日均 6000+ 实例,TB 级数据流量,Apache DolphinScheduler 如何做联通医疗大数据平台的“顶梁柱”?

作者 | 胡泽康 鄞乐炜
作者简介

胡泽康
联通(广东)产业互联网公司 大数据工程师,专注于开源大数据领域,从事大数据平台研发工作

鄞乐炜
联通(广东)产业互联网公司 大数据工程师,主要从事大数据平台的应用与引擎端开发
01 背景介绍
我们是联通医疗团队,一直践行 “服务医改,惠及民生” 的使命,全面驱动医疗健康产业数字化、智能化转型。
在调度系统选型初期,我们团队技术栈以 JVM 语言为主,由于 Airflow 的结构体系无法进行充分的改造和融合,因此在开源调度系统的选择上,我们主要对 **Azkaban 和 **Apache Dolphin Scheduler 进行了充分的调研和预演。结果显示,在相同的环境压测下,Azkaban 在稳定性上存在不足,会有任务积压和 executor 负载过高等影响,功能性上也存在一定的缺陷。
我们选择 Apache DolphinScheduler 主要原因有以下几点:
分布式去中心化结构,系统的稳定性有足够的保障;
可视化的DAG编辑模式,使用成本低;
多项目实施、资源隔离和动态扩缩容有完整的解决方案,可快速落地;
JVM体系,快速开发改造和适配。
从2020年开始,我们团队基于 Apache DolphinScheduler(版本1.3.2)构建了涵盖数据采集、同步、处理和治理为一体的大数据平台(UniM-Data)。在实际生产中,当前该平台每天处理超过6000+任务实例,调度系统承载业务量大,作业定义与调度策略复杂度高。在如此庞杂的任务调度中,**Apache DolphinScheduler **发挥了重要的作用,向上支撑应用侧的任务下发和管理,向下承接大数据底座的任务编排和调度。
02 UniM-Data架构
