ShardingSphere-JDBC实战
一、环境准备
1.数据库
创建2个库2个表:
- xdclass_shop_order_0
- product_order_0
- product_order_1
- ad_config
- product_order_item_0
- product_order_item_1
- xdclass_shop_order_1
- product_order_0
- product_order_1
- ad_config
- product_order_item_0
- product_order_item_1
数据库脚本:
CREATE TABLE `product_order_0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`out_trade_no` varchar(64) DEFAULT NULL COMMENT '订单唯一标识',
`state` varchar(11) DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',
`create_time` datetime DEFAULT NULL COMMENT '订单生成时间',
`pay_amount` decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',
`nickname` varchar(64) DEFAULT NULL COMMENT '昵称',
`user_id` bigint DEFAULT NULL COMMENT '用户id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
CREATE TABLE `ad_config` (
`id` bigint unsigned NOT NULL COMMENT '主键id',
`config_key` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置key',
`config_value` varchar(1024) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '配置value',
`type` varchar(128) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '类型',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
CREATE TABLE `product_order_item_0` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`product_order_id` bigint DEFAULT NULL COMMENT '订单号',
`product_id` bigint DEFAULT NULL COMMENT '产品id',
`product_name` varchar(128) DEFAULT NULL COMMENT '商品名称',
`buy_num` int DEFAULT NULL COMMENT '购买数量',
`user_id` bigint DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
2.代码工程
1.工程创建
- 创建Maven工程,添加相关Maven依赖,
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<spring.boot.version>2.5.5</spring.boot.version>
<mybatisplus.boot.starter.version>3.4.0</mybatisplus.boot.starter.version>
<lombok.version>1.18.16</lombok.version>
<sharding-jdbc.version>4.1.1</sharding-jdbc.version>
<junit.version>4.12</junit.version>
<druid.version>1.1.16</druid.version>
<!--跳过单元测试-->
<skipTests>true</skipTests>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring.boot.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>${spring.boot.version}</version>
<scope>test</scope>
</dependency>
<!--mybatis plus和springboot整合-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatisplus.boot.starter.version}</version>
</dependency>
<!-- mysql数据库 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<!-- shardingshpere-jdbc-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-jdbc.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>
- 添加数据库配置文件,根据配置文件可知,配置了两个数据库ds0,ds1;
spring.application.name=yb-sharding-jdbc
server.port=8080
logging.level.root=INFO
# 打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true
# 数据源 ds0 ds1
spring.shardingsphere.datasource.names=ds0,ds1
# 第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ybe_shop_order0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=*****
# 第二个数据库
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ybe_shop_order1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=*****
2.广播表介绍和配置实战
- 添加AdConfigDO实体类和添加ProductOrderDOMapper类
//数据库实体类
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("ad_config")
public class AdConfigDO {
private Long id;
private String configKey;
private String configValue;
private String type;
}
//数据库实体配置类
