我为什么要放弃RESTful,选择拥抱GraphQL
背景
REST作为一种现代网络应用非常流行的软件架构风格,自从Roy Fielding博士在2000年他的博士论文中提出来到现在已经有了20年的历史。它的简单易用性,可扩展性,伸缩性受到广大Web开发者的喜爱。
REST 的 API 配合JSON格式的数据交换,使得前后端分离、数据交互变得非常容易,而且也已经成为了目前Web领域最受欢迎的软件架构设计模式。
但随着REST API的流行和发展,它的缺点也暴露了出来:
滥用REST接口,导致大量相似度很高(具有重复性)的API越来越冗余。
对于前端而言:REST API粒度较粗,难以一次性符合前端的数据要求,前端需要分多次请求接口数据。增加了前端人员的工作量。
对于后端而言:前端需要的数据往往在不同的地方具有相似性,但却又不同,比如针对同样的用户信息,有的地方只需要用户简要信息(比如头像、昵称),有些地方需要详细的信息,这就需要开发不同的接口来满足这些需求。当这样的相似但又不同的地方多的时候,就需要开发更多的接口来满足前端的需要。增加了后端开发人员的工作量和重复度。
那我们来分析一下,当前端需求变化,涉及到改动旧需求时,会有以下这些情况:
「做加法:」
产品需求增加,页面需要增加功能,数据也就相应的要增加显示,那么REST接口也需要做增加,这种无可厚非。
「做减法:」
产品需求减少,页面需要减少功能,或者减少某些信息显示,那么数据就要做减法。
一种通常懒惰的做法是,前端不与后端沟通,仅在前端对数据选择性显示。
因为后端接口能够满足数据需要,仅仅是在做显示的时候对数据进行了选择性显示,但接口的数据是存在冗余的,这种情况一个是存在数据泄露风险,另外就是数据量过大时造成网络流量过大,页面加载缓慢,用户流量费白白消耗,用户体验就会下降。
另外一种做法就是告知后端,要么开发新的接口,要么,修改旧接口,删掉冗余字段。
但一般来说,开发新接口往往是后端开发人员会选择的方案,因为这个方案对现有系统的影响最低,不会有额外的风险。
修改旧接口删除冗余数据的方案往往开发人员不会选择,这是为什么呢?
这就涉及到了系统的稳定性问题了,旧接口往往不止是一个地方在用,很有可能很多页面、设置不同客户端、不同服务都调用了这个接口获取数据,不做详细的调查,是不可能知道到底旧接口被调用了多少次,一旦改动旧接口,涉及范围可能非常大,往往会引起其他地方出现崩溃。改动旧接口成本太高,所以往往不会被采取。
「同时做加减法:」
既有加法,又有减法,其实这种就跟新需求没啥区别,前端需要重做页面,后端需要新写接口满足前端需要,但是旧接口还是不能轻举妄动(除非确定只有这一处调用才可以删除)。
往往这个时候,其实用到的数据大多都是来自于同一个DO或者DTO,不过是在REST接口组装数据时,用不同的VO来封装不同字段,或者,使用同样的VO,组装数据时做删减。
看到这些问题是不是觉得令人头大?
所以需求频繁改动是万恶之源,当产品小哥哥改动需求时,程序员小哥哥可能正提着铁锹赶来......
那么有没有一种方案或者框架,可以使得在用到同一个领域模型(DO或者DTO)的数据时,前端对于这个模型的数据字段需求的改动,后端可以根据前端的改动和需要,自动适配,自动组装需要的字段,返回给前端呢?如果能这样做的话,那么后端程序猿小哥可能要开心死了,前端妹子也不用那么苦口婆心地劝说后端小哥哥了。
所以GraphQL隆重出世了!那么问题来了!
Part 1 What is GraphQL
GraphQL简介
GraphQL是一种新的API标准,它提供了一种比REST更有效、更强大和更灵活的替代方案。
它是由Facebook开发并开源的,现在由来自世界各地的公司和个人组成的大型社区维护。
GraphQL本质上是一种基于api的查询语言,现在大多数应用程序都需要从服务器中获取数据,这些数据存储可能存储在数据库中,API的职责是提供与应用程序需求相匹配的存储数据的接口。
它是数据库无关的,而且可以在使用API的任何环境中有效使用,我们可以理解为GraphQL是基于API之上的一层封装,目的是为了更好,更灵活的适用于业务的需求变化。
简单的来说,它