在社区的蓬勃发展下,Apache DolphinScheduler 已经演进到3.0版本,带来了很多优秀的特性和启发。UniM-Data当前在线运行的 Apache DolphinScheduler 原生****版本为1.3.2,产品迭代升级中吸收和融合了 Apache DolphinScheduler 的优秀架构和特性。基于系统设计和业务需求,我们团队对 Apache DolphinScheduler 做了一定的开发改造、适配和代码合并,让其在 UniM-Data 上仍能稳定支撑线上生产系统的运行。
接下来,我们也准备致力于 Apache DolphinScheduler 的版本升级,引入更多社区的优秀能力。在此也感谢社区的贡献,为我们带来如此优秀的项目,希望后续也能贡献我们的力量,为 Apache DolphinScheduler 的壮大添砖加瓦。
在 UniM-Data 的构建实践中,产品设计与 Apache DolphinScheduler 的风格存在一定的冲突,因此我们放弃了原有的 Apache DolphinScheduler 的 UI 前端,重新构建基于产品风格的前端页面。在 Apache DolphinScheduler 的底层实现中。为了满足平台团队、数仓团队、算法团队和医疗业务团队的实际需求,我们不仅借助 Apache DolphinScheduler 的优秀架构提供的任务调度和失败策略等能力,也在其之上展开了接口拓展、新增任务类型、血缘埋点、数据治理工具开发等工作,进行整体架构设计和构建。
UniM-Data 的整体的架构视图如下所示:
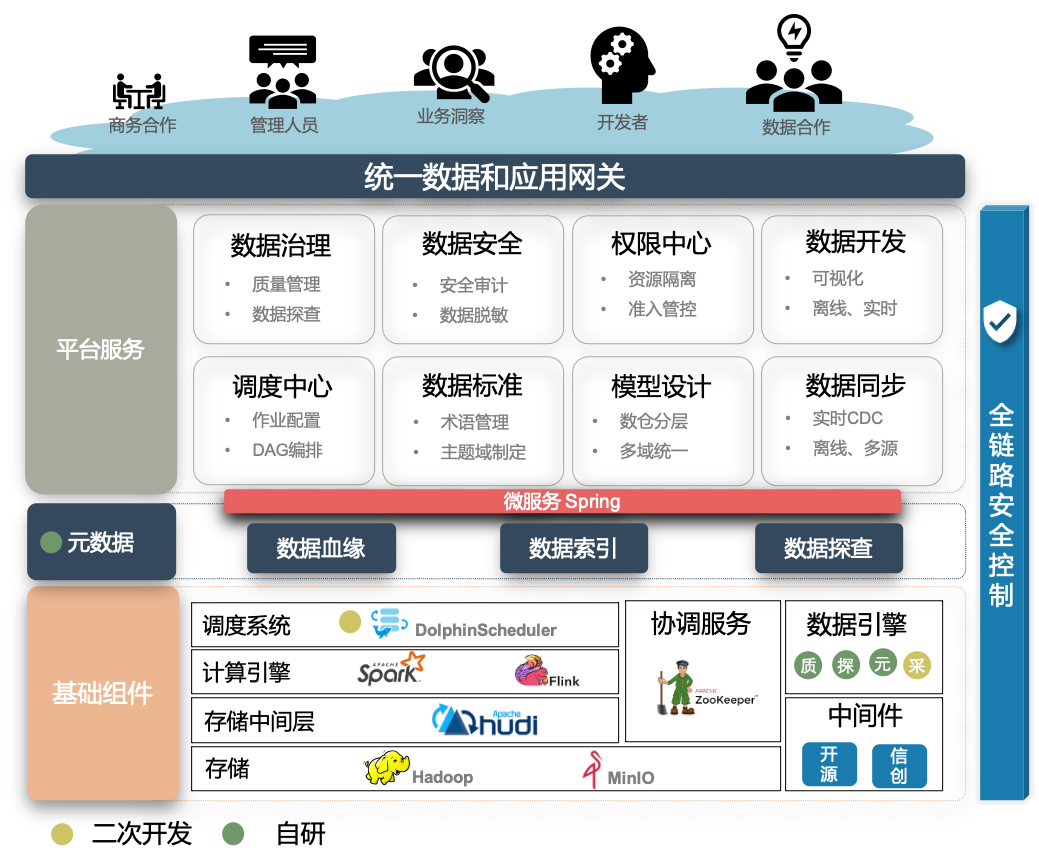
技术架构视图
03 Apache DolphinScheduler的实践与改造
从横向上看,UniM-Data 上元数据和数据安全两个模块贯穿数据的全生命周期,Apache DolphinScheduler 在其中扮演了关键角色,主要从任务执行器嵌入血缘采集、权限校验和数据探查等功能上,对生产加以支撑。
元数据模块在 UniM-Data 的设计上属于关键模块,可实现数据溯源、元数据采集、信息探查等功能(如下所示)。在全链路数据的变更上,都需要向元数据模块暴露血缘关系,我们的解决方案是在 Apache DolphinScheduler 上进行了各类任务的血缘埋点和采集器嵌入,如 Spark SQL、Spark Shell、数据同步等,实现了表级血缘的全链路采集。
