java初级开发面试题
目录
Q7、String、StringBuffer和StringBuilder
Q9、final、finally、finalize的区别与用法
Q5、where、having、order、group by的执行顺序
Q4、Spring、SpringMVC和Springboot的区别
Q1、如何在maven中央仓库找到你想用的包,如果中央仓库没有这个包怎么办
1、java基础知识
Q1、equals和==的区别
- ==是判断两个变量或实例是不是指向同一个内存空间,equals是判断两个变量或实例所指向的内存空间的值是不是相同。
- ==是对内存地址进行比较,而equals比较的是两个字符串的值是否相等。
- ==指引用是否相同,而equals是比较值是否相同。

Q2:集合的父类是什么
List<T> extends Collection<T> Collection<T> entends Iterable<T>
List:元素有序且可重复,主要实现类有 ArrayList,LinkedList,Vector。
Set:元素有序且不可重复。主要实现类:HashSet,TreeSet,LinkedHashSet。
Vector类是线程安全的,因为Vector类里面的方法都是有synchronized修饰的。
ArrayList类不是线程安全的,ArrayList类里面的方法是没有用synchronized同步的。
Q3:List、Hashmap、Set区别
1、List( 有序、可重复)
ArrayList与Vector
①底层数据结构是数组,查询快,增删慢。
②前者效率高、线程不安全,后者效率低、线程安全。
LinkedList
①底层数据结构是链表,查询慢,增删快。
②线程不安全,效率高。因为是not synchronized。
2、Set
HashSet(唯一、无序)
①底层数据结构是哈希表。Hash表又叫散列表,其底层是数组,在数组中存放关键字,关键字在数据中的位置是由散列函数计算得来的。常见的散列函数有:直接定址法(线性函数)、除留余数法、数字分析法、*方取中法。在存储的时候可能会产生冲突即一个位置有多个关键字会去竞争,为了避免冲突就要去用线性探测法、*方探测法、再散列法。
②HashSet常用方法有:add、remove、isEmpty、contain等
LinkedHashSet(唯一、有序)
①底层数据结构是链表和哈希表,继承自HashSet。
②由链表保证元素有序、哈希表保证元素唯一。
TreeSet(唯一、有序)
①底层数据结构是红黑树,红黑树是一颗*衡二叉查找树。TreeSet源码里面有一个构造方法使用了Comparator比较强接口,因此在构造一个TreeSet时会调比较器构造一颗*衡二叉查找树。因此TreeSet是有序的。
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}②自然排序、比较器排序。
③根据比较的返回值是否是0来决定是否唯一。
3、Map
key-value键值对,有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
HashMap
HashMap的底层结构是红黑树,HashMap是由数组和链表构成的。hashmap会自动按照key的值从小到大排列。
HashMap的使用
HashMap<String, String> hm = new HashMap<>();
hm.put("a", "1");
hm.put("d", "5");
hm.put("c", "3");
System.out.println(hm); //调用hashmap类中toString方法输出
//使用Set遍历输出hashmap
Set<Map.Entry<String, String>> ss = hm.entrySet();
for (Map.Entry<String, String> mm : ss) {
System.out.println(mm.getKey() + "---" + mm.getValue());
}使用map.put(k,v)时,首先会将k,v封装到Node节点当中,然后它的底层会调用K的hashCode()方法得出hash值,通过哈希表函数/哈希算法,将hash值转换成数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
使用map.get(k)时,会先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标,通过数组下标定位到某个位置,然后再从这个位置上的单链表找到相应的元素。
public final int hashCode() { //HashMap类中的hashCode()方法
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public static int hashCode(Object o) { //Object类在的hashCode()方法
return o != null ? o.hashCode() : 0;
}HashMap增删和查询效率都很高,是因为增删是在链表上进行的,查询有哈希函数,hashCode()帮忙定位,所以只需扫描部分就行了。
相比 jdk1.7 的 HashMap 而言,jdk1.8最重要的就是引入了红黑树的设计,当hash表的单一链表长度超过 8 个的时候,链表结构就会转为红黑树结构。为什么要这样设计呢?好处就是避免在最极端的情况下链表变得很长很长,在查询的时候,效率会非常慢。简单的说,红黑树是一种*似*衡的二叉查找树,其主要的优点就是“*衡“,即左右子树高度几乎一致,以此来防止树退化为链表,通过这种方式来保障查找的时间复杂度为 log(n)。
HashMap的扩容因子是0.75,即当容量达到3/4的时候会进行扩容。
红黑树特性:
- 每个节点要么是红色,要么是黑色,但根节点永远是黑色的
- 每个红色节点的两个子节点一定都是黑色
- 红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色)
- 从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点
- 所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点)
在树的结构发生改变时(插入或者删除操作),往往会破坏上述条件 3 或条件 4,需要通过调整使得查找树重新满足红黑树的条件。
Hashtable的方法是同步的、synchronized线程安全的;HashMap的方法不是同步的、线程不安全。HashMap效率较高,Hashtable效率较低。
Hashtable的父类是Dictionary,HashMap的父类是AbstractMap。
HashTable的操作几乎和HashMap一致,HashTable和HashMap的底层源码非常相似,主要的区别在于HashTable为了实现多线程安全,在几乎所有的方法上都加上了synchronized锁,而加锁的结果就是HashTable操作的效率十分低下。
Hashtable<String, String> ht = new Hashtable<>();
ht.put("a", "1");
ht.put("f", "4");
ht.put("e", "6");
System.out.println(ht); //调用hashtable类中toString方法输出
//使用Set遍历输出hashtable
Set<Map.Entry<String, String>> ss1 = ht.entrySet();
for (Map.Entry<String, String> mm : ss1) {
System.out.println(mm.getKey() + "---" + mm.getValue());
}如何构建一个线程安全的Hashmap?
写一个类继承HashMap,重写HashMap的方法,并在一些方法前加”synchronized”
public class SafeMap extends HashMap {
@Override
public synchronized Object put(Object key, Object value) {
return super.put(key, value);
}
}
Q4、java数据类型
java中的八种基本数据类型是:1、byte;2、short;3、int;4、long;5、float;6、double;7、char;8、boolean。
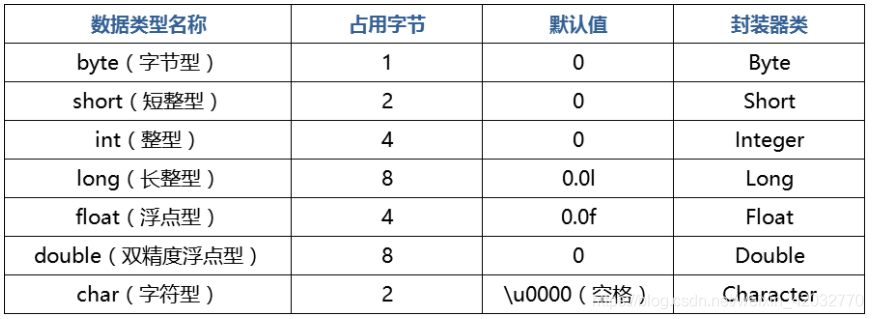
java四大数据类型:
- 整型:byte 、short 、int 、long
- 浮点型:float 、 double
- 字符型:char
- 布尔型:boolean
Q5、javaIO流
java IO流分为字符流和字节流,字节流继承inputStream和OutputStream,字符流继承自InputSteamReader和OutputStreamWriter。输入流就是从外部文件输入到内存,输出流主要是从内存输出到文件。程序中的输入输出都是以流的形式保存的,流中保存的实际上全都是字节文件。
在实现文件下载会使用到字节流,首先会获取一个文件路径path,从这个path找到要下载的文件,File file=new File(path),再把这个文件封装成一个字节流
InputStreamResource resource = new InputStreamResource(new FileInputStream((file))); 通过http传输字节流,使用HttpHeaders中的add方法可以设置要传输的内容。然后使用ResponseEntity去响应这个http请求,最终返回一个ResponseEntity对象。ResponseEntity对象就是你下载的文件。
注:不过一般实际应用中更倾向于后端生成一个数据list,再由前端合成,具体可以参考:Vue中实现自定义excel下载
//下载上传的预算申请表附件
@RequestMapping(value = "/download_appendix", method = RequestMethod.GET)
public ResponseEntity<Object> download_appendix(HttpServletRequest request,HttpServletResponse response) throws FileNotFoundException {
String index_no=request.getParameter("ck_index_no");
Budget_apply budget_apply=new Budget_apply();
budget_apply=budget_applyService.get_by_index_no(index_no);
String fileName=budget_apply.getFile_path()+budget_apply.getFile_name();
File file = new File(fileName);
InputStreamResource resource = new InputStreamResource(new FileInputStream((file)));
HttpHeaders headers = new HttpHeaders();
headers.add("Content-Disposition",String.format("attachment;filename=\"%s\"",file.getName()));
headers.add("Cache-Control","no-cache,no-store,must-revalidate");
headers.add("Pragma","no-cache");
headers.add("Expires","0");
ResponseEntity<Object> responseEntity = ResponseEntity.ok()
.headers(headers)
.contentLength(file.length())
.contentType(MediaType.parseMediaType("application/text"))
.body(resource);
return responseEntity;
}
字符流和字节流的区别?
