迁移学习《Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks》
论文信息
论文标题:Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
论文作者:Dong-Hyun Lee
论文来源:2013——ICML
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
本文提出了一种简单有效的深度神经网络半监督学习方法。本文所提出的网络是在监督方式下同时使用标记和未标记数据进行训练。对于未标记数据,$\text{Pseudo-Label}$ 是选择具有最大预测概率的类,假设他们形如真实标签。
伪标签等同于熵正则化,它有利于类之间的低密度分离,这是半监督学习通常假设的先验。
2 方法
$\text{Pseudo-Label}$ 模型作为一个简单、有效的半监督学习方法早在 2013年就被提出,其核心思想包括两步:
- 第一步:运用训练好的模型给予无标签数据一个伪标签,可以用概率最高的类别作为无标签数据的伪标签;
- 第二步:运用 $\text{entropy regularization}$ 思想,将无监督数据转为目标函数(Loss)的正则项。实际中,就是将拥有伪标签的无标签数据视为有标签的数据,然后用交叉熵来评估误差大小;
目标函数:
$L=\frac{1}{n} \sum_{m=1}^{n} \sum_{i=1}^{C} L\left(y_{i}^{m}, f_{i}^{m}\right)+\alpha(t) \frac{1}{n^{\prime}} \sum_{m=1}^{n^{\prime}} \sum_{i=1}^{C} L\left(y_{i}^{\prime m}, f_{i}^{\prime m}\right)$
其中,左边第一项为交叉熵,用来评估有标签数据的误差。第二项即为 $\text{entropy regularization}$ 项,用来从无标签的数据中获取训练信号;
为了平衡有标签数据和无标签数据的信号强度,引入时变参数 $\alpha(t)$,随着训练时间的增加,$\alpha(t)$ 将会从零开始线性增长至某个饱和值。背后的核心想法也很直观,早期模型预测效果不佳,因此 $\text{entropy regularization}$ 产生信号的误差也较大,因而 $\alpha(t)$ 应该从零开始,由小逐渐增大;
其中,$\alpha_{f}=3$、$T_{1}=100$、$T_{2}=600$。
3 为什么伪标签有效
低密度分离
聚类假设指出决策边界应位于低密度区域以提高泛化性能。
熵正则化
该方案通过最小化未标记数据的类概率的条件熵来支持类之间的低密度分离,而无需对密度进行任何建模。
$H\left(y \mid x^{\prime}\right)=-\frac{1}{n^{\prime}} \sum_{m=1}^{n^{\prime}} \sum_{i=1}^{C} P\left(y_{i}^{m}=1 \mid x^{\prime m}\right) \log P\left(y_{i}^{m}=1 \mid x^{\prime m}\right)$
熵是类重叠的量度,随着类别重叠的减少,决策边界处的数据点密度会降低。
使用伪标签作为熵正则化进行训练
可视化结果:

在使用神经网络进行分类时, $y^{u}=f_{\theta^{*}}^{*}\left(x^{u}\right)$ , 其中 $y_{u}$ 是 one-hot 编码。现在我们并不限制其必须是某个类 别, 而是将其看做1个分布, 我们希望这个分布越集中越好("非黑即白"), 因为分布越集中时它的含义就是样本 $x^{u}$ 属于某类别的概率很大属于其它类别的概率很小。
我们可以使用 Entropy 评估分布 $ y^{\mu}$ 的集中程度 $ E\left(y^{\mu}\right)=-\sum_{m=1}^{5} y_{m}^{\mu} \ln \left(y_{m}^{\mu}\right)$ , 假设是5分类, 其值越小则表示分布 $ y^{\mu}$ 越集中。
如下图左侧所示, 上面两个的 $E$为 0 , 所以 $\mathrm{y}$ 的分布很集中; 最后一个 $\mathrm{E}=1 / 5 $, 比上面两个大, 我们 只管也可以看出, 他的分布不那么集中。
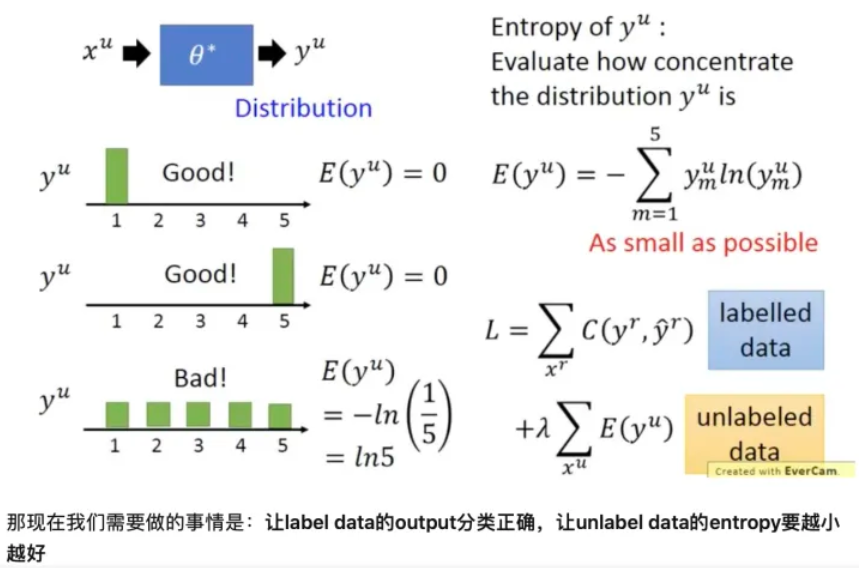
参考
迁移学习《Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks》的更多相关文章
- 迁移学习(IIMT)——《Improve Unsupervised Domain Adaptation with Mixup Training》
论文信息 论文标题:Improve Unsupervised Domain Adaptation with Mixup Training论文作者:Shen Yan, Huan Song, Nanxia ...