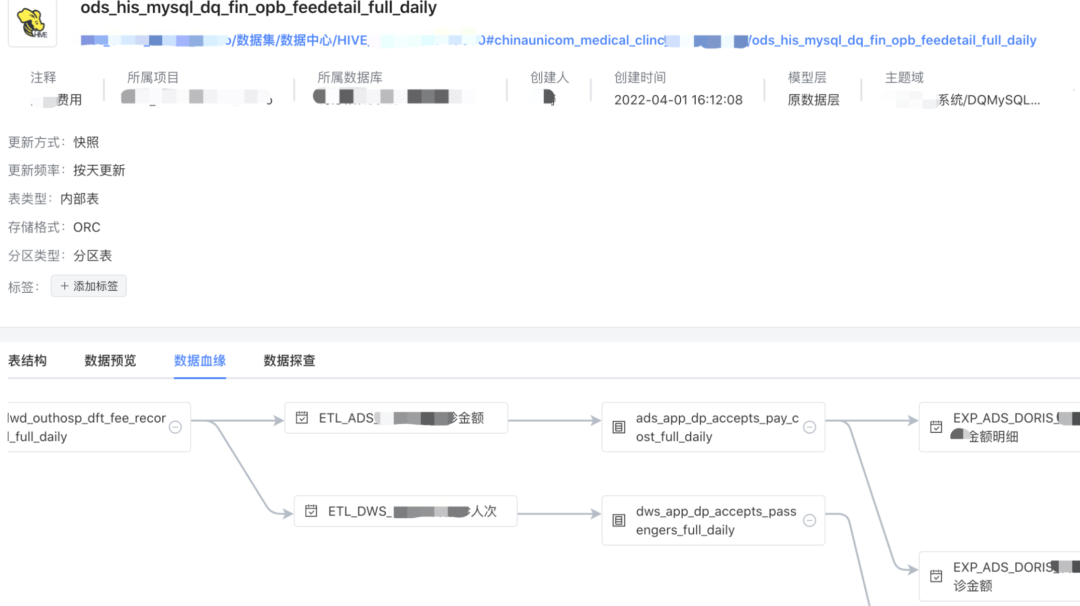
元数据管理
各类任务的血缘关系解析方式大致如下:
SQL类型:采用 Druid SQL 解析,解析源表和目标表信息。HiveSQL 使用org.apache.hadoop.hive.ql.parse 工具类解析
Spark shell:解析 Spark 的DAG信息,获取源表和目标表信息
数据同步:采用 DataX 进行数据同步,利用 DataX 的 Json 信息,解析源表和目标表
应用侧:建设模型设计模块,在数据变更时,同步进行血缘关系推送;应用侧,全部自研模块,可简单嵌入血缘采集器进行血缘信息推送
任务间:利用 Apache DolphinScheduler 的任务关系,串联表级血缘信息
数据安全模块,首先平台侧沿用 Apache DolphinScheduler 的项目管理模式,嵌入数据源隔离、用户权限、文件权限等功能,建设项目间资源隔离环境。在 Apache DolphinScheduler 上,我们在各类任务的生成上进行权限校验,统一访问平台权限中心,控制数据访问安全。
从纵向上看,在 **UniM-Data **上,我们主要借助 Apache Dolphin Scheduler 的任务调度、失败策略和补数等功能,支撑所有任务的既定计划的执行。主要从以下几方面进行了开发和适配:
离线开发
在进行 UniM-Data 的离线开发功能适配中,Apache DolphinScheduler (1.3.2)的原生版本在SQL任务类型通过 jdbc 连接时,对 Spark SQL,Hive SQL的支持上存在性能、稳定、安全认证等问题,以及交互上无法获取任务执行日志的痛点,加之使用团队的复杂需求,所以我们对离线开发任务做了统一的改造:
1) UniM-Data 的离线任务开发,提供了在线开发和调试功能。在 Apache DolphinScheduler 上,我们进行了任务编排逻辑的改造,支持任务开发调试确认后形成作业。任务在调试模式运行时,处理结果会缓存起来,支撑在线调试结果预览功能。
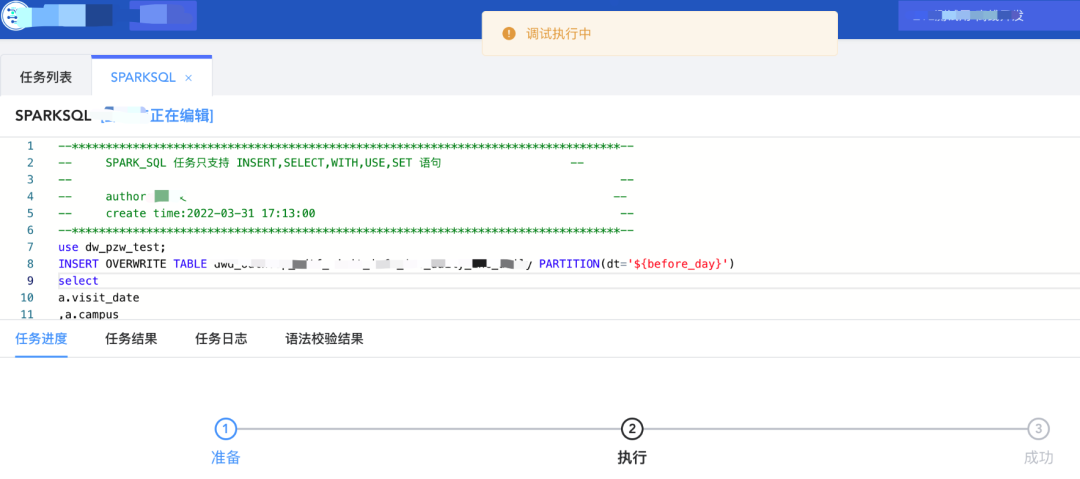
在线开发与调试
2) 在原生的 SQL 任务的基础上,添加备注支持、优化 SQL 语句切割逻辑等功能,贴近用户编辑 SQL 的使用习惯
3) 优化 Spark SQL 任务,放弃 Apache DolphinScheduler 原生使用Spark Thrift Server 的方案,采用 Spark API 进行封装,并使用 Spark Submit的方式执行,可以灵活配置资源,解决任务的性能和日志输出问题
4) 优化 Hive SQL 任务,融合 HiveServer2 的 HA 功能,使用 namespace 进行连接,解决应用端的并发和负载问题
5) 新增 Spark Shell 任务,支撑在线编辑 Spark 代码,在 SparkShell 的执行引擎内部,我们封装了 ApiProxy 的 API ,方便用户快速读写各数据源
6) 新增 Kerbero 安全认证,在各任务生成阶段,根据成员的 Kerberos 绑定信息,完成票据认证
7) 新增图形化开发任务(内部代号EasyFlow),搭载 Apache DolphinScheduler 的调度能力,提供低代码能力。现阶段已实现数据处理基本算子的集成,后续计划完成业务类算子的集成,支撑复杂业务逻辑形成算子能力。
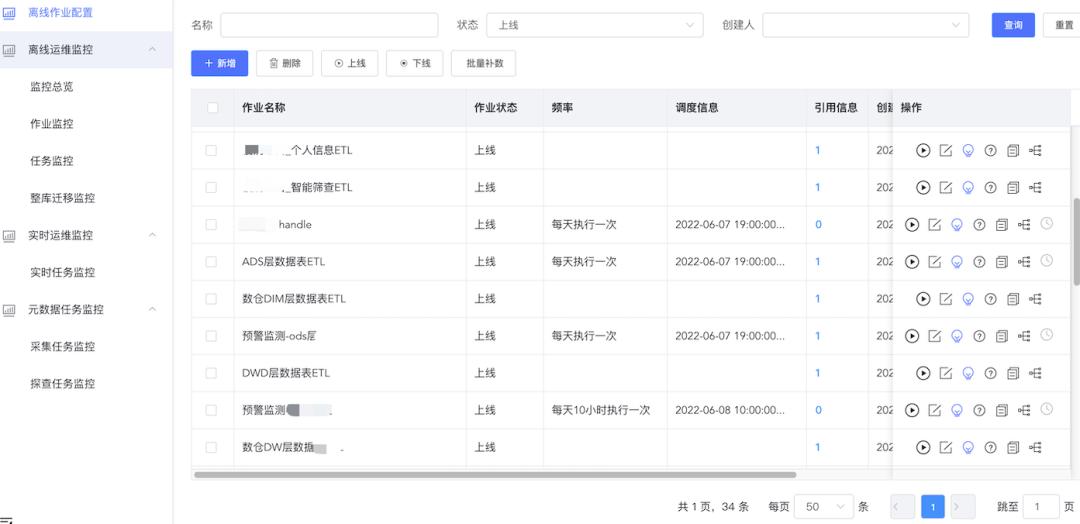
调度中心
UniM-Data 的调度中心主要借助 Apache DolphinScheduler 的任务调度能力,基本沿用其任务上下线、重跑、定时执行等能力,为用户提供任务监控和管理能力。为了使平台与 Apache DolphinScheduler 能够解耦,我们对其进行了接口拓展,新增和改造了任务添加、任务信息订阅等接口,暴露给平台进行通信。