- 字节流是由字节组成的(byte)
- 字符流是由字符组成的(char)
- Java里字符由两个字节组成. 1字符=2字节
- JAVA中的字节流是采用ASCII编码的,
- 字符流是采用好似UTF编码,支持中文的
Q6、jdk1.8新特性
详细可参考:java8新特性学习笔记
- Lambda表达式
- 函数式接口
- 方法引用和构造器调用
- Stream API
- 接口中的默认方法和静态方法
- 新时间日期API
1、Lambda表达式
可以使用Lambda表达式写匿名内部类
public class Lambda {
interface AAA {
void test(int a, int b);
}
public static void main(String[] args) {
AAA aaa = new AAA() { //匿名内部类
@Override
public void test(int a, int b) {
System.out.println(a + "," + b);
}
};
AAA aaa1 = (a, b) -> { //匿名内部类,lambda表达式
System.out.println(a + "," + b);
};
aaa.test(2, 3);
aaa1.test(3, 4);
}
}2、函数式接口
@FunctionalInterface这个注解声明该接口是一个函数式接口,简单来说,函数式接口是只包含一个方法的接口。比如Java标准库中的java.lang.Runnable和 java.util.Comparator都是典型的函数式接口。
3、方法引用和构造器调用
方法引用:当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!(实现抽象方法的参数列表,必须与方法引用方法的参数列表保持一致)!

构造器引用:与函数式接口相结合,自动与函数式接口中方法兼容。可以把构造器引用赋值给定义的方法,与构造器参数列表要与接口中抽象方法的参数列表一致!
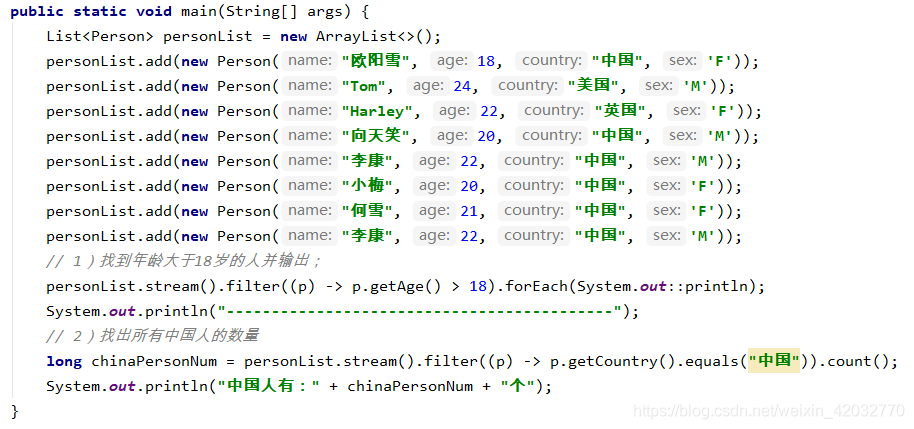
4、Stream API
Stream 是Java8中处理集合的关键抽象概念,它可以对集合进行非常复杂的查找、过滤、筛选等操作。
可以使用StreamAPI的filter对集合进行过滤。
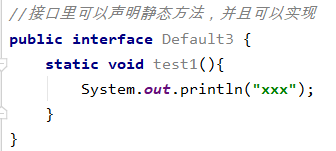
5、接口中的默认方法和静态方法
jdk1.8对接口进行了增强
- 在接口中可以添加使用 default 关键字修饰的非抽象方法。即:默认方法(或扩展方法)。
- 接口里可以声明静态方法,并且可以实现。
Java 8 允许给接口添加一个非抽象的方法实现,只需要使用 default 关键字即可,这个特征又叫做扩展方法。

接口里可以声明静态方法,并且可以实现
6、新时间日期API
- LocalDate:包含了年月日信息。
- LocalTime:LocalTime和LocalDate类似,区别在于LocalTime包含的是时分秒(毫秒)信息。
- LocalDateTime:LocalDateTime是LocalDate和LocalTime的组合形式,包含了年月日时分秒信息。
- Duration:Duration用于计算两个LocalTime或者LocalDateTime的时间差。
- Period:Period用于计算两个LocalDate之间的时长。
Q7、String、StringBuffer和StringBuilder
String是final类,是不可以被继承的,是不可变对象,一旦被创建,就不能修改它的值。对于已经存在的String对象的修改都是重新创建一个新的对象,然后把新的值保存进去。String底层有用到synchronized,因此String是线程安全的。
StringBuffer是一个可变对象,当对他进行修改的时候不会像String那样重新建立对象,可以通过append()方法进行字符串追加,StringBuffer类自带reverse()方法可以实现字符串逆序。StringBuffer底层方法是用synchronized修饰的,因此StringBuffer是线程安全的。
StringBuilder和StringBuffer非常相似,都是可变字符序列,但StringBuilder不是线程安全的,不过StringBuilder的效率要比StringBuffer高。
Q8、JVM调优
JVM常用的垃圾回收算法有四种:标记-清除算法、复制算法、标记-整理算法、分代收集算法。(初级开发一般不会细问,只要能回答上四种算法应该就行了)
Q9、final、finally、finalize的区别与用法
- final用于声明属性,方法和类,分别表示属性不可交变,方法不可覆盖,类不可继承。
- finally是异常处理语句结构的一部分,表示总是执行。
- finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,供垃圾收集时的其他资源回收,例如关闭文件等。
Q10、两个线程同时执行i++100次
可能的结果:最小为2,最大为200。
两个线程a,b,全局变量i。
最大为200:a执行100次i++,i=100。b再执行100次i++,i=200。
最小为2:a执行1次i=i+1,当i=1还未写入内存时,b抢过来CPU,一口气执行了99次并写入内存。此时a将i=1写入内存,替换掉了b的i=99,此时i还是等于1。b再抢得cpu执行一次i++,i变为了2但还未写入内存,此时a一口气执行99次,i=100并写入内存。然后i=2写入内存会替换掉i=100的值,因此i=2。
Q11、线程中sleep和wait的区别
- sleep是Thread的静态方法,wait是Object的方法,任何对象实例都能调用。
- sleep不会释放锁,它也不需要占用锁。wait会释放锁,但调用它的前提是当前线程占有锁(即代码要在synchronized中)。
- 它们都可以被interrupted方法中断。
2、锁
Q1、悲观锁和乐观锁
悲观锁,就是以悲观的态度来处理一切冲突。在数据修改前就先把数据锁住,防止其他人操作数据。在锁释放前,除了加锁者自己,其他人都不可以操作该数据。直到前面的加锁者把锁释放,然后后面的人拿到锁,并对数据加锁后才能对数据进行处理。常见的悲观锁像数据库中的行锁,表锁,读锁,写锁这些都是在做操作之前先上锁,是悲观锁。java线程同步中的synchronized也是悲观锁。
注意:悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。但是在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会。另外还会降低并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数据。
悲观锁实现形式:
1、表锁
lock table users; --给表加写锁
unlock tables; --释放锁
2、行锁
--使用行锁需在建表时使用innodb引擎
create table t_rowLock(id int,txt varchar(50)engine=innodb;
--为了使行锁生效,需关闭自动提交
set autocommit=0;
--InnoDB行锁是通过给索引上的索引项加锁来实现的
alter table t_rowLock add index id_index(id);
