Redis 中的原子操作(3)-使用Redis实现分布式锁
Redis 中的分布式锁如何使用
分布式锁的使用场景
为了保证我们线上服务的并发性和安全性,目前我们的服务一般抛弃了单体应用,采用的都是扩展性很强的分布式架构。
对于可变共享资源的访问,同一时刻,只能由一个线程或者进程去访问操作。这时候我们就需要做个标识,如果当前有线程或者进程在操作共享变量,我们就做个标记,标识当前资源正在被操作中, 其它的线程或者进程,就不能进行操作了。当前操作完成之后,删除标记,这样其他的线程或者进程,就能来申请共享变量的操作。通过上面的标记来保证同一时刻共享变量只能由一个线程或者进行持有。
对于单体应用:多个线程之间访问可变共享变量,比较容易处理,可简单使用内存来存储标示即可;
分布式应用:这种场景下比较麻烦,因为多个应用,部署的地址可能在不同的机房,一个在北京一个在上海。不能简单的存储标示在内存中了,这时候需要使用公共内存来记录该标示,栗如 Redis,MySQL 。。。
使用 Redis 来实现分布式锁
这里来聊聊如何使用 Redis 实现分布式锁
Redis 中分布式锁一般会用 set key value px milliseconds nx 或者 SETNX+Lua来实现。
因为 SETNX 命令,需要配合 EXPIRE 设置过期时间,Redis 中单命令的执行是原子性的,组合命令就需要使用 Lua 才能保证原子性了。
看下如何实现
使用 set key value px milliseconds nx 实现
因为这个命令同时能够设置键值和过期时间,同时Redis中的单命令都是原子性的,所以加锁的时候使用这个命令即可
func (r *Redis) TryLock(ctx context.Context, key, value string, expire time.Duration) (isGetLock bool, err error) {// 使用 set nxres, err := r.Do(ctx, "set", key, value, "px", expire.Milliseconds(), "nx").Result()if err != nil {return false, err}if res == "OK" {return true, nil}return false, nil}
SETNX+Lua 实现
如果使用 SETNX 命令,这个命令不能设置过期时间,需要配合 EXPIRE 命令来使用。
因为是用到了两个命令,这时候两个命令的组合使用是不能保障原子性的,在一些并发比较大的时候,需要配合使用 Lua 脚本来保证命令的原子性。
func tryLockScript() string {script := `local key = KEYS[1]local value = ARGV[1]local expireTime = ARGV[2]local isSuccess = redis.call('SETNX', key, value)if isSuccess == 1 thenredis.call('EXPIRE', key, expireTime)return "OK"endreturn "unLock" `return script}func (r *Redis) TryLock(ctx context.Context, key, value string, expire time.Duration) (isGetLock bool, err error) {// 使用 Lua + SETNXres, err := r.Eval(ctx, tryLockScript(), []string{key}, value, expire.Seconds()).Result()if err != nil {return false, err}if res == "OK" {return true, nil}return false, nil}
除了上面加锁两个命令的区别之外,在解锁的时候需要注意下不能误删除别的线程持有的锁
为什么会出现这种情况呢,这里来分析下
举个栗子
1、线程1获取了锁,锁的过期时间为1s;
2、线程1完成了业务操作,用时1.5s ,这时候线程1的锁已经被过期时间自动释放了,这把锁已经被别的线程获取了;
3、但是线程1不知道,接着去释放锁,这时候就会将别的线程的锁,错误的释放掉。
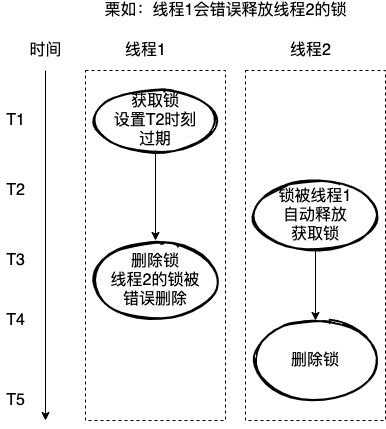
面对这种情况,其实也很好处理
1、设置 value 具有唯一性;
2、每次删除锁的时候,先去判断下 value 的值是否能对的上,不相同就表示,锁已经被别的线程获取了;
看下代码实现
var UnLockErr = errors.New("未解锁成功")func unLockScript() string {script := `local value = ARGV[1]local key = KEYS[1]local keyValue = redis.call('GET', key)if tostring(keyValue) == tostring(value) thenreturn redis.call('DEL', key)elsereturn 0end`return script}func (r *Redis) Unlock(ctx context.Context, key, value string) (bool, error) {res, err := r.Eval(ctx, unLockScript(), []string{key}, value).Result()if err != nil {return false, err}return res.(int64) != 0, nil}
代码可参考lock
上面的这类锁的最大缺点就是只作用在一个节点上,即使 Redis 通过 sentinel 保证高可用,如果这个 master 节点由于某些原因放生了主从切换,那么就会出现锁丢失的情况:
1、在 Redis 的 master 节点上拿到了锁;
2、但是这个加锁的 key 还没有同步到 slave 节点;
3、master 故障,发生了故障转移,slave 节点升级为 master 节点;
4、导致锁丢失。
针对这种情况如何处理呢,下面来聊聊 Redlock 算法
使用 Redlock 实现分布式锁
在 Redis 的分布式环境中,我们假设有 N 个 Redis master。这些节点完全互相独立,不存在主从复制或者其他集群协调机制。我们确保将在 N 个实例上使用与在 Redis 单实例下相同方法获取和释放锁。现在我们假设有 5 个 Redis master 节点,同时我们需要在5台服务器上面运行这些 Redis 实例,这样保证他们不会同时都宕掉。