public interface AdConfigMapper extends BaseMapper<AdConfigDO> {
}
- 设置ad_config为广播表,如果需要配置多个用 逗号 (,) 分开;设置id为生成算法为雪花算法。配置文件中添加如下代码,
#配置广播表
spring.shardingsphere.sharding.broadcast-tables=ad_config
spring.shardingsphere.sharding.tables.ad_config.key-generator.column=id
spring.shardingsphere.sharding.tables.ad_config.key-generator.type=SNOWFLAKE
- 添加测试方法
@Test
public void testSaveAdConfig(){
AdConfigDO adConfigDO = new AdConfigDO();
adConfigDO.setConfigKey("banner");
adConfigDO.setConfigValue("ybe.com");
adConfigDO.setType("ad");
adConfigMapper.insert(adConfigDO);
}
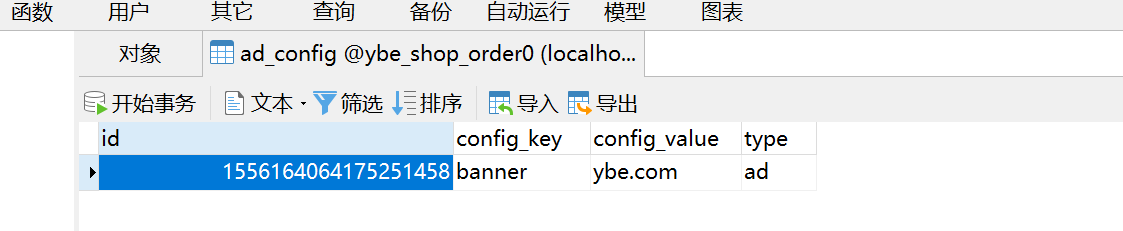
- 执行结果,两个数据库的表都进行了更新。如下图

3.绑定表介绍和配置实战
- 添加ProductOrderItemDO实体类和添加ProductOrderDOMapper类
//数据库实体类
@Data
@TableName("product_order_item")
@EqualsAndHashCode(callSuper = false)
public class ProductOrderItemDO {
private Long id;
private Long productOrderId;
private Long productId;
private String productName;
private Integer buyNum;
private Long userId;
}
//数据库实体配置类
public interface ProductOrderItemMapper extends BaseMapper<ProductOrderItemDO> {
}
- 添加配置文件,设置product_order和product_order_ite为广播表,如果需要配置多个需要配置多行,binding-tables是个数据
#配置绑定表
spring.shardingsphere.sharding.binding-tables[0]=product_order,product_order_item
- 添加测试方法
@Test
public void testBinding(){
List<Object> objects = productOrderMapper.listProductOrderDetail();
System.out.println(objects);
}
执行结果:
- 添加绑定表配置之前,可以看到查询的sql语句,主表和子表是笛卡尔积的关联关系。如下图,

- 添加绑定表配置之后,可以看到查询的sql语句,主表和子表是一一对应的。如下图,

4.行表达式分片策略 InlineShardingStrategy
- 只支持【单分片键】使用Groovy的表达式,提供对SQL语句中的 =和IN 的分片操作支持
- 可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
- 添加ProductOrderDO实体类和添加ProductOrderDOMapper类
//数据库实体类
@Data
@TableName("product_order")
@EqualsAndHashCode(callSuper = false)
public class ProductOrderDO {
// 不设置Mybatis-plus的主键规则,由sharding-jdbc 设置
private Long id;
private String outTradeNo;
private String state;
private Date createTime;
private Double payAmount;
private String nickname;
private Long userId;
}
//数据库实体配置类
public interface ProductOrderMapper extends BaseMapper<ProductOrderDO> {
}
- 配置文件添加如下代码,
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
#id生成策略
spring.shardingsphere.sharding.tables.product_order.key-generator.column=id
spring.shardingsphere.sharding.tables.product_order.key-generator.type=SNOWFLAKE
#work_id 的设置
spring.shardingsphere.sharding.tables.product_order.key-generator.props.worker.id=1
#配置分库规则
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
#配置分表规则
#指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{id % 2}
由配置文件可知,
设置了product_order为逻辑表,设置了它的真实数据节点为ds$->{0..1}.product_order_$->{0..1},使用了表达式$->{...},它表示实际的物理表为:ds0.product_order_0,ds0.product_order_1,ds1.product_order_0,ds1.product_order_1,总共对应了2个库的2个物理表。
设置了product_order表的id计算方式为雪花算法;
设置了product_order表的分库规则,分库规则为 user_id % 2;也就是说会根据user_id % 2的结果确定是ds0库还是ds1库。
设置了product_order表的分表规则,分表规则为 id % 2;也就是说会根据id % 2的结果确定是product_order_0表还是product_order_1表。
- 添加测试方法
@Test
public void testSaveProductOrder(){
Random random = new Random();
for (int i = 0 ;i < 10 ; i++){
// id是由配置的雪花算法生成
ProductOrderDO productOrderDO = new ProductOrderDO();
productOrderDO.setCreateTime(new Date());
productOrderDO.setNickname("ybe:"+i);
productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrderDO.setPayAmount(100.00);