alter table t_rowLock add index txt_index(txt);乐观锁,就是以乐观的态度来处理一切冲突。在数据修改前无需加锁,只有在数据要提交时才会进行冲突检测。如果冲突了则提交失败并返回错误的信息给用户。
乐观锁是一种并发类型的锁,其本身不对数据进行加锁通而是通过业务实现锁的功能,不对数据进行加锁就意味着允许多个请求同时访问数据,同时也省掉了对数据加锁和解锁的过程,这种方式大大的提高了数据操作的性能。
乐观锁适用于读操作多的场景,这样可以提高程序的吞吐量
乐观锁实现形式:
乐观锁是通过在表中增加一个字段来控制数据的版本,如果要更新某行数据会校验版本号,版本相同则可以提交更新,版本不同则把数据视为过期。

用户A和用户B都要对uname=zhangsan进行数据更新。
--首先要关闭数据库的自动提交
SET autocommit=0;
--用户A获取要修改数据的版本号,用户A得到数据版本号VERSION=1
SELECT VERSION FROM users WHERE uname='zhangsan';
--用户B获取要修改数据的版本号,用户B得到数据版本号VERSION=1
SELECT VERSION FROM users WHERE uname='zhangsan';
--用户A对version=1的数据进行更新,并更新版本号
UPDATE users SET upwd='AAAAAA' ,VERSION=VERSION+1 WHERE uname='zhangsan' AND VERSION=1;
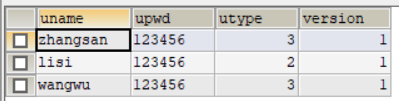
由于关闭了自动提交,因此此时用户A的update操作,没有提交,所以数据库表中相应的数据没有发生变化。
此时在A还没有提交的时候,B也执行了update的操作。
--用户B对version=1的数据进行更新,并更新版本号
UPDATE users SET upwd='BBBBBB' ,VERSION=VERSION+1 WHERE uname='zhangsan' AND VERSION=1;由于A还没有提交,所以此时B的操作是处于等待状态,等待A完成提交,B的update才能执行。

A提交之后,B的Update操作也执行成功了。并提交B的操作。

然而却发现此时数据库表中的数据只是操作A进行数据修改的结果,而操作B的数据修改则无效。
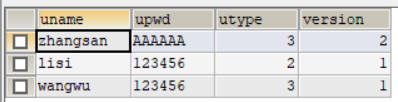
这是因为当操作A提交后此时该数据的version已经改变了,version变为2了。而操作B还在用未改变之前的version作为条件修改数据,当然就修改失败了。
这就是乐观锁!!!
Q2、公*锁和非公*锁
1、公*锁
公*锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
优点:所有的线程都能得到资源,不会饿死在队列中。
缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
2、非公*锁
非公*锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
3、数据库知识
Q1、分页查询
1、Mysql分页查询
//取前5条数据
select * from xxx limit 0,5;
//取第11条到第15条数据,共5条
select * from xxx limit 10,5;2、Oracle分页查询
rownum关键字:oracle对外提供的自动给查询结果编号的关键字
//每页显示m条数据,查询第n页数据)
select rownum,t.* from (select rownum r,e.* from 要分页的表 e where rownum<=n*m) t where r>n*m-m3、Sqlserver分页查询
// 1、 先查询当前页码之前的所有数据id
select top ((当前页数-1)*每页数据条数) id from 表名
// 2、再查询所有数据的前几条,但是id不在之前查出来的数据中
select top 每页数据条数 * from 表名 where id not in ( select top ((当前页数-1)*每页数据条数) id from 表名 )4、DB2分页查询
row_number()(Oracle中为rownum)作为查询的辅助函数
select * from (
select row_number() over(ORDER BY date DESC) as r,e.*
from emp e
where e.name=’A’)
where r between 1 AND 5Q2、数据库索引
1、索引失效
- 计算、函数、类型转换会使索引失效
- 使用 != 或者<> 的时候无法使用索引会导致全表扫描
- is not null 也无法使用索引,但是is null是可以使用索引的
- like以通配符开头('%abc...')mysql索引失效会变成全表扫描的操作
- 字符串不加单引号索引失效
- 少用or,用它来连接时会索引失效
2、索引分类
Mysql有普通索引、唯一索引、主键索引、组合索引、全文索引。
//普通索引
create index name_no_index on t_staff(no);
//唯一索引
create unique index name_index on t_staff(name);
//主键索引
ALTER TABLE tbl_name ADD PRIMARY KEY (col_list);
//组合索引
create index name_no_index on t_staff(no,name);
//全文索引
ALTER TABLE tbl_name ADD FULLTEXT index_name (col_list);创建全文索引可以极大的提升检索效率,解决判断字段是否包含的问题,例如: 有title字段,需要查询所有包含 "政府"的记录. 需要 like "%政府%"方式查询,查询速度慢,当查询包含"政府" OR "中国"的需要是,sql难以简单满足.全文索引就可以实现这个功能。
//全文索引使用
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('精神' IN NATURAL LANGUAGE MODE);
3、索引的优缺点
优点:大大提升查询效率
缺点:建立索引后,执行update、insert、delete操作效率会降低。insert数据时,要额外建立索引耗费存储空间。
4、索引底层
索引底层通常会采用B树实现,因为B树会自动根据两边的情况自动调节,使两端无限趋*于*衡状态。可以使性能最稳定。但B树也有弊端就是当插入/修改操作过多时,B树会不断调整*衡,消耗性能,因此索引不是越多越好。
由于索引底层的B树是三层的,因此无论查找哪个,都最多只需访问三次内存就可以搞定,B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更*,因此访问也更迅速。
Q3、数据库调优
如果要往一张表里插入100w条信息,如何进行性能调优
首先要根据业务需求选择合适的存储引擎,Mysql的存储引擎有MyISM和InnoDB。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
- 在建表的时候尽量使得表中的字段都是定长的
- 要建立适当的索引来加快查询速度
