超级重磅!Apache Hudi多模索引对查询优化高达30倍

与许多其他事务数据系统一样,索引一直是 Apache Hudi 不可或缺的一部分,并且与普通表格式抽象不同。 在这篇博客中,我们讨论了我们如何重新构想索引并在 Apache Hudi 0.11.0 版本中构建新的多模式索引,这是用于 Lakehouse 架构的首创高性能索引子系统,以优化查询和写入事务,尤其是对于大宽表而言。
1. 为什么在 Hudi 中使用多模态索引
索引被广泛应用于数据库系统中,例如关系数据库和数据仓库,以降低 I/O 成本并提高查询效率。类似于书末的索引页如何帮助您快速定位信息,数据库索引包含辅助数据结构,可以快速定位所需的记录,而无需从存储中读取不必要的数据。鉴于 Hudi 的设计已经针对处理可变更改流进行了高度优化,具有不同的写入模式,Hudi 从一开始就独特地支持索引能力以加快 Lakehouse 的 upserts。
事实上,文献中存在数十种索引技术,并且大多数流行的数据库系统,例如 RDBMS、PostgreSQL、MySQL、Spanner、CockroachDB 等,都提供了一个强大的工具箱来支持其中的许多技术。虽然 Hudi 的索引现在已经被行业证明可以快速更新插入,但这些优势还没有被用于查询。