productOrderDO.setState("PAY");
// 随机生成UserId
productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrderDO);
}
}
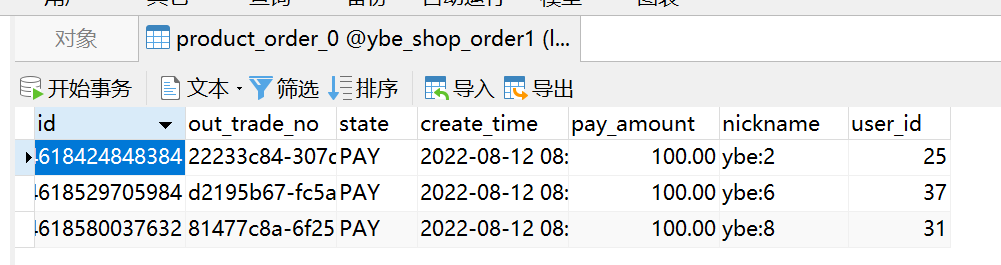
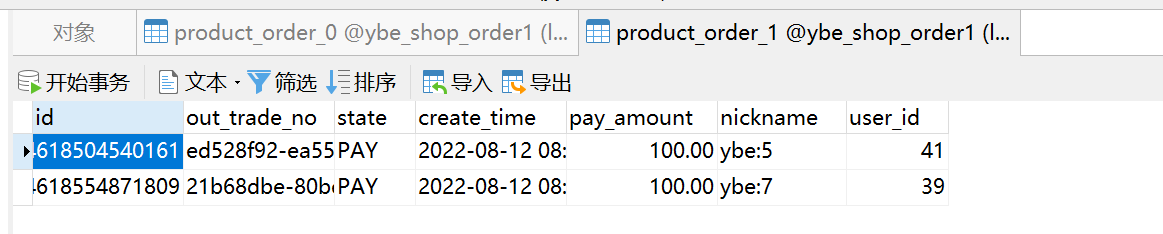
- 执行结果根据不同的user_id 和 id ,生成的表记录插入到了不同的库和表,如下图可以看到数据分散在了两个不同的数据库,以及不同的表中。


5.标准分片策略StandardShardingStrategy
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分片 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
- 添加分表配置类CustomTablePreciseShardingAlgorithm
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//循环遍历 数据源,根据算法
for (String databaseName : collection) {
String value = preciseShardingValue.getValue() % collection.size() + "";
//value是0,则进入0库表,1则进入1库表
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
- 添加分库配置类CustomDBPreciseShardingAlgorithm
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
for (String databaseName : collection) {
String value = preciseShardingValue.getValue() % collection.size() + "";
//value是0,则进入0库表,1则进入1库表
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
- 添加分表范围配置类CustomRangeShardingAlgorithm
public class CustomRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param rangeShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Set<String> result = new LinkedHashSet<>();
// between 起始值
Long lower = rangeShardingValue.getValueRange().lowerEndpoint();
// between 结束值
Long upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (long i = lower; i <= upper; i++) {
for (String databaseName : collection) {
if (databaseName.endsWith(i % collection.size() + "")) {
result.add(databaseName);
}
}
}
return result;
}
}
- 配置文件添加图下代码,
# 分库分片算法
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=com.ybe.algorithm.CustomDBPreciseShardingAlgorithm
#精准水平分表下,增加一个范围分片
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.range-algorithm-class-name=com.ybe.algorithm.CustomRangeShardingAlgorithm
# 分表分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=com.ybe.algorithm.CustomTablePreciseShardingAlgorithm
- 添加测试方法
@Test
public void testRand(){
Random random = new Random();
for (int i = 0 ;i < 10 ; i++){
ProductOrderDO productOrderDO = new ProductOrderDO();
productOrderDO.setCreateTime(new Date());
productOrderDO.setNickname("ybe:"+i);
productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrderDO.setPayAmount(100.00);
productOrderDO.setState("PAY");
productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrderDO);
}
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().between("id",1L,1L));
}
- 执行结果:1.会根据配置的分库、分表规则进行插入不同的数据库和表;2.范围(between)查询的时候会根据id的范围值查询映射的物理表集合。
6.标准分片策略StandardShardingStrategy
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分片 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
添加分表配置类CustomTablePreciseShardingAlgorithm
public class CustomTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//循环遍历 数据源,根据算法
for (String databaseName : collection) {
String value = preciseShardingValue.getValue() % collection.size() + "";
//value是0,则进入0库表,1则进入1库表
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
}
添加分库配置类CustomDBPreciseShardingAlgorithm
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param preciseShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
for (String databaseName : collection) {