- 开启数据库缓存机制,避免重复查询浪费时间和性能
- 使用explain,如果发现查询缓慢则要在where条件后要有索引字段
- 避免select *
聚集索引和非聚集索引
聚集索引一个表只能有一个,而非聚集索引一个表可以存在多个,聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。
Q4、mysql和sql server的区别
1、性能
- mysql读写性能一流,即使是针对大量数据也没有问题,但前提是必须是简单查询效率快。如果是复杂查询则mysql的查询效率会下降许多。就是最好不要使用函数/join/group等方式查询。
- sqlserver简单查询速度不如mysql,但复杂查询时,性能降低的不多,可见,sqlserver的查询优化作的可能更好。
2、对机器配置要求
- mysql对机器配置要求比sqlserver低。
3、功能
sqlserver的功能要比mysql要多,sqlserver有一个图形化操作界面比mysql的什么Navicat要强大许多。不过Mysql比sqlserver更加容易上手。
Q5、where、having、order、group by的执行顺序
where肯定在group by 之前,即也在having之前。
where后的条件表达式里不允许使用聚合函数,而having可以。
首先是where xxx对全表数据进行筛选,返回第一个结果集。
针对第一个结果集进行group by分组,然后是having对分组后的结果进行筛选(即使用having的前提条件是分组)
最后是order对最终的一个结果进行排序。
Q6、数据库事务四大属性
ACID:原子性、一致性、隔离性和持久性
一、原子性(atomicity)
一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性。
二、一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。
如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所作的修改有一部分已写入物理数据库,这是数据库就处于一种不正确的状态,也就是不一致的状态。
三、隔离性(isolation)
事务的隔离性是指在并发环境中,并发的事务时相互隔离的,一个事务的执行不能不被其他事务干扰。不同的事务并发操作相同的数据时,每个事务都有各自完成的数据空间,即一个事务内部的操作及使用的数据对其他并发事务时隔离的,并发执行的各个事务之间不能相互干扰。
四、持久性(durability)
一旦事务提交,那么它对数据库中的对应数据的状态的变更就会永久保存到数据库中。--即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束的状态。
4、Spring框架
Q1、Spring IOC和AOP
IOC,即控制反转,是通过依赖注入的方式去实现的。
所谓依赖注入,就是把底层类作为参数传入上层类,实现上层类对下层类的“控制”。把有依赖关系的类放到容器中,解析出这些类的实例,就是依赖注入。目的是实现类的解耦。
可参考:ssm——spring整理_金斗潼关的博客-CSDN博客
Q2、Springboot常用注解
@SpringBootApplication:Springboot项目启动类注解
@MapperScan:加在springboot启动类上,编译后会扫描相应接口的实现类(mybatis)
@Component、@Repository、@Service:用于类注解,表示将该类变成一个bean
@Component:服务层接口
@Service:服务层实现类
@Repository:持久层
@Autowired:自动装配。
@Resource:属性注入=@Autowired+@Qualifier
Q3、Springboot启动流程
入口类的要求是最顶层包下面第一个含有 main 方法的类,使用注解 @SpringBootApplication 来启用 Spring Boot 特性,使用 SpringApplication.run 方法来启动 Springboot项目。
@SpringBootApplication
public class ErpApplication extends SpringBootServletInitializer {
public static void main(String[] args) {
SpringApplication.run(ErpApplication.class, args);
}public static ConfigurableApplicationContext run(Class<?> primarySource, String... args) {
return run(new Class[]{primarySource}, args);
}
public static ConfigurableApplicationContext run(Class<?>[] primarySources, String[] args) {
return (new SpringApplication(primarySources)).run(args);
}SpringApplication类中的run方法是有两个参数,run(a,b)。
第一个参数 primarySource:加载的主要资源类。
第二个参数 args:传递给应用的应用参数。
先用主要资源类来实例化一个 SpringApplication 对象,再调用这个对象的 run 方法。
SpringApplication对象的实例化是用到了一个构造方法。
public SpringApplication(ResourceLoader resourceLoader, Class<?>... primarySources) {
this.sources = new LinkedHashSet();
this.bannerMode = Mode.CONSOLE;
this.logStartupInfo = true;
this.addCommandLineProperties = true;
this.addConversionService = true;
this.headless = true;
this.registerShutdownHook = true;
this.additionalProfiles = new HashSet();
this.isCustomEnvironment = false;
this.lazyInitialization = false;
// 1、初始化资源加载器为null
this.resourceLoader = resourceLoader;
// 2、断言资源类不能为null,否则会报错
Assert.notNull(primarySources, "PrimarySources must not be null");
// 3、初始化资源类集合,并去重
this.primarySources = new LinkedHashSet(Arrays.asList(primarySources));
// 4、判断当前web应用类型
this.webApplicationType = WebApplicationType.deduceFromClasspath();
// 5、设置应用上下文并初始化