它的工作模式是这样子的:
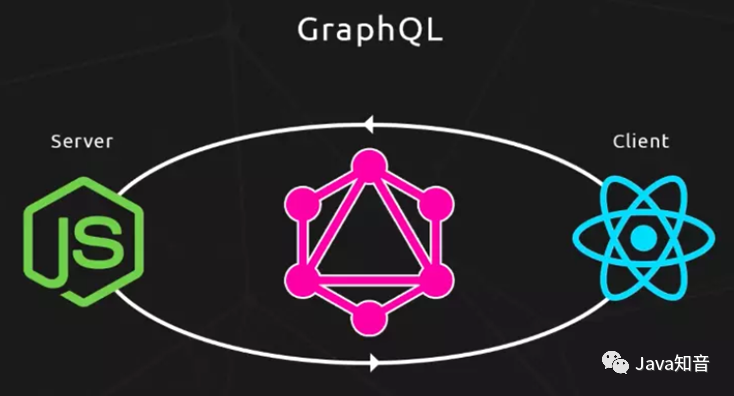
GraphQL 对比 REST API 有什么好处?
REST API 的接口灵活性差、接口操作流程繁琐,GraphQL 的声明式数据获取,使得接口数据精确返回,数据查询流程简洁,照顾了客户端的灵活性。
客户端拓展功能时要不断编写新接口(依赖于服务端),GraphQL 中一个服务仅暴露一个 GraphQL 层,消除了服务器对数据格式的硬性规定,客户端按需请求数据,可进行单独维护和改进。
REST API 基于HTTP协议,不能灵活选择网络协议,而传输层无关、数据库技术无关使得 GraphQL 有更加灵活的技术栈选择,能够实现在网络协议层面优化应用。
举个经典的例子:前端向后端请求一个book对象的数据及其作者信息。
我用动图来分别演示下REST和GraphQL是怎么样的一个过程。
先看REST API的做法:

再来看GraphQL是怎么做的:

可以看出其中的区别:
- 与REST多个endpoint不同,每一个的 GraphQL 服务其实对外只提供了一个用于调用内部接口的端点,所有的请求都访问这个暴露出来的唯一端点。

Endpoints对比

REST API's Endpoints
- GraphQL 实际上将多个 HTTP 请求聚合成了一个请求,将多个 restful 请求的资源变成了一个从根资源 POST 访问其他资源的 Comment 和 Author 的图,多个请求变成了一个请求的不同字段,从原有的分散式请求变成了集中式的请求,因此GraphQL又可以被看成是图数据库的形式。
那我们已经能看到GraphQL的先进性,接下来看看它是怎么做的。

GraphQL 思考模式
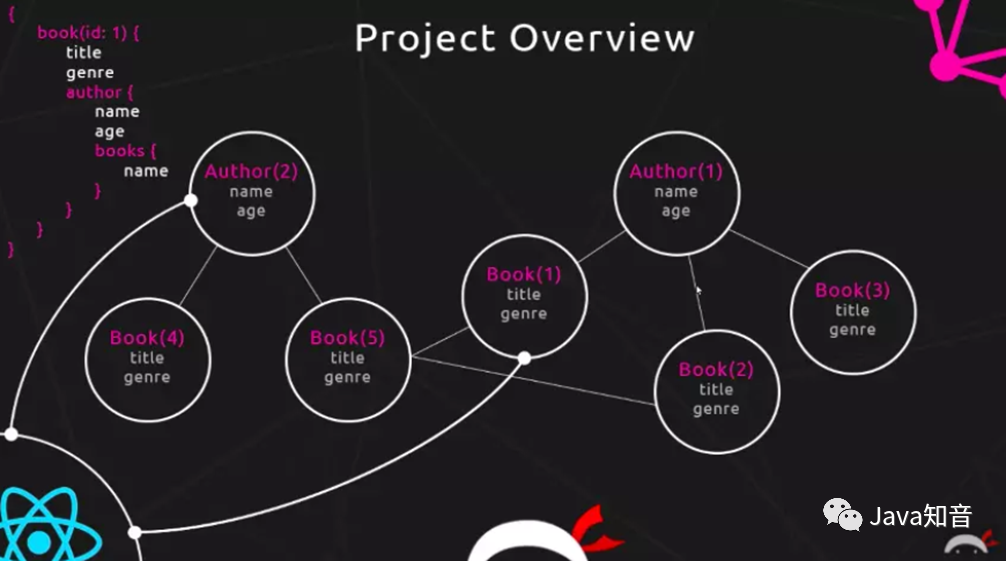
使用GraphQL接口设计获取数据需要三步:

GraphQL获取数据三步骤
首先要设计数据模型,用来描述数据对象,它的作用可以看做是VO,用于告知GraphQL如何来描述定义的数据,为下一步查询返回做准备;
前端使用模式查询语言(Schema)来描述需要请求的数据对象类型和具体需要的字段(称之为声明式数据获取);
后端GraphQL通过前端传过来的请求,根据需要,自动组装数据字段,返回给前端。
GraphQL的这种思考模式是不是完美解决了之前遇到的问题呢?!
总结它的好处:
在它的设计思想中,GraphQL 以图的形式将整个 Web 服务中的资源展示出来,客户端可以按照其需求自行调用,类似添加字段的需求其实就不再需要后端多次修改了。
创建GraphQL服务器的最终目标是:
允许查询通过图和节点的形式去获取数据。
是什么让我放弃了restful api?了解清楚后我全面拥抱GraphQL
GraphQL执行逻辑
有人会问:
使用了GraphQL就要完全抛弃REST了吗?
GraphQL需要直接对接数据库吗?
使用GraphQL需要对现有的后端服务进行大刀阔斧的修改吗?
答案是:NO!不需要!
它完全可以以一种不侵入的方式来部署,将它作为前后端的中间服务,也就是,现在开始逐渐流行的 前端 —— 中端 —— 后端 的三层结构模式来部署!
那就来看一下这样的部署模式图:
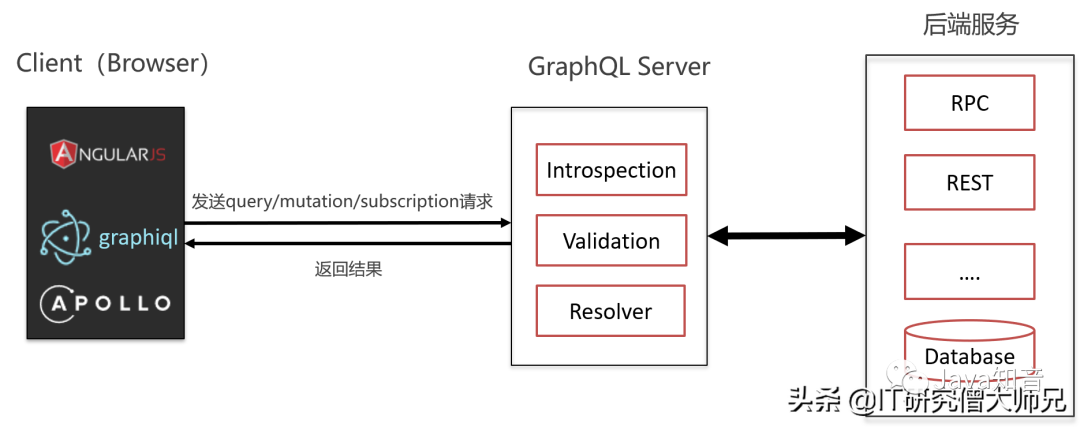
GraphQL执行逻辑
也就是说,完全可以搭建一个GraphQL服务器,专门来处理前端请求,并处理后端服务获取的数据,重新进行组装、筛选、过滤,将完美符合前端需要的数据返回。
新的开发需求可以直接就使用GraphQL服务来获取数据了,以前已经上线的功能无需改动,还是使用原有请求调用REST接口的方式,最低程度的降低更换GraphQL带来的技术成本问题!
如果没有那么多成本来支撑改造,那么就不需要改造!
只有当原有需求发生变化,需要对原功能进行修改时,就可以换成GraphQL了。
GraphQL应用的基本架构
下图是一个 GraphQL 应用的基本架构,其中客户端只和 GraphQL 层进行 API 交互,而 GraphQL 层再往后接入各种数据源。这样一来,只要是数据源有的数据, GraphQL 层都可以让客户端按需获取,不必专门再去定接口了。