String value = preciseShardingValue.getValue() % collection.size() + "";
//value是0,则进入0库表,1则进入1库表
if (databaseName.endsWith(value)) {
return databaseName;
}
}
throw new IllegalArgumentException();
}
添加分表范围配置类CustomRangeShardingAlgorithm
public class CustomRangeShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* @param collection 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param rangeShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),
* value 为从 SQL 中解析出的分片健的值
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
Set<String> result = new LinkedHashSet<>();
// between 起始值
Long lower = rangeShardingValue.getValueRange().lowerEndpoint();
// between 结束值
Long upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (long i = lower; i <= upper; i++) {
for (String databaseName : collection) {
if (databaseName.endsWith(i % collection.size() + "")) {
result.add(databaseName);
}
}
}
return result;
}
}
添加配置文件
# 分库分片算法
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.database-strategy.standard.precise-algorithm-class-name=com.ybe.algorithm.CustomDBPreciseShardingAlgorithm
#精准水平分表下,增加一个范围分片
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.range-algorithm-class-name=com.ybe.algorithm.CustomRangeShardingAlgorithm
# 分表分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.sharding-column=id
spring.shardingsphere.sharding.tables.product_order.table-strategy.standard.precise-algorithm-class-name=com.ybe.algorithm.CustomTablePreciseShardingAlgorithm
添加测试方法
@Test
public void testRand(){
Random random = new Random();
for (int i = 0 ;i < 10 ; i++){
ProductOrderDO productOrderDO = new ProductOrderDO();
productOrderDO.setCreateTime(new Date());
productOrderDO.setNickname("ybe:"+i);
productOrderDO.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrderDO.setPayAmount(100.00);
productOrderDO.setState("PAY");
productOrderDO.setUserId(Long.valueOf(random.nextInt(50)));
productOrderMapper.insert(productOrderDO);
}
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().between("id",1L,1L));
}
执行结果:1.会根据配置的分库、分表规则进行插入不同的数据库和表;2.between范围查询的时候会根据id查询映射的物理表集合。
7.复合分片算法ComplexShardingStrategy
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作,支持【多分片键】
- 由于多分片键之间的关系复杂,Sharding-JDBC并未做过多的封装
- 而是直接将分片键值组合以及分片操作符交于算法接口,全部由应用开发者实现,提供最大的灵活度
- 添加分表配置类CustomComplexKeysShardingAlgorithm
public class CustomComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
// 得到每个分片健对应的值
Collection<Long> orderIdValues = this.getShardingValue(complexKeysShardingValue, "id");
Collection<Long> userIdValues = this.getShardingValue(complexKeysShardingValue, "user_id");
List<String> shardingSuffix = new ArrayList<>();
// 对两个分片健取模的方式
for (Long userId : userIdValues) {
for (Long orderId : orderIdValues) {
String suffix = userId % 2 + "_" + orderId % 2;
for (String databaseName : collection) {
if (databaseName.endsWith(suffix)) {
shardingSuffix.add(databaseName);
}
}
}
}
return shardingSuffix;
}
/**
* shardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnNameAndShardingValuesMap 存储多个分片健 包括key-value
* key:分片key,id和user_id
* value:分片value,66和99
*
* @return shardingValues 集合
*/
private Collection<Long> getShardingValue(ComplexKeysShardingValue<Long> shardingValues, final String key) {
Collection<Long> valueSet = new ArrayList<>();