this.setInitializers(this.getSpringFactoriesInstances(ApplicationContextInitializer.class));
// 6、设置监听器
this.setListeners(this.getSpringFactoriesInstances(ApplicationListener.class));
// 7、找到主入口应用类
this.mainApplicationClass = this.deduceMainApplicationClass();
}Q4、Spring、SpringMVC和Springboot的区别
Spring 框架就像一个家族,有众多衍生产品例如 boot、security、jpa等等;但他们的基础都是Spring 的ioc和 aop,ioc 提供了依赖注入的容器, aop解决了面向切面编程,然后在此两者的基础上实现了其他延伸产品的高级功能。
Spring MVC提供了一种轻度耦合的方式来开发web应用;它是Spring的一个模块,是一个web框架;通过DispatcherServlet, ModelAndView 和 View Resolver,开发web应用变得很容易;解决的问题领域是网站应用程序或者服务开发——URL路由、Session、模板引擎、静态Web资源等等。
Spring Boot实现了auto-configuration自动配置(另外三大神器actuator监控,cli命令行接口,starter依赖),降低了项目搭建的复杂度。它主要是为了解决使用Spring框架需要进行大量的配置太麻烦的问题,所以它并不是用来替代Spring的解决方案,而是和Spring框架紧密结合用于提升Spring开发者体验的工具;同时它集成了大量常用的第三方库配置(例如Jackson, JDBC, Mongo, Redis, Mail等等),Spring Boot应用中这些第三方库几乎可以零配置的开箱即用(out-of-the-box)。
简单来说:
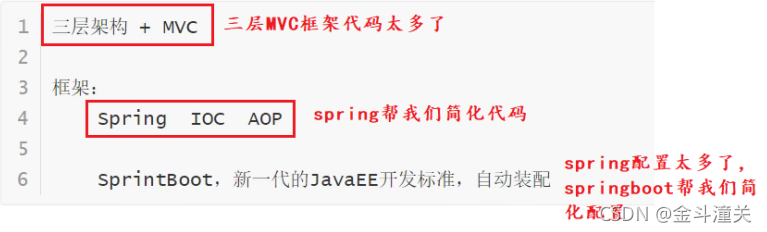
所以,用最简练的语言概括就是:
Spring 是一个“引擎”;
Spring MVC 是基于Spring的一个 MVC 框架;
Spring Boot 是基于Spring4的条件注册的一套快速开发整合包。
约定大于配置
开发人员仅需规定应用中不符合约定的部分。在没有规定配置的地方,采用默认配置,以力求最简配置为核心思想。
springboot中常见约定:
- Maven的目录结构。默认有resources文件夹,存放资源配置文件。src-main-resources,src-main-java。
- 默认的编译生成的类都在targe文件夹下面
- spring boot默认的配置文件必须是,也只能是application.命名的yml文件或者properties文件,且唯一application.yml中默认属性。
- 数据库连接信息必须是以spring: datasource: 为前缀;多环境配置。该属性可以根据运行环境自动读取不同的配置文件;端口号、请求路径等
Q5、AOP实现原理
AOP :全称是 Aspect Oriented Programming 即:面向切面编程。AOP可以把我们程序重复的代码抽取出来,在需要执行的时候,使用动态代理的技术,在不修改源码的基础上,对我们的已有方法进行增强。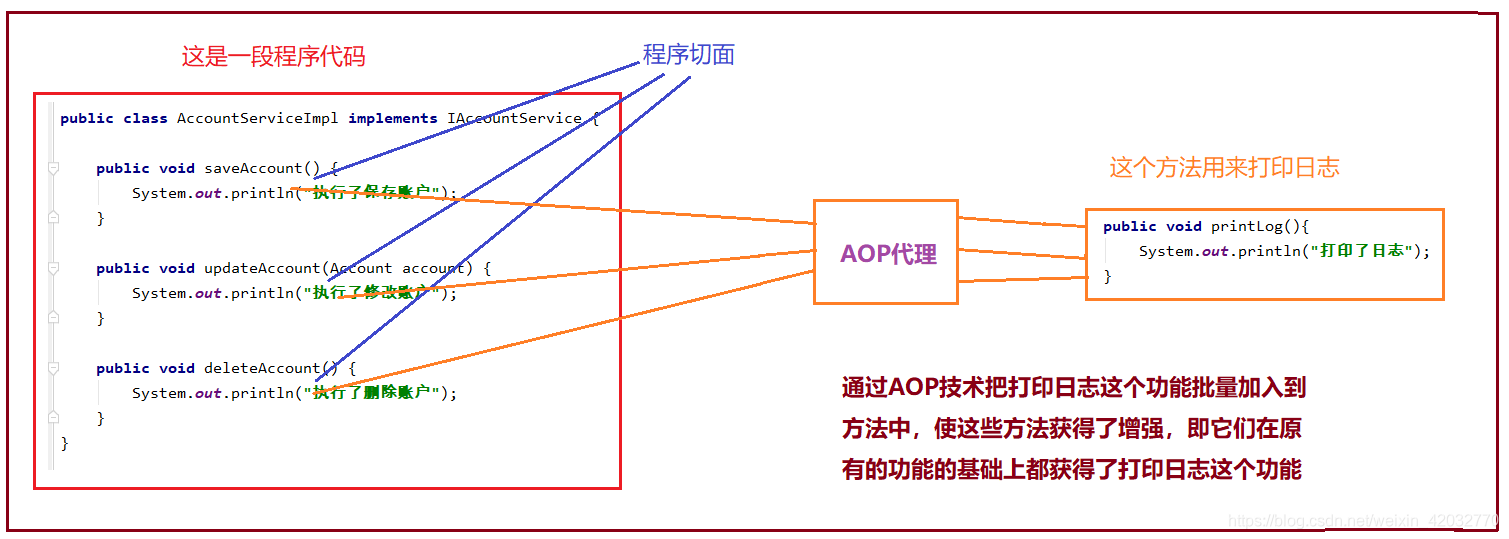
AOP的作用及优势:
作用: AOP使用动态代理实现,在程序运行期间,可以在不修改源码的情况下对已有方法进行增强。
优势: 减少重复代码 、提高开发效率 、维护方便。
AOP是通过动态代理实现的,但具体怎么实现我没有动手操作过,只是看过一些相关的面试题。
可以参考下这篇:AOP如何实现及实现原理_Java笔记-CSDN博客_aop原理
Q6、前端调用controller接口的过程
从代码层面简单说一下
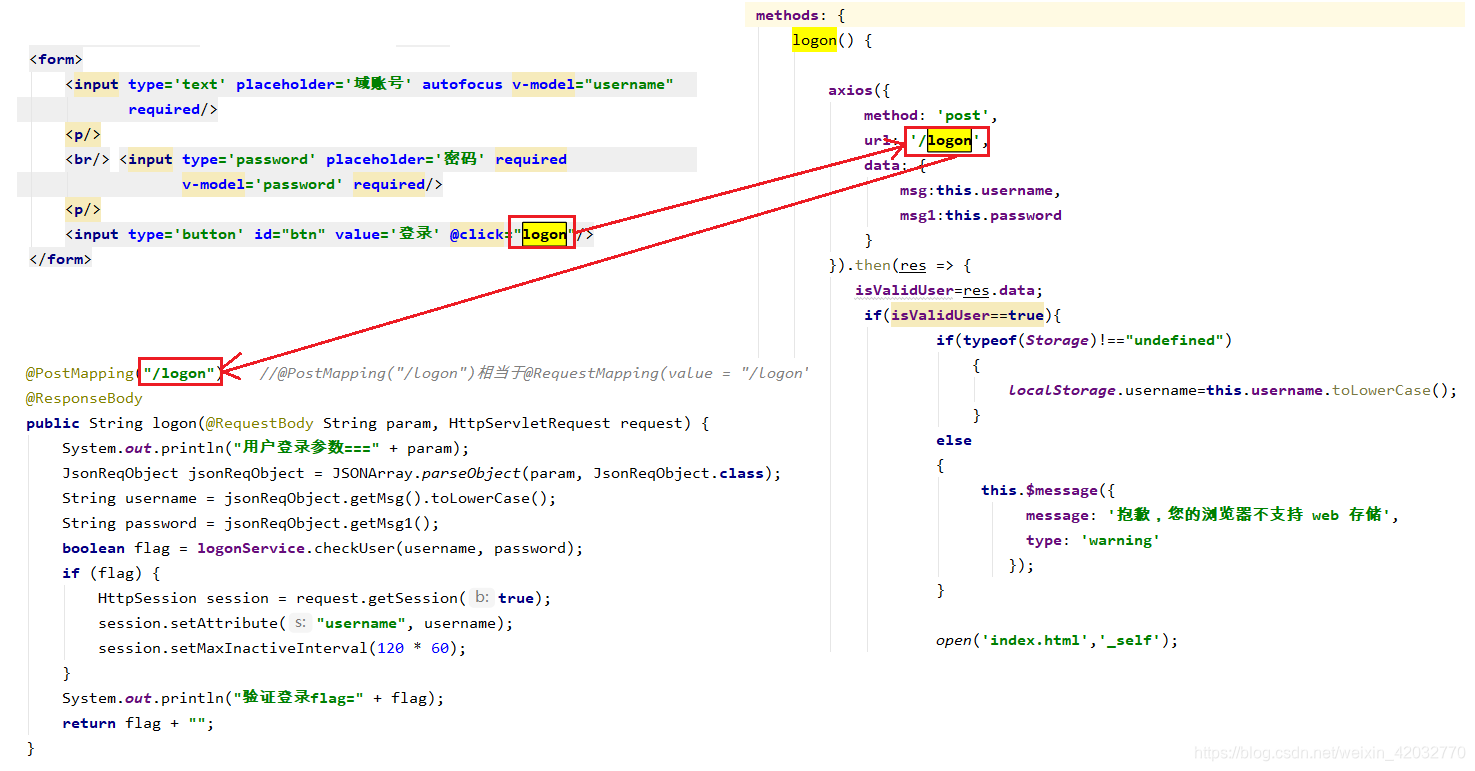
5、Linux常用命令
ifconfig --查看网络命令
service network restart --重启网络配置
service iptables status --查看防火墙启用状态
service iptables start/service iptables restart --启用防火墙
service iptables stop --关闭防火墙
service sshd start --开启ssh(使用工具ssh或xshell连接linux时必须先开启)
tar --压缩包相关命令
tar -cvf /home/abc.tar /home/abc --只打包,不压缩
tar -zcvf /home/abc.tar.gz /home/abc --打包,并用gzip压缩
tar -jcvf /home/abc.tar.bz2 /home/abc --打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令 tar -cvf / tar -zcvf / tar -jcvf 中的“c” 换成“x” 就可以了,例如:tar -zxvf redis-6.2.1.tar.gz --解压
ls --显示文件或目录
ls -l --显示文件或目录以及创建时间
ls -ll --显示文件或目录、创建时间和文件大小
ls -lh --显示文件或目录、创建时间和文件大小
cat xxx --从第一行开始显示文本内容(适用于内容较少的)
tac xxx --从最后一行开始显示,是 cat 的逆顺序
more xxx 一页一页的显示文本内容(适用于内容较多的)
less xxx --与 more 类似,但是比 more 更好的是,它可以往前翻页!
head xxx --只看文本的前面几行
tail xxx --只看文本的后面几行
nl xxx --显示文本内容与行号
cd xxx/ --切换目录
cd / --返回根目录
cd .. --返回上一级目录
touch xxx.txt --创建文件
mkdir xxxs --创建文件夹
vi sentinel.conf --新建一个文件
rm redis6379.conf --删除文件(如果出现是否删除询问,输入 y/n)
rm -f redis6379.conf --强制删除
rmdir rediscluster_conf --删除文件夹
cp redis_conf/redis6379.conf rediscluster_conf --把redis_conf文件夹下的redis6379.conf文件复制到rediscluster_conf文件夹中
cp redis6379.conf redis6380.conf --把redis6379.conf复制一份并把名字改为redis6380.conf
:%s/6379/6380 --把6379替换为6380可参考:Linux常用命令(面试题)_RuiDer的博客-CSDN博客_linux常用命令面试题
6、Git常用命令
$ git config --global user.name "Atlantide"
$ git config --global user.email "13917052985@163.com"
$ git init
$ git remote add origin https://gitee.com/wulinchun/Graduation_Project.git
$ git add .
