单例模式实现的多种方式、pickle序列化模块、选课系统需求分析等
单例模式实现的多种方式
方式一:
#方式一:定义一个类方法实现单例模式
class C1:
__instance = None # 定义一个全局变量
def __init__(self, name, age):
self.name = name
self.age = age
# 2、绑定给类的方法
@classmethod
def singleton(cls):
# 3、当使用类调用该方法时,进行判断
if not cls.__instance:
# 4、当类未生成对象时,生成一个对象
cls.__instance = cls('jason', 18)
# 5、当类已生成对象时,将绑定对象的变量返回给调用者
return cls.__instance
# 这里的意思是如果不传参数产生新的对象,始终调用的是同一个对象
obj1 = C1.singleton()
obj2 = C1.singleton()
obj3 = C1.singleton()
print(id(obj1), id(obj2), id(obj3))
obj4 = C1('kevin', 28)
obj5 = C1('tony', 38)
print(id(obj4), id(obj5))
方式二:
#方式二:定制元类实现单例模式
class Mymeta(type):
def __init__(self, name, bases, dic): #定义类Mysql时就触发
# 事先先从配置文件中取配置来造一个Mysql的实例出来
self.__instance = object.__new__(self) # 产生对象
self.__init__(self.__instance, 'jason',18) # 初始化对象
# 上述两步可以合成下面一步
# self.__instance=super().__call__(*args,**kwargs)
super().__init__(name, bases, dic)
def __call__(self, *args, **kwargs): #Mysql(...)时触发
if args or kwargs: # args或kwargs内有值
obj = object.__new__(self)
self.__init__(obj,*args,**kwargs)
return obj
return self.__instance
class Mysql(metaclass=Mymeta):
def __init__(self, name, age):
self.name = name
self.age = age
obj1 = Mysql() # 没有传值则默认从配置文件中读配置来实例化,所有的实例应该指向一个内存地址
obj2 = Mysql()
print(id(obj1), id(obj2))
obj3 = Mysql('tony', 321)
obj4 = Mysql('kevin', 222)
print(id(obj3), id(obj4))
方式三
'''基于模块的单例模式:提前产生一个对象 之后导模块使用'''
class C1:
def __init__(self, name, age):
self.name = name
self.age = age
obj = C1('jason', 18)
方式四
#方式三:定义一个装饰器实现单例模式
def outer(cls):
_instance = cls('jason', 18)
def inner(*args,**kwargs):
if args or kwargs:
obj = cls(*args, **kwargs)
return obj
return _instance
return inner
@outer # Mysql=outer(Mysql)
class Mysql:
def __init__(self, host, port):
self.host = host
self.port = port
obj1 = Mysql()
obj2 = Mysql()
obj3 = Mysql()
print(obj1 is obj2 is obj3) # True