数据同步
在 2020 年进行数据同步技术选型时,基于医疗信息多源异构的特点,我们经过考察分析,认为 Sqoop 虽然在分布式上具备一定的优势,但是需要使用 MR 的计算框架,成本较高。而 DataX 虽然是单进程模式,但可以通过 Apache DolphinScheduler 的调度系统进行性能规避,且单进程模式更容易进行控制和排错,DataX 具有开放式的框架,可以在极短的时间开发一个新插件,快速支持新的数据库/文件系统,实现架构如下:
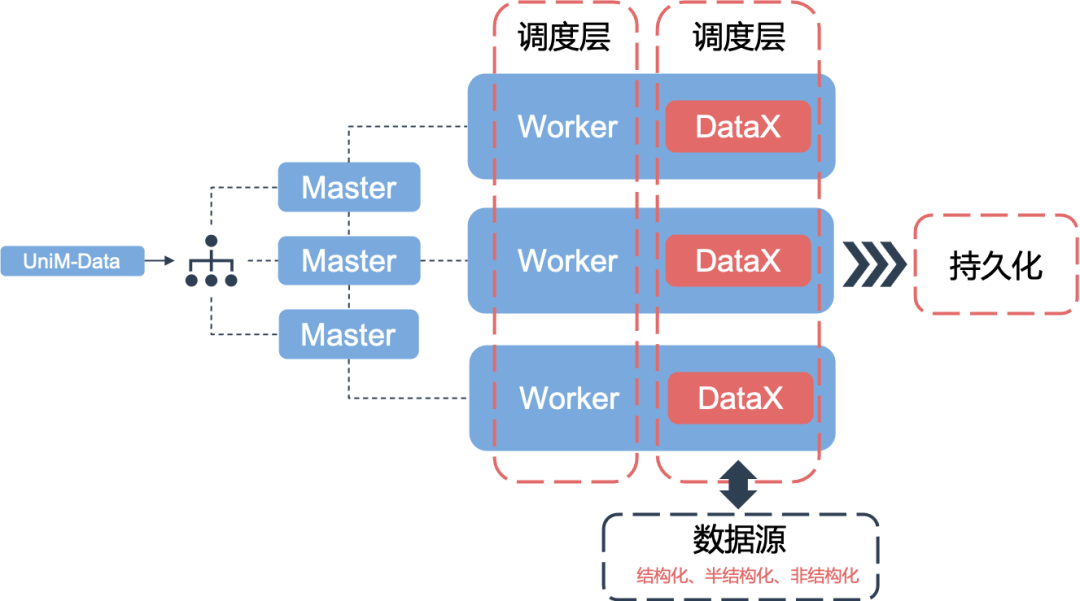
在项目落地过程中,我们在开源版本 DataX 上拓展 了诸如百度 Doris、人大金仓 kingbase、华为 openGauss 等国产数据库的适配。
数据治理工具
UniM-Data 上,提供了数据质控、数据探查、数据识别等自研治理工具,在 Apache Dolphin Scheduler 上进行较为综合性的拓展和应用。我们的设计思路是,实现独立的计算引擎,使用 Apache DolphinScheduler 的调度系统,提供数据治理能力。实现方式主要是在 org.apache.Dolphin
Scheduler.server.worker.task 的 package 上增加对应的任务生成逻辑,通过 Apache DolphinScheduler 的调度能力执行计算引擎。下面以数据质控为例进行说明。
整体的运行流程
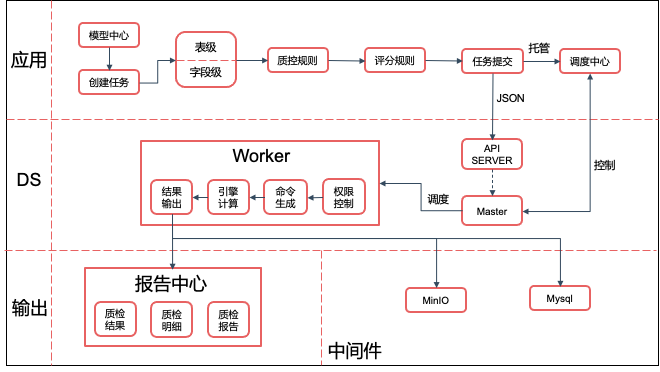
1)应用侧:
模型中心创建质控任务( UniM-Data 的数据表实体统一由模型中心标注和创建)
质控引擎提供表级和字段级质控类型,如记录数、及时性、范围、规则等质控算子
设置评分规则,根据质控结果形成等级划分
提交任务 Json 至 Apache DolphinScheduler 的 API Server ,并将任务控制权托管至调度中心
2) Apache DolphinScheduler 侧:
API Server 接收和保存质控任务