鉴于数据湖的数据规模是传统数据库/仓库的 10-100 倍,通用索引子系统可以为湖带来改变游戏规则的性能提升。在 Hudi 0.11.0 版本中,我们重新构想了用于数据湖的通用多模索引应该是什么样子。 Hudi 的多模态索引是通过增强元数据表来实现的,可以灵活地扩展到新的索引类型,以及异步索引构建机制。
该博客涉及核心设计原则以及多模式索引如何服务于所有现有的索引机制,而随后的其他博客则更详细地介绍了其余方面。
2. 设计以及实现
多模态索引需要满足以下要求:
- 可扩展的元数据:表元数据,即有关表的辅助数据,必须可扩展至非常大的大小,例如,Terabytes (TB)。 应该轻松集成不同类型的索引以支持各种用例,而不必担心管理相同的用例。
- ACID 事务更新:索引和表元数据必须始终保持最新并与数据表同步,并且部分写入数据不应该对下游暴露。
- 快速查找:大海捞针类型的查找必须快速高效,无需扫描整个索引,因为大型数据集的索引大小可能是 TB。
基于这些需求,我们设计并实现了多模态索引,实现了Hudi的通用索引子系统。
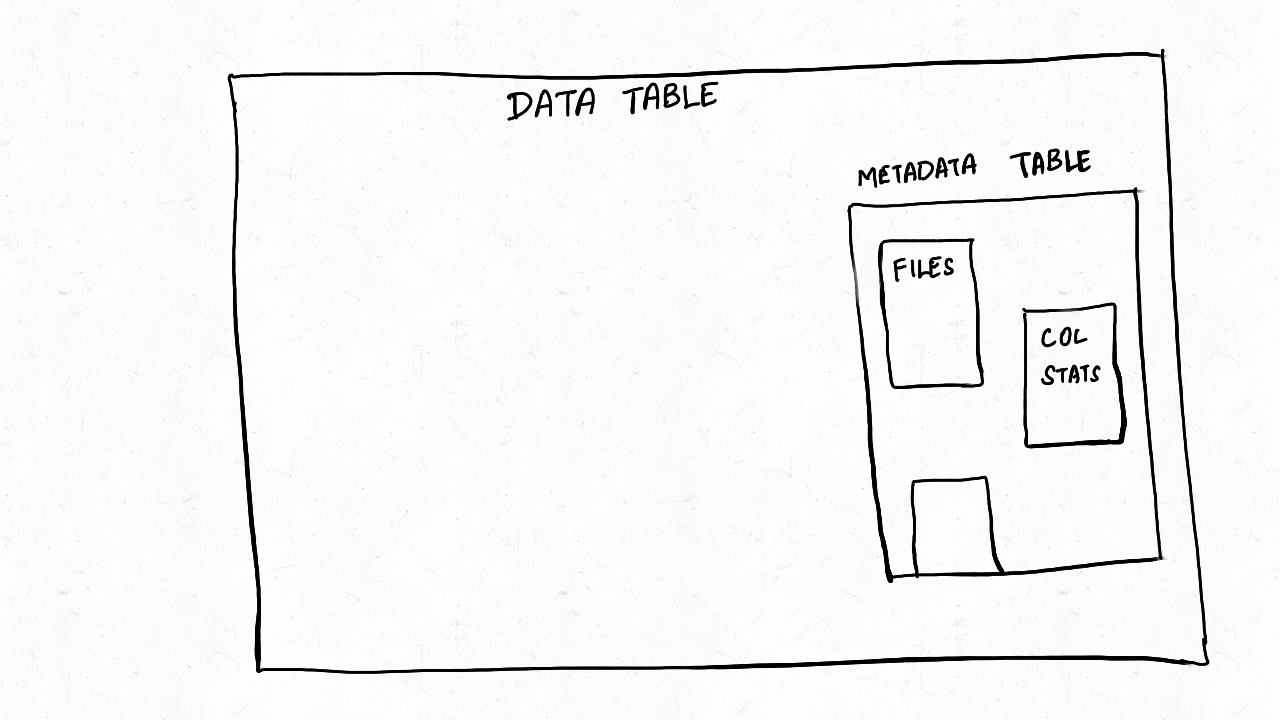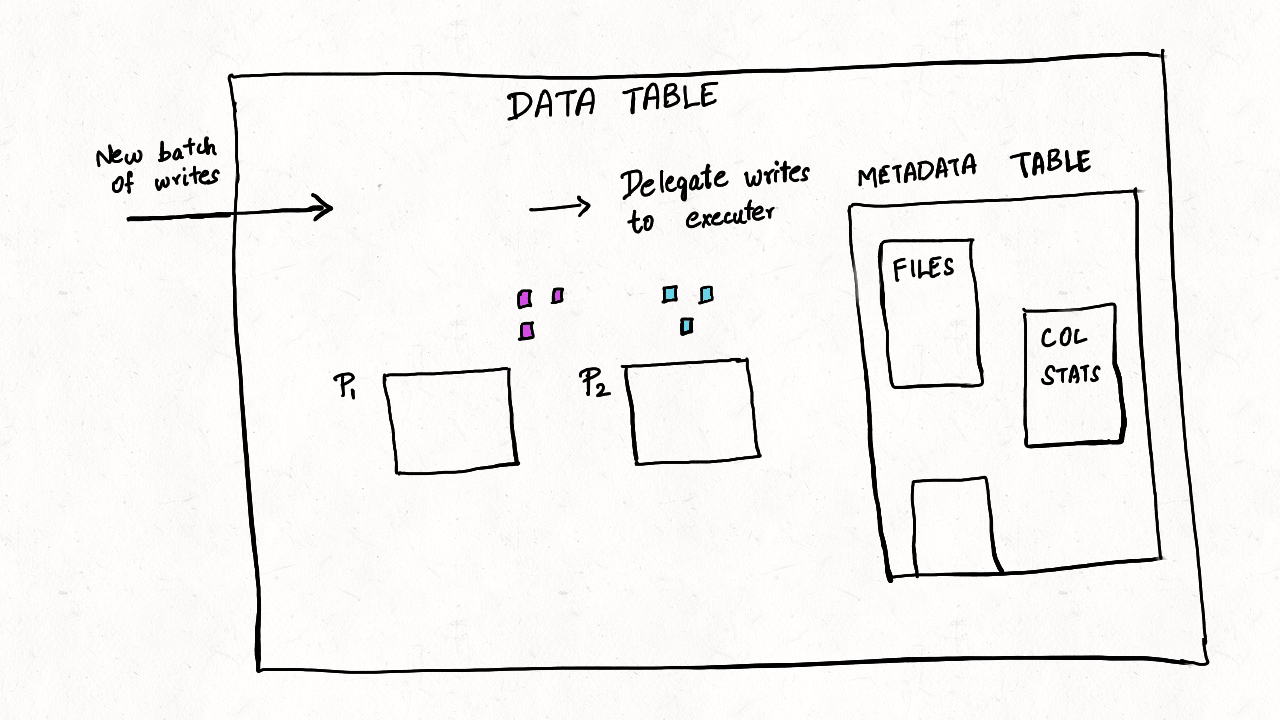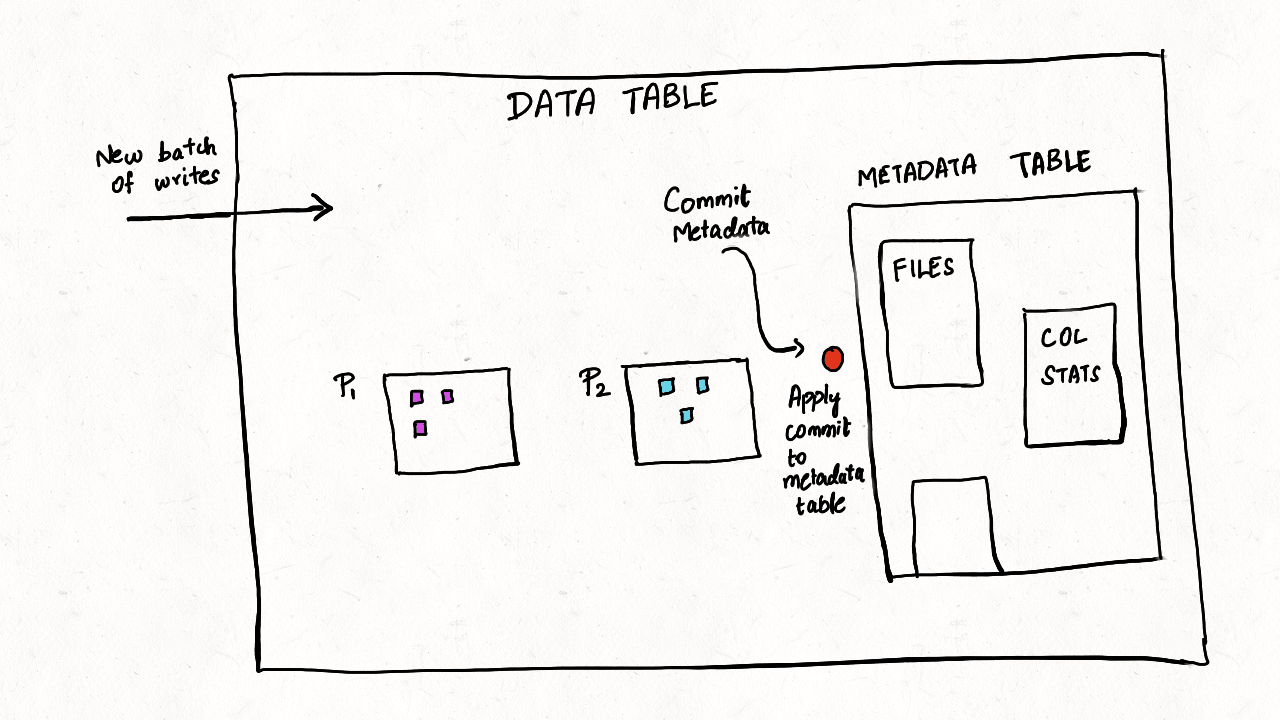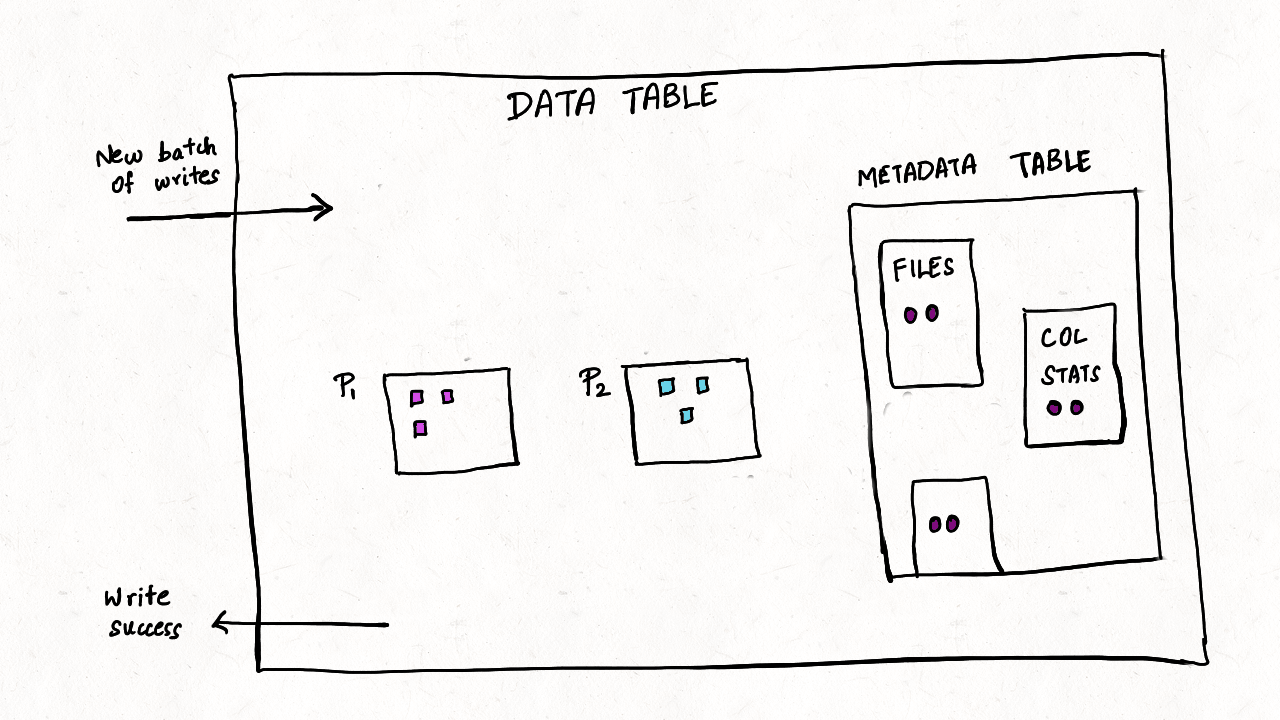
2.1 可扩展的元数据
所有包含表元数据的索引都存储在一个 Hudi Merge-On-Read (MOR) 类型的表,即元数据表。 这是一种常见的做法,其中数据库将元数据存储为内部视图,将 Apache Kafka 存储为内部主题。 元数据表是无服务器的,独立于计算和查询引擎。 MOR 表布局通过避免数据同步合并和减少写入放大来提供极快的写入速度。 这对于大型数据集非常重要,因为元数据表的更新大小可能会增长到无法管理。 这有助于 Hudi 将元数据扩展到 TB 大小,就像 BigQuery 等其他数据系统一样。
我们已经有了文件、column_stats 和bloom_filter 索引来提高多个方面的性能,如本博客后面所述。 基础框架的构建可扩展和可扩展至任何新索引,如位图、基于 R-tree 的索引、记录级索引等等。 任何此类索引都可以根据需要启用和禁用,而无需与其他索引协调。 此外,Hudi 很自豪能够提供异步索引,这是同类中的第一个,支持与常规写入器一起构建索引,而不会影响写入延迟(即将发布的博客详细讨论异步索引)。
