Flask 之 高可用IP代理网站
高可用代理IP网站
目标:提供高可用代理IP
步骤一:通过爬虫获取代理IP
步骤二:对代理IP进行检测,判断代理是否可用
步骤三:将可用的代理IP写入mongodb数据库
步骤四:创建网站,从数据库获取代理IP显示到网页中
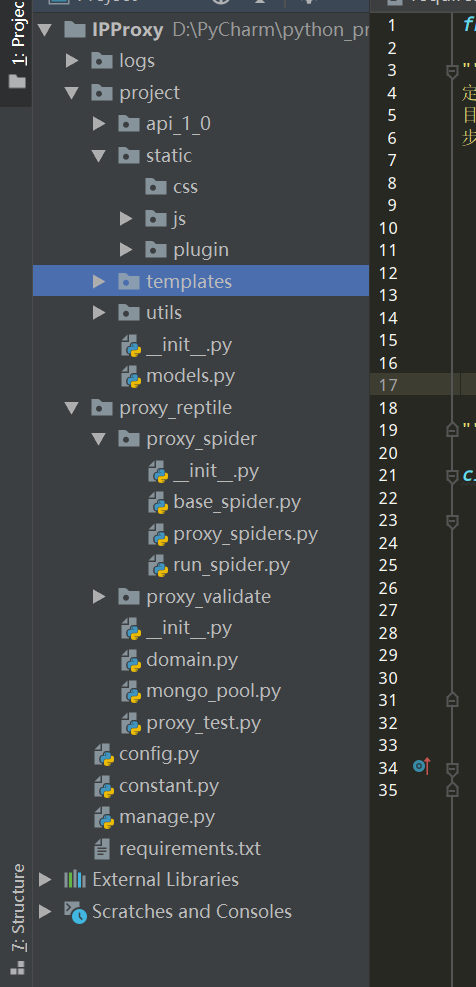
IPProxy 项目目录
|---logs 日志目录
|---project Flask项目目录
|---api_1_0 flask蓝图目录
|---static 静态文件目录
|---templates 模板文件目录
|---utils 工具类
|---__init__ Flask初始化配置文件
|---proxy_reptile 爬虫项目目录
|---proxy_spider 爬虫目录
|---proxy_validate 代理检测目录
|---domain.py 代理IP数据模型类
|---mongo_pool.py mongoDB数据库
|---proxy_test.py 代理检测文件
|---config.py 配置文件
|---constant.py 常量文件
|---manage.py 启动文件
一、Flask框架项目准备
项目步骤参考:Python Flask项目步骤
主要是该项目采用mongodb数据库
在配置数据库的时候改为mongodb
# 数据库
MONGO_URI = "mongodb://127.0.0.1:27017/proxies_pool"
二、定义代理IP的数据模型类
1.定义Proxy类,继承object
2.通过`__init__`方法,初始化
ip:代理ip地址
port:代理ip端口
protocol:代理ip支持的协议类型(http:0;https:1;https和http都支持是2)
nick_type:代理ip的匿名程度(高匿:0,匿名:1,透明:2)
speed:代理IP的响应速度,单位s
area:代理ip所在地区
score:代理ip的评分,用于衡量代理的可用性;默认分值可以通过配置文件进行配置,在进行代理可 用性检测,遇到一次请求失败减1,减到0的时候删除
3. 提供__str__方法,返回字符串
创建domain.py 文件,用于定义代理IP的数据模型类
from constant import MAX_SCORE
# 常量文件 constant.py 中定义MAX_SCORE = 50,表示代理IP的默认最高分数
class Proxy(object):
def __init__(self, ip, port, protocol=-1, nick_type=-1, speed=-1, area=None, score=MAX_SCORE):
self.ip = ip
self.port = port
self.protocol = protocol
self.nick_type = nick_type
self.speed = speed
self.area = area
self.score = score
def __str__(self):
return str(self.__dict__)
三、定义mongodb模块
目的:对代理ip的数据模型类(proxies)集合进行相关操作
基础功能:
1.提供基础的正删改查功能
1.实现插入功能
2.实现修改功能
3.实现删除功能
4.查询所以代理ip功能
2.提供代理ip的api模块功能
1.实现查询功能:根据条件查询,可以指定数量,先按分数降序,速度按升序排,保证优质的代理IP在上面
2.实现根据协议类型 和 访问网站域名,获取代理ip列表
3.实现根据协议类型 和 访问网站域名,随机获取代理IP
在proxy_reptile文件夹下创建 mongo_pool.py 文件
import random
import pymongo
from project import db
from project.utils.log import logger
from .domain import Proxy
class MongoPool(object):
def __init__(self):
self.proxies = db.db.proxies
def insert_one(self, proxy):
"""实现插入功能"""
# 判断数据库是否存在该数据
count = self.proxies.count_documents({'_id': proxy.ip})
if count == 0:
# 使用proxy.ip作为,mongodb中数据的主键:_id
dic = proxy.__dict__
dic['_id'] = proxy.ip
self.proxies.insert_one(dic)
logger.info('插入新的代理:{}'.format(proxy))
else:
logger.warning('已存在的代理:{}'.format(proxy))
def update_one(self, proxy):
"""实现更新功能"""
self.proxies.update_one({'_id': proxy.ip}, {'$set': proxy.__dict__})
def delete_one(self, proxy):
"""实现删除功能"""
self.proxies.delete_one({'_id': proxy.ip})
logger.info('删除的代理:{}'.format(proxy))
def find_all(self):
"""查询所有代理ip"""
cursor = self.proxies.find()