为了取到锁,客户端营该执行以下操作:
1、获取当前Unix时间,以毫秒为单位。
2、依次尝试从5个实例,使用相同的key和具有唯一性的 value(例如UUID)获取锁。当向 Redis 请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在 5-50 毫秒之间。这样可以避免服务器端 Redis 已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试去另外一个 Redis 实例请求获取锁;
3、客户端使用当前时间减去开始获取锁时间(步骤1记录的时间)就得到获取锁使用的时间。当且仅当从大多数(N/2+1,这里是3个节点)的 Redis 节点都取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功;
4、如果取到了锁,key 的真正有效时间等于有效时间减去获取锁所使用的时间(步骤3计算的结果);
5、如果因为某些原因,获取锁失败(没有在至少N/2+1个 Redis 实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁(即便某些 Redis 实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而导致接下来的一段时间不能被重新获取锁)。
根据官方的推荐,go 版本中 Redsync 实现了这一算法,这里看下具体的实现过程
// LockContext locks m. In case it returns an error on failure, you may retry to acquire the lock by calling this method again.func (m *Mutex) LockContext(ctx context.Context) error {if ctx == nil {ctx = context.Background()}value, err := m.genValueFunc()if err != nil {return err}for i := 0; i < m.tries; i++ {if i != 0 {select {case <-ctx.Done():// Exit early if the context is done.return ErrFailedcase <-time.After(m.delayFunc(i)):// Fall-through when the delay timer completes.}}start := time.Now()// 尝试在所有的节点中加锁n, err := func() (int, error) {ctx, cancel := context.WithTimeout(ctx, time.Duration(int64(float64(m.expiry)*m.timeoutFactor)))defer cancel()return m.actOnPoolsAsync(func(pool redis.Pool) (bool, error) {// acquire 加锁函数return m.acquire(ctx, pool, value)})}()if n == 0 && err != nil {return err}// 如果加锁节点书没有达到的设定的数目// 或者键值的过期时间已经到了// 在所有的节点中解锁now := time.Now()until := now.Add(m.expiry - now.Sub(start) - time.Duration(int64(float64(m.expiry)*m.driftFactor)))if n >= m.quorum && now.Before(until) {m.value = valuem.until = untilreturn nil}_, err = func() (int, error) {ctx, cancel := context.WithTimeout(ctx, time.Duration(int64(float64(m.expiry)*m.timeoutFactor)))defer cancel()return m.actOnPoolsAsync(func(pool redis.Pool) (bool, error) {// 解锁函数return m.release(ctx, pool, value)})}()if i == m.tries-1 && err != nil {return err}}return ErrFailed}// 遍历所有的节点,并且在每个节点中执行传入的函数func (m *Mutex) actOnPoolsAsync(actFn func(redis.Pool) (bool, error)) (int, error) {type result struct {Status boolErr error}ch := make(chan result)// 执行传入的函数for _, pool := range m.pools {go func(pool redis.Pool) {r := result{}r.Status, r.Err = actFn(pool)ch <- r}(pool)}n := 0var err error// 计算执行成功的节点数目for range m.pools {r := <-chif r.Status {n++} else if r.Err != nil {err = multierror.Append(err, r.Err)}}return n, err}// 手动解锁的lua脚本var deleteScript = redis.NewScript(1, `if redis.call("GET", KEYS[1]) == ARGV[1] thenreturn redis.call("DEL", KEYS[1])elsereturn 0end`)// 手动解锁func (m *Mutex) release(ctx context.Context, pool redis.Pool, value string) (bool, error) {conn, err := pool.Get(ctx)if err != nil {return false, err}defer conn.Close()status, err := conn.Eval(deleteScript, m.name, value)if err != nil {return false, err}return status != int64(0), nil}