GraphQL应用基本架构
一个GraphQL服务仅暴露一个 GraphQL Endpoint,可以按照业务来进行区分,部署多个GraphQL服务,分管不同的业务数据,这样就可以避免单服务器压力过大的问题了。
GraphQL特点总结
声明式数据获取(可以对API进行查询): 声明式的数据查询带来了接口的精确返回,服务器会按数据查询的格式返回同样结构的 JSON 数据、真正照顾了客户端的灵活性。
一个微服务仅暴露一个 GraphQL 层:一个微服务只需暴露一个GraphQL endpoint,客户端请求相应数据只通过该端点按需获取,不需要再额外定义其他接口。
传输层无关、数据库技术无关:带来了更灵活的技术栈选择,比如我们可以选择对移动设备友好的协议,将网络传输数据量最小化,实现在网络协议层面优化应用。
GraphQL支持的数据操作
GraphQL对数据支持的操作有:
查询(Query):获取数据的基本查询。
变更(Mutation):支持对数据的增删改等操作。
订阅(Subscription):用于监听数据变动、并靠websocket等协议推送变动的消息给对方。


GraphQL支持的操作
GraphQL的核心概念:图表模式(Schema)
要想要设计GraphQL的数据模型,用来描述你的业务数据,那么就必须要有一套Schema语法来做支撑。
想要描述数据,就必须离不开数据类型的定义。所以GraphQL设计了一套Schema模式(可以理解为语法),其中最重要的就是数据类型的定义和支持。
那么类型(Type)就是模式(Schema)最核心的东西了。
什么是类型?
对于数据模型的抽象是通过类型(Type)来描述的,每一个类型有若干字段(Field)组成,每个字段又分别指向某个类型(Type)。这很像Java、C#中的类(Class)。
GraphQL的Type简单可以分为两种,一种叫做Scalar Type(标量类型),另一种叫做Object Type(对象类型)。
那么就分别来介绍下两种类型。
标量类型(Scalar Type)
标量是GraphQL类型系统中最小的颗粒。类似于Java、C#中的基本类型。
其中内建标量主要有:
String
Int
Float
Boolean
Enum
ID
上面的类型仅仅是GraphQL默认内置的类型,当然,为了保证最大的灵活性,GraphQL还可以很灵活的自行创建标量类型。
对象类型(Object Type)
仅有标量类型是不能满足复杂抽象数据模型的需要,这时候我们可以使用对象类型。
通过对象模型来构建GraphQL中关于一个数据模型的形状,同时还可以声明各个模型之间的内在关联(一对多、一对一或多对多)。
对象类型的定义可以参考下图:

对象模型引入关联关系
是不是很方便呢?我们可以像设计类图一样来设计GraphQL的对象模型。
类型修饰符(Type Modifier)
那么,类型系统仅仅只有类型定义是不够的,我们还需要对类型进行更广泛性的描述。
类型修饰符就是用来修饰类型,以达到额外的数据类型要求控制。
比如:
列表:[Type]
非空:Type!
列表非空:[Type]!
非空列表,列表内容类型非空:[Type!]!
在描述数据模型(模式Schema)时,就可以对字段施加限制条件。
例如定义了一个名为User的对象类型,并对其字段进行定义和施加限制条件:

User字段控制
那么,返回数据时,像下面这种情况就是不允许的:

Graphql会根据Schema Type来自动返回正确的数据:

其他类型
除了上面的,Graphql还有一些其他类型来更好的引入面向对象的设计思想:
- 接口类型(Interfaces):其他对象类型实现接口必须包含接口所有的字段,并具有相同的类型修饰符,才算实现接口。
比如定义了一个接口类型:

那么就可以实现该接口:

联合类型(Union Types):联合类型和接口十分相似,但是它并不指定类型之间的任何共同字段。几个对象类型共用一个联合类型。

- 输入类型(Input Types):更新数据时有用,与常规对象只有关键字修饰不一样,常规对象时 type 修饰,输入类型是 input 修饰。
比如定义了一个输入类型:

前端发送变更请求时就可以使用(通过参数来指定输入的类型):

所以,这样面向对象的设计方式,真的对后端开发人员特别友好!而且前端MVVM框架流行以来,面向对象的设计思想也越来越流行,前端使用Graphql也会得心应手。
Graphql 技术接入架构
那么,该怎么设计来接入我们现有的系统中呢?
- 将Graphql服务直连数据库的方式:最简洁的配置,直接操作数据库能减少中间环节的性能消耗。

直连数据库的接入
- 集成现有服务的GraphQL层:这种配置适合于旧服务的改造,尤其是在涉及第三方服务时、依然可以通过原有接口进行交互。
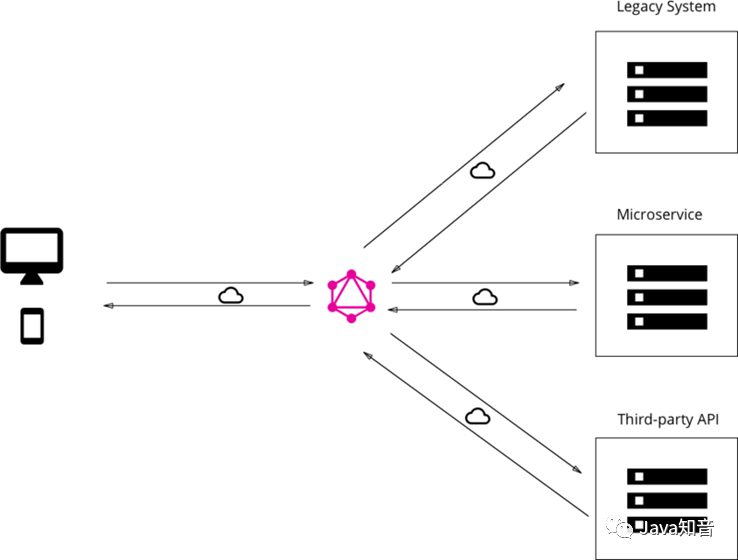
集成现有服务的GraphQL层
- 直连数据库和集成服务的混合模式:前两种方式的混合。
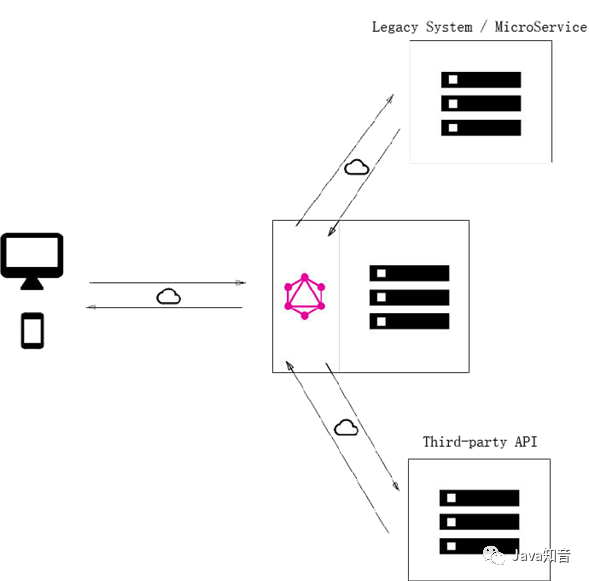
混合接入方式
可以说是非常灵活了!你都不用担心会给你带来任何的麻烦。