for item in cursor:
# 删除_id
item.pop('_id')
proxy = Proxy(**item)
yield proxy
def find(self, conditions={},page=1,count=0):
"""
1.实现查询功能:根据条件查询,可以指定数量,先按分数降序,速度按升序排,保证优质的代理IP在上面
:param conditions: 查询条件字典
:param count:限制取出多少个代理ip
:return:返回满足要求的代理ip列表
"""
cursor = self.proxies.find(conditions, skip=(page-1)*count,limit=count).sort(
[('score', pymongo.DESCENDING), ('speed', pymongo.ASCENDING)])
total = self.proxies.find(conditions).count()
# 准备列表,用于存储查询的代理IP
proxy_list = []
for item in cursor:
item.pop("_id")
proxy = Proxy(**item)
proxy_list.append(proxy)
return proxy_list,total
def get_proxies(self, protocol=None, domains=None, count=0, nick_type=0):
"""
2.实现根据协议类型 和 访问网站域名,获取代理ip列表
:param protocol: 协议http或https
:param domains: 域名:jd.com
:param count: 限制获取多个代理ip,默认获得所有
:param nick_type: 匿名类型,默认获取高匿代理
:return: 代理ip
"""
# 定义查询条件
conditions = {"nick_type": nick_type}
# 根据协议查询条件
if protocol is None:
# 没有传入协议类型,返回即支持http又支持https
conditions['protocol'] = 2
elif protocol.lower() == 'http':
conditions['protocol'] = {'$in': [0, 2]}
else:
conditions['protocol'] = {'$in': [1, 2]}
if domains:
conditions['disable_domains'] = {'$nin': [domains]}
return self.proxies.find(conditions, count=count)
def random_proxy(self, protocol=None, domains=None, count=0, nick_type=0):
"""
3.实现根据协议类型 和 访问网站域名,随机获取代理IP
:param protocol: 协议http或https
:param domains: 域名:jd.com
:param count: 限制获取多个代理ip,默认获得所有
:param nick_type: 匿名类型,默认获取高匿代理
:return: 代理ip
"""
proxy_list = self.get_proxies(protocol=protocol, domains=domains, count=count, nick_type=nick_type)
return random.choice(proxy_list)
四、爬取代理IP
目标网站 :
对目标网站分析:

通过对几个网站的数据分析,其结构基本相同,因此编写通用的爬虫类,通过对类的继承来爬取不同网站的数据。
1.编写通用爬虫类
在proxy_reptile爬虫项目下的proxy_spider的base_spider.py文件编写通用爬虫类。
import requests
from lxml import etree
from project.utils.http import get_request_headers # 获取随机请求头
from proxy_reptile.domain import Proxy # ip代理数据模型类
class BaseSpider(object):
# 1.urls: 代理ip网址的url列表
urls = []
# 2.group_xpath:分组xpath,获取包含代理ip信息标签列表的xpath
group_xpath = ""
# 3.detail_xpath:组内xpath,获取代理ip详情的信息xpath,格式为 {'ip': 'xx', 'port': 'xx', 'area': 'xx'}
detail_xpath = {}
def __init__(self, urls=None, group_xpath=None, detail_xpath=None):
if urls:
self.urls = urls
if group_xpath:
self.group_xpath = group_xpath
if detail_xpath:
self.detail_xpath = detail_xpath
def get_proxies(self):
for url in self.urls:
page = self.get_page_from_url(url)
proxies = self.get_proxies_from_page(page)
# 返回Proxy对象的生成器
yield from proxies