分析下思路
1、遍历所有的节点,然后尝试在所有的节点中执行加锁的操作;
2、收集加锁成功的节点数,如果没有达到指定的数目,释放刚刚添加的锁;
关于 Redlock 的缺点可参见
锁的续租
Redis 中分布式锁还有一个问题就是锁的续租问题,当锁的过期时间到了,但是业务的执行时间还没有完成,这时候就需要对锁进行续租了
续租的流程
1、当客户端加锁成功后,可以启动一个定时的任务,每隔一段时间,检查业务是否完成,未完成,增加 key 的过期时间;
2、这里判断业务是否完成的依据是:
1、这个 key 是否存在,如果 key 不存在了,就表示业务已经执行完成了,也就不需要进行续租操作了;
2、同时需要校验下 value 值,如果 value 对应的值和之前写入的值不同了,说明当前锁已经被别的线程获取了;
看下 redsync 中续租的实现
// Extend resets the mutex's expiry and returns the status of expiry extension.func (m *Mutex) Extend() (bool, error) {return m.ExtendContext(nil)}// ExtendContext resets the mutex's expiry and returns the status of expiry extension.func (m *Mutex) ExtendContext(ctx context.Context) (bool, error) {start := time.Now()// 尝试在所有的节点中加锁n, err := m.actOnPoolsAsync(func(pool redis.Pool) (bool, error) {return m.touch(ctx, pool, m.value, int(m.expiry/time.Millisecond))})if n < m.quorum {return false, err}// 判断下锁的过期时间now := time.Now()until := now.Add(m.expiry - now.Sub(start) - time.Duration(int64(float64(m.expiry)*m.driftFactor)))if now.Before(until) {m.until = untilreturn true, nil}return false, ErrExtendFailed}var touchScript = redis.NewScript(1, `// 需要先比较下当前的value值if redis.call("GET", KEYS[1]) == ARGV[1] thenreturn redis.call("PEXPIRE", KEYS[1], ARGV[2])elsereturn 0end`)func (m *Mutex) touch(ctx context.Context, pool redis.Pool, value string, expiry int) (bool, error) {conn, err := pool.Get(ctx)if err != nil {return false, err}defer conn.Close()status, err := conn.Eval(touchScript, m.name, value, expiry)if err != nil {return false, err}return status != int64(0), nil}
1、锁的续租需要客户端去监听和操作,启动一个定时器,固定时间来调用续租函数给锁续租;
2、每次续租操作的时候需要匹配下当前的 value 值,因为锁可能已经被当前的线程释放了,当前的持有者可能是别的线程;
看看 SETEX 的源码
SETEX 能保证只有在 key 不存在时设置 key 的值,那么这里来看看,源码中是如何实现的呢
// https://github.com/redis/redis/blob/7.0/src/t_string.c#L78// setGenericCommand()函数是以下命令: SET, SETEX, PSETEX, SETNX.的最底层实现void setGenericCommand(client *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) {...found = (lookupKeyWrite(c->db,key) != NULL);// 这里是 SETEX 实现的重点// 如果nx,并且在数据库中找到了这个值就返回// 如果是 xx,并且在数据库中没有找到键值就会返回// 因为 Redis 中的命令执行都是单线程操作的// 所以命令中判断如果存在就返回,能够保证正确性,不会出现并发访问的问题if ((flags & OBJ_SET_NX && found) ||(flags & OBJ_SET_XX && !found)){if (!(flags & OBJ_SET_GET)) {addReply(c, abort_reply ? abort_reply : shared.null[c->resp]);}return;}...}
1、命令的实现里面加入了键值是否存在的判断,来保证 NX 只有在 key 不存在时设置 key 的值;
2、因为 Redis 中总是一个线程处理命令的执行,单命令是能够保证原子性,不会出现并发的问题。
为什么 Redis 可以用来做分布式锁
分布式锁需要满足的特性
互斥性:在任意时刻,对于同一个锁,只有一个客户端能持有,从而保证一个共享资源同一时间只能被一个客户端操作;
安全性:即不会形成死锁,当一个客户端在持有锁的期间崩溃而没有主动解锁的情况下,其持有的锁也能够被正确释放,并保证后续其它客户端能加锁;
可用性:当提供锁服务的节点发生宕机等不可恢复性故障时,“热备” 节点能够接替故障的节点继续提供服务,并保证自身持有的数据与故障节点一致。
对称性:对于任意一个锁,其加锁和解锁必须是同一个客户端,即客户端 A 不能把客户端 B 加的锁给解了。
那么 Redis 对上面的特性是如何支持的呢?
