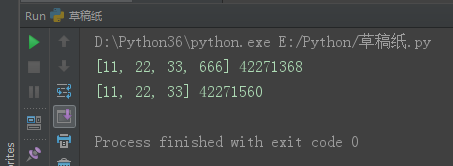
import copy
l1 = [11, 22, ['barry']]
l2 = copy.deepcopy(l1)
l1[2].append('alex')
print(l1, id(l1[-1]))
print(l2, id(l2[-1]))

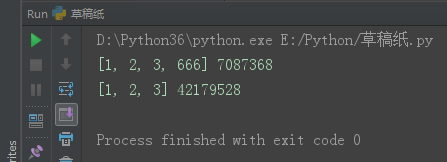
深copy 完全独立。
l1 = [1, 2, 3]
l2 = [1, 2, 3]
l1.append(666)
print(l1, id(l1))
print(l2, id(l2))
对于切片来说,这是浅copy。
l1 = [1, 2, 3, 4, 5, 6, [11, 22]]
l2 = l1[:]
l1.append(666)
print(l1, l2)
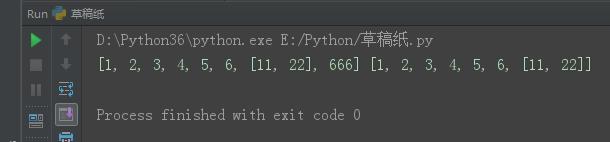
l1 = [1, 2, 3, 4, 5, 6, [11, 22]]
l2 = l1[:]
l1[-1].append(666)
print(l1, l2)
Python_数据类型的补充、集合set、深浅copy的更多相关文章
- python基础之数据类型操作补充,集合及其操作,深浅拷贝
内容概要: 数据类型操作补充 集合及其操作 深浅拷贝1.基础数据类型补充 1.1字符串的操作补充li = ["李嘉诚", "麻花藤", "黄海峰&qu ...
- python之数据类型补充、集合、深浅copy
一.内容回顾 代码块: 一个函数,一个模块,一个类,一个文件,交互模式下,每一行就是一个代码块. is == id id()查询对象的内存地址 == 比较的是两边的数值. is 比较的是两边的内存地址 ...
- python 的基础 学习 第八天数据类型的补充 ,集合和深浅copy
1,数据类型的补充: 元组()tuple,如果只有元素,并且没有逗号,此元素是什么数据类型,该表达式就是什么数据类型. tu = ('rwr') print(tu,type(tu)) tu = ('r ...
- 基础数据类型之集合和深浅copy,还有一些数据类型补充
集合 集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的.以下是集合最重要的两点: 去重,把一个列表变成集合,就自动去重了. 关系 ...
- day 07 数据类型,集合,深浅copy
1.day 06 内容回顾 小数据池 int :-5-256 str:特殊字符 ,*20 ascii:8位 1字节 表示一个字符 unicode:32位 4个字节 , 表示一个字符 字节表示8位表示一 ...
- python-基础数据类型,集合及深浅copy
一 数据类型定义及分类 我们人类可以很容易的分清数字与字符的区别,但是计算机并不能呀,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘汉’的区 ...
- 基础数据类型的坑和集合及深浅copy
一.基础数据类型的坑: 元组: 如果一个元组中,只有一个元素,且没有逗号,则该"元组"与里面的数据的类型相同. # 只有一个数据,且没有逗号的情况: print(tu1,type( ...
- 07、python的基础-->数据类型、集合、深浅copy
一.数据类型 1.列表 lis = [11, 22, 33, 44, 55] for i in range(len(lis)): print(i) # i = 0 i = 1 i = 2 del li ...
- 数据结构中的列表、元组、字典、集合 ,深浅copy
数据结构:数据结构是计算机存储数据和组织数据的方式.数据结构是指相互之间存在一种或多种特定关系的数据元素的集合.在python中主要的数据类型统称为容器. 而序列(如列表.元组).映射(如字典).集合 ...
随机推荐
- (转)Eclipse中快速输入System.out.println()的快捷键
https://blog.csdn.net/ShiMengRan107/article/details/73614417 善用 Eclipse 组合键,可以提高输入效率. Step1: Eclipse ...
- 怎么将后缀为.opt,.frm,.myd,.myi文件还原或者是导入mySQL中
其实这个问题的解决方案很简单,把这些文件连同这些文件所在的文件夹原封不动地复制到你的 mysql 文件夹下的 data 里面 (在我的电脑里面是D:\xampp\mysql\data), 然后你进my ...
- 【Linux基础】alias命令指定别名
1.alias命令 alias是一个系统自建的shell命令,允许你为名字比较长的或者经常使用的命令指定别名. alias //显示当前定义的所有别名 alias ll='ls -l' //定义别名l ...
- Thread.currentThread()和this的区别——《Java多线程编程核心技术》
前言:在阅读<Java多线程编程核心技术>过程中,对书中程序代码Thread.currentThread()与this的区别有点混淆,这里记录下来,加深印象与理解. 具体代码如下: pub ...
- Linux之系统优化
查看系统版本 [root@luffy- /]# cat /etc/redhat-release CentOS release 6.9 (Final) [root@luffy- /]# uname -m ...
- SQLite的文件锁、并发与pager---(SQLite学习手册(锁和并发控制))
一.概述: 在SQLite中,锁和并发控制机制都是由pager_module模块负责处理的,如ACID(Atomic, Consistent, Isolated, and Durable).在含有数据 ...
- CSS--position:relative和position:absolute
position:relative相对定位 1. 如何定位?每个元素在页面的普通流中会“占有”一个位置,这个位置可以理解为默认值,而相对定位就是将元素偏离元素的默认位置,但普通流中依然保持着原有的默认 ...
- 使用VMWare虚拟mac系统,设置网络的正确姿势
1. 启动mac虚拟机: 2. 虚拟机-虚拟机设置-网络适配器-选择NAT模式: 3. 打开mac的网络设置,选择使用DHCP模式,并设置DNS服务器为win的DNS: 4. 回到win,控制面板-网 ...
- 邮票面值设计 (动态规划+DFS)
题意:https://ac.nowcoder.com/acm/problem/16813 思路: 深度搜索:每一层枚举一个面值,然后通过dp进行检查,并通过已知面值得到最多n张得到的最大表示数. 其实 ...
- 【转】Android多进程总结一:生成多进程(android:process属性)
前言 正常情况下,一个apk启动后只会运行在一个进程中,其进程名为apk的包名,所有的组件都会在这个进程中运行,以下为DDMS的进程截屏: com.biyou.multiprocess为进程名,也是a ...