Map<String, Collection<Long>> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if (columnNameAndShardingValuesMap.containsKey(key)) {
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
}
return valueSet;
}
- 配置文件添加如下代码,多个列的类型必须一样。
# 复合分片算法,order_id,user_id 同时作为分片健
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.sharding-columns=user_id,id
spring.shardingsphere.sharding.tables.product_order.table-strategy.complex.algorithm-class-name=com.ybe.algorithm.CustomComplexKeysShardingAlgorithm
- 添加测试方法
@Test
public void testComplex(){
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id",66L).eq("user_id",99L));
}
- 执行结果:1.会根据配置的复合分片算法去查找相关的物理表。
8.Hint分片算法HintShardingStrategy
- 这种分片策略无需配置文件进行配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行
- 通过Hint代码指定的方式而非SQL解析的方式分片的策略
- Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好
- 可以指定sql去某个库某个表进行执行
- 添加分表配置类CustomTableHintShardingAlgorithm
public class CustomTableHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String tableName : collection) {
for (Long shardingValue : hintShardingValue.getValues()) {
if (tableName.endsWith(String.valueOf(shardingValue % collection.size()))) {
result.add(tableName);
}
}
}
return result;
}
}
- 添加分库配置类CustomDBHintShardingAlgorithm
public class CustomDBHintShardingAlgorithm implements HintShardingAlgorithm<Long>
{
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String dbName : collection) {
for (Long shardingValue : hintShardingValue.getValues()) {
if (dbName.endsWith(String.valueOf(shardingValue % collection.size()))) {
result.add(dbName);
}
}
}
return result;
}
}
- 配置文件添加如下代码
# Hint分片算法
spring.shardingsphere.sharding.tables.product_order.table-strategy.hint.algorithm-class-name=com.ybe.algorithm.CustomTableHintShardingAlgorithm
spring.shardingsphere.sharding.tables.product_order.database-strategy.hint.algorithm-class-name=com.ybe.algorithm.CustomDBHintShardingAlgorithm
- 添加测试方法
@Test
public void testHint(){
// 清除掉历史的规则
HintManager.clear();
//Hint分片策略必须要使用 HintManager工具类
HintManager hintManager = HintManager.getInstance();
// 设置库的分片健,value用于库分片取模,
hintManager.addDatabaseShardingValue("product_order",4L);
// 设置表的分片健,value用于表分片取模,
hintManager.addTableShardingValue("product_order", 5L);
//对应的value只做查询,不做sql解析
productOrderMapper.selectList(new QueryWrapper<ProductOrderDO>().eq("id", 66L));
}
- 执行结果:1.不会解析Sql中的分片键,会把hintManager配置的值作为分片键,在CustomTableHintShardingAlgorithm分片算法的中使用。
ShardingSphere-JDBC实战的更多相关文章
- JDBC实战案例--利用jdbc实现的宠物信息管理系统
一.需求: 利用jdbc实现对宠物的信息进行管理的一套系统 宠物信息:宠物ID,宠物类别,宠物名字,宠物性别,宠物年龄,宠物入库日期 系统完成功能:实现对宠物信息的录入,修改,删除,查询. 二.解决方 ...
- spark之JDBC开发(实战)
一.概述 Spark Core.Spark-SQL与Spark-Streaming都是相同的,编写好之后打成jar包使用spark-submit命令提交到集群运行应用$SPARK_HOME/bin#. ...
- 重磅|Apache ShardingSphere 5.0.0 即将正式发布
Apache ShardingSphere 5.0.0 GA 版在经历 5.0.0-alpha 及 5.0.0-beta 接近两年时间的研发和打磨,终于将在 11 月份与大家正式见面! 11 月 10 ...
- JDBC上
JDBC实战--打通数据库 代码实现: package com.imooc.db; import java.sql.Connection; import java.sql.DriverManager; ...
- Apache ShardingSphere 5.1.2 发布|全新驱动 API + 云原生部署,打造高性能数据网关
在 Apache ShardingSphere 5.1.1 发布后,ShardingSphere 合并了来自全球的团队或个人的累计 1028 个 PR,为大家带来 5.1.2 新版本.该版本在功能.性 ...
- MYSQL的Java操作器——JDBC
MYSQL的Java操作器--JDBC 在学习了Mysql之后,我们就要把Mysql和我们之前所学习的Java所结合起来 而JDBC就是这样一种工具:帮助我们使用Java语言来操作Mysql数据库 J ...
