数据结构与算法【Java】05---排序算法总结
前言
数据 data 结构(structure)是一门 研究组织数据方式的学科,有了编程语言也就有了数据结构.学好数据结构才可以编写出更加漂亮,更加有效率的代码。
- 要学习好数据结构就要多多考虑如何将生活中遇到的问题,用程序去实现解决.
- 程序 = 数据结构 + 算法
- 数据结构是算法的基础, 换言之,想要学好算法,需要把数据结构学到位
我会用数据结构与算法【Java】这一系列的博客记录自己的学习过程,如有遗留和错误欢迎大家提出,我会第一时间改正!!!
注:数据结构与算法【Java】这一系列的博客参考于B站尚硅谷的视频,视频原地址为【尚硅谷】数据结构与算法(Java数据结构与算法)
上一篇文章数据结构与算法【Java】04---递归
接下来进入正题!
数据结构与算法【Java】05---排序算法
1、排序算法介绍
- 排序也称排序算法(SortAlgorithm),排序是将 一组数据,依指定的顺序进行排列的过程
- 有很多种不同的排序算法,每一种都有各自的优势和限制
- 下面我们会一一分析不同种的排序算法并比较他们之间的区别
2、排序的分类
内部排序:
指将需要处理的所有数据都加载到 内部存储器( 内存)中进行排序。
外部排序法:
数据量过大,无法全部加载到内存中,需要借助 外部存储( 文件等)进行排序。
3、算法的时间复杂度
3.1、度量一个程序(算法)执行时间的两种方法
- 事后统计:实际运行程序统计时间,但是容易受计算机的软硬件环境影响
- 事前统计:分析时间复杂度
3.2、时间频度
介绍:一个算法中的语句执行次数称为语句频度或时间频度。记为 T(n)
举例说明:
1、比如计算1-100所有数字之和, 我们设计两种算法:
(1)T(n)=n+1

(2)T(n)=1

2、时间频度的表示
(1)忽略常数项

结论:
2n+20 和 2n 随着n 变大,执行曲线无限接近, 20可以忽略
3n+10 和 3n 随着n 变大,执行曲线无限接近, 10可以忽略
(2)忽略低次项

结论:
2n^2+3n+10 和 2n^2 随着n 变大, 执行曲线无限接近, 可以忽略 3n+10
n^2+5n+20 和 n^2 随着n 变大,执行曲线无限接近, 可以忽略 5n+20
(3)忽略系数

结论:
随着n值变大,5n^2+7n 和 3n^2 + 2n ,执行曲线重合, 说明 这种情况下, 5和3可以忽略。
而n^3+5n 和 6n^3+4n ,执行曲线分离,说明多少次方式关键
3.3、时间复杂度
1.一般情况下, 算法中的基本操作语句的重复执行次数是问题规模 n 的某个函数,用 T(n)表示,若有某个辅
助函数 f(n),使得当 n 趋近于无穷大时,T(n) / f(n) 的极限值为不等于零的常数,则称 f(n)是 T(n)的同数量级函数。
记作 T(n)= O( f(n) ),称O( f(n) ) 为算法的渐进时间复杂度,简称时间复杂度。
- T(n) 不同,但时间复杂度可能相同。 如:T(n)=n²+7n+6 与 T(n)=3n²+2n+2 它们的 T(n) 不同,但时间复杂
度相同,都为 O(n² )。 - 计算时间复杂度的方法:
(1) 用常数 1 代替运行时间中的所有加法常数 T(n)=n²+7n+6 => T(n)=n²+7n+1
(2)修改后的运行次数函数中,只保留最高阶项 T(n)=n²+7n+1 => T(n) = n²
(3)去除最高阶项的系数 T(n) = n² => T(n) = n² => O(n²)
3.4、常见的时间复杂度
- 常数阶O(1)
- 对数阶O(log2n)
- 线性阶O(n)
- 线性对数阶O(nlog2n)
- 平方阶O(n^2)
- 立方阶O(n^3)
- k次方阶O(n^k)
- 指数阶O(2^n)

说明:
- 常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)< Ο(nk) <Ο(2n) ,随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低
- 从图中可见,我们应该尽可能避免使用指数阶的算法
举例说明
1.常数阶O(1)
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是O(1)
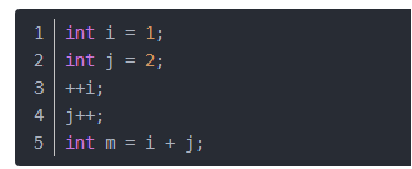
上述代码在执行的时候,它消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用O(1)来表示它的时间复杂度
2.对数阶O(log2n)
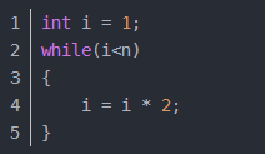
在while循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。假设循环x次之后,i 就大于 2 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 x = log2n也就是说当循环 log2n 次以后,这个代码就结束了。
因此这个代码的时间复杂度为:O(log2n) 。 O(log2n) 的这个2 时间上是根据代码变化的,i = i * 3 ,则是 O(log3n) .
3.线性阶O(n)
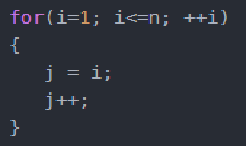
这段代码,for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用O(n)来表示它的时间复杂度
4.线性对数阶O(nlog2n)
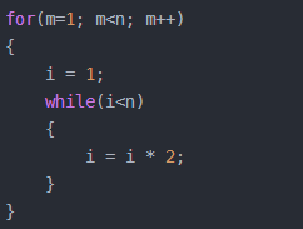
线性对数阶O(nlogN) 其实非常容易理解,将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logN),也就是了O(nlogN)
5.平方阶O(n^2)

平方阶O(n²) 就更容易理解了,如果把 O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O(n²),这段代码其实就是嵌套了2层n循环,它的时间复杂度就是 O(n*n),即 O(n²) 如果将其中一层循环的n改成m,那它的时间复杂度就变成了 O(m*n)
6.立方阶O(n^3)、 k次方阶O(n^k)
O(n³)相当于三层n循环,其它的类似
3.5、平均时间复杂度和最坏时间复杂度
平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间
最坏情况下的时间复杂度称最坏时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。 这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的界限,这就保证了算法的运行时间不会比最坏情况更长
平均时间复杂度和最坏时间复杂度是否一致,和算法有关
4、算法的空间复杂度
类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,它也是问题规模n的函数
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元,例如快速排序和归并排序算法就属于这种情况
在做算法分析时,主要讨论的是时间复杂度。从用户使用体验上看,更看重的程序执行的速度。一些缓存产品(redis, memcache)和算法(基数排序)本质就是用空间换时间.
5、冒泡排序
5.1、冒泡排序简介
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就象水底下的气泡一样逐渐向上冒。
优化:因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置
一个标志flag判断元素是否进行过交换。从而减少不必要的比较。
5.2、冒泡排序过程演示
图解过程
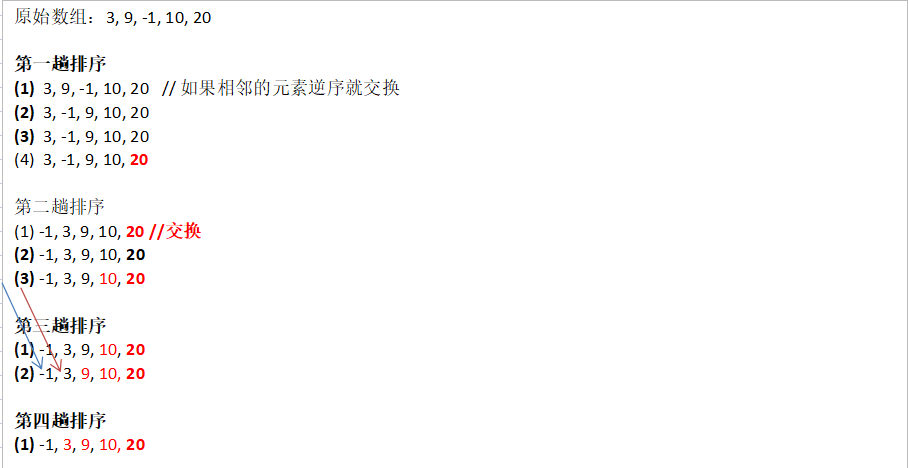
过程分析
(1) 一共进行数组的大小 - 1 (
arr.length - 1)次 大的循环
(2)每一趟排序的次数在逐渐的减少
(3) 优化思路:如果我们发现在某趟排序中,没有发生一次交换, 可以提前结束冒泡排序
动态图

5.3、冒泡排序代码实现
未优化
public class Test {
public static void main(String[] args) {
int arr[] = {3, 9, -1, 10, 20};
//冒泡排序,时间复杂度O(n²)
//定义一个临时变量
int temp = 0;
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
//如果前面的数比后面的大,就交换
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
System.out.println("第" + (i + 1) + "趟排序后的数组");
System.out.println(Arrays.toString(arr));
}
}
}
结果展示:

优化
public class Test {
public static void main(String[] args) {
int arr[] = {3, 9, -1, 10, 20};
//冒泡排序,时间复杂度O(n²)
int temp = 0;//定义一个临时变量
boolean flag = false;//表示变量,表示是否进行过交换
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
//如果前面的数比后面的大,就交换
if (arr[j] > arr[j + 1]) {
flag = true;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
System.out.println("第" + (i + 1) + "趟排序后的数组");
System.out.println(Arrays.toString(arr));
if (!flag) {//在一趟排序中,一次交换都没有发生过,!flag也可以写成flag==false
break;
} else {
flag = false;//重置flag,进行下一次判断
}
}
}
}
结果展示:

封装成方法
public class BubbleSort {
public static void main(String[] args) {
int arr[] = {3, 9, -1, 10, 20};
//测试冒泡排序
System.out.println("排序前的数组");
System.out.println(Arrays.toString(arr));
bubbleSort(arr);
System.out.println("排序后的数组");
System.out.println(Arrays.toString(arr));
}
//将前面的冒泡排序封装成一个方法
public static void bubbleSort(int arr[]){
//冒泡排序,时间复杂度O(n²)
int temp = 0;//定义一个临时变量
boolean flag = false;//表示变量,表示是否进行过交换
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
//如果前面的数比后面的大,就交换
if (arr[j] > arr[j + 1]) {
flag = true;
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
//System.out.println("第" + (i + 1) + "趟排序后的数组");
//System.out.println(Arrays.toString(arr));
if (!flag) {//在一趟排序中,一次交换都没有发生过,!flag也可以写成flag==false
break;
} else {
flag = false;//重置flag,进行下一次判断
}
}
}
}
结果展示:

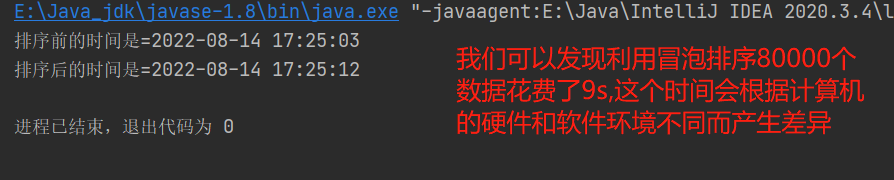
测试冒泡排序O(n²)的速度
为了测试冒泡排序O(n²)的速度,我们随机生成80000个数据进行排序,由于打印80000个数据很不方便,我们就输出排序前后的时间
//测试一下冒泡排序的速度O(n^2), 给80000个数据,测试
//创建要给80000个的随机的数组
int[] arr = new int[80000];
for(int i =0; i < 80000;i++) {
arr[i] = (int)(Math.random() * 8000000); //生成一个[0, 8000000) 数
}
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
//测试冒泡排序
bubbleSort(arr);
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序后的时间是=" + date2Str);
结果展示:
6、选择排序
6.1、选择排序简介
选择排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到排序的目的
排序思想:
第一次从arr[0]~arr[n-1]中选取最小值,与arr[0]交换,
第二次从arr[1]~arr[n-1]中选取最小值,与arr[1]交换,
第三次从arr[2]~arr[n-1]中选取最小值,与arr[2]交换,…,
第i次从arr[i-1]~arr[n-1]中选取最小值,与arr[i-1]交换,…,
第n-1次从arr[n-2]~arr[n-1]中选取最小值,与arr[n-2]交换,
总共通过n-1次,得到一个按排序码从小到大排列的有序序列。
6.2、选择排序过程演示
- 过程图解