1、Redis 中命令的执行都是单线程的,虽然在 Redis6.0 的版本中,引入了多线程来处理 IO 任务,但是命令的执行依旧是单线程处理的;
2、单线程的特点,能够保证命令的执行的是不存在并发的问题,同时命令执行的原子性也能得到保证;
3、Redis 中提供了针对 SETNX 这样的命令,能够保证同一时刻是只会有一个请求执行成功,提供互斥性的保障;
4、Redis 中也提供了 EXPIRE 超时释放的命令,可以实现锁的超时释放,避免死锁的出现;
5、高可用,针对如果发生主从切换,数据丢失的情况,Redis 引入了 RedLock 算法,保证了 Redis 中主要大部分节点正常运行,锁就可以正常运行;
6、Redis 中本身没有对锁提供续期的操作,不过一些第三方的实现中实现了 Redis 中锁的续期,类似 使用 java 实现的 Redisson,使用 go 实现的 redsync,当然自己实现也不是很难,实现过程可参见上文。
总体来说,Redis 中对分布式锁的一些特性都提供了支持,使用 Redis 实现分布式锁,是一个不错的选择。
分布式锁如何选择
1、如果业务规模不大,qps 很小,使用 Redis,etcd,ZooKeeper 去实现分布式锁都不会有问题,就看公司了基础架构了,如果有现成的 Redis,etcd,ZooKeeper 直接用就可以了;
2、Redis 中分布式锁有一定的安全隐患,如果业务中对安全性要求很高,那么 Redis 可能就不适合了,etcd 或者 ZooKeeper 就比较合适了;
3、如果系统 qps 很大,但是可以容忍一些错误,那么 Redis 可能就更合适了,毕竟 etcd或者ZooKeeper 背面往往都是较低的吞吐量和较高的延迟。
总结
1、在分布式的场景下,使用分布式锁是我们经常遇到的一种场景;
2、使用 Redis 实现锁是个不错的选择,Redis 的单命令的执行是原子性的同时借助于 Lua 也可以很容易的实现组合命令的原子性;
3、针对分布式场景下主从切换,数据同步不及时的情况,redis 中引入了 redLock 来处理分布式锁;
4、根据 martin 的描述,redLock 是繁重的,且存在安全性,不过我们可以根据自己的业务场景做出判断;
5、需要注意的是在设置分布式锁的时候需要设置 value 的唯一性,并且每次主动删除锁的时候需要匹配下 value 的正确性,避免误删除其他线程的锁;
参考
【Redis核心技术与实战】https://time.geekbang.org/column/intro/100056701
【Redis设计与实现】https://book.douban.com/subject/25900156/
【Redis 的学习笔记】https://github.com/boilingfrog/Go-POINT/tree/master/redis
【Redis 分布式锁】https://redis.io/docs/reference/patterns/distributed-locks/
【How to do distributed locking】https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
【etcd 实现分布式锁】https://www.cnblogs.com/ricklz/p/15033193.html#分布式锁
【Redis中的原子操作(3)-使用Redis实现分布式锁】https://boilingfrog.github.io/2022/06/15/Redis中的原子操作(3)-使用Redis实现分布式锁/
Redis 中的原子操作(3)-使用Redis实现分布式锁的更多相关文章
- Redis 中的原子操作(1)-Redis 中命令的原子性
Redis 如何应对并发访问 Redis 中处理并发的方案 原子性 Redis 的编程模型 Unix 中的 I/O 模型 thread-based architecture(基于线程的架构) even ...
- Redis中的原子操作(2)-redis中使用Lua脚本保证命令原子性
Redis 如何应对并发访问 使用 Lua 脚本 Redis 中如何使用 Lua 脚本 EVAL EVALSHA SCRIPT 命令 SCRIPT LOAD SCRIPT EXISTS SCRIPT ...