- Hibernate学习笔记整理系列-------一、Hibernate简介
Hibernate的官网:http://hibernate.org/ 1.1 Hibernate框架的作用 Hibernate框架是一个数据访问框架(也叫持久层框架,可将实体对象变成持久对象).通过H ...
- SpringCloud微服务实战——搭建企业级开发框架(二十七):集成多数据源+Seata分布式事务+读写分离+分库分表
读写分离:为了确保数据库产品的稳定性,很多数据库拥有双机热备功能.也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器:第二台数据库服务器,主要进行读的操作. 目前有多种方式实现读写分离,一种 ...
- ShardingSphere 集成 CosId 实战
背景 在软件系统演进过程中,随着业务规模的增长 (TPS/存储容量),我们需要通过集群化部署来分摊计算.存储压力. 应用服务的无状态设计使其具备了伸缩性.在使用 Kubernetes 部署时我们只需要 ...
- 综合实战--文件上传系统【JDBC&IO&Socket】
本文纯属记录第一次实战遇到的坑和知识,如果后边有时间再做整理. 1,先写了个操作数据库的工具类SqlTool,照着JDBC资料打完之后,测试的时候出错了,java.lang.ClassNotFound ...
随机推荐
- CabloyJS部署了一套演示站点
为了方便大家快速体验和了解CabloyJS的风格和特性,全新部署了一套演示站点.对于初次接触CabloyJS的开发者,不用下载新建项目,就可以直接体验CabloyJS了 在线演示 场景 链接/二维码 ...
- JavaScript数据类型BigInt实践之id数值太大,导致前后端交互异常
项目开发中前后端数据交互常会使用id作为主键索引,通常id数值都不大,使用number类型就可以表示处理,但对于一些分布式id或其他情况,id数值太大且超过了JS的最大处理数(Math.pow(2, ...
- vue项目经常遇到的Error: Loading chunk * failed
vue项目随着代码量.业务组件.路由页面等的丰富,出于性能要求考虑不得不使用代码分割技术实现路由和组件的懒加载,这看似没什么问题 当每次通过npm run build构建生产包并部署到服务器后,操作页 ...
- SRE,了解一下?35+岁程序员新选择
摘要:随着云业务的发展,今后会有越来越多的工程师深入到SRE领域. 本文分享自华为云社区<浅谈SRE角色认知>,作者: SRE确定性运维. 一.什么是SRE? SRE(Site Relia ...
- LVGL库入门教程04-样式
LVGL样式 LVGL样式概述 创建样式 在 LVGL 中,样式都是以对象的方式存在,一个对象可以描述一种样式.每个控件都可以独立添加样式,创建的样式之间互不影响. 可以使用 lv_style_t 类 ...
- C语言学习之我见-strlen()字符串长度函数
strlen()函数,负责给出字符串的长度.注意是字符串的长度,不是字符数组的长度. (1)函数原型: size_t __cdecl strlen(const char *_Str); (2)头文件` ...
- 手把手教你实现一个图片压缩工具(Vue与Node的完美配合)
前言 图片压缩对于我们日常生活来讲,是非常实用的一项功能.有时我们会在在线图片压缩网站上进行压缩,有时会在电脑下软件进行压缩.那么我们能不能用前端的知识来自己实现一个图片压缩工具呢?答案是有的.效果展 ...
- Tomcat深入浅出(一)
一.Tomcat简介 我们下载好Tomcat后需要配置一下Java环境:如果打开出现闪退得情况,首先是jdk 同时配置JRE_HOME Tomcat的一些关键目录: /bin:存放用于启动及关闭的文件 ...
- android stdio开发抖音自动点赞案例
最近做了一个安卓开发自动刷抖音. 点赞. 评论等等养号行为. 总结一下知识点和遇到的一些问题: 知识点: 1. 使用acessibility mode 对抖音自动化操作. android stdio中 ...
- 方法的调用和JDK9的JShell简单使用
方法在定义完毕后,方法不会自己运行,必须被调用才能执行,我们可以在主方法main中来调用我们自己定义好的方法.在主方法中,直接写要调用的方法名字就可以调用了 public static void ma ...