过程分析
- 选择排序一共有 数组大小 - 1(
arr.length-1) 轮排序
2. 每1轮排序,又是一个循环, 循环的规则(代码)
2.1先假定当前这个数是最小数
2.2 然后和后面的每个数进行比较,如果发现有比当前数更小的数,就重新确定最小数,并得到下标
2.3 当遍历到数组的最后时,就得到本轮最小数和下标
2.4 交换
- 选择排序一共有 数组大小 - 1(
动态图

6.3、选择排序代码实现
优化+封装
public class SelectSort {
public static void main(String[] args) {
int [] arr = {100,35,120,7};
System.out.println("排序前");
System.out.println(Arrays.toString(arr));
selectSort(arr);
System.out.println("排序后");
System.out.println(Arrays.toString(arr));
}
//选择排序的方法
public static void selectSort(int [] arr){
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
int min = arr[i];
for (int j = i+1; j < arr.length; j++) {
if (min > arr[j]){//说明假定的最小值不是最小
minIndex = j;//重置min和minIndex
min = arr[j];
}
}
//交换,将最小值依次放在最前面
//优化:如果假定的最小值就是真实的最小值,那么就不进行交换(这里假定的最小值是上一轮交换后的下一个值)
if (minIndex != i){
arr[minIndex] = arr[i];
arr[i] = min;
}
//System.out.println("第"+(i+1)+"轮后");
//System.out.println(Arrays.toString(arr));
}
}
}
结果展示
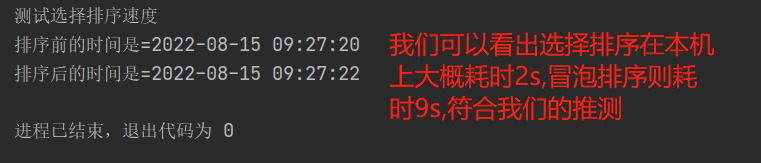
测试选择排序O(n²)的速度
测试方法同冒泡排序中的方法,我们在测试之前通过分析可以得出选择排序交换是找到最小(大)值才进行交换,而冒泡排序是相邻元素之间进行比较交换,所以选择排序的交换次数应该比冒泡排序少,速度应该更快。
7、插入排序
7.1、插入排序简介
插入式排序属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的。
排序思想:
插入排序(Insertion Sorting)的基本思想是:把 把 n 个待排序的元素看成为一个有序表和一个无序表,开始时 有
序表中只包含一个元素,无序表中包含有 n-1 个元素,排序过程中每次从无序表中取出第一个元素,把它的排
序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表。
7.2、插入排序过程演示
过程图解

动态图

7.3、插入排序代码实现
插入排序
public class InsertSort {
public static void main(String[] args) {
int [] arr = {23,56,189,77,-1,0};
insertSort(arr);
}
//插入排序
public static void insertSort(int [] arr){
for (int i = 1; i < arr.length ; i++) {
//定义待插入的数
int insertVal = arr[i];
int insertIndex = i - 1;
// 给insertVal 找到插入的位置
// 说明
// 1. insertIndex >= 0 保证在给insertVal 找插入位置,不越界
// 2. insertVal < arr[insertIndex] 待插入的数,还没有找到插入位置
// 3. 就需要将 arr[insertIndex] 后移
while (insertIndex >=0 && insertVal < arr[insertIndex]){
arr[insertIndex + 1] = arr[insertIndex];
insertIndex--;
}
// 当退出while循环时,说明插入的位置找到, insertIndex + 1
//这里我们判断是否需要赋值(加上if语句就是优化)
if (insertVal + 1 != i) {
arr[insertIndex + 1] = insertVal;
}
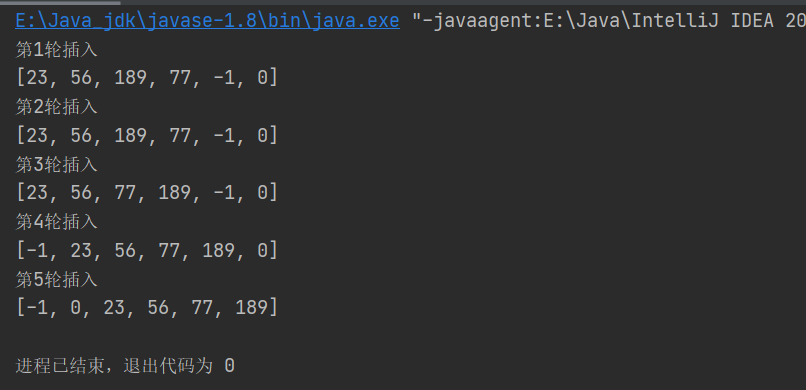
System.out.println("第"+i+"轮插入");
System.out.println(Arrays.toString(arr));
}
}
}
结果:
测试插入排序O(n²)的速度
public static void main(String[] args) {
// 创建要给80000个的随机的数组
int[] arr = new int[80000];
for (int i = 0; i < 80000; i++) {
arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数
}
System.out.println("插入排序前");
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
insertSort(arr); //调用插入排序算法
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序后的时间是=" + date2Str);
}
测试结果:本机耗时约为1s

8、希尔排序
8.1、简单插入排序存在的问题
我们看简单的插入排序可能存在的问题.
数组 arr = {2,3,4,5,6,1} 这时需要插入的数 1( 最小), 这样的过程是:
{2,3,4,5,6,6}
{2,3,4,5,5,6}
{2,3,4,4,5,6}
{2,3,3,4,5,6}
{2,2,3,4,5,6}
{1,2,3,4,5,6}
结论: 当 需要插入的数是较小的数时, 后移的次数明显增多,对 效率有影响.
8.2、希尔排序简介
希尔排序是希尔(Donald Shell)于 1959 年提出的一种排序算法。
希尔排序也是一种 插入排序,它是简单插入排序经过改进之后的一个 更高效的版本,也称为 缩小增量排序
排序思想
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含
的关键词越来越多, 当增量减至 1 时,整个文件恰被分成一组,算法便终止
8.3、希尔排序过程演示
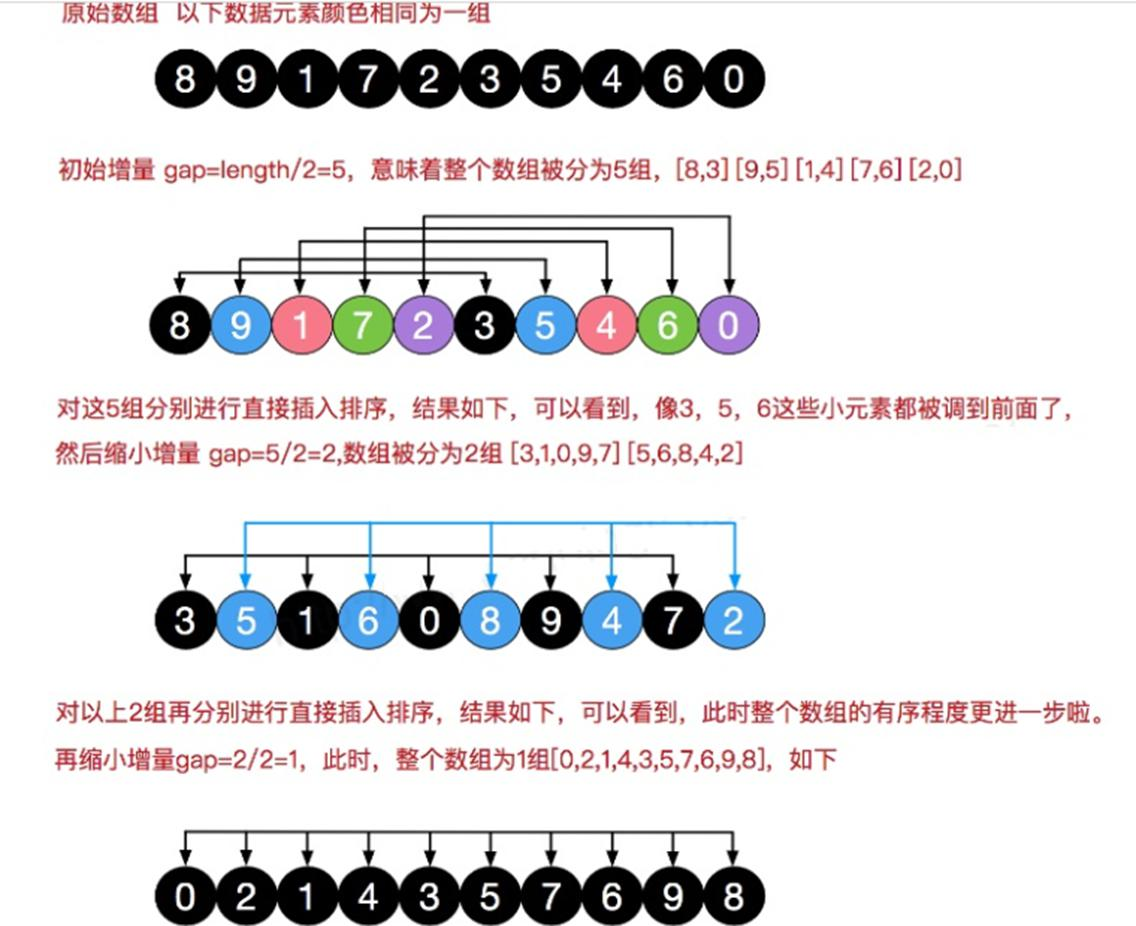

动态图

8.4、希尔排序代码实现
- 希尔排序时, 对有序序列在插入时采用 交换法, 并测试排序速度.(速度较慢但易于理解)
- 希尔排序时, 对有序序列在插入时采用 移动法, 并测试排序速度(速度较快但不易理解)
交换法
public class ShellSort {
public static void main(String[] args) {
int [] arr = {8,9,1,7,2,3,5,4,6,0};
shellSort(arr);
}
//希尔排序
public static void shellSort(int [] arr){
int temp = 0;
int count = 0;
//分组
for (int gap = arr.length/2;gap > 0; gap /= 2){
//遍历各组
for (int i = gap;i < arr.length;i++){
//遍历各组中的所有元素(共gap组,每组有arr.length/gap个元素,步长是gap)
//j -= gap,之前插入排序是index--,因为每次要往前一步,现在是希尔排序,有间隔,所以是j -= gap
for (int j = i - gap; j >= 0 ; j -= gap) {
//如果当前元素大于加上步长后的那个元素,说明交换
if (arr[j] > arr[j+gap]) {
temp = arr[j];
arr[j] = arr[j + gap];
arr[j + gap] = temp;
}
}
}
System.out.println("希尔排序第"+ (++count) +"轮:"+ Arrays.toString(arr));
}
}
}
结果:

