ALBERT论文简读
问题描述
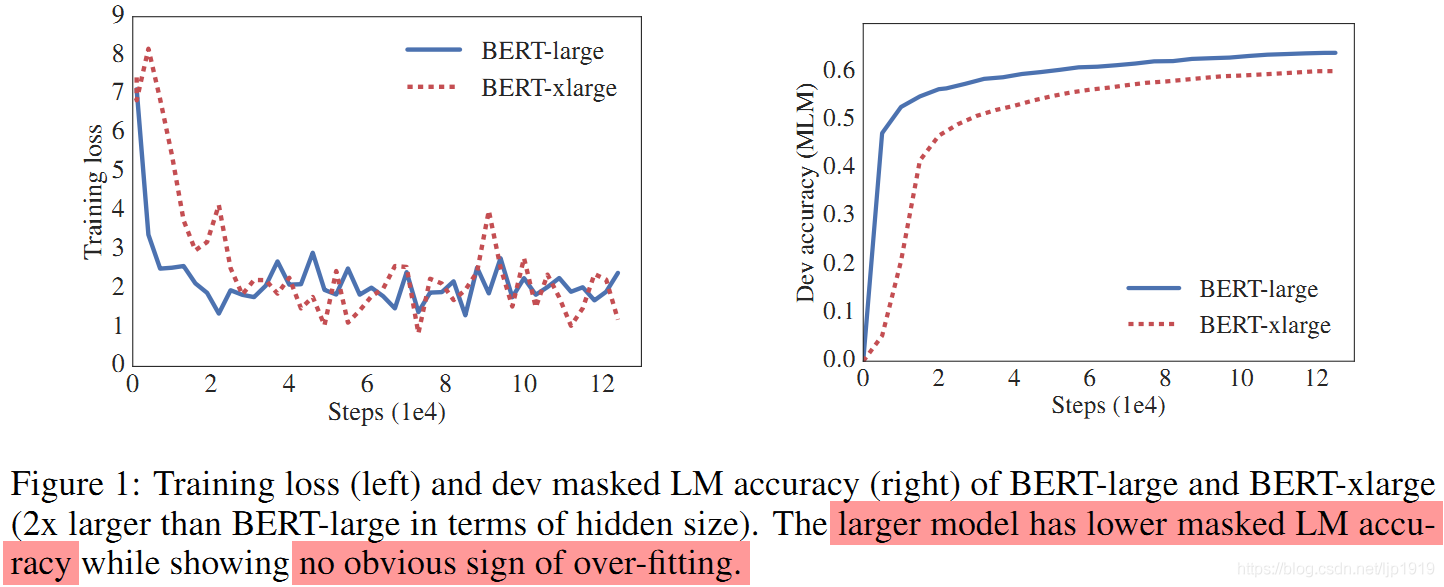
预训练自然语言表征时,增加模型的参数量通常可以是模型在下有任务中性能提升。但是这种做法对硬件设备的要求较高(当下的各种SOTA模型动辄数亿甚至数十亿个参数,倘若要扩大模型规模,这个内存问题是无法回避的),也会显著地降低训练效率(由于通信开销与模型中参数的数量成正比,在分布式训练中训练速度将成为一大瓶颈。简单地增加隐含层单元数,只会适得其反,从而降低效率)。并且随着模型参数的增加,模型性能会先提升,后又会随着参数的增加性能反而变差。
核心方法
为了降低模型训练的系统开销,提升模型的训练效率,且几乎不降低模型效果,本文做如下一些优化:
对嵌入参数进行因式分解(factorized embedding parameterization)。将一个大的词汇嵌入矩阵分解为两个小的矩阵, 将隐藏层的大小与词汇嵌入的大小分离开来(原本认为词汇嵌入学习的是一种上下文无关,无依赖的词嵌入表示;而隐状态学习的是上下文相关的,有上下文依赖的表示;故而应该将其分类开来,同时降低了参数)。此过程其实就是降低了词嵌入向量的长度,使得每个词嵌入向量长度远小于隐状态的向量长度(原bert模型中二者长度相同)。而且在后续增加隐状态的参数时,并不会显著增加词汇嵌入的参数量
跨层参数共享。共享模型不同layer之间的参数,避免模型参数量随着网络深度的增加而增加
- All-shared:在该方法中,与其他编码器的所有子层共享第一个编码器的所有子层的参数
- Shared feedforward network:只与其他编码器层的前馈网络共享第一个编码器层的前馈网络的参数
- Shared attention:只与其他编码层的多头注意力共享第一个编码器层的多头注意力参数。