def get_page_from_url(self, url):
"""根据url发送请求"""
response = requests.get(url, headers=get_request_headers())
return response.content
def get_proxies_from_page(self, page):
"""解析页面,提取数据,封装Proxy对象返回"""
element = etree.HTML(page)
# 获取包含代理IP的标签列表
trs = element.xpath(self.group_xpath)
# 遍历trs,获取代理ip相关信息
for tr in trs:
ip = self.get_first_from_list(tr.xpath(self.detail_xpath['ip']))
print(ip)
port = self.get_first_from_list(tr.xpath(self.detail_xpath['port']))
area = self.get_first_from_list(tr.xpath(self.detail_xpath['area']))
proxy = Proxy(ip,port=port,area=area)
# 使用yield返回生成器
yield proxy
def get_first_from_list(self,lis):
"""如果列表有元素则返回第一个否则为空字符串"""
return lis[0] if len(lis) != 0 else ''
2.继承通用爬虫类,对不同目标网站进行修改
在proxy_reptile爬虫项目下的proxy_spider的proxy_spiders.py文件继承通用爬虫,对不同网站进行编写。
from proxy_reptile.proxy_spider.base_spider import BaseSpider
import time
import random
"""
1.高可用全球免费代理爬虫
url:https://ip.jiangxianli.com/?page=1
"""
class QuanqiuSpider(BaseSpider):
urls = ['https://ip.jiangxianli.com/?page={}'.format(i) for i in range(1,9)]
# 分组xpath,获取分组代理IP信息
group_xpath = '/html/body/div[1]/div[2]/div[1]/div[1]/table/tbody/tr'
detail_xpath = {
'ip': './td[1]/text()',
'port': './td[2]/text()',
'area': './td[6]/text()'
}
"""
2.云免费代理爬虫
url:http://www.ip3366.net/free/?stype=1&page=1
"""
class YunSpider(BaseSpider):
urls = ['http://www.ip3366.net/free/?stype=1&page={}'.format(i) for i in range(1, 8)]
# 分组xpath,获取分组代理IP信息
group_xpath = '//div[@id="list"]/table/tbody/tr'
detail_xpath = {
'ip':'./td[1]/text()',
'port':'./td[2]/text()',
'area':'./td[5]/text()'
}
"""
3.快免费代理爬虫
url:https://www.kuaidaili.com/free/inha/1/
"""
class KuaiSpider(BaseSpider):
urls = ['https://www.kuaidaili.com/free/inha/{}/'.format(i) for i in range(1, 6)]
# 分组xpath,获取分组代理IP信息
group_xpath = '//*[@id="list"]/table/tbody/tr'
detail_xpath = {
'ip':'./td[1]/text()',
'port':'./td[2]/text()',
'area':'./td[5]/text()'
}
# 页面访问时间间隔太短,反爬措施
def get_page_from_url(self,url):
# 随机等待1,3s
time.sleep(random.uniform(1,3))
# 调用父类方法
return super().get_page_from_url(url)
"""
4.89费代理爬虫
url:https://ip.jiangxianli.com/?page=1
"""
class ENSpider(BaseSpider):
urls = ['https://www.7yip.cn/free/?action=china&page={}'.format(i) for i in range(1, 7)]
# 分组xpath,获取分组代理IP信息
group_xpath = '//*[@id="content"]/section/div[2]/table/tbody/tr'
detail_xpath = {
'ip':'./td[1]/text()',
'port':'./td[2]/text()',
'area':'./td[5]/text()'
}
if __name__ == '__main__':
""" 测试能否使用"""