Master 进行任务调度,向调度中心暴露控制接口
Worker 完成对参数的解析和构造,通过权限控制后,生成质控引擎的执行命令,执行计算引擎
3) 输出侧:
报告中心承接质控结果的展示和报告输出
质检异常的抽样数据存放至 MinIO,以文件形式提供异常数据
引擎实现
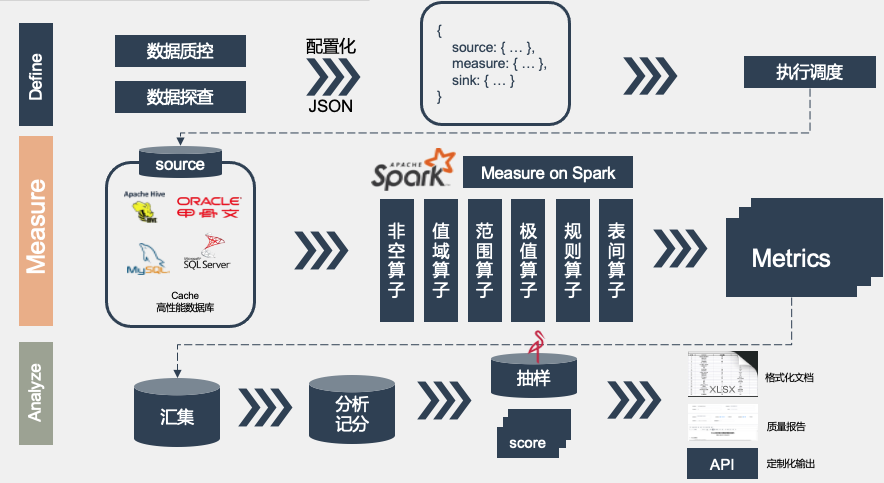
数据质控的架构图
按照整体的系统设计思想,引擎与 Apache DolphinScheduler 分别解耦,各司其职,可单独执行也可以与 Apache DolphinScheduler 配合使用。引擎抽象层设计有 source、measure、sink、sample和score(记分规则):
source:现支持hive、oracle、mysql、doris、kingbase、openguase、cache、sqlserver等数据源
measure:现建设有记录值、及时性、值域、极值、非空等10+种算子
sink:支持API、CSV
sample:支持MinIO、mysql的数据样本下发
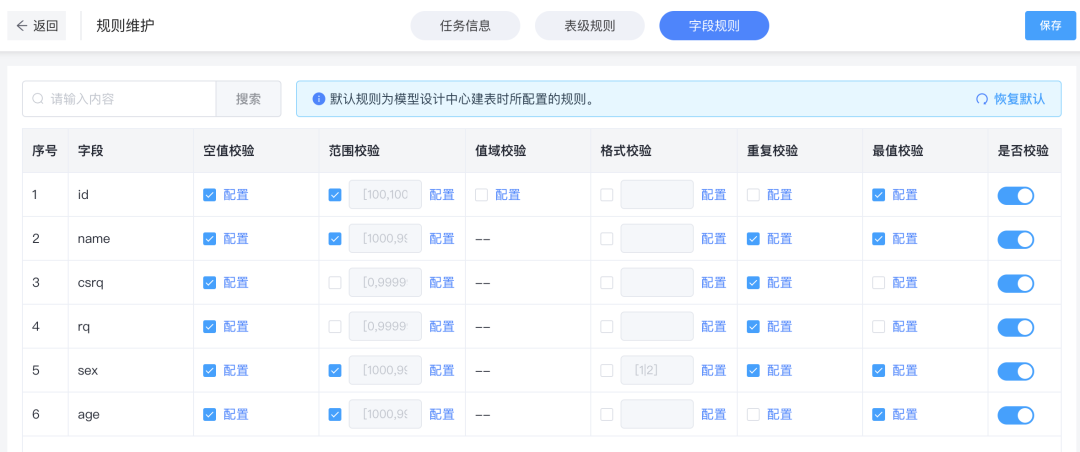
应用实现
数据质控在应用端采用配置化方式,降低使用成本,提供了可选表级与字段级质控范围,进行不同数据的定制化任务设定。
04 成果与总结
从2020年至今,UniM-Data 经过持续的运营与建设,在医疗、运营、科研、应急等业务线条上有多个项目落地。在项目实施落地阶段,UniM-Data 承接着日均超6000+任务实例,面临着数据流量达 TB 级别、系统7*24小时支持、准确率达99.9999%等挑战。Apache DolphinScheduler 作为 UniM-Data 的任务调度中心,基于其优秀的架构和丰富的功能,在实际生产中交出了令人欣喜的答卷,主要体现在:
基于 Apache DolphinScheduler 的调度能力,开发并提供数据采集、血缘、治理等多类执行器,支撑业务的快速演进