$ git commit -m "基于springboot和mybatis的erp系统"
$ git push origin master
$ git push origin master -f --强制提交
https://gitee.com/wulinchun/Video_teaching_platform.git
$ git remote add origin https://gitee.com/wulinchun/Video_teaching_studing_platform.git
$ git commit -m "基于springMVC和jdbc和mysql的视频教学*台"
$ git remote rm origin(删除关联的origin的远程库)
$ git remote update origin --prune --git更新远程分支
可参考:git常用命令与常见面试题总结_From Zero To Hero-CSDN博客_git常用命令面试
gitee在实际工作中都是集成开发工具使用的,拉代码,推分支,合代码等这些操作都不需要用到命令的。
下面的这些git代码可以着重记一下,当你推代码推错了,可以通过回滚本地分支再推到远程分支上实现一个覆盖。
git check CMS //切换到自己的本地分支
git log //查看历史提交记录
git reset --hard 29b4ebb37aad1f57039428806875f6b5e672eee5 //回退到之前指定版本
git push origin CMS --force //强制提交本地代码到远程分支
git pull //同步本地与远程分支具体可参考:gitee删除上传到的远程分支的提交记录_金斗潼关的博客-CSDN博客
7、Vue
Q1、Vue启动流程
1、最简单的
可以通过引入vue的官方在线开发环境,来使用vue框架。
<!-- 开发环境版本,包含了有帮助的命令行警告 -->
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
<!-- 官网提供的 axios 在线地址 -->
<script src="https://cdn.bootcdn.net/ajax/libs/axios/0.20.0-0/axios.min.js"></script>
引入官方提供的vue开发环境以及axios在线地址2、引入vue.js
3、创建一个vue项目
npm run dev
可参考:Vue+ElementUI+Springboot实现前后端分离的一个demo_金斗潼关的博客-CSDN博客
相关详细vue面试题可参考:Vue进阶(四十七):面试必备:2021 Vue经典面试题总结(含答案)_IT全栈 华强工作室-CSDN博客_vue面试题
Q2、DOM
DOM是文档对象模型,是和javascript相关用来绘制前端的网页。
8、中间件
消息队列:Rabbit MQ
关于消息队列,初级开发只要会用就行了,以RabbitMQ为例,在方法上添加@RabbitListener就可以监听相应队列的消息了。
我之前整理过相关RabbitMQ的学习笔记
面试题的话,可以参考这两篇
RabbitMQ几个常用面试题 - woadmin - 博客园
rabbitmq面试题_Java技术博客-CSDN博客_rabbitmq面试题
9、Redis
Q1、Redis几种基本类型及区别和应用场景
Redis是一个开源的key-value存储系统。
Redis的五种基本类型:String(字符串),list(链表),set(集合),zset(有序集合),hash,stream(Redis5.0后的新数据结构)
这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。
Redis的应用场景为配合关系型数据库做高速缓存,降低数据库IO
需要注意的是,Redis是单线程的,如果一次批量处理命令过多,会造成Redis阻塞或网络拥塞(传输数据量大)

1、String
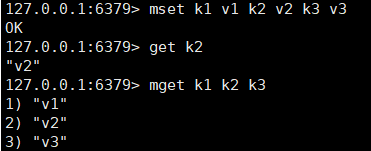
string 是Redis的最基本的数据类型,可以理解为与 Memcached 一模一样的类型,一个key 对应一个 value。string 类型是二进制安全的,意思是 Redis 的 string 可以包含任何数据,比如图片或者序列化的对象,一个 redis 中字符串 value 最多可以是 512M。
用法:


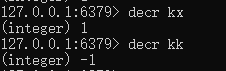
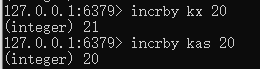
Incr:可以给key中的value值加1,如果key不存在则先初始化为0后再加1

Decr:可以给key中的value值减1,如果key不存在则先初始化为0后再减1
Incrby: 可以给key中的value值加指定的值,如果key不存在则先初始化为0后再加指定的值
典型使用场景
一、计数
由于Redis单线程的特点,我们不用考虑并发造成计数不准的问题,通过 incrby 命令,我们可以正确的得到我们想要的结果。
二、限制次数
比如登录次数校验,错误超过三次5分钟内就不让登录了,使用setex每次登录设置key自增一次,并设置该key的过期时间为5分钟后,每次登录检查一下该key的值来进行限制登录。
2、hash数据类型
hash 是一个键值对集合,是一个 string 类型的 key和 value 的映射表,key 还是key,但是value是一个键值对(key-value)。类比于 Java里面的 Map<String,Map<String,Object>> 集合。
用法:


典型使用场景
查询的时间复杂度是O(1),用于缓存一些信息。
3、list数据类型
list 列表,它是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表。
列表有两个特点:1、有序。2、可重复
用法:



典型使用场景
一、栈:通过命令 lpush+lpop
二、队列:命令 lpush+rpop
三、有限集合:命令 lpush+ltrim
四、消息队列:命令 lpush+brpop
4、set数据类型
Redis 的 set 是 string 类型的无序集合。
相对于列表,集合也有两个特点:1、无序 2、不可重复
用法:



典型使用场景
利用集合的交并集特性,比如在社交领域,我们可以很方便的求出多个用户的共同好友,共同感兴趣的领域等。
5、zset数据类型
zset(sorted set 有序集合),和上面的set 数据类型一样,也是 string 类型元素的集合,但是它是有序的。
用法:



典型使用场景
和set数据结构一样,zset也可以用于社交领域的相关业务,并且还可以利用zset 的有序特性,还可以做类似排行榜的业务。
6、stream(Redis5.0新数据结构)
redis stream主要用于消息队列(MQ,Message Queue),Redis本身是有一个Redis发布订阅(pub/sub)来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis宕机等,消息就会被丢弃。
关于redis的详细可以参考我之前整理的一篇redis学习笔记:Redis学习整理_金斗潼关的博客-CSDN博客
Q2、在项目中,你用Redis干了些什么
可以谈谈Redis分布式锁——Redisson,Redisson是一个非公*锁,适用于并发的情况下,可以锁住一段代码。
<!-- https://mvnrepository.com/artifact/org.redisson/redisson -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.2</version>
</dependency>@Autowired
private Redisson redissonClient;
private final String LOCK="25YEAR";
RLock lock=redissonClient.getLock(LOCK);
lock.lock();
try {
要加锁的代码
}catch (Exception e){
e.printStackTrace();
}
lock.unlock();再谈谈redisTemplate常用方法,以及分别的对应应用场景,比如登录缓存,有效期这些。
Q3、在springboot中如何找到redis的配置信息
Springboot配置redis: 可参考: Redis在SpringBoot中的配置_MIYAOW-CSDN博客
引入redis依赖:spring-boot-starter-redis,添加配置文件,添加cache的配置类,接下来就可以直接使用了。
Q4、如何用redis存储token信息及配置失效时间
//用户名作为token,设置过期时间为5分钟
redisTemplate.opsForValue().set("token", "username", 5, TimeUnit.MINUTES);10、Maven
Q1、如何在maven中央仓库找到你想用的包,如果中央仓库没有这个包怎么办
首先可以去mvn repository网站上搜相应的依赖名称,在pom.xml中添加该依赖。让maven自动联网下载相应的jar包,如果自动下载失败,则需手动添加。
具体方法为: Step1、从网上下载相应的jar包。