句子顺序预测(SOP:sentence-order prediction)。在bert中有提出NSP,即预测一个句子是否是另一个句子的下一句。其正样本是两个连续的句子,欺负样本中后一句来自于其他文档,这可能会导致模型根据两句话的主题就能判断后一句子是否是前一句子的next sentence,而并未真正学到语序信息。本文所提SOP的正样本与bert一样,但负样本是将正样本进行对换顺序,从而预测两个句子顺序。
实验结果
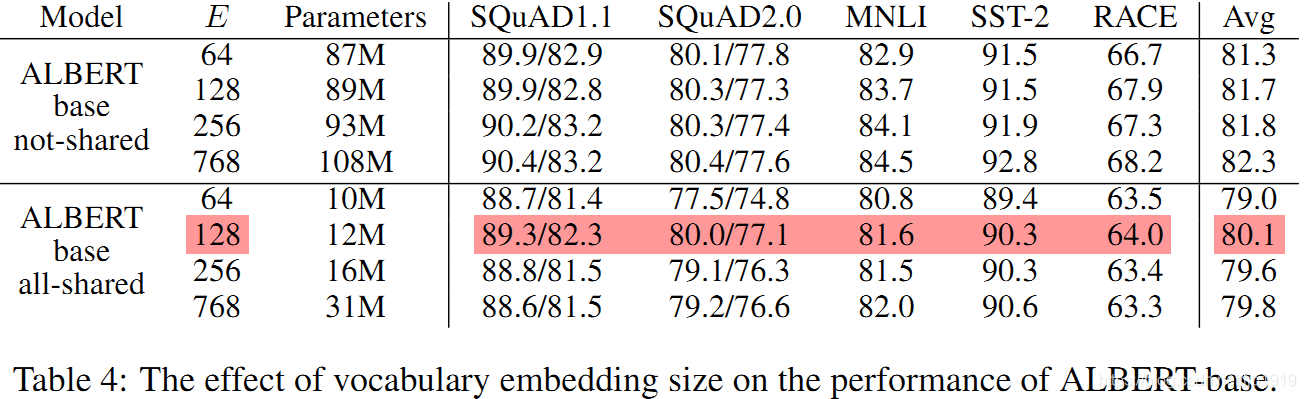
对于ALBERT,在不共享参数时,词嵌入的尺寸越大,模型效果越好,但提升幅度并不是很大;在共享参数时,随着嵌入尺寸增大,模型效果先变好,后变差。
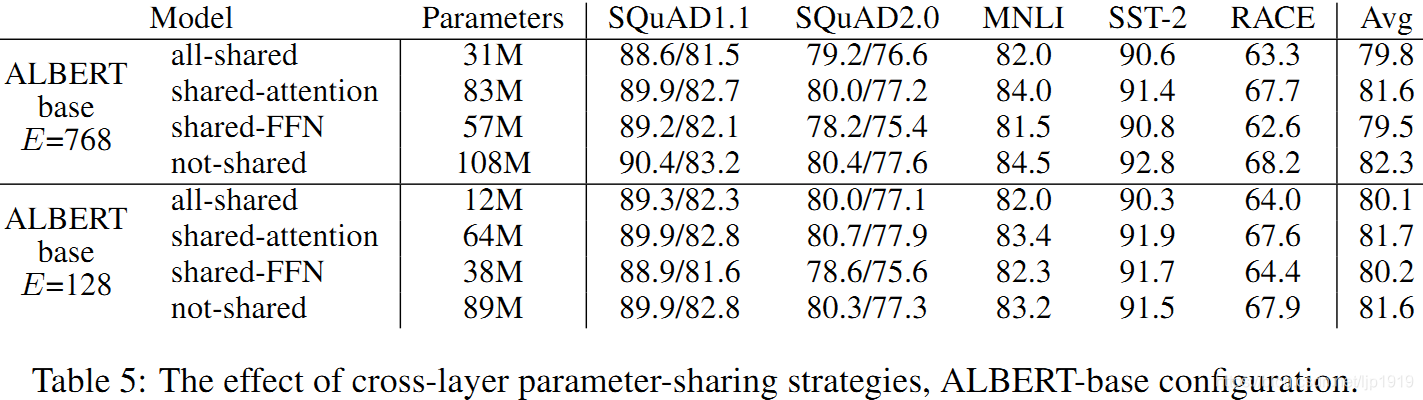
不同跨层参数共享的效果,同样使用 ALBERT-base 作为示例模型,all-shared策略(ALBERT-style)、not-shared 策略(BERT-style)及其介于二者之间的中间策略(仅注意力参数共享,FNN不共享;仅FNN参数共享,注意力参数不共享)。总体而言,all-shared型策略使得模型在一定程度上降低了性能,但是下降幅度较小。
在预测下一句任务中,本文总共对比三种策略:没有句子间损失(比如XLNet和RoBERTa)、NSP(比如BERT)、SOP(ALBERT)。从表中可以看出,训练NSP任务,对SOP任务的益处并不明显,正确率只打到52%;而SOP任务则有利于NSP,能使其正确率达到78.9%。更重要的是,SOP对下游任务性能的提升也较为明显。

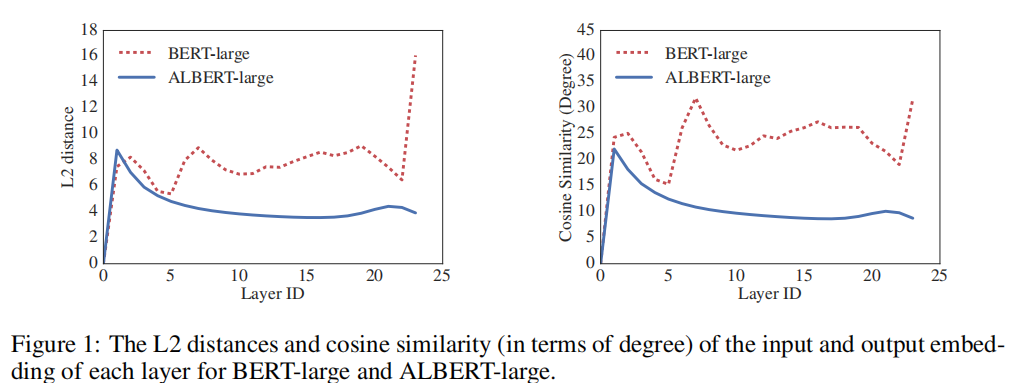
ALBERT模型默认使用All-shared方式。实验表明,使用参数共享后,每一层的输入嵌入和输入嵌入的L2距离和余弦相似度都比bert平滑得多,证明参数共享能够使模型的参数更加稳定。
参考链接
https://blog.csdn.net/ljp1919/article/details/101680220