速度测试:本机耗时约为5s,可以看到交换法并没有对简单插入排序的速度进行提升,接下来我们来看移动法

移位法(重点)
//希尔排序移动法
public static void shellSort2(int [] arr){
int count = 0;
//增量gap,并逐步缩小增量
for (int gap = arr.length/2;gap > 0; gap /= 2){
//从第gap个元素开始,逐个对其所在的组进行直接插入排序
for (int i = gap; i < arr.length; i++) {
int j = i;
int temp = arr[j];
if(arr[j] < arr[j -gap]){
while (j - gap >= 0 && temp < arr[j - gap]){
//移动
arr[j] = arr[j - gap];
j -= gap;
}
//当退出while循环后,就给temp找到插入的位置
arr[j] = temp;
}
}
System.out.println("希尔排序第"+ (++count) +"轮:"+ Arrays.toString(arr));
}
}
结果:
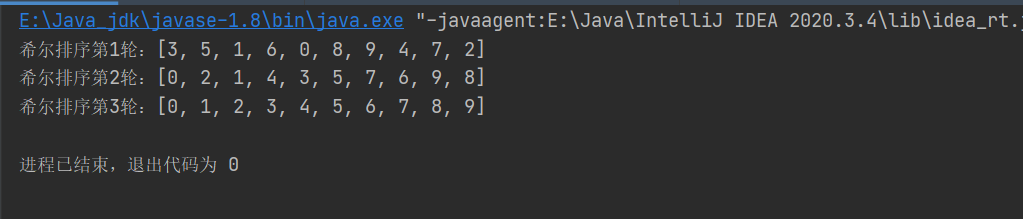
速度测试:本机耗时不到1s,确实提升了简单插入排序的速度
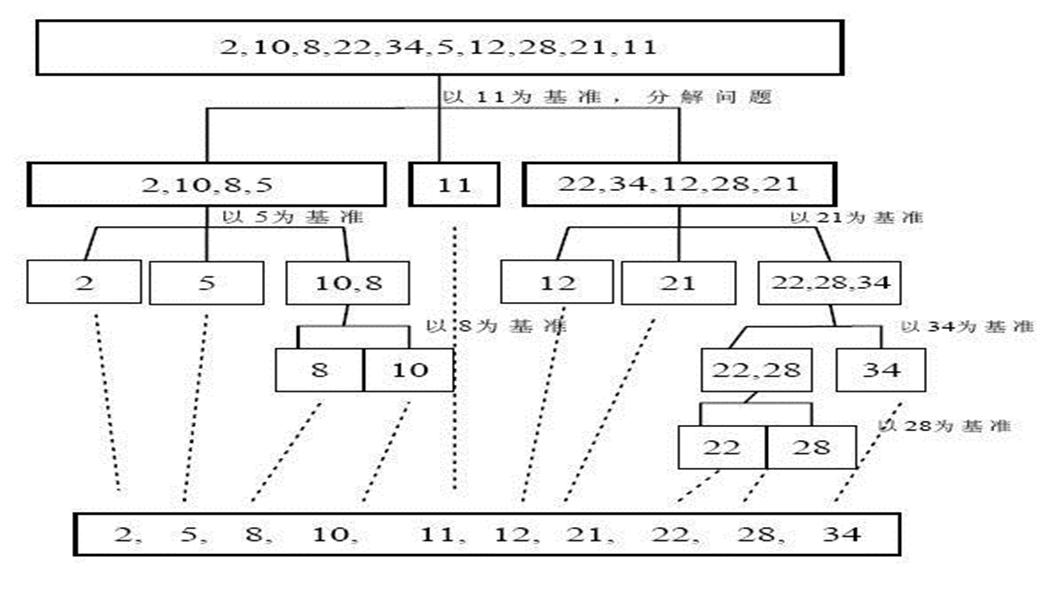
9、快速排序
9.1、快速排序简介
快速排序(Quicksort)是对 冒泡排序的一种改进。基本思想是:通过一趟排序将要排序的数据分割成独立的两
部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排
序, 整个排序过程可以递归进行,以此达到整个数据变成有序序列
9.2、快速排序过程演示
动态图

9.3、快速排序代码实现
要求:对 10,7,2,4,7,62,3,4,2,1,8,9,19 进行从小到大的排序,要求使用快速排序法
代码实现
public class QuickSort {
public static void main(String[] args){
int[] arr = {10,7,2,4,7,62,3,4,2,1,8,9,19};
quickSort(arr, 0, arr.length-1);
System.out.println("arr="+ Arrays.toString(arr));
}
public static void quickSort(int[] arr,int low,int high){
int i,j,temp,t;
if(low>high){
return;
}
i=low;
j=high;
//temp就是基准位,这里基准位取的是低半区的第一个数据
temp = arr[low];
while (i<j) {
//先看右边,依次往左递减
while (temp<=arr[j]&&i<j) {
j--;
}
//再看左边,依次往右递增
while (temp>=arr[i]&&i<j) {
i++;
}
//如果满足条件则交换
if (i<j) {
t = arr[j];
arr[j] = arr[i];
arr[i] = t;
}
}
//最后将基准位与i和j相等位置的数字交换,因为这里基准位取的是低半区的第一个数据
arr[low] = arr[i];
arr[i] = temp;
//递归调用左半数组
quickSort(arr, low, j-1);
//递归调用右半数组
quickSort(arr, j+1, high);
}
}
结果:

快速排序速度测试O(nlogn)
分析
快速排序是基于一种叫做“二分”的思想,快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。
每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。
这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。
因此总的比较和交换次数就少了,速度自然就提高了。
当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。
快速排序理论上速度是优于希尔排序的
10、归并排序
10.1、归并排序简介
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的 分治 (divide-and-conquer )
策略(分治法将问题分(divide)成一些 小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修
补"在一起,即分而治之)。
10.2、归并排序过程演示
(1)归并排序示意图1
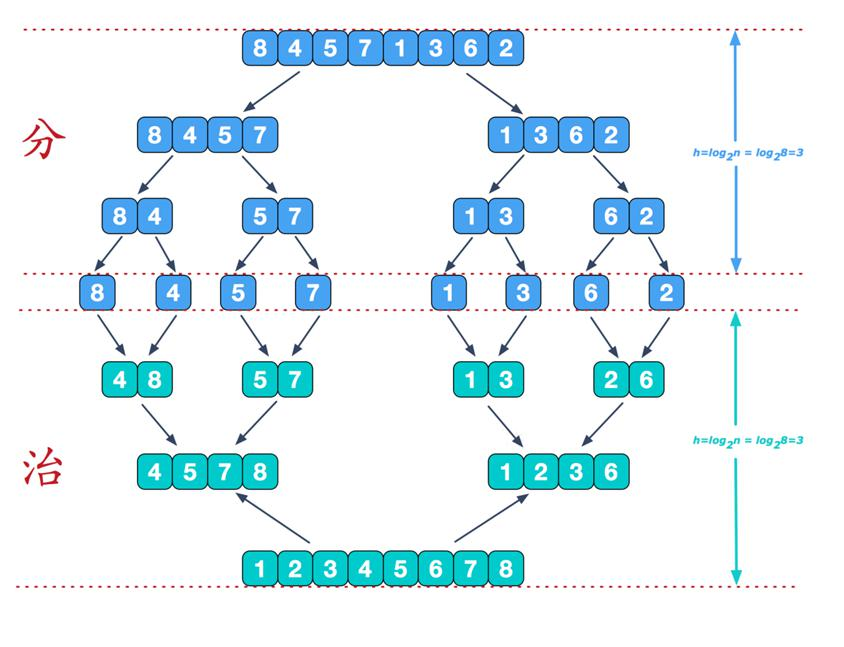
(2)归并排序示意图2
来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将
[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤

动态图

10.3、归并排序代码实现
代码实现
public class MergetSort {
public static void main(String[] args) {
int arr[] = {8,4,5,7,1,3,6,2};
int temp[] = new int[arr.length]; //归并排序需要一个额外空间
mergeSort(arr, 0, arr.length - 1, temp);
System.out.println("归并排序后="+ Arrays.toString(arr));
}
//分+合方法
public static void mergeSort(int[] arr, int left, int right, int[] temp) {
if(left < right) {
int mid = (left + right) / 2; //中间索引
//向左递归进行分解
mergeSort(arr, left, mid, temp);
//向右递归进行分解
mergeSort(arr, mid + 1, right, temp);
//合并
merge(arr, left, mid, right, temp);
}
}
//合并的方法
/**
*
* @param arr 排序的原始数组
* @param left 左边有序序列的初始索引
* @param mid 中间索引
* @param right 右边索引
* @param temp 做中转的数组
*/
public static void merge(int[] arr, int left, int mid, int right, int[] temp) {
int i = left; // 初始化i, 左边有序序列的初始索引
int j = mid + 1; //初始化j, 右边有序序列的初始索引
int t = 0; // 指向temp数组的当前索引
//(一)
//先把左右两边(有序)的数据按照规则填充到temp数组
//直到左右两边的有序序列,有一边处理完毕为止
while (i <= mid && j <= right) {//继续
//如果左边的有序序列的当前元素,小于等于右边有序序列的当前元素
//即将左边的当前元素,填充到 temp数组
//然后 t++, i++
if(arr[i] <= arr[j]) {
temp[t] = arr[i];
t += 1;
i += 1;
} else { //反之,将右边有序序列的当前元素,填充到temp数组
temp[t] = arr[j];
t += 1;
j += 1;
}
}
//(二)
//把有剩余数据的一边的数据依次全部填充到temp
while( i <= mid) { //左边的有序序列还有剩余的元素,就全部填充到temp
temp[t] = arr[i];
t += 1;
i += 1;
}
while( j <= right) { //右边的有序序列还有剩余的元素,就全部填充到temp
temp[t] = arr[j];
t += 1;
j += 1;
}
//(三)
//将temp数组的元素拷贝到arr
//注意,并不是每次都拷贝所有
t = 0;
int tempLeft = left; //
//第一次合并 tempLeft = 0 , right = 1 // tempLeft = 2 right = 3 // tL=0 ri=3
//最后一次 tempLeft = 0 right = 7
while(tempLeft <= right) {
arr[tempLeft] = temp[t];
t += 1;
tempLeft += 1;
}
}
}
结果:

归并排序速度测试O(nlogn)

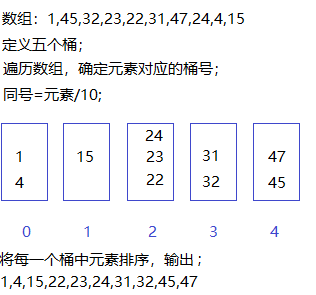
11、桶排序
11.1、桶排序简介
桶排序(Bucket sort)是将待排序集合中处于同一个值域的元素存入同一个桶中,也就是根据元素值特性将集合拆分为多个区域,则拆分后形成的多个桶,从值域上看是处于有序状态的。对每个桶中元素进行排序,则所有桶中元素构成的集合是已排序的。
如果桶的大小划分得足够小,到达每个元素之间的最小差值,则可以保证每一个桶里面所有的数据都是一样的,入桶后的数据也就不需要再次进行排序,这种情况也就是桶排序时间复杂度最优的情况即O ( n ) .一般情况下桶排序的时间复杂度为O ( n + k) ,其中n为元素个数,k为桶个数。
11.2、桶排序过程演示
排序思想
- 确定桶的大小与个数,一般根据要排序的元素的值域区间取定。
- 设计一种方式使元素能映射至对应值域的桶的索引。
- 遍历所有元素,将它们入桶。
- 每个桶内元素排序。
- 从桶内依次提取各元素重新排列
过程演示
动态图