2.2 ACID事务更新
元数据表保证 ACID 事务更新。 对数据表的所有更改都将转换为提交到元数据表的元数据记录,我们将其设计为多表事务,这样每次对 Hudi 表的写入只有在数据表和元数据表都提交时才能成功。多表事务确保原子性并且对故障具有弹性,因此对数据或元数据表的部分写入永远不会暴露给其他读取或写入事务。 元数据表是为自我管理而构建的,因此用户不需要在任何表服务上花费操作周期,包括压缩和清理。 未来我们计划通过日志压缩服务来增加 MOR 表的更新,这可以进一步减少写入放大。
2.3 快速查找
为了提高读写性能,处理层需要点查找以从元数据表中的文件中找到必要的条目。 由于 Parquet 是列式的,而 Avro 是基于行的,因此它们不适合点查找。 另一方面,来自 HBase 的 HFile 格式专为高效的点查找而设计。
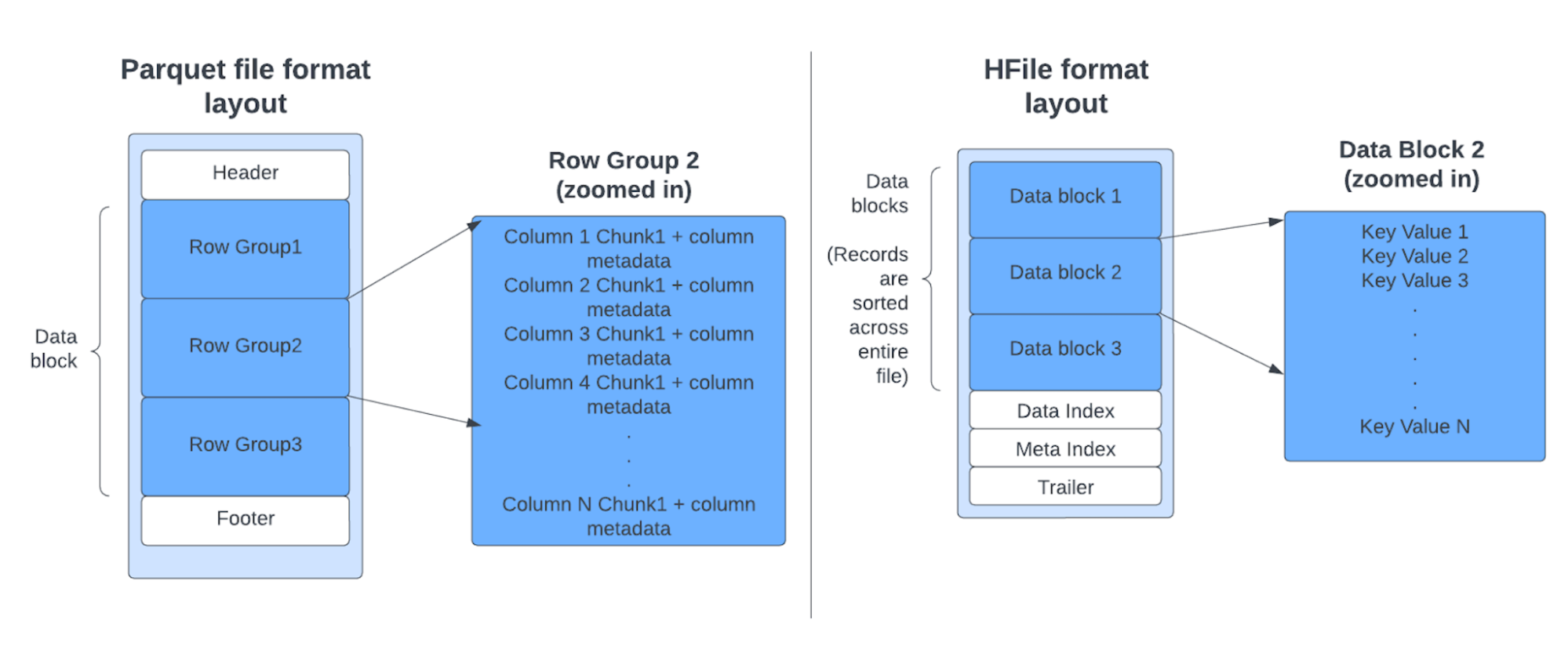
我们进行了实验,以测量在一个文件中针对不同文件格式的 1000 万 (10M) 个条目中的 N 个条目的点查找延迟。 与 Parquet 或 Avro 相比,HFile 显示了 10 到 100 倍的改进,Parquet 或 Avro 仍用于其他格式,如 Delta 和 Iceberg 用于表元数据。