服务端实现
在服务端, GraphQL 服务器可用任何可构建 Web 服务器的语言实现。有以下语言的实现供参考:
- C# / .NET
- Clojure
- Elixir
- Erlang
- Go
- Groovy
- Java
- JavaScript
- Julia
- Kotlin
- Perl
- PHP
- Python
- R
- Ruby
- Rust
- Scala
- Swift
种类繁多,几乎流行的语言都有支持。
客户端实现
在客户端,Graphql Client目前有下面的语言支持:
- C# / .NET
- Clojurescript
- Elm
- Flutter
- Go
- Java / Android
- JavaScript
- Julia
- Swift / Objective-C iOS
- Python
- R
覆盖了众多客户端设计语言,而其他语言的支持也在推进中。
Graphql的一些服务
整理了下目前比较流行的服务框架:
Apollo Engine:一个用于监视 GraphQL 后端的性能和使用的服务。
Graphcool (github): 一个 BaaS(后端即服务),它为你的应用程序提供了一个 GraphQL 后端,且具有用于管理数据库和存储数据的强大的 web ui。
Tipe (github): 一个 SaaS(软件即服务)内容管理系统,允许你使用强大的编辑工具创建你 的内容,并通过 GraphQL 或 REST API 从任何地方访问它。
AWS AppSync:完全托管的 GraphQL 服务,包含实时订阅、离线编程和同步、企业级安全特性以及细粒度的授权控制。
Hasura:一个 BaaS(后端即服务),允许你在 Postgres 上创建数据表、定义权限并使用 GraphQL 接口查询和操作。
Graphql的一些工具
graphiql (npm): 一个交互式的运行于浏览器中的 GraphQL IDE。
Graphql Language Service: 一个用于构建 IDE 的 GraphQL 语言服务(诊断、自动完成等) 的接口。
quicktype (github): 在 TypeScript、Swift、golang、C#、C++ 等语言中为 GraphQL 查 询生成类型。
想要获取更多关于Graphql的一些框架、工具,可以去awesome-graphql:一个神奇的社区,维护一系列库、资源等,地址是
https://github.com/chentsulin/awesome-graphql。
想要学习更多Graphql的知识,可以去GraphQL.cn。
好了,一个入门级的Graphql介绍篇就这样完结了(尽管篇幅也很大哈哈)。
不知道你懂得它的原理和优点了吗?
你对它感兴趣吗?
看完这篇介绍,有没有想动手尝试一下呢?
你会在你下一个项目中引入Graphql并使用它吗?
你对Graphql还有什么疑惑的问题呢?
我为什么要放弃RESTful,选择拥抱GraphQL的更多相关文章
- 人人都是 API 设计师:我对 RESTful API、GraphQL、RPC API 的思考
原文地址:梁桂钊的博客 博客地址:http://blog.720ui.com 欢迎关注公众号:「服务端思维」.一群同频者,一起成长,一起精进,打破认知的局限性. 有一段时间没怎么写文章了,今天提笔写一 ...
- 放弃iOS4,拥抱iOS5
前言 苹果在2011年的WWDC大会上发布了iOS5,不过考虑到要支持iOS4.x的系统,大多数App都无法使用iOS5的新特性.现在将近1年半过去了,从我们自己的App后台的统计数据.一些第三方 ...
- 放弃 Tightvnc, 选择 Tigervnc
构建headless vnc server ,我终于放弃了Tightvnc 基于以下原因: 1) 已知的Qt5的键盘映射问题,导致virtualbox 的使用出现困难 https://unix.sta ...
- 放弃 Electron,拥抱 WebView2!JavaScript 快速开发独立 EXE 程序
Electron 不错,但也不是完美的. Electron 带来了很多优秀的桌面软件,但并不一定总是适合我们的需求. 多个选择总是好事! 我使用 Electron 遇到的一些麻烦 1.Electron ...
- 为什么 Spring Boot 2.3.0 放弃Maven最终拥抱Gradle