11.3、桶排序代码实现
代码
public static void main(String[] args) {
int[] arr = { 1, 45, 32, 23, 22, 31, 47, 24, 4, 15 };
bucketsort(arr);
}
public static void bucketsort(int[] arr) {
ArrayList bucket[] = new ArrayList[5];// 声明五个桶
for (int i = 0; i < bucket.length; i++) {
bucket[i] = new ArrayList<Integer>();// 确定桶的格式为ArrayList
}
for (int i = 0; i < arr.length; i++) {
int index = arr[i] / 10;// 确定元素存放的桶号
bucket[index].add(arr[i]);// 将元素存入对应的桶中
}
for (int i = 0; i < bucket.length; i++) {// 遍历每一个桶
bucket[i].sort(null);// 对每一个桶排序
for (int i1 = 0; i1 < bucket[i].size(); i1++) {// 遍历桶中的元素并输出
System.out.print(bucket[i].get(i1) + " ");
}
}
}
}
结果:

桶排序速度测试
public class BucketSort {
public static void main(String[] args) {
// int[] arr = { 1, 45, 32, 23, 22, 31, 47, 24, 4, 15 };
// bucketsort(arr);
int[] arr = new int[80000];
for (int i = 0; i < 80000; i++) {
arr[i] = (int) (Math.random() * 80000); // 生成一个[0, 8000000) 数
}
System.out.println("排序前");
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
bucketsort(arr);
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序后的时间是=" + date2Str);
}
public static void bucketsort(int[] arr) {
ArrayList bucket[] = new ArrayList[80000];// 声明五个桶
for (int i = 0; i < bucket.length; i++) {
bucket[i] = new ArrayList<Integer>();// 确定桶的格式为ArrayList
}
for (int i = 0; i < arr.length; i++) {
int index = arr[i] / 10;// 确定元素存放的桶号
bucket[index].add(arr[i]);// 将元素存入对应的桶中
}
for (int i = 0; i < bucket.length; i++) {// 遍历每一个桶
bucket[i].sort(null);// 对每一个桶排序
for (int i1 = 0; i1 < bucket[i].size(); i1++) {// 遍历桶中的元素并输出
System.out.print(bucket[i].get(i1) + " ");
}
}
}
}
12、基数排序
12.1、基数排序简介
1.基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或 bin sort,顾
名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用
- 基数排序法是属于稳定性的排序,基数排序法的是效率高的 稳定性排序法
- 基数排序(Radix Sort)是桶排序的扩展
- 基数排序是 1887 年赫尔曼·何乐礼发明的。它是这样实现的:将整数按位数切割成不同的数字,然后按每个
位数分别比较。
12.2、基数排序过程演示
- 排序思想:
- 将所有待比较数值统一为同样的数位长度,数位较短的数前面补零然后,从最低位开始,依次进行一次排序这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列

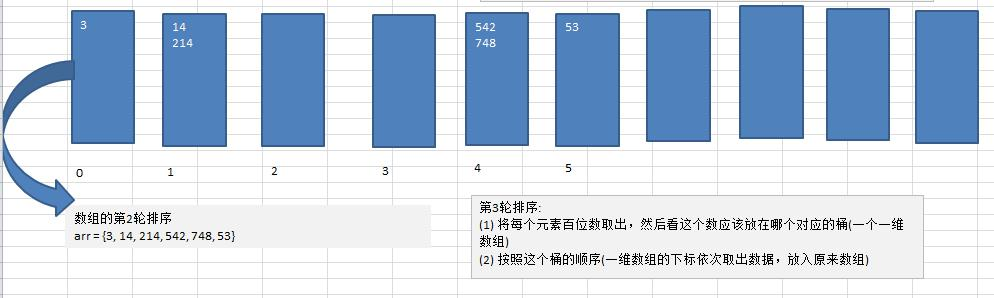

动态图

12.3、基数排序代码实现
按每一轮具体分析(推导过程)
public class RadixSort {
public static void main(String[] args) {
int arr[] = {53,3,542,748,14,214};
radixSort(arr);
}
//基数排序
public static void radixSort(int [] arr){
//定义一个二维数组,表示是10个桶,每一个桶代表一个一维数组
//说明
//1. 二维数组包含10个一维数组
//2. 为了防止在放入数的时候,数据溢出,则每个一维数组(桶),大小定为arr.length
//3. 很明显基数排序是使用空间换时间的经典算法
int[][] bucket = new int[10][arr.length];
//为了记录每个桶中,实际存放了多少个数据,我们定义一个一维数组来记录各个桶的每次放入的数据个数
//比如:bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数
int [] bucketElementCounts = new int[10];
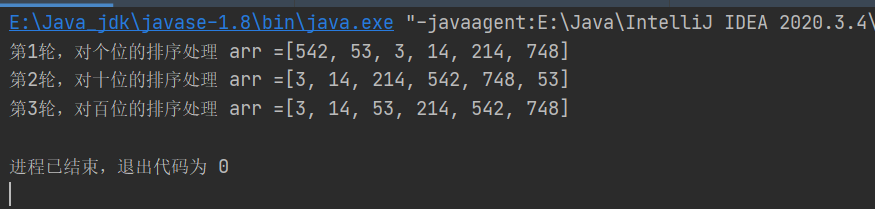
//第一轮排序,针对每个元素的个位进行排序
for (int i = 0; i < arr.length; i++) {
//取出每个元素的个位的值
int digitOfElement = arr[i]%10;
//放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[i];
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
int index = 0;
//遍历每一个桶,并将桶中的数据放入到原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
//如果桶中有数据,我们才放入到原数组
if (bucketElementCounts[k]!=0){//说明第k个桶有数据
//循环该桶(即第k个一位数组)
for (int j = 0; j < bucketElementCounts[k]; j++) {
//取出元素放入到arr中
arr[index++] = bucket[k][j];//第k个桶里面的第j个元素
}
}
//第1轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!!
bucketElementCounts[k] = 0;
}
System.out.println("第1轮,对个位的排序处理 arr =" + Arrays.toString(arr));
//第2轮(针对每个元素的十位进行排序处理)
for (int j = 0; j < arr.length; j++) {
// 取出每个元素的十位的值
int digitOfElement = arr[j] / 10 % 10; //748 / 10 => 74 % 10 => 4
// 放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
// 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
index = 0;
// 遍历每一桶,并将桶中是数据,放入到原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
// 如果桶中,有数据,我们才放入到原数组
if (bucketElementCounts[k] != 0) {
// 循环该桶即第k个桶(即第k个一维数组), 放入
for (int j = 0; j < bucketElementCounts[k]; j++) {
// 取出元素放入到arr
arr[index++] = bucket[k][j];
}
}
//第2轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!!
bucketElementCounts[k] = 0;
}
System.out.println("第2轮,对十位的排序处理 arr =" + Arrays.toString(arr));
//第3轮(针对每个元素的百位进行排序处理)
for (int j = 0; j < arr.length; j++) {
// 取出每个元素的十位的值
int digitOfElement = arr[j] / 100 % 10; //748 / 100 => 7
// 放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
// 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
index = 0;
// 遍历每一桶,并将桶中是数据,放入到原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
// 如果桶中,有数据,我们才放入到原数组
if (bucketElementCounts[k] != 0) {
// 循环该桶即第k个桶(即第k个一维数组), 放入
for (int j = 0; j < bucketElementCounts[k]; j++) {
// 取出元素放入到arr
arr[index++] = bucket[k][j];
}
}
//第3轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!!
bucketElementCounts[k] = 0;
}
System.out.println("第3轮,对百位的排序处理 arr =" + Arrays.toString(arr));
}
}
结果:
最终代码
import java.util.Arrays;
public class RadixSort {
public static void main(String[] args) {
int arr[] = {53,3,542,748,14,214};
radixSort(arr);
}
//基数排序
public static void radixSort(int [] arr){
//根据前面的推导过程,我们可以得到最终的基数排序代码
//得到数组中最大的数
int max = arr[0]; //假设第一数就是最大数
for(int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
//得到最大数是几位数
int maxLength = (max + "").length();
//定义一个二维数组,表示是10个桶,每一个桶代表一个一维数组
//说明
//1. 二维数组包含10个一维数组
//2. 为了防止在放入数的时候,数据溢出,则每个一维数组(桶),大小定为arr.length
//3. 很明显基数排序是使用空间换时间的经典算法
int[][] bucket = new int[10][arr.length];
//为了记录每个桶中,实际存放了多少个数据,我们定义一个一维数组来记录各个桶的每次放入的数据个数
//比如:bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数
int [] bucketElementCounts = new int[10];
//这里使用循环处理一下
for (int i = 0, n = 1; i < maxLength; i++,n*=10) {
//(针对每个元素的对应位进行排序处理), 第一次是个位,第二次是十位,第三次是百位..
for (int m = 0; m < arr.length; m++) {
//取出每个元素的个位的值
int digitOfElement = arr[m] / n % 10;
//放入到对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[m];
bucketElementCounts[digitOfElement]++;
}
//按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组)
int index = 0;
//遍历每一个桶,并将桶中的数据放入到原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
//如果桶中有数据,我们才放入到原数组
if (bucketElementCounts[k]!=0){//说明第k个桶有数据
//循环该桶(即第k个一位数组)
for (int j = 0; j < bucketElementCounts[k]; j++) {
//取出元素放入到arr中
arr[index++] = bucket[k][j];//第k个桶里面的第j个元素
}
}
//第i+1轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!!
bucketElementCounts[k] = 0;
}
System.out.println("第"+(i+1)+"轮,对个位的排序处理 arr =" + Arrays.toString(arr));
}
}
}
结果:

基数排序速度测试O(n*k)

12.4、基数排序说明
基数排序是对传统桶排序的扩展,速度很快.
基数排序是经典的空间换时间的方式,占用内存很大, 当对海量数据排序时,容易造成 OutOfMemoryError 。
基数排序是稳定的。
[注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些
记录的相对次序保持不变,即在原序列中,r[i]=r[j],且 r[i]在 r[j]之前,而在排序后的序列中,r[i]仍在 r[j]之前,
则称这种排序算法是稳定的;否则称为不稳定的]
- 有负数的数组,我们不用基数排序来进行排序, 如果要支持负数,参考: https://code.i-harness.com/zh-CN/q/e98fa9
13、计数排序
13.1、计数排序简介
计数排序是一个非基于比较的排序算法,元素从未排序状态变为已排序状态的过程,是由额外空间的辅助和元素本身的值决定的。
该算法于1954年由 Harold H. Seward 提出。
它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。
当然这是一种牺牲空间换取时间的做法,而且当
O(k)>O(nlogn)的时候其效率反而不如基于比较的排序,因为基于比较的排序的时间复杂度在理论上的下限是O(nlogn)。
13.2、计数排序过程演示
排序思想
- 根据待排序集合中最大元素和最小元素的差值范围,申请额外空间;
- 遍历待排序集合,将每一个元素出现的次数记录到元素值对应的额外空间内;
- 对额外空间内数据进行计算,得出每一个元素的正确位置;
- 将待排序集合每一个元素移动到计算得出的正确位置上
排序示意图
详解过程图:
先假设 20 个数列为:{9, 3, 5, 4, 9, 1, 2, 7, 8,1,3, 6, 5, 3, 4, 0, 10, 9, 7, 9}。
让我们先遍历这个无序的随机数组,找出最大值为 10 和最小值为 0。这样我们对应的计数范围将是 0 ~ 10。然后每一个整数按照其值对号入座,对应数组下标的元素进行加1操作。
比如第一个整数是 9,那么数组下标为 9 的元素加 1,如下图所示。