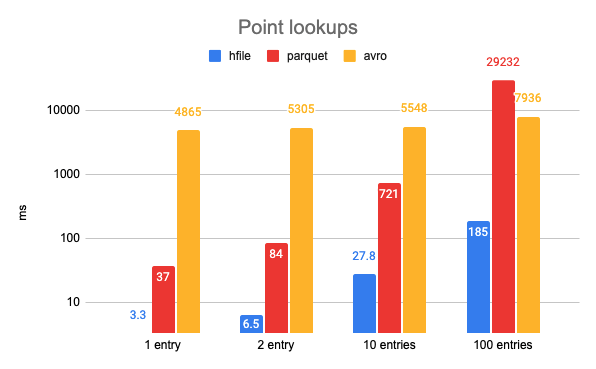
由于对元数据表的大多数访问都是点和范围查找,因此选择 HFile 格式作为内部元数据表的基本文件格式。 由于元数据表在分区级别(文件索引)或文件级别(column_stats 索引)存储辅助数据,因此基于单个分区路径和文件组的查找对于 HFile 格式将非常有效。 Hudi 元数据表中的基本文件和日志文件都使用 HFile 格式。 每个日志文件可以包含多个日志块。 如下图所示,Hudi 采用了一种新颖的思路,即利用 Inline File System 将实际数据块的内容读取为 HFile,从而利用 HFile 格式更快的查找。 这种设计经过精心挑选,以减少云存储方案中的远程 GET 调用,因为点查找可能不需要下载整个文件。
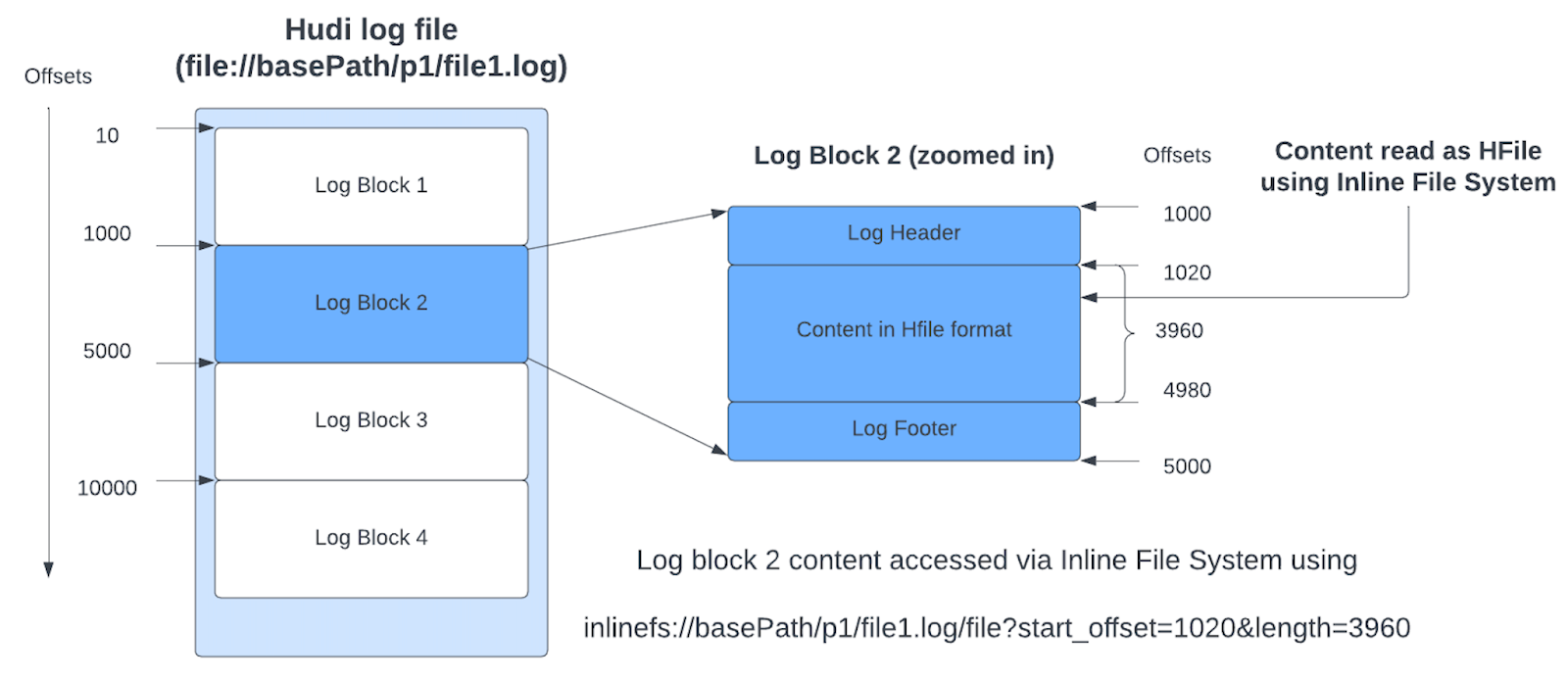
此外,这些元数据表索引通过缓存元数据的集中时间线服务器提供服务,进一步减少了执行程序查找的延迟。
3. 多模索引如何提升性能?