在 2.3.0 中对 Spring Boot 进行了相当重大的更改,这是使用 Gradle 而非 Maven 构建的项目的第一个版本. Spring 的每个项目都独立的项目组在开发运营,在用户最常使用 ...
- 放弃火狐,选择chrome
最近公司笔记本电脑经常卡的不行(win10系统),先是硬盘经常占用99%-100%,改系统设置,软件优化,硬件测试...尝试了能搜索到所有办法后,还是没有解决,换成win7后感觉稍微好点了(心理作用? ...
- graphql详解
随着系统业务量的增大不同的应用和系统共同使用着许多的服务api,而随着业务的变化和发展,不同的应用对相同资源的不同使用方法最终会导致需要维护的服务api数量呈现爆炸式的增长,比如我试着跑了下我们自己业 ...
- Spring Boot 集成 Swagger 生成 RESTful API 文档
原文链接: Spring Boot 集成 Swagger 生成 RESTful API 文档 简介 Swagger 官网是这么描述它的:The Best APIs are Built with Swa ...
- 七月小说网 Python + GraphQL (三)
概述 后台数据库几个基本表基本搭建完毕,看了下Github Develop的V4 Api抛弃了RESTful,采用GraphQL,感觉很有意思,一看文档,竟然有Python的开源实现 Graphene ...
- RESTful再理解
目录 目录 前言 RESTful的目的 REST的含义 表现层 状态转化 无状态协议HTTP 最后 前言 这是在经过一段时间的积累后,对RESTFul框架的再一次更深入的理解.希望能够将零散的知识点连 ...
随机推荐
- ubuntu 输入法IBUS 输入不成功问题
ubuntu 输入法IBUS 输入不成功问题 只需要在 输入如下代码 -Xms128m -Xmx750m -XX:ReservedCodeCacheSize=240m -XX:+UseConcMark ...
- 有依赖的背包问题(Acwing 10)
1 # include<iostream> 2 # include<cstring> 3 # include<algorithm> 4 using namespac ...
- windows查看端口和杀掉端口
//执行下面命令 netstat --help 获取netstat的所有命令参数 //例如查看8080端口占用 netstat -ano | findstr 8080 //查看该端口是什么 taskl ...
- C++初阶(运算符重载汇总+实例)
运算重载符 概念: 运算符重载是具有特殊函数名的函数,也具有其返回值类型,函数名字以及参数列表,其返回值类型与参数列表与普通的函数类似. 函数原型: 返回值 operator操作符(参数列表) 注意: ...
- mysql管理工具mysqladmin的使用
1. 初始化密码 mysqladmin -uroot -p'password' password 'new-password' [root@controller3 ~]# yum -y install ...
- [排序算法] 直接/折半插入排序 (C++)
插入排序解释 插入排序很好理解,其步骤是 :先将第一个数据元素看作是一个有序序列,后面的 n-1 个数据元素看作是未排序序列.对后面未排序序列中的第一个数据元素在这个有序序列中进行从后往前扫描,找到合 ...
- c++ *和& 指针,取内容,别名,取地址
*前面有类型符时为定义指针 &前面有类型符时为定义引用变量(别名) (int ,float,long,double,char等 ) *p:定义xx类型的指针 int *p 整型指针,char ...
- 3 c++编程-提高篇-模版
重新系统学习c++语言,并将学习过程中的知识在这里抄录.总结.沉淀.同时希望对刷到的朋友有所帮助,一起加油哦! 生命就像一朵花,要拼尽全力绽放!死磕自个儿,身心愉悦! 系列文章列表: 1 c+ ...
- combotree 的简单使用2
上一次我在 combotree 的简单使用 中介绍了一种combotree的写法,不过有一个缺点,就是当输的结构非常大的时候,分级较多时,消耗内存的现象会比较严重,下面介绍的一种方法,使combotr ...
- ArcObjects SDK开发 005 ArcObjects SDK中的插件式架构
1.什么是插件式架构 插件式架构设计中主要包括三个重要部分,宿主.插件协议以及插件实现.宿主是指使用插件的部分,该模块可以是一个类,也可以是多个接口和类组成的模块.插件协议是指宿主与插件之间的协议,宿 ...