第二个整数是 3,那么数组下标为 3 的元素加 1,如下图所示。

继续遍历数列并修改数组......。最终,数列遍历完毕时,数组的状态如下图。

数组中的每一个值,代表了数列中对应整数的出现次数。
有了这个统计结果,排序就很简单了,直接遍历数组,输出数组元素的下标值,元素的值是几,就输出几次。比如统计结果中的 1 为 2,就是数列中有 2 个 1 的意思。这样我们就得到最终排序好的结果。
0, 1, 1, 2, 3, 3, 3, 4, 4, 5, 5, 6, 7, 7, 8, 9, 9, 9, 9, 10
动态演示:
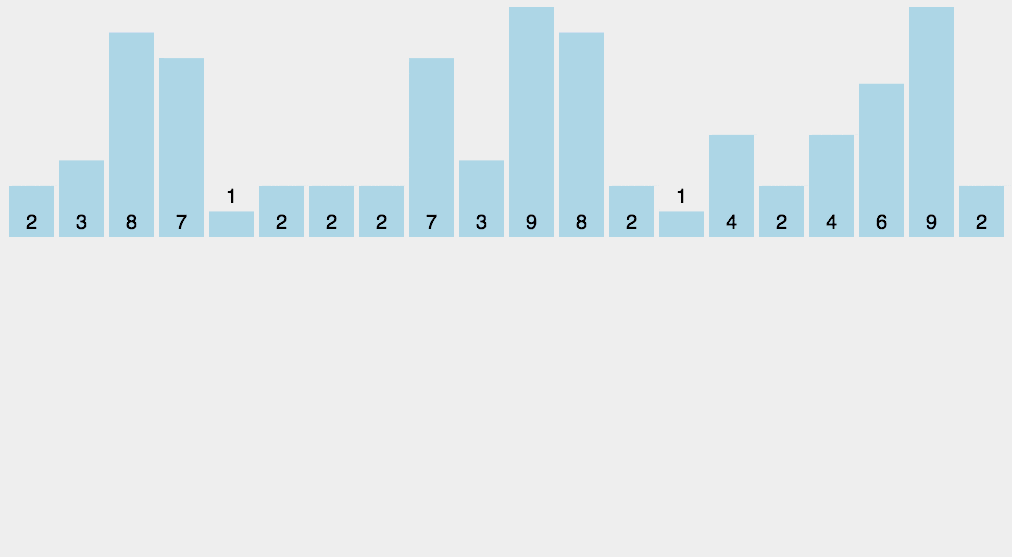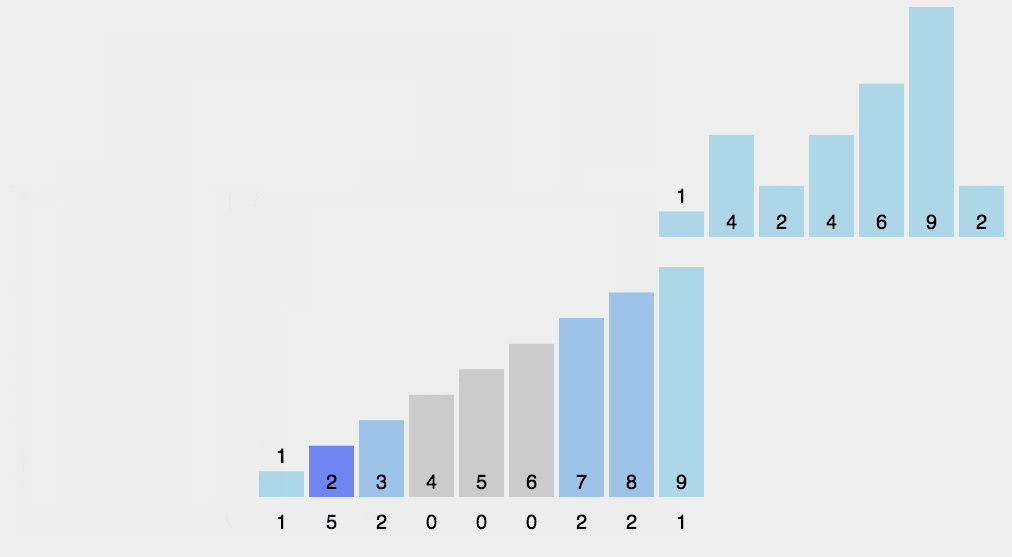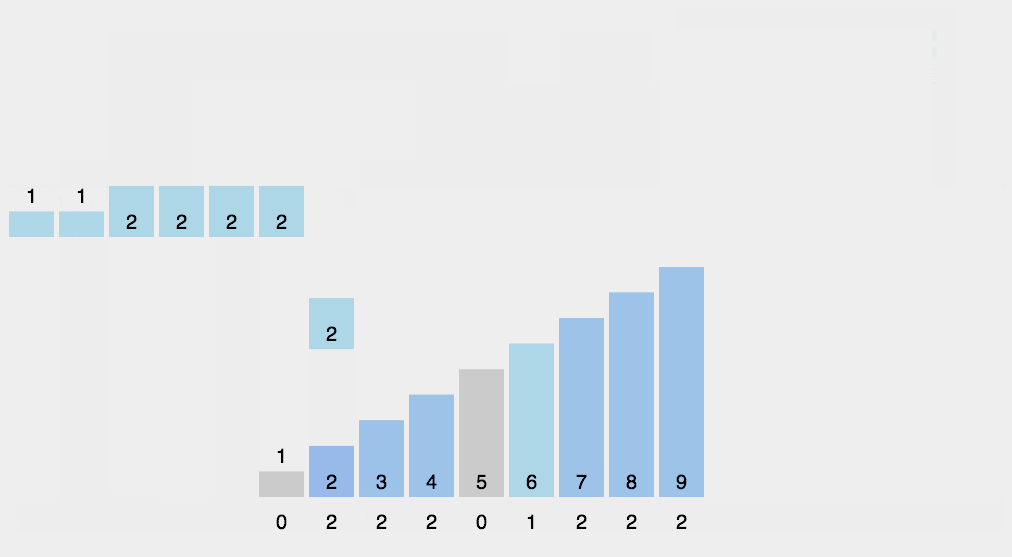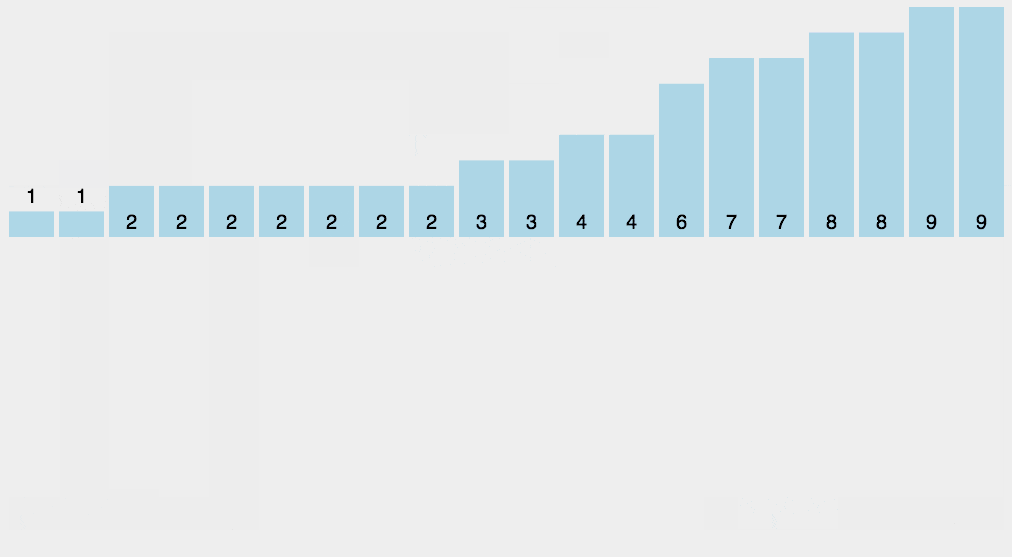
13.3、计数排序代码实现
代码
public class CountingSort {
public static void main(String[] args) {
int []num ={7,4,9,3,2,1,8,6,5,10};
long startTime=System.currentTimeMillis();
int min=Integer.MAX_VALUE;
int max=Integer.MIN_VALUE;
//先找出数组中的最大值与最小值
for(int i=0;i<num.length;i++) {
if(num[i]<min)
min=num[i];
if(num[i]>max)
max=num[i];
}
//创建一个长度为max-min+1长度的数组来进行计数
int []figure=new int [max-min+1];
for(int i=0;i<num.length;i++) {
//计算每个数据出现的次数
figure[num[i]-min]++;
}
int begin=0;
//创建一个新的数组来存储已经排序完成的结果
int []num1=new int [num.length];
for(int i=0;i<figure.length;i++) {
//循环将数据pop出来
if(figure[i]!=0) {
for(int j=0;j<figure[i];j++) {
num1[begin++]=min+i;
}
}
}
System.out.println("数据范围:"+min+"~"+max);
System.out.println("计数结果: ");
for(int i=0;i<num.length;i++)
System.out.println(" "+num[i]+"出现"+figure[num[i]-min]+"次");
System.out.print("排序结果: ");
for(int i=0;i<num1.length;i++)
System.out.print(num1[i]+" ");
System.out.println();
long endTime=System.currentTimeMillis();
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
}
}
结果:

14、堆排序
14.1、堆排序简介
1.堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为 O(nlogn),它 是不稳定排序。
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大根堆(或大顶堆), 注意 : 没有
要求结点的左孩子的值和右孩子的值的大小关系。每个结点的值都小于或等于其左右孩子结点的值,称为小根堆(或小顶堆)
一般升序采用大根堆,降序采用小根堆