新增功能和业务性接口,在 Apache DolphinScheduler 的调度能力基础上,提供功能更加丰富的调度中心
基于 Apache DolphinScheduler 的补数和重跑机制,有效降低数仓团队的运维成本,提高数据准确率
去中心化结构,保证整体系统7*24小时稳定运行
提供多项目、多资源的隔离环境,可在较低成本下,提供统一门户、差异化功能和权限校验
05 下一步计划
UniM-Data 目前采用的是 Apache DolphinScheduler 的1.3.2版本,在社区快速发展下,为了进一步强化调度系统和融合优秀能力,我们计划将基线版本升级至社区3.0版本,期待 Apache DolphinScheduler 为大家带来更多能力。
日均 6000+ 实例,TB 级数据流量,Apache DolphinScheduler 如何做联通医疗大数据平台的“顶梁柱”?的更多相关文章
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- 大数据平台的技术演化之路 诸葛io平台设计实例
如今,数据分析能力正逐渐成为企业发展的标配,企业通过数据分析的过程将数据中的信息提取出来,进行处理.识别.加工.呈现,最后成为指导企业业务发展的知识和智慧.而处理.识别.加工.呈现的过程从本质上来讲, ...
- Apache Kylin在4399大数据平台的应用
来自:AI前线(微信号:ai-front),作者:林兴财,编辑:Natalie作者介绍:林兴财,毕业于厦门大学计算机科学与技术专业.有多年的嵌入式开发.系统运维经验,现就职于四三九九网络股份有限公司, ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- 【喜讯】Apache DolphinScheduler 荣获 “2020 年度十大开源新锐项目”
经 10000+ 开发者公开票选,20+专家评审. 10+ 主编团打分,历经数月打磨,11 月 19 日,由InfoQ 发起并组织的[2020中国技术力量年度榜单评选]结果正式揭晓. 2020 年度十 ...