# spider = ENSpider()
spider = YunSpider()
# spider = KuaiSpider()
# spider = QuanqiuSpider()
i = 0
for proxy in spider.get_proxies():
i = i + 1
print(proxy)
print(i)
3.对代理ip进行检测(ip速度,ip匿名程度,以及支持的协议类型)
1.检查代理IP速度 和 匿名程度
1).代理IP速度,就是发送请求到获取响应的时间间隔
2).匿名程度检查:
1.对 http://httpbin.org/get 或 https://httpbin.org/get 发送请求
2. 如果响应的 origin 中有 '.' 分隔的两个ip就是透明代理ip
3. 如果响应的headers 中包含 Proxy-Connection 就是匿名代理IP
4.否则就是高匿代理ip
2.检查代理ip协议类型
1). 如果 http://httpbin.org/get 发送请求成功,说明支持http协议
2). 如果 https://httpbin.org/get 发送请求成功,说明支持https协议
import requests
import time
import json
import constant
from project.utils.http import get_request_headers
def check_proxy(proxy):
"""
检查代理协议类型,匿名程度
:param proxy:
:return: (
protocol协议:
http和https:2;
https:1;
http:0
nick_type匿名程度:
高匿:0;
匿名:1;
透明:2;
speed速度:单位s
)
"""
# 根据proxy对象构造,请求使用代理
proxies = {
'http':'http://{}:{}'.format(proxy.ip,proxy.port),
'https':'https://{}:{}'.format(proxy.ip,proxy.port)
}
http, http_nick_type, http_speed = _check_http_proxy(proxies)
https, https_nick_type, https_speed = _check_http_proxy(proxies, False)
if http and https:
# 如果http和https都可以请求成功,说明支持http也支持https,协议类型为2
proxy.protocol = 2
proxy.nick_type = http_nick_type
proxy.speed = http_speed
elif http:
# 如果只有http请求成功,说明支持http协议,协议类型为0
proxy.protocol = 0
proxy.nick_type = http_nick_type
proxy.speed = http_speed
elif https:
# 如果只有https请求成功,说明支持http协议,协议类型为1
proxy.protocol = 1
proxy.nick_type = https_nick_type
proxy.speed = https_speed
else:
proxy.protocol = -1
proxy.nick_type = -1
proxy.speed = -1
# logger.info(proxy)
return proxy
def _check_http_proxy(proxies,isHttp=True):
nick_type = -1
speed = -1
if isHttp:
test_url ='http://httpbin.org/get'
else:
test_url = 'https://httpbin.org/get'
try:
start =time.time()
res =requests.get(url=test_url,headers = get_request_headers(),timeout=constant.TEST_TIMEOUT,proxies=proxies)
if res.ok:
# 计算响应速度,保留两位小数
speed = round(time.time()-start,2)
# 把响应内容转为字典
content =json.loads(res.text)
# 获取请求头
headers = content['headers']
# 获取origin,请求来源IP地址
ip = content['origin']
# 获取请求头中 ’Proxy-Connection‘,如果有,说明是匿名代理
proxy_connection = headers.get('Proxy-Connection', None)
if ',' in ip:
# 如果响应的 origin 中有 ',' 分隔的两个ip就是透明代理ip
nick_type = 2 # 透明
elif proxy_connection:
nick_type = 1 # 匿名
else:
nick_type = 0 # 高匿
return True,nick_type,speed
else:
return False, nick_type, speed
except Exception as e:
# logger.exception(e)
return False,nick_type,speed
4.运行爬虫模块
运行爬虫,实现对IP代理的爬取,校验以及保存。
在proxy_reptile爬虫项目下的proxy_