14.2、堆排序过程演示
堆排序的基本思想是:
- 将待排序序列构造成一个大根堆
- 此时,整个序列的最大值就是堆顶的根节点。
- 将其与末尾元素进行交换,此时末尾就为最大值。
- 然后将剩余 n-1 个元素重新构造成一个堆,这样会得到 n 个元素的次小值。如此反复执行,便能得到一个有序
序列了。
步骤图解
要求:给你一个数组 {4,6,8,5,9} , 要求使用堆排序法,将数组升序排序。
- 步骤一 构造初始堆。将给定无序序列构造成一个大根堆(一般升序采用大根堆,降序采用小根堆)。
- 原始的数组 [4, 6, 8, 5, 9]
- .假设给定无序序列结构如下
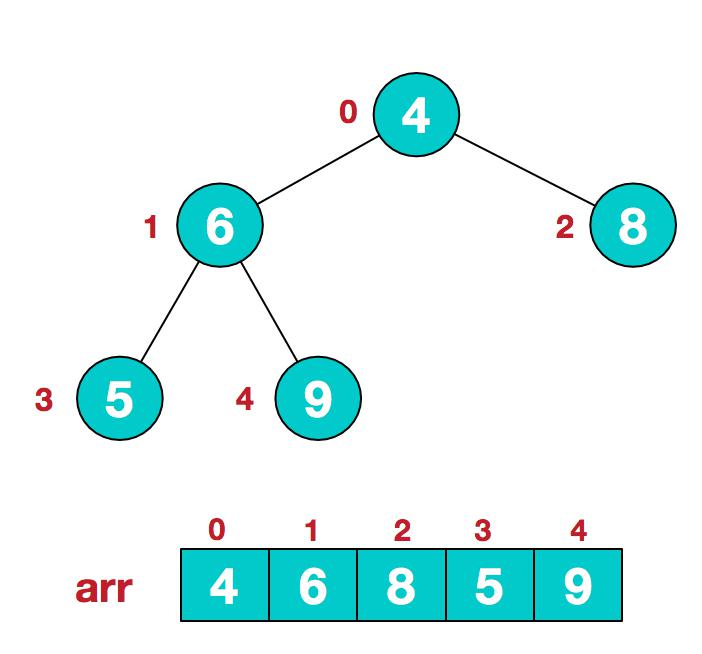
- .此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点
arr.length/2-1=5/2-1=1,也就是下面的 6 结点),从左至右,从下至上进行调整。
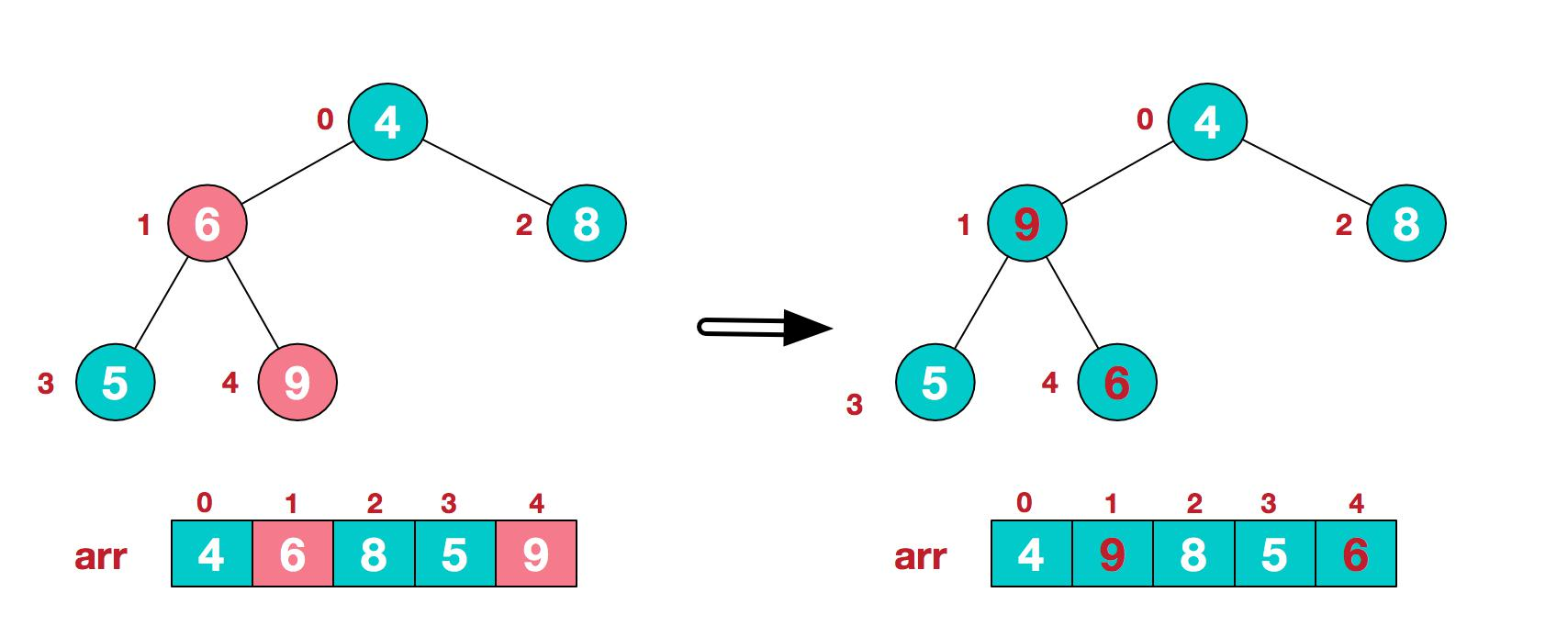
3.找到第二个非叶节点 4,由于[4,9,8]中 9 元素最大,4 和 9 交换。
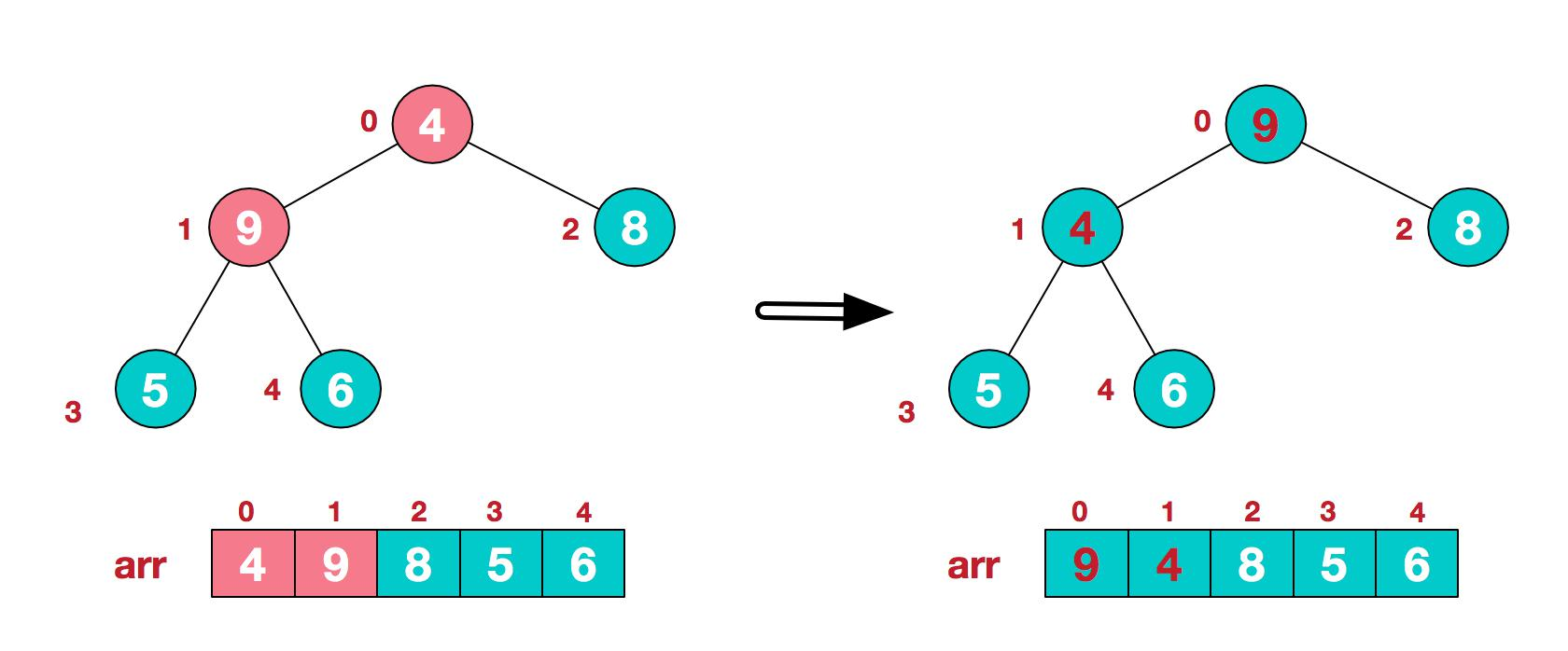
4.这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中 6 最大,交换 4 和 6。
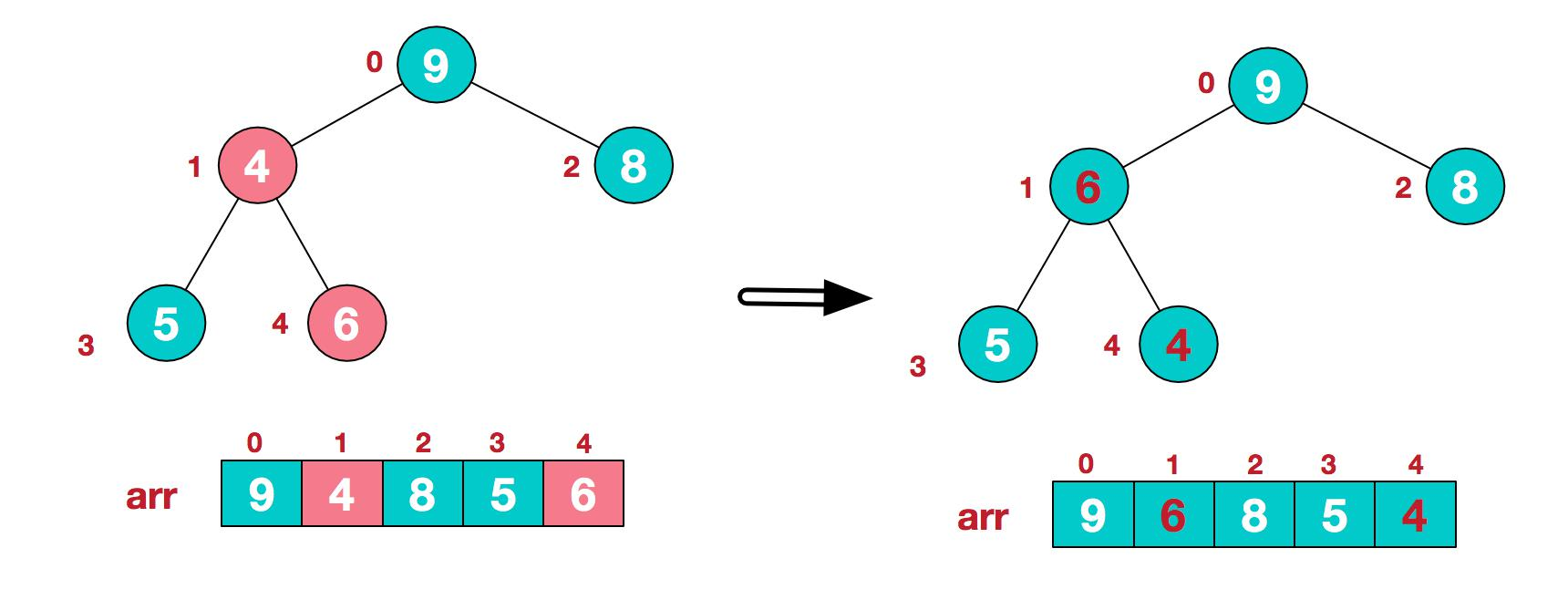
此时,我们就将一个无序序列构造成了一个大顶堆.
- 步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换得到第二大元素。如此反复进行交换、重建、交换
1.将堆顶元素 9 和末尾元素 4 进行交换
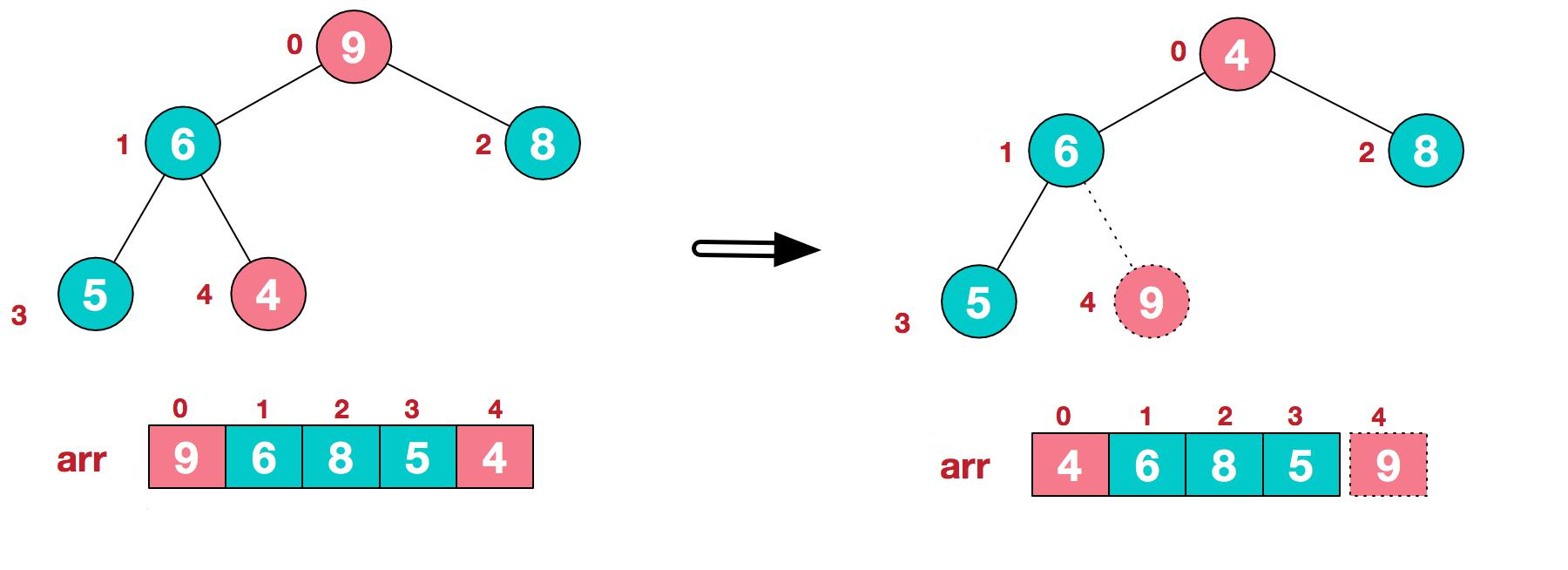
2.重新调整结构,使其继续满足堆定义
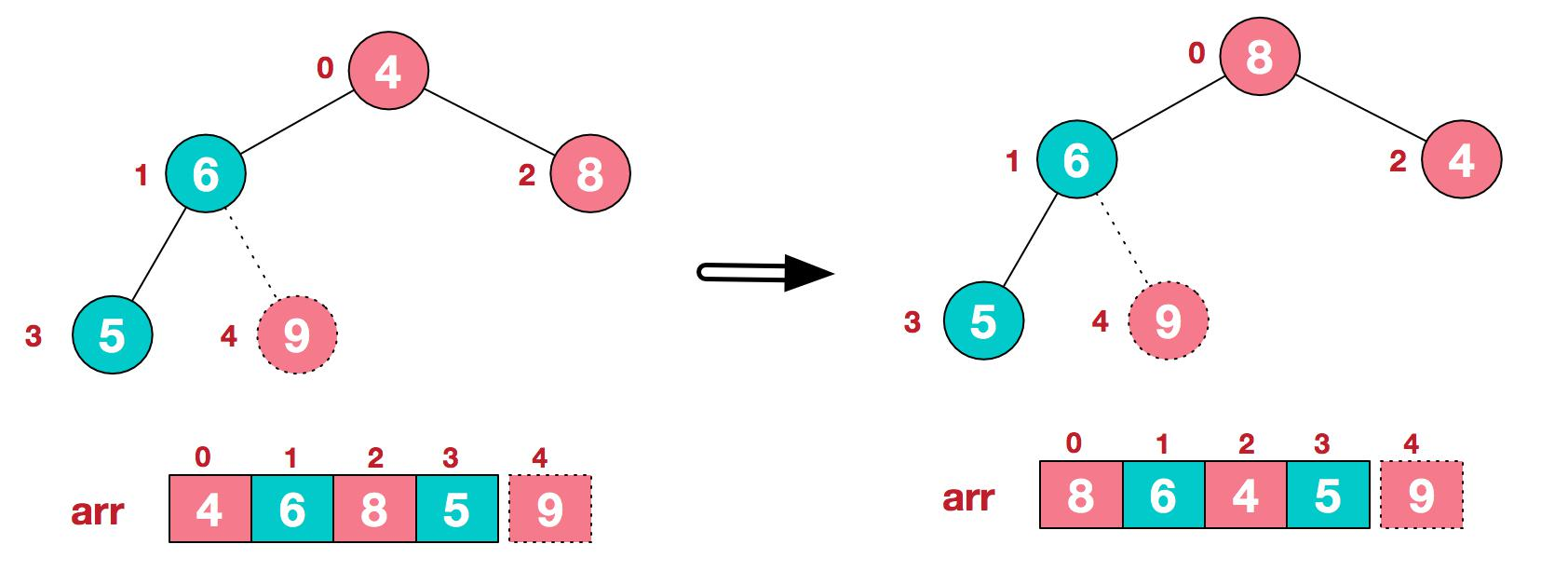
3.再将堆顶元素 8 与末尾元素 5 进行交换,得到第二大元素 8