- 腾讯大数据平台Oceanus: A one-stop platform for real time stream processing powered by Apache Flink
January 25, 2019Use Cases, Apache Flink The Big Data Team at Tencent In recent years, the increa ...
- GoldenGate实时投递数据到大数据平台(7)– Apache Hbase
Apache Hbase安装及运行 安装hbase1.4,确保在这之前hadoop是正常运行的.设置相应的环境变量, export HADOOP_HOME=/u01/hadoop export HBA ...
- GoldenGate实时投递数据到大数据平台(3)- Apache Flume
Apache Flume Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合,最后存储到一个中心化数据存储系统中,方便进行数据分析.事实上flume也可 ...
- 利用先电云iaas平台搭建apache官方大数据平台(ambari2.7+hdp3.0)
一.ambari架构解析 二.基础环境配置 以两台节点为例来组件Hadoop分布式集群,这里采用的系统版本为Centos7 1511,如下表所示: 主机名 内存 硬盘 IP地址 角色 master 8 ...
随机推荐
- Nexus5x 修改Android开机动画
1.制作帧动画 这里随便从网上找了一个gif图片,导入PS中,打开后会形成很多帧图层,选择导航栏中的文件->脚本->将图层导出到文件可以将所有图层导出来.要注意文件命名,Android会按 ...
- awk-文本处理【中文手册版】
01. 简介 AWK是一个文本(面向行和列)处理工具,同时它也是一门脚本语言. AWK其名称得自于它的创始人 Alfred Aho .Peter Weinberger 和 Brian Kernigha ...
- Fail2ban 简介
Fail2ban是一个基于日志的IP自动屏蔽工具.可以通过它来防止暴力破解攻击. Fail2ban通过扫描日志文件(例如/var/log/apache/error_log),并禁止恶意IP(太多的密码 ...
- CF1485E Move and Swap
题意:Move and Swap 很好的题呢 n个节点的树,根为1,所有叶子的深度都是D,一开始根节点上有两个颜色分别微R,B的球,你执行下列操作D-1次: 1.R点跳到子树内 2.B点跳到下一层的任 ...
- MOS管实现的STC自动下载电路
目录 MOSFET, MOS管基础和电路 MOS管实现的STC自动下载电路 三极管配合 PMOS 管控制电路开关 STC MCU在烧录时, 需要断电重置后才能进入烧录状态, 通常是用手按开关比较繁琐. ...
- 深入浅出Nginx实战与架构
本文主要内容如下(让读者朋友们深入浅出地理解Nginx,有代码有示例有图): 1.Nginx是什么? 2.Nginx具有哪些功能? 3.Nginx的应用场景有哪些? 4.Nginx的衍生生态有哪些? ...
- flask实现python方法转换服务
一.flask安装 pip install flask 二.flask简介: flask是一个web框架,可以通过提供的装饰器@server.route()将普通函数转换为服务 flask是一个web ...
- 意味着JNPF迈入新时代的3.4版本,与3.3.3版本有着哪些功能区别呢?
在线开发 3.3.3版本 同一个功能分功能设计和移动设计 功能设计没有更换模式 功能设计没有同步菜单 功能设计和移动设计无表模式 3.4.1版本 同一个功能可以在功能设计里面设计,根据客户需求自己选 ...
- Spring Security:用户和Spring应用之间的安全屏障
摘要:Spring Security是一个安全框架,作为Spring家族的一员. 本文分享自华为云社区<[云驻共创]深入浅出Spring Security>,作者:香菜聊游戏. 一.前言 ...
- SAP 时区转换
DATA:l_tzone TYPE tzonref-tzone. "TIME ZONE DATA:l_timesp TYPE tzonref-tstamps."TIME ...