Step2、cmd进入命令行:
mvn install:install-file -Dfile=f:\modbus4j-3.0.3.jar -DgroupId=com.infiniteautomation -DartifactId=modbus4j -Dversion=3.0.3 -Dpackaging=jar
Q2、Maven dependency的注入过程
在pom.xml写入依赖,加载maven项目时选择“enauto import”,让maven自动去联网下载jar包,如果自动下载jar包失败,则Reimport一下maven窗口。如果jar包还是下载失败或者依赖无法被识别(标红),则需手动往maven仓库里面添加jar包。
11、持久层框架
Q1、Hibernate和Mybatis的区别及应用场景
Hibernate
Hibernate是一个标准的ORM框架,不需要写sql,只需要通过mapping将实体类与数据库的表一一映射关联,通过操作实体类,来改变数据库表中的数据。
此时配置文件就搞定了直接去Main方法写代码
首先创建出Configuration对象调用configure()方法加载配置文件
然后通过Configuration对象调用buildSessionFactory()方法得到SessionFactory()
然后调用openSession()得到Session对象,通过Session对象开启事务
———————————————
增加方法:创建实体对象调用set方法插入数据以后使用session调用save(对象引用)方法将数据同步到数据库中
删除方法:通过session.get(实体.class,id);得到查询的对象 使用session.delete(对象引用)将查询的对象删除
修改方法:通过session.get(实体.class,id);得到查询的对象,使用对象引用修改数据之后使用session.update(对象引用);
查询方法:直接session.get(实体.class,id);
不要忘了提交还有关闭
transaction.commit();
session.close();
hibernate优点:
hibernate框架的好处是不用自己写sql,sql语句自动生成,开发效率比较高
hibernate缺点:
对sql语句进行优化,修改比较困难。
应用场景:
适用于需求变化不多的中小型项目,比如:后台管理系统。
mybatis
mybatis:专注是sql本身,需要程序员自己编写sql语句,sql修改,优化比较方便。mybatis是一个不完全的ORM框架,虽然程序员自己写sql,mybatis也可以实现映射(输入映射,输出映射)。
应用场景:
适用于需求变化较多的项目,比如:互联网项目
mybatis-plus
Mybatis-Plus(简称MP)是 Mybatis 的增强工具,在 Mybatis 的基础上只做增强不做改变,为简化开发、提高效率而生。mybatis-plus已经封装好了一些crud方法,我们不需要再写SQL语句了,直接调用这些方法就行。
可参考:Mybatis-plus实现数据库的增删改查操作_金斗潼关的博客-CSDN博客
12、其他
Q1、什么是同步和异步
同步:指发送一个请求,需要等待返回,然后才能够发送下一个请求,有个等待过程。
异步:指发送一个请求,不需要等待返回,随时可以再发送下一个请求,即不需要等待。
Q2、在后端中如何实现一个异步操作
springboot中实现异步:使用注解@Async,@Async注解是加在要异步的方法上,然后在springboot启动类上要加注解@EnableAsync开启异步。
使用@Async注解要注意的地方是必须把相应的接口注入,而不是注入其实现类。可参考:编写异步任务@Async出现bean无法注入的问题解决方案_金斗潼关的博客-CSDN博客
关于异步这块,在jdk1.8中新增了一个CompletableFuture.runAsync()可以实现多线程异步任务。
CompletableFuture completableFuture1 = CompletableFuture.runAsync(() -> {
xxx1();
});
CompletableFuture completableFuture2 = CompletableFuture.runAsync(() -> {
xxx2();
});
CompletableFuture completableFuture3 = CompletableFuture.runAsync(() -> {
xxx3();
});package com.springboot_redis;
import java.util.concurrent.CompletableFuture;
/**
* @author: wu linchun
* @time: 2021/9/28 21:13
* @description:
*/
public class Test {
public static void main(String[] args) throws InterruptedException {
CompletableFuture completableFuture1 = CompletableFuture.runAsync(() -> {
try {
xxx1();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
CompletableFuture completableFuture2 = CompletableFuture.runAsync(() -> {
try {
xxx2();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
CompletableFuture completableFuture3 = CompletableFuture.runAsync(() -> {
try {
xxx3();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
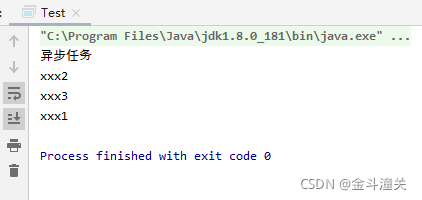
System.out.println("异步任务");
Thread.sleep(5000);
}
static void xxx1() throws InterruptedException {
Thread.sleep(1000);
System.out.println("xxx1");
}
static void xxx2() throws InterruptedException {
Thread.sleep(1000);
System.out.println("xxx2");
}
static void xxx3() throws InterruptedException {
Thread.sleep(1000);
System.out.println("xxx3");
}
}
package com.springboot_redis;
import java.util.concurrent.CompletableFuture;
/**
* @author: wu linchun
* @time: 2021/9/28 21:13
* @description:
*/
public class Test {
public static void main(String[] args) throws InterruptedException {
CompletableFuture completableFuture1 = CompletableFuture.runAsync(() -> {
try {
xxx1();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
CompletableFuture completableFuture2 = CompletableFuture.runAsync(() -> {
try {
xxx2();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
CompletableFuture completableFuture3 = CompletableFuture.runAsync(() -> {
try {
xxx3();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
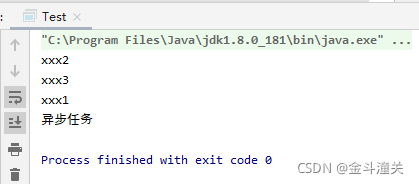
CompletableFuture cf = CompletableFuture.allOf(completableFuture1, completableFuture2, completableFuture3);
//等待并行处理完毕
cf.join();
System.out.println("异步任务");
Thread.sleep(5000);
}
static void xxx1() throws InterruptedException {
Thread.sleep(1000);
System.out.println("xxx1");
}
static void xxx2() throws InterruptedException {
Thread.sleep(1000);
System.out.println("xxx2");