4.后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
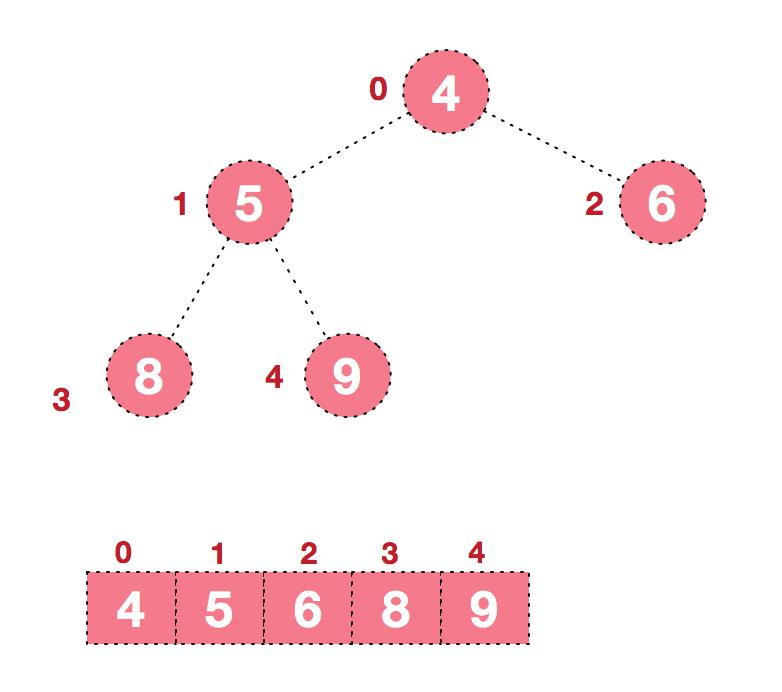
动态演示

再简单总结下堆排序的基本思路:
1).将无序序列构建成一个堆,根据升序降序需求选择大根堆或小根堆;
2).将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序
14.3、堆排序代码实现
堆排序的理解还是比较困难的,尤其是代码实现过程,下面提供两种代码实现,大家可以选择适合自己的实现方法来理解堆排序
代码实现(一)
import java.util.Arrays;
public class HeapSort {
public static void main(String[] args) {
//升序--->大顶堆
long startTime=System.currentTimeMillis();
int arr[] = {5,3,7,1,4,6,2};
heapSort(arr);
long endTime=System.currentTimeMillis();
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
}
//编写一个堆排序的方法
public static void heapSort(int arr[]) {
int temp = 0;
//完成我们最终代码
//将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆
for(int i = arr.length / 2 -1; i >=0; i--) {
adjustHeap(arr, i, arr.length);
}
/*
* 2).将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
*/
for(int j = arr.length-1;j >0; j--) {
//交换
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr, 0, j);
}
System.out.println("数组=" + Arrays.toString(arr));
}
//将一个数组(二叉树), 调整成一个大顶堆
/**
* 功能: 完成 将 以 i 对应的非叶子结点的树调整成大顶堆
* 举例 int arr[] = {4, 6, 8, 5, 9}; => i = 1 => adjustHeap => 得到 {4, 9, 8, 5, 6}
* 如果我们再次调用 adjustHeap 传入的是 i = 0 => 得到 {4, 9, 8, 5, 6} => {9,6,8,5, 4}
* @param arr 待调整的数组
* @param i 表示非叶子结点在数组中索引
* @param length 表示对多少个元素继续调整, length 是在逐渐的减少
*/
public static void adjustHeap(int arr[], int i, int length) {
int temp = arr[i];//先取出当前元素的值,保存在临时变量
//开始调整
//说明
//1. k = i * 2 + 1 k 是 i结点的左子结点
for(int k = i * 2 + 1; k < length; k = k * 2 + 1) {
if(k+1 < length && arr[k] < arr[k+1]) { //说明左子结点的值小于右子结点的值
k++; // k 指向右子结点
}
if(arr[k] > temp) { //如果子结点大于父结点
arr[i] = arr[k]; //把较大的值赋给当前结点
i = k; //!!! i 指向 k,继续循环比较
} else {
break;//!
}
}
//当for 循环结束后,我们已经将以i 为父结点的树的最大值,放在了 最顶(局部)
arr[i] = temp;//将temp值放到调整后的位置
}
}
结果:
代码实现(二)
//交换数组中的元素
public static void swap(int[]num ,int i,int j) {
int temp=num[i];
num[i]=num[j];
num[j]=temp;
}
//将待排序的数组构建成大根堆
public static void buildbigheap(int []num,int end) {
//从最后一个非叶子节点开始构建,依照从下往上,从右往左的顺序
for(int i=end/2;i>=0;i--) {
adjustnode(i, end, num);
}
}
//调整该节点及其以下的所有节点
public static void adjustnode(int i,int end,int []num) {
int left=2*i+1;
int right=2*i+2;
int big=i;
//判断小分支那个是大元素
if(left<end&&num[i]<num[left])
i=left;
if(right<end&&num[i]<num[right])
i=right;
if(i!=big) {
//交换顺序之后需要继续校验
swap(num, i, big);
//重新校验,防止出现交换之后根节点小于孩子节点的情况
adjustnode(i, end, num);
}
}
public static void main(String[] args) {
int []num ={5,3,7,1,4,6,2};
long startTime=System.currentTimeMillis();
//第一次构建大根堆
buildbigheap(num, num.length);
for(int j=num.length-1;j>0;j--) {
System.out.print("第"+(num.length-j)+"次排序前: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
//交换队头已经排序得到的最大元素与队尾元素
swap(num, 0, j);
System.out.print("第"+(num.length-j)+"次排序后: ");
for(int k=0;k<num.length;k++) {
System.out.print(num[k]+" ");
}
System.out.println();
//交换结束之后,大根堆已经被破坏,需要开始重新构建大根堆
buildbigheap(num,j);
}
long endTime=System.currentTimeMillis();
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
}
结果:

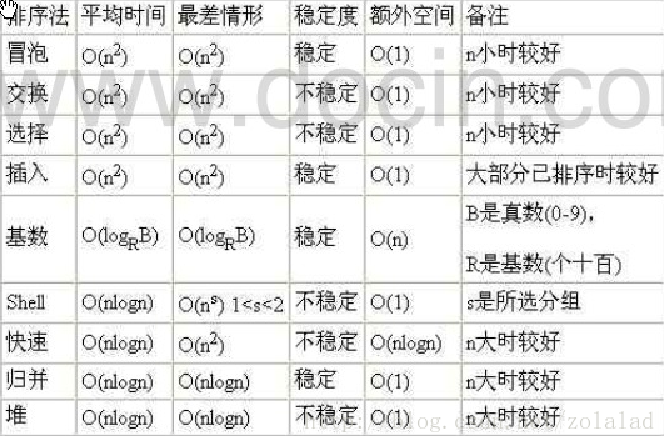
15、十大排序算法总结
15.1、十大排序算法分类
(1)按照是否是比较算法分类
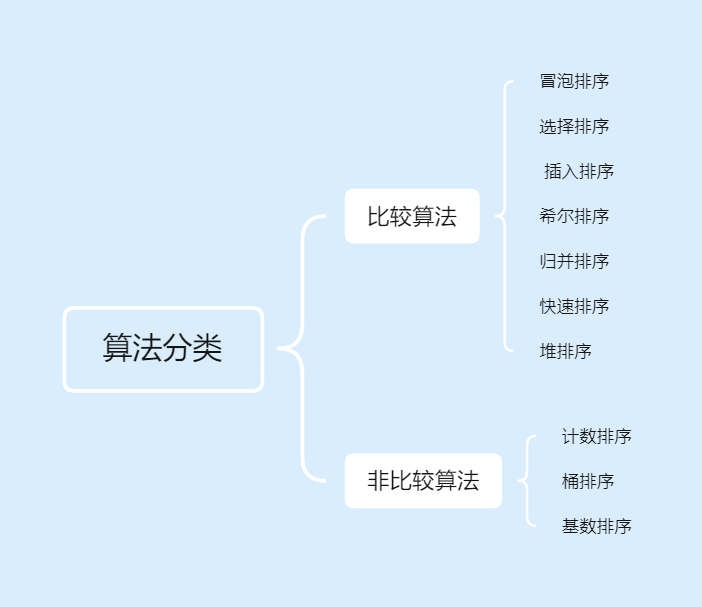
(2)按照算法是否稳定分类
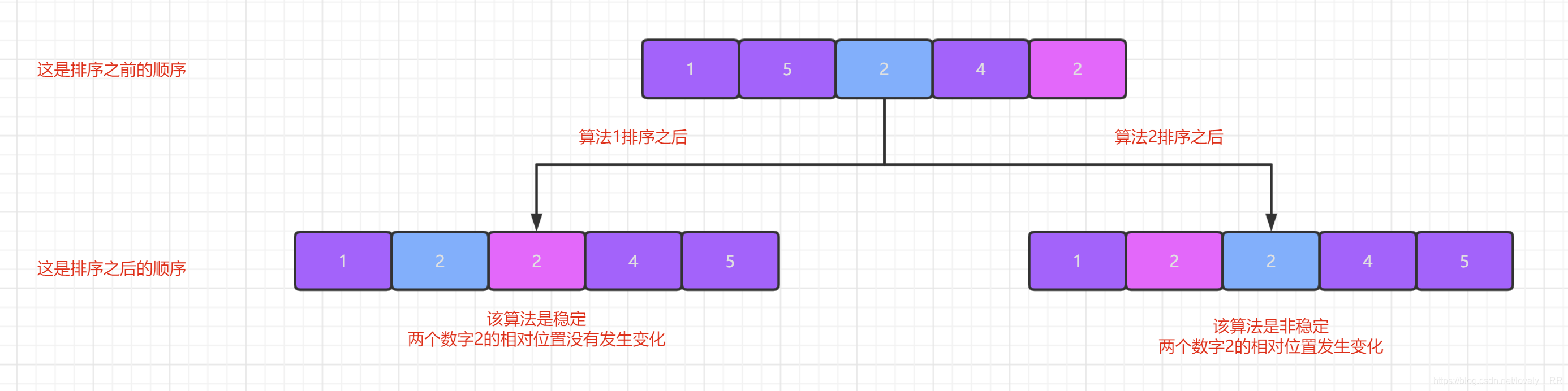
如何区分算法是否稳定?
通俗来讲就是数据相对于原来的相对位置没有发生变化

15.2、十大算法的平均时间复杂度
下面这张图说明了各个排序算法的时间复杂度等各项衡量算法的指标,希望大家记住!!!
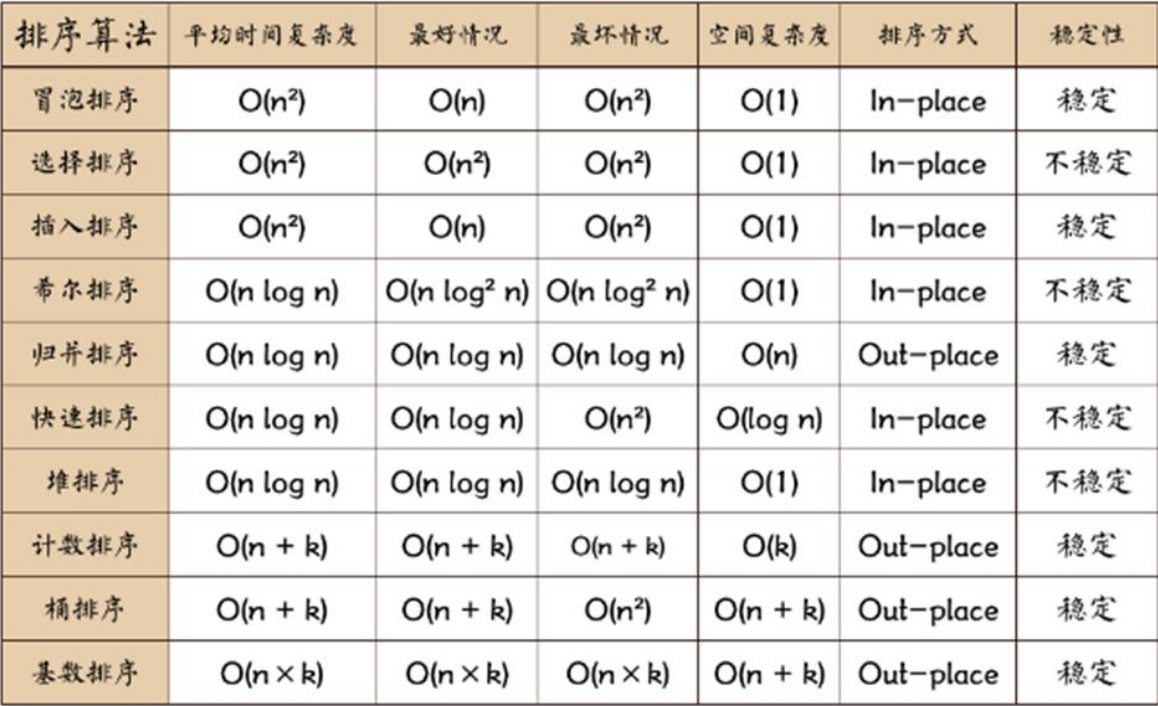
术语解释:
1)稳定:如果 a 原本在 b 前面,而 a=b,排序之后 a 仍然在 b 的前面;
2) 不稳定:如果 a 原本在 b 的前面,而 a=b,排序之后 a 可能会出现在 b 的后面;
3) 内排序:所有排序操作都在内存中完成;
4) 外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
5) 时间复杂度: 一个算法执行所耗费的时间。
6) 空间复杂度:运行完一个程序所需内存的大小。
7) n: 数据规模
8) k: “桶”的个数
9) In-place: 不占用额外内存
10) Out-place: 占用额外内存
到这里关于十大排序算法的知识到这里就结束了,最后推荐一个数据结构动态可视化的网站帮助大家学习数据结构与算法https://visualgo.net/zh,
排序算法在数据结构与算法中十分重要,虽然有一些排序算法晦涩难懂,但是算法学习是一个持续的过程,大家一定不要放弃
,相信在大家的不断学习过程中一定能将这些算法掌握,希望这篇文章对大家学习有所帮助(๑•̀ㅂ•́)و✧
数据结构与算法【Java】05---排序算法总结的更多相关文章
- 算法 | Java 常见排序算法(纯代码)
目录 汇总 1. 冒泡排序 2. 选择排序 3. 插入排序 4. 快速排序 5. 归并排序 6. 希尔排序 6.1 希尔-冒泡排序(慢) 6.2 希尔-插入排序(快) 7. 堆排序 8. 计数排序 9 ...
- Java常用排序算法+程序员必须掌握的8大排序算法+二分法查找法
Java 常用排序算法/程序员必须掌握的 8大排序算法 本文由网络资料整理转载而来,如有问题,欢迎指正! 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排 ...
- Java 常用排序算法/程序员必须掌握的 8大排序算法
Java 常用排序算法/程序员必须掌握的 8大排序算法 分类: 1)插入排序(直接插入排序.希尔排序) 2)交换排序(冒泡排序.快速排序) 3)选择排序(直接选择排序.堆排序) 4)归并排序 5)分配 ...
- java:高速排序算法与冒泡排序算法
Java:高速排序算法与冒泡算法 首先看下,冒泡排序算法与高速排序算法的效率: 例如以下的是main方法: /** * * @Description: * @author:cuiyaon ...
- Java八大排序算法
Java八大排序算法: package sort; import java.util.ArrayList; import java.util.Arrays; import java.util.List ...
- Java常用排序算法及性能测试集合
测试报告: Array length: 20000 bubbleSort : 573 ms bubbleSortAdvanced : 596 ms bubbleSortAdvanced2 : 583 ...
- Java各种排序算法
Java各种排序算法详解 排序大的分类可以分为两种:内排序和外排序.在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序.下面讲的排序都是属于内排序. 内排序有 ...
- 插入排序算法--直接插入算法,折半排序算法,希尔排序算法(C#实现)
插入排序算法主要分为:直接插入算法,折半排序算法(二分插入算法),希尔排序算法,后两种是直接插入算法的改良.因此直接插入算法是基础,这里先进行直接插入算法的分析与编码. 直接插入算法的排序思想:假设有 ...
- java 各种排序算法
各种排序算法的分析及java实现 排序一直以来都是让我很头疼的事,以前上<数据结构>打酱油去了,整个学期下来才勉强能写出个冒泡排序.由于下半年要准备工作了,也知道排序算法的重要性(据说 ...
- Java各种排序算法详解
排序大的分类可以分为两种:内排序和外排序.在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序.下面讲的排序都是属于内排序. 内排序有可以分为以下几类: (1).插 ...
随机推荐
- ABP框架之——数据访问基础架构(下)
大家好,我是张飞洪,感谢您的阅读,我会不定期和你分享学习心得,希望我的文章能成为你成长路上的一块垫脚石,我们一起精进. EF Core集成 EF Core是微软的ORM,可以使用它与主流的数据库提供商 ...
- 十分钟快速实战Three.js
前言 本文不会对Three.js几何体.材质.相机.模型.光源等概念详细讲解,会首先分成几个模块给大家快速演示一盒小案例.大家可以根据这几个模块快速了解Three.js的无限魅力.学习 我们会使用Th ...
- skywalking链路监控
1. 下载安装包官网地址:http://skywalking.apache.org/downloads/ 2. tar xzf apache-skywalking-apm-6.5.0.tar.gz - ...
- raid划分及创建
RAID 的划分 RAID 0 - RAID 0是最早出现的,是数据分条技术.组建磁盘阵列中最简单的一种形式,可以提高整个磁盘的性能和吞吐量,利用率100%,缺点:一但磁盘损坏,raid0将失效,数据 ...
- Tapdata 实时数据中台在智慧教育中的实践
摘要:随着教育信息化的推进,智慧校园建设兴起,但在实施过程中面临数据孤岛.应用繁多.数据再利用等方面挑战,而 Tapdata 的实时数据中台解决方案,能够高效地解决智慧校园实施中的基础数据问题. ...
- 可变参数和Collections集合工具类的方法_addAll&shuffle
可变参数 可变参数:是JDK1.5之后出现的新特性 使用前提:当方法的参数列表数据类型已经确定,但是参数的个数不确定,就可以使用可变参数 使用格式:定义方法时使用 ~修饰符 返回值类型 方法名(数据类 ...
- 练习-使用日期时间相关的API ,计算出一个人已经出生了多长时间
程序分析:(1)使用Scanner类获取出生日期(2)使用DataFormat类中的方法parse,把字符串的出生日期解析为Data格式的出生日期(3)把Data格式的出生日期转化为毫秒值(4)获取当 ...
- Deep Learning-深度学习(一)
深度学习入门 1.人工智能.机器学习.深度学习 1.1 人工智能(AI) 一个比较宽泛的概念.即用来模拟人的智能的理论,并对这个模拟出来的智能进行延伸和开拓.通俗来讲就是要达到用机器模拟人类的聪慧来处 ...
- Mac安装 Scrapy 报错 No local packages or working download links found for incremental>=16.10.1
证书原因: wget http://curl.haxx.se/ca/cacert.pem mv cacert.pem ca-bundle.crt sudo mkdir -p /etc/pki/tls/ ...
- SQLZOO练习5--join(表的连接)
game表: id mdate stadium team1 team2 1001 8 June 2012 National Stadium, Warsaw POL GRE 1002 8 June 20 ...