- 迁移学习(JDDA) 《Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation》
论文信息 论文标题:Joint domain alignment and discriminative feature learning for unsupervised deep domain ad ...
- 论文解读(CDCL)《Cross-domain Contrastive Learning for Unsupervised Domain Adaptation》
论文信息 论文标题:Cross-domain Contrastive Learning for Unsupervised Domain Adaptation论文作者:Rui Wang, Zuxuan ...
- 论文解读(CDTrans)《CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation》
论文信息 论文标题:CDTrans: Cross-domain Transformer for Unsupervised Domain Adaptation论文作者:Tongkun Xu, Weihu ...
- 虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup》
论文信息 论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversari ...
- 论文解读(CAN)《Contrastive Adaptation Network for Unsupervised Domain Adaptation》
论文信息 论文标题:Contrastive Adaptation Network for Unsupervised Domain Adaptation论文作者:Guoliang Kang, Lu Ji ...
- Unsupervised Domain Adaptation by Backpropagation
目录 概 主要内容 代码 Ganin Y. and Lempitsky V. Unsupervised Domain Adaptation by Backpropagation. ICML 2015. ...
- Deep Transfer Network: Unsupervised Domain Adaptation
转自:http://blog.csdn.net/mao_xiao_feng/article/details/54426101 一.Domain adaptation 在开始介绍之前,首先我们需要知道D ...
- Unsupervised Domain Adaptation Via Domain Adversarial Training For Speaker Recognition
年域适应挑战(DAC)数据集的实验表明,所提出的方法不仅有效解决了数据集不匹配问题,而且还优于上述无监督域自适应方法.
- 论文笔记:Unsupervised Domain Adaptation by Backpropagation
14年9月份挂出来的文章,基本思想就是用对抗训练的方法来学习domain invariant的特征表示.方法也很只管,在网络的某一层特征之后接一个判别网络,负责预测特征所属的domain,而后特征提取 ...
随机推荐
- 20200926--矩阵转置(奥赛一本通P95 8 多维数组)
输入一个n行m列的矩阵A,输出它的转置(看下面说明) 输入:第1行包含两个整数n和m(1<=n<=100,1<=m<=100),表示矩阵A的行数和列数.接下来n行,每行m个整数 ...
- 20200923--计算鞍点(奥赛一本通P91 4)
给定一个5*5的矩阵,每行只有一个最大值,每列只有一个最小值,寻找这个矩阵的鞍点.鞍点指的是矩阵中的一个元素,它是所在行的最大值,并且是所在列的最小值. 例如:在下面的例子中(第4行第1列的元素就是鞍 ...
- C 语言 scanf 格式化输入函数
C 语言 scanf 格式化输入函数 函数概要 scanf 函数从标准输入流中读取格式化字符串.与 printf 格式化输出函数相反,scanf 函数是格式化输入函数. 函数原型 #include & ...
- Spring系列之类路径扫描和注册组件-8
目录 类路径扫描和注册组件 `@Component` 使用元注释和组合注释 自动检测类和注册 Bean 定义 使用过滤器自定义扫描 在组件中定义 Bean 元数据 命名自动检测到的组件 为自动检测的组 ...
- springboot项目 报错No mapping for GET /css/bootstrap.css,前端无法展示样式
说来也奇怪,前几天刚写完的项目 写的好好的 现在打开他就加载不了前端的静态资源了 报错No mapping for GET /css/bootstrap.css 解决方法: 新建一个配置类 ,将静态资 ...
- sqlserver substring 函数截取text格式文本格式乱码导致的定位错误的问题
描述:使用 charindex 函数对 text 字段所要截取的内容下标读取例如:str(表字段名称-类型text)= <p>●123456</p> 截取 123 , inde ...
- C语言初级阶段5——函数1
C语言初级阶段5--函数1 函数的基本概念 1.函数:理解为封装功能的容器. 主函数是函数的入口 2.函数定义的基本格式: 返回值类型:常用的基本数据类型,执行完以后,函数会得到一个什么类型的值,如果 ...
- C++多线程编程之【线程管理】
1.如何启动线程? 构建std::thread对象即可. 直接传函数名(地址) 创建一个类并创建伪函数. 构建对象(实例化),将对象作为参数传入thread对象实例化. 2.为什么要等待线程? 首先必 ...
- 一些狗J8稳定性测试
1.CTS 2.NTS 3.高温老化 4.DDR 稳定度 5.一些HW 指标
- 西电oj73题字符串处理
问题描述 有一种简单的字符串压缩算法,对于字符串中连续出现的同一个英文字符,用该字符加上连续出现的次数来表示(连续出现次数小于3时不压缩).例如,字符串aaaaabbbabaaaaaaaaaaaaab ...