}
static void xxx3() throws InterruptedException {
Thread.sleep(1000);
System.out.println("xxx3");
}
}
Q3、前端后端交互的过程
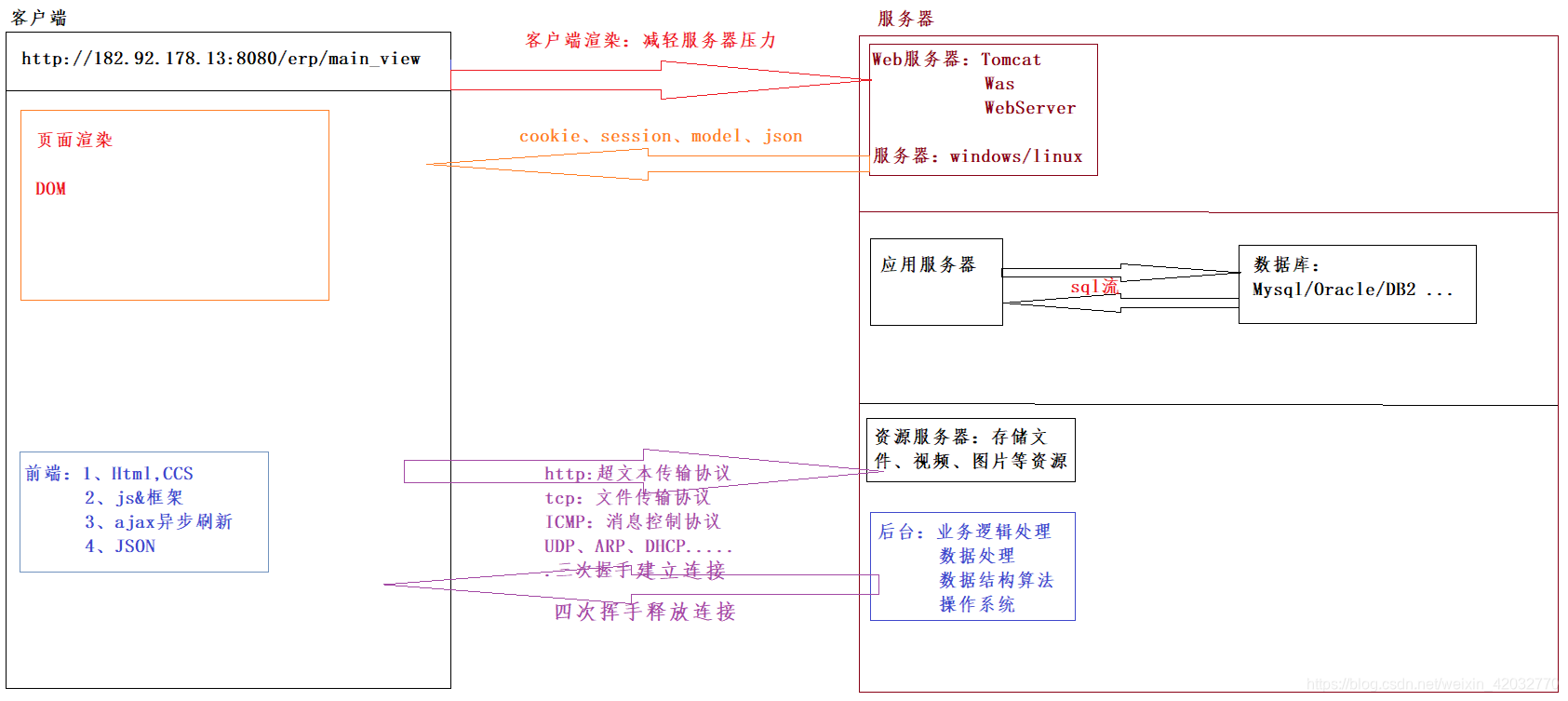
13、总结
这些题目是我之前以及最*在面试时被问到的,然后做了一个整理以及相应的拓展,部分的回答可能会有不周到或者不合理的地方,如有的话欢迎指正。对于本文中的一些知识点,由于本人学识经验有限,更多的还是偏向于概念+应用。对于实现原理这块,有所了解但因为自己也没有透彻的理解,所以也不好表述,等我后续深入了解后会做相应的补充的。
今天是9/28也算是我在高知特的最后一天了,明天9/29就去下家公司了,也算是无缝衔接了。
累计算下来,也在高知特干了1年零4个月了。因为是人力外包公司,第一年是外包到甲方公司的生产运维,不涉及写代码。然后今年6月份换到另一个甲方做App的后端开发,才算正式开始接触写代码了。原本打算再干久一点,但由于项目的原因,不得已选择跳槽的。感觉还是有点仓促的。
其实对于外包有一点不太好的地方就是人力外包本身就是相当于甲方公司的临时工,不同的项目之间缺乏连续性,因此很难说能够有太多的积累和成长性。
之前在知乎看到一篇回答,有一点点感同身受。
为什么it外包永远在招人? - 知乎 (zhihu.com)
当然外包其实也有很多好的地方,外包其实主要还是看项目,如果项目好的话确实可以学到不少东西,并且也可以积累一些甲方公司的资源的。
个人感觉外包主要适合三种人:
- 想进一些巨头公司,或者大型银行的,当时由于名额或者其他原因进不了,但可以通过外包进入这些公司,工作几年争取转甲方(不过前提是学历,工作能力过硬)。
- 应届生或者刚入行的缺乏经验的可以进外包练练手,因为通常对于外包,甲方的要求会低一些,而且外包公司会对员工有简历包装,面试培训这种。再加上甲方也会看在外包公司的面子上,问的差不多就行了。
- 暂时没有理想的公司,外包也是不错的选择。毕竟外包公司,不管是高知特、中科软、复深蓝、中软国际、软通动力、京北方等,都是具有一定规模的公司。起码相应的福利工资可以得到保障的,抗风险能力强,这绝对比许多初创小公司画大饼的老板要强的多。
之前看到过一篇文章,是讨论产品思维的
大多数技术本身并不值钱,技术变现才是王道。技术变现的一种方式就是通过产品,无论是app,网站系统这种实体变现,还是卖课,智商税这种知识变现。都比单纯的会用这些技术强。
之前看到的一篇回答
为什么程序员到一定年纪开始关注管理相关的内容,不再在技术上深入下去? - 知乎
第一个项目的Home Manager有一次和我说过他为什么会从做开发转到管理,他说开发做到后面写代码做需求真的是很枯燥也没有发展空间。当时还没明白他的意思,现在有些明白了。
有机会还是要多读读书,读个研究生,提升一下学历什么的。虽然IT这行讲究实战,但有时候学历真的是决定上限的。多去认识些人,多积累些资源,多见识见识吧。不要让会写代码成为你唯一拿的出手的东西了。不过开始工作的三五年内还是以写好高质量的代码为准。
暂时就这些了,明天还要去新公司报到了。
一年很短,但未来很长。
14、参考资料
Linux | 文本文件查看命令_嵌入式大杂烩-CSDN博客_linux查看文件命令
探讨一下Vue和以前的jQuery两大框架的的区别_别把代码当饭吃-CSDN博客_jquery和vue的区别
面试官:说一下公*锁和非公*锁的区别? - 知乎 (zhihu.com)
java初级开发面试题的更多相关文章
- J2EE进阶(十四)超详细的Java后台开发面试题之Spring IOC与AOP
J2EE进阶(十四)超详细的Java后台开发面试题之Spring IOC与AOP 前言 搜狐畅游笔试题中有一道问答题涉及到回答谈谈对Spring IOC与AOP的理解.特将相关内容进行整理. ...
- 各大公司java后端开发面试题
各大公司Java后端开发面试题总结 ThreadLocal(线程变量副本)Synchronized实现内存共享,ThreadLocal为每个线程维护一个本地变量.采用空间换时间,它用于线程间的数据隔离 ...
- 入我新美大的Java后台开发面试题总结
静儿最近在总结一些面试题,那是因为做什么事情都要认真.面试也一样,静儿作为新美大金融部门的面试官,负责任的告诉大家,下面的问题回答不上来,面试是过不了的.不过以下绝不是原题,你会发现自己实力不过硬,最 ...
- 面试题:各大公司Java后端开发面试题总结 已看1 背1 有用 链接有必要看看
ThreadLocal(线程变量副本) --整理 Synchronized实现内存共享,ThreadLocal为每个线程维护一个本地变量. 采用空间换时间,它用于线程间的数据隔离,为每一个 ...
- 用友网络科技Java高级开发面试题(2019)
面试时间:2019年8月18日上午9:30 面试岗位:Java高级开发 面试形式:电话面试 这些天在boss上逛了下,看见北京Java开发工资比较诱人,便萌生了去北京的想法,做一名北漂的程序猿.约了几 ...
- 最新阿里Java后端开发面试题100道(P6-P7)
面试题 1.什么是字节码?采用字节码的好处是什么?2. Oracle JDK 和 OpenJDK 的对比?3.Arrays.sort 和 Collections.sort 实现原理和区别4.wait ...
- 各大公司Java后端开发面试题总结
ThreadLocal(线程变量副本)Synchronized实现内存共享,ThreadLocal为每个线程维护一个本地变量.采用空间换时间,它用于线程间的数据隔离,为每一个使用该变量的线程提供一个副 ...
- Java后台开发面试题总结
1>如何定位线上服务OOM问题 2>JVM的GC ROOTS存在于那些地方 3>mysql innodb怎样做查询优化 4>java cas的概念 Java服务OOM,比较常见 ...
- (最新)各大公司Java后端开发面试题总结
ThreadLocal(线程变量副本) Synchronized实现内存共享,ThreadLocal为每个线程维护一个本地变量. 采用空间换时间,它用于线程间的数据隔离,为每一个使用该变量的线程提供一 ...
随机推荐
- 死锁与Lock锁
死锁1.死锁的理解:不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁 2.说明: 1)出现死锁后,不会出现异常,不会出现提示,只是所有的线程都处于阻塞 ...
- VS code 如何使用HTML Boilerplate插件
此插件是一个HTML 模版插件,可以摆脱为 HTML 新文件重新编写头部和正文标签的苦恼. 只需在空文件中输入 html,并按 tab 键,即可生成干净的文档结构.也可以输入!,然后按tab键或者en ...
- wpf 手指触摸图片放大缩小 设置放大缩小值
xaml代码: <Window x:Class="WpfApp1.MainWindow" xmlns="http://schemas.microsoft.com/w ...
- git的介绍、git的功能特性、git工作流程、git 过滤文件、git多分支管理、远程仓库、把路飞项目传到远程仓库(非空的)、ssh链接远程仓库,协同开发
Git(读音为/gɪt/)是一个开源的分布式版本控制系统,可以有效.高速地处理从很小到非常大的项目版本管理. [1] 也是Linus Torvalds为了帮助管理Linux内核开发而开发的一个开放源码 ...
- 第一章:TypeScript快速入门
一.TypeScript 开发环境搭建 1.TypeScript 是什么? TypeScript 是一种由微软开发的自由和开源的编程语言.它是 JavaScript 的一个超集,而且本质上向这个语言添 ...
- centos7 uwsgi 加入系统服务
生产环境中采用nginx + uwsgi + django 来部署web服务,这里需要实现uwsgi的启动和停止,简单的处理方式可以直接在命令行中启动和kill掉uwsgi服务,但为了更安全.方便的管 ...
- 【Java集合框架002】原理层面:HashMap全解析
一.前言 二.HashMap 2.1 HashMap数据结构 + HashMap线程不安全 + 哈希冲突 2.1.1 HashMap数据结构 学习的时候,先整体后细节,HashMap整体结构是 底层数 ...
- Codeforces Round #833 (Div. 2)补题
Codeforces Round #833 (Div. 2) D. ConstructOR 知识点:高位和对低位无影响 一开始以为和广州的M一样,是数位dp,后来发现只要找到一个就行 果然无论什么时候 ...
- (C++) C++ new operator, operator new 及 placement new (待整理)
https://blog.csdn.net/songthin/article/details/1703966 https://cplusplus.com/reference/new/operator ...
- Linux系统安装 tftp服务 NFS服务
安装tftp服务 安装 sudo apt-get install tftp-hpa tftpd-hpa 配置文件 # /etc/default/tftpd-hpa TFTP_USERNAME=&quo ...