obj4 = Mysql('1.1.1.3', 3307)
obj5 = Mysql('1.1.1.4', 3308)
print(obj3 is obj4) # False
pickle序列化模块
优势:能够序列化python中所有的类型
缺陷:只能够在python中使用,无法跨语言传输 pickle序列化后的数据,可读性差,人一般无法识别。(都是二进制)
"""
需求:产生一个对象并保存到文件中 取出来还是一个对象
"""
class C1:
def __init__(self, name, age):
self.name = name
self.age = age
def func1(self):
print('from func1')
def func2(self):
print('from func2')
obj = C1('jason', 18)
# json模块不可以用
import json
with open(r'a.txt','w',encoding='utf8') as f:
json.dump(obj, f)
import pickle
# pickle是二进制,用wb,rb
with open(r'a.txt','wb') as f:
pickle.dump(obj,f)
with open(r'a.txt','rb') as f:
data = pickle.load(f)
print(data) # <__main__.C1 object at 0x000001748B674B20>
data.func1() # from func1
data.func2() # from func2
选课系统需求分析
选课系统
角色:学校、学员、课程、讲师
要求:
1. 创建北京、上海 2 所学校
2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开
3. 课程包含,周期,价格,通过学校创建课程
4. 通过学校创建班级, 班级关联课程、讲师5. 创建学员时,选择学校,关联班级
5. 创建讲师角色时要关联学校,
6. 提供三个角色接口
6.1 学员视图, 可以注册, 交学费, 选择班级,
6.2 讲师视图, 讲师可管理自己的班级, 上课时选择班级, 查看班级学员列表 , 修改所管理的学员的成绩
6.3 管理视图,创建讲师, 创建班级,创建课程
7. 上面的操作产生的数据都通过pickle序列化保存到文件里
功能提炼
1.管理员功能
注册功能
登录功能
创建学校
创建课程
创建老师
2.讲师功能
登录功能
选择课程
查看课程
查看学生分数
修改学生分数
3.学生功能
注册功能
登录功能
选择学校
选择课程
查看课程分数
选课系统架构设计
三层架构
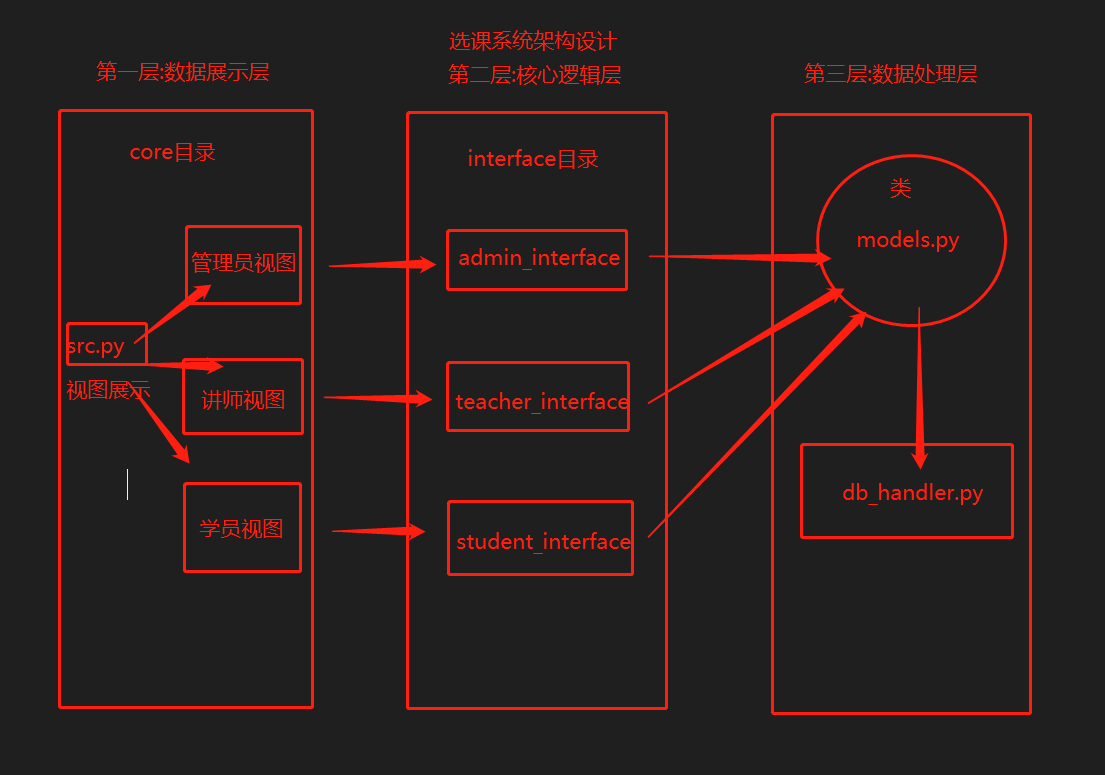
与ATM架构设计的差异
1.第一层做分层展示
2.第三层创建models.py存储所有的类 只有该py文件内的代码有资格调用db_handler
选课系统目录搭建
基于软件开发目录规范即可
选课系统功能搭建
空函数 循环 功能字典
数据保存的时候注意点:
# 当有类名时 可以通过类名.__name__获取对应的字符串名
print(Admin.__name__,type(Admin.__name__))
# 如何通过对象获取类对应的字符串名称
obj = Admin('jason',123)
# 固定方法
当有对象时 可以通过对象.__class.__name__获取对应类的字符串名
print(obj.__class__) # <class '__main__.Admin'> 类名
print(obj.__class__.__name__) # Admin 字符串单例模式实现的多种方式、pickle序列化模块、选课系统需求分析等的更多相关文章
- python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- (转)python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
阅读目录 1.1.1导入模块 1.1.2__name__ 1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代 ...