https://blog.csdn.net/yjw123456/article/details/120275965
ALBERT论文简读的更多相关文章
- 【论文简读】 Deep web data extraction based on visual
<Deep web data extraction based on visual information processing>作者 J Liu 上海海事大学 2017 AIHC会议登载 ...
- 简读《ASP.NET Core技术内幕与项目实战》之3:配置
特别说明:1.本系列内容主要基于杨中科老师的书籍<ASP.NET Core技术内幕与项目实战>及配套的B站视频视频教程,同时会增加极少部分的小知识点2.本系列教程主要目的是提炼知识点,追求 ...
- 论文泛读:Click Fraud Detection: Adversarial Pattern Recognition over 5 Years at Microsoft
这篇论文非常适合工业界的人(比如我)去读,有很多的借鉴意义. 强烈建议自己去读. title:五年微软经验的点击欺诈检测 摘要:1.微软很厉害.2.本文描述了大规模数据挖掘所面临的独特挑战.解决这一问 ...
- ICCV 2019|70 篇论文抢先读,含目标检测/自动驾驶/GCN/等(提供PDF下载)
虽然ICCV2019已经公布了接收ID名单,但是具体的论文都还没放出来,为了让大家更快得看论文,我们汇总了目前已经公布的大部分ICCV2019 论文,并组织了ICCV2019论文汇总开源项目(http ...
- React v16-alpha 从virtual dom 到 dom 源码简读
一.物料准备 1.克隆react源码, github 地址:https://github.com/facebook/react.git 2.安装gulp 3.在react源码根目录下: $npm in ...