元数据表对于提高 Hudi 用户的性能有几个好处。 让我们看看 Hudi 的文件列表如何提高 10 倍,数据跳过如何通过多模式索引将读取延迟降低 10 倍至 30 倍或更多。
3.1 文件Listing
云存储中分析管道的大型部署通常在 1000 多个分区中包含 100k 或更多文件。 由于节流和高 I/O 操作,如此大规模的直接进行文件Listing通常是瓶颈,从而导致可伸缩性问题。 为了提高文件Listing性能,Hudi 将信息存储在元数据表中名为 files 的分区中,以避免文件系统调用,例如 exists、listStatus 和 listFiles。 文件分区存储数据表中每个分区的文件名、大小和活动状态等文件信息。

我们展示了在 Amazon S3 上使用包含不同数量的文件和分区的各种规模的 Hudi 表对文件列表的性能改进。 通过使用元数据表中的文件索引,与在 S3 上直接列出相比,文件列出延迟大大降低,提供 2-10 倍的加速(包括 1M 文件的非分区表,图中未显示)。 由于像 S3 这样的云存储对非常大的数据集上的文件系统调用进行速率限制和节流,因此直接文件列表不能随着分区中文件数量的增加而很好地扩展,并且在某些情况下,文件系统调用可能无法完成。 相比之下,文件索引有助于消除此类瓶颈并提供对文件Listing的快速访问。 更好的是,通过重用元数据表读取器并在时间线服务器缓存索引,文件列表延迟进一步降低。
3.2 Data Skipping
元数据表的另一个主要好处是在服务读取查询时帮助跳过数据。 column_stats 分区存储所有数据文件的感兴趣列的统计信息,例如最小值和最大值、总值、空计数、大小等。 在使用匹配感兴趣列的谓词提供读取查询时使用统计信息。 这可以大大提高查询性能,因为不匹配的文件会被过滤掉,而不会从文件系统中读取,还可以减少文件系统的 I/O 负担。 此外,如果用户配置了集群、Z 顺序或任何其他布局优化,这些可以将查询延迟减少一个数量级,因为文件根据常见查询列的访问模式很好地布局。
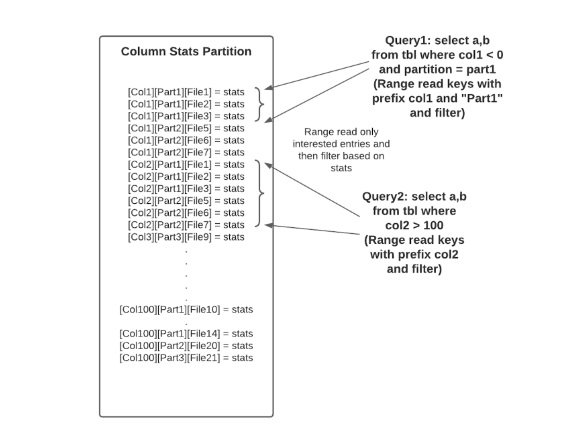
在column_stats分区中,记录键是由列名、分区名、数据文件名依次串联而成的,这样我们就可以进行点查找和范围读取。 这种记录键设计也解锁了在 column_stats 索引上执行前缀查找的能力。 例如,如上所示,Query1 指定了 col1 和分区,Query2 在谓词中指定了 col2。 谓词用于构造对 column_stats 索引的前缀查找,而无需提供完整的记录键。 这大大减少了对具有 100 甚至 1000 列的大型数据集的索引查找,因为要查找的索引条目的数量大约为 O(num_query_columns),通常很小(例如,5 到 10),而不是 O (num_table_columns) 可能很大(例如,超过 100 或 1000)。