- json和pickle序列化模块
一.json序列化模块 1.序列化:将内存数据转成字符串加以保存. 2.反序列化:将字符串转成内存数据加以读取. data = { '北京':{ '五道口':{ 'sohu':'引擎', } } } ...
- day14-Python运维开发基础(内置函数、pickle序列化模块、math数学模块)
1. 内置函数 # ### 内置函数 # abs 绝对值函数 res = abs(-10) print(res) # round 四舍五入 (n.5 n为偶数则舍去 n.5 n为奇数,则进一!) 奇进 ...
- (1)json和pickle序列化模块
json 和pickle 模块 json和pickle模块下都有4个功能 dumps <---> loads (序列化 <--->反序列化) dump <---> ...
- 13、Python文件处理、os模块、json/pickle序列化模块
一.字符编码 Python3中字符串默认为Unicode编码. str类型的数据可以编码成其他字符编码的格式,编码的结果为bytes类型. # coding:gbk x = '上' # 当程序执行时, ...
- python之序列化模块、双下方法(dict call new del len eq hash)和单例模式
摘要:__new__ __del__ __call__ __len__ __eq__ __hash__ import json 序列化模块 import pickle 序列化模块 补充: 现在我们都应 ...
- Python 基础之序列化模块pickle与json
一:pickle 序列化模块把不能够直接存储的数据,变得可存储就是序列化把存储好的数据,转化成原本的数据类型,加做反序列化 php: 序列化和反序列化(1)serialize(2)unserializ ...
- day 20 - 1 序列化模块,模块的导入
序列化模块 首先我们来看一个序列:'sdfs45sfsgerg4454287789sfsf&*0' 序列 —— 就是字符串序列化 —— 从数据类型 --> 字符串的过程反序列化 —— 从 ...
- python day7: time,datetime,sys,pickle,json模块
目录 python day 7 1. time模块 2. datetime模块 2.1 date类 2.2 time类 2.3 datetime类 2.4 timedelta类 2.5 tzinfo时 ...
随机推荐
- plpgsql 编译执行
Oracle 的存储过程或函数提供了两种执行方式: 解释执行:将源代码逐条转换成目标代码,解释一条,执行一条的过程.PLPGSQL将语句翻译成中间形式的系统代码,并在运行时进行解释. 编译执行:将源代 ...
- python的环境,你再也不用愁-conda
Conda Guide Conda简介 conda是一个包,依赖和环境管理工具,适用于多种语言,如: Python, R, Scala, Java, Javascript, C/ C++, FORTR ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Java根据Freemarker模板生成Word文件
1. 准备模板 模板 + 数据 = 模型 1.将准备好的Word模板文件另存为.xml文件(PS:建议使用WPS来创建Word文件,不建议用Office) 2.将.xml文件重命名为.ftl文件 3 ...
- Prometheus 监控外部 Kubernetes 集群
转载自:https://www.qikqiak.com/post/monitor-external-k8s-on-prometheus/ 在实际环境中很多企业是将 Prometheus 单独部署在集群 ...
- Portainer 基本功能介紹之升級映像檔並更新 Container
文档地址:https://www.asustor.com/zh-tw/online/College_topic?topic=145#dpt7
- Docker网络详解——原理篇
安装Docker时,它会自动创建三个网络,bridge(创建容器默认连接到此网络). none .host 网络模式 简介 Host 容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP ...
- Effective java 总结
用静态工厂方法代替构造器的最主要好处 1.不必每次都创建新的对象 Boolean.valueOf Long.valueOf 2.直接返回接口的子类型,对于外界来说并不需要关心实现细节,主要知道这个接口 ...
- 你的哪些骚操作会导致Segmentation Fault😂
你的哪些骚操作会导致Segmentation Fault 前言 如果你是一个写过一些C程序的同学,那么很大可能你会遇到魔幻的segmentation fault,可能一时间抓耳挠腮,本篇文章主要介绍一 ...
- 齐博x1内容页中下一页上一页的标签
在模板中分别插入如下代码即可 前一页 {:fun('content@prev',$info,20)} 后一页 {:fun('content@next',$info,20)} 复制 其中20代表取标题多 ...