- 论文速读(Chuhui Xue——【arxiv2019】MSR_Multi-Scale Shape Regression for Scene Text Detection)
Chuhui Xue--[arxiv2019]MSR_Multi-Scale Shape Regression for Scene Text Detection 论文 Chuhui Xue--[arx ...
- 论文速读(Jiaming Liu——【2019】Detecting Text in the Wild with Deep Character Embedding Network )
Jiaming Liu--[2019]Detecting Text in the Wild with Deep Character Embedding Network 论文 Jiaming Liu-- ...
- 论文速读(Yongchao Xu——【2018】TextField_Learning A Deep Direction Field for Irregular Scene Text)
Yongchao Xu--[2018]TextField_Learning A Deep Direction Field for Irregular Scene Text Detection 论文 Y ...
- 【论文速读】Cong_Yao_CVPR2017_EAST_An_Efficient_and_Accurate_Scene_Text_Detector
Cong_Yao_CVPR2017_EAST_An_Efficient_and_Accurate_Scene_Text_Detector 作者和代码 非官方版tensorflow实现 非官方版kera ...
- 论文泛读 A Novel Ensemble Learning-based Approach for Click Fraud Detection in Mobile Advertising [1/10]
title:新的基于集成学习的移动广告作弊检测 导语:基于buzzcity数据集,我们提出了对点击欺诈检测是基于一组来自现有属性的新功能的一种新方法.根据所得到的精度.召回率和AUC对所提出的模型进行 ...
随机推荐
- 基于Linux下的Ubuntu操作系统常用命令
一 .linux操作系统的特点 1.linux下一切皆文件 2.linux系统就像一个倒置数 3.linux系统支持多用户.多任务 二. Ubuntu --"乌班图"操作系统 Ub ...
- python之路36 MySQL查询关键字
报错及作业讲解 报错 1.粗心大意 单词拼写错误 2.手忙脚乱 不会看报错 思考错误的核心 作业讲解 '''表与表中数据的关系可能会根据业务逻辑的不同 发生改变 不是永远固定的''' 服务器表与应用程 ...
- [Leetcode]设计链表
题目 设计链表的实现.您可以选择使用单链表或双链表.单链表中的节点应该具有两个属性:val 和 next.val 是当前节点的值,next 是指向下一个节点的指针/引用.如果要使用双向链表,则还需要一 ...
- [WPF]限制程序单例运行
代码 System.Threading.Mutex mutex; protected override void OnStartup(StartupEventArgs e) { bool ret; m ...
- SPOJ PHONELST - Phone List | UVA11362 Phone List | LibreOJ10049. 「一本通 2.3 例 1」Phone List
简要题意 \(t\) 组数据,每组数据给定 \(n\) 个长度不超过 \(10\) 的数字串,判断是否有两个字符串 \(A\) 和 \(B\),满足 \(A\) 是 \(B\) 的前缀,若有,输出 N ...
- 线段树套线性基——题解P4839 P哥的桶
文章历史 2022-08-03: 文章初稿,由于对算法介绍过于少而被管理员打回重造. 2020-08-06:将算法介绍进行扩写,并删除了一些可有可无的内容或玩梗内容. 管理员审核题解辛苦了. 简要题意 ...
- 使用prometheus来避免Kubernetes CPU Limits造成的事故
使用prometheus来避免Kubernetes CPU Limits造成的事故 译自:Using Prometheus to Avoid Disasters with Kubernetes CPU ...
- Java 进阶P-7.4+P-7.5
JTable 用JTbale类可以以表格的形式显示和编辑数据. JTable类的对象并不存储数据,他只是数据的表现. 表格是 Swing 新增加的组件,主要功能是把数据以二维表格的形式显示出来,并且允 ...
- Map集合概述-Map常用子类
Map集合概述 现实生活中,我们常会看到这样的一种集合︰IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种--对应的关系,就叫做映射.Java提供了专门的集合类用来存放这种对象关系的对 ...
- 论文翻译:2022_2022_TEA-PSE 2.0:Sub-Band Network For Real-Time Personalized Speech Enhancement
论文地址:TEA-PSE 2.0:用于实时个性化语音增强的子带网络 论文代码: 引用: 摘要 个性化语音增强(Personalized speech enhancement,PSE)利用额外的线索,如 ...