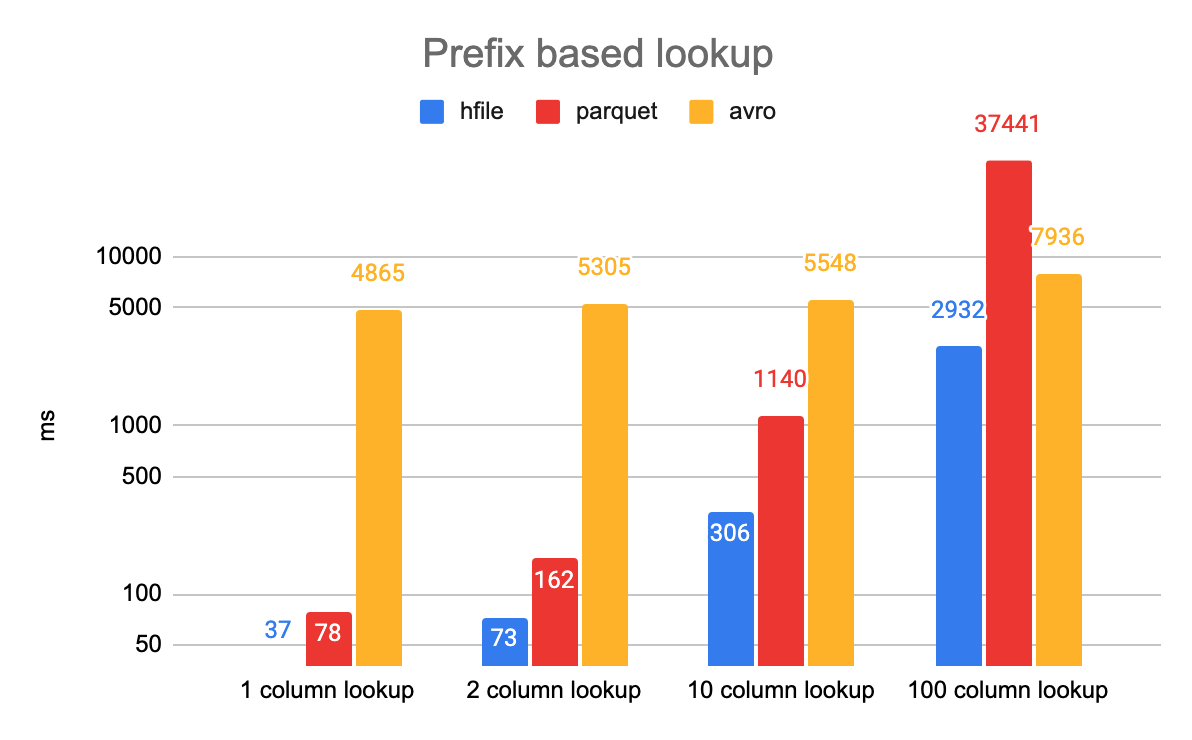
我们对一个包含 10M 条目的文件进行了基于前缀查找的实验。 每个列查找预计将匹配 10k 个条目。 在所有情况下,与次优(即 Parquet)相比,HFile 能够显示出至少 3 倍的延迟。 这也极大地提高了云存储的性能,因为这大大减少了远程 GET 调用的数量。 通过这样的设计,与没有数据跳过相比,数据跳过带来了 10 到 30 倍的查询延迟增益。 期待更多关于 Hudi 数据跳过的后续博客的详细信息。
3.3 upsert性能
Hudi 中使用最广泛的索引之一是基于布隆过滤器的索引。该索引对记录键的最小值和最大值采用基于范围的修剪,并使用基于布隆过滤器的查找来标记传入记录。对于大型表,这涉及读取所有匹配数据文件的页脚以进行布隆过滤器,这在整个数据集随机更新的情况下可能会很昂贵。引入元数据表中的bloom_filter分区来存储所有数据文件的bloom过滤器,避免扫描所有数据文件的页脚。该分区中的记录键由分区名和数据文件名组成。与 column_stats 索引类似,它利用点和前缀查找。根据我们对包含 100k 个文件的 Hudi 表的分析,与从单个数据文件页脚读取相比,从元数据表中的 bloom_filter 分区读取布隆过滤器的速度要快 3 倍。
3.4 未来的工作
如上所述,我们希望进一步丰富 Hudi 的元数据。我们正在添加一个新的记录级索引,领先于可扩展元数据的 Lakehouse 技术,它将记录键映射到存储它们的实际数据文件。对于像 1000 亿多条记录这样的超大规模数据集,现有索引可能无法满足某些类型工作负载的 SLA。借助我们的多模式索引框架和更快的查找,我们应该能够比现有索引更快地定位记录。这对于索引查找本身可以定义整个写入延迟的大型部署非常强大。我们还希望为辅助列、位图索引等添加布隆过滤器。我们欢迎来自社区的更多想法和贡献,为我们的多模式索引潮流添加更多索引。
4. 结论
Hudi 为 Lakehouse 架构带来了一种新颖的多模式索引,一个无服务器和高性能的索引子系统,用于存储各种类型的辅助数据,以提高读写性能。旨在以多种方式进行可扩展、自我管理,并支持高效、轻松地向 Hudi 添加更丰富的索引。 我们计划在即将发布的版本中使用新索引来增强多模式索引。
超级重磅!Apache Hudi多模索引对查询优化高达30倍的更多相关文章
- 深入理解Apache Hudi异步索引机制
在我们之前的文章中,我们讨论了多模式索引的设计,这是一种用于Lakehouse架构的无服务器和高性能索引子系统,以提高查询和写入性能.在这篇博客中,我们讨论了构建如此强大的索引所需的机制,异步索引机制 ...
- 数据湖框架选型很纠结?一文了解Apache Hudi核心优势
英文原文:https://hudi.apache.org/blog/hudi-indexing-mechanisms/ Apache Hudi使用索引来定位更删操作所在的文件组.对于Copy-On-W ...
- Apache Hudi重磅特性解读之全局索引
1. 摘要 Hudi表允许多种类型操作,包括非常常用的upsert,当然为支持upsert,Hudi依赖索引机制来定位记录在哪些文件中. 当前,Hudi支持分区和非分区的数据集.分区数据集是将一组文件 ...
- Apache Hudi 0.8.0版本重磅发布
1. 重点特性 1.1 Flink集成 自从Hudi 0.7.0版本支持Flink写入后,Hudi社区又进一步完善了Flink和Hudi的集成.包括重新设计性能更好.扩展性更好.基于Flink状态索引 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Apache Hudi 0.5.1版本重磅发布
历经大约3个月时间,Apache Hudi 社区终于发布了0.5.1版本,这是Apache Hudi发布的第二个Apache版本,该版本中一些关键点如下 版本升级 将Spark版本从2.1.0升级到2 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- Apache Hudi 0.6.0版本重磅发布
1. 下载信息 源码:Apache Hudi 0.6.0 Source Release (asc, sha512) 二进制Jar包:nexus 2. 迁移指南 如果您从0.5.3以前的版本迁移至0.6 ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
随机推荐
- 解决github上不去
github上不去 在hosts文件中加入下列IP,保存即可生效. !!!!!注意!!!!! 网站对应的IP需要去[https://www.ipaddress.com/]网站查询, 可能与下面给出的不 ...
- python函数基础算法简介
一.多层语法糖本质 """ 语法糖会将紧挨着的被装饰对象名字当参数自动传入装饰器函数中""" def outter(func_name): ...
- springboot打包时候忽略编译测试类
方法1.可以在依赖中加入插件 <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId ...
- eBPF Cilium实战(2) - 底层网络可观测性
在之前的平台中,对于组件之间的网络流向不具备直接的可观测性,用户组件间通信出现问题,只能通过传统命令行工具进行手动排查,而 cilium 的 Hubble 服务可以提供 UI 界面向用户展示实时的流量 ...
- go sync.map源码解析
go中的map是并发不安全的,同时多个协程读取不会出现问题,但是多个协程 同时读写就会出现 fatal error:concurrent map read and map write的错误.通用的解决 ...
- Kotlin 之 let、with、run、apply、also 函数的使用
一.内联拓展函数 let let 扩展函数的实际上是一个作用域函数,当你需要去定义一个变量在一个特定的作用域范围内,let函数的是一个不错的选择:let函数另一个作用就是可以避免写一些判断null的操 ...
- 关于物理机没有VMnet1和VMnet8网卡的问题
当我们在用虚拟机做实验需要与物理机进行连接时,发现无法连接上,这时候可能是没有Vmnet1或者Vmnet8网卡,又或者是Vmnet1和Vmnet8网卡都没有. 之前试过很多方法,重装.重启虚拟网络编辑 ...
- Jquery_效果-隐藏显示、淡入淡出、滑动面板、简单的动画队列
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- 彻底解决Failed to execute goal on project xxxxx
1.错误内容:Could not resolve dependencies for project 今天在使用mvn clean package命令对一个子项目打包的时候出现如下错误(但是使用mave ...
- C/C++游戏项目:中国程序员一定要会的中国象棋教程
中国象棋是中国一种流传十分广泛的游戏. 下棋双方根据自己对棋局形式的理解和对棋艺规律的掌握,调动车马,组织兵力,协调作战在棋盘这块特定的战场上进行着象征性的军事战斗. 象棋,亦作"象碁&qu ...