- 多线程查询数据,将结果存入到redis中,最后批量从redis中取数据批量插入数据库中【我】
多线程查询数据,将结果存入到redis中,最后批量从redis中取数据批量插入数据库中 package com.xxx.xx.reve.service; import java.util.ArrayL ...
- Redis | 第5章 Redis 中的持久化技术《Redis设计与实现》
目录 前言 1. RDB 持久化 1.1 RDB 文件的创建与载入 1.2 自动间隔性保存 1.2.1 设置保存条件 1.2.2 dirty 计数器和 lastsave 属性 1.2.3 检查保存条件 ...
- Redis 当成数据库在使用和可靠的分布式锁,Redlock 真的可行么?
怎样做可靠的分布式锁,Redlock 真的可行么? https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html ...
- Redis 实战 —— 08. 实现自动补全、分布式锁和计数信号量
自动补全 P109 自动补全在日常业务中随处可见,应该算一种最常见最通用的功能.实际业务场景肯定要包括包含子串的情况,其实这在一定程度上转换成了搜索功能,即包含某个子串的串,且优先展示前缀匹配的串.如 ...
- Java之——redis并发读写锁,使用Redisson实现分布式锁
原文:http://blog.csdn.net/l1028386804/article/details/73523810 1. 可重入锁(Reentrant Lock) Redisson的分布式可重入 ...
- 关于Redis中的serverCron
1.serverCron简介 在 Redis 中, 常规操作由 redis.c/serverCron 实现, 它主要执行以下操作 /* This is our timer interrupt, cal ...
- redis中的事务
首先明白在java中线程和进程的区别: 1.什么是多线程? 是指一个应用程序同时执行多个任务,一般来说一个任务就是一个线程 ,而一个应用程序有一个以上的线程我们称之为多线程. 2.什么是进程? 进程是 ...
随机推荐
- C++---变量、数据类型和运算符
内存 计算机使用内存来记忆或存储计算时所使用的的数据. 计算机执行程序时, 组成程序的指令和程序所操作的数据都必须存放在某个地方, 而这个地方就是计算机的内存, 也称为主存, 或随机访问存储器(RAM ...
- 解决pycharm的爬虫乱码问题(初步了解各种编码格式)
Ascii码(American Standard Code for Information Interchange,美国信息互换标准代码):最初计算机只在美国使用时,只用8位的字节来组合出256(2的 ...
- 六、IDEA安装
一.IDEA下载与安装 1.1.下载IDEA安装包 博主在这里给大家准备了一个64位操作系统的IDEA以便大家下载(使用的是迅雷) 点击此处下载 提取码:dgiy 如果其他小伙伴的电脑版本不一样,博主 ...
- 硬核 | Redis 布隆(Bloom Filter)过滤器原理与实战
在Redis 缓存击穿(失效).缓存穿透.缓存雪崩怎么解决?中我们说到可以使用布隆过滤器避免「缓存穿透」. 码哥,布隆过滤器还能在哪些场景使用呀? 比如我们使用「码哥跳动」开发的「明日头条」APP 看 ...
- JS/TS项目里的Module都是什么?
摘要:在日常进行JS/TS项目开发的时候,经常会遇到require某个依赖和module.exports来定义某个函数的情况.就很好奇Modules都代表什么和有什么作用呢. 本文分享自华为云社区&l ...
- List实现类
List实现类: ArrayList; 数组结构实现,查询快,增删慢 JDK1.2版本,运行效率快,线程不安全 Vector: 数组结构实现,查询快,增删慢 JDK1.0版本,运行效率慢,线程安全 ...
- HTML5的基本功能
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="U ...
- linux 下通过fork实现后台运行进程
1 # 通常建议使用双fork方法.在每个fork处,父级退出,子级继续 2 3 #!/usr/bin/env python 4 5 import time,platform 6 7 import o ...
- PXE实现无人值守批量安装服务器
今天我们使用PXE+Kickstart+TFTP+DHCP+FTP实现无人值守安装服务器. 一.无人值守所需服务介绍: 1)PXE PXE,远程引导技术 功能:使计算机通过网络启动 硬件要求:客户端的 ...
- Flutter 状态管理框架 Provider 和 Get 分析
文/ Nayuta,CFUG 社区 状态管理一直是 Flutter 开发中一个火热的话题.谈到状态管理框架,社区也有诸如有以 Get.Provider 为代表的多种方案,它们有各自的优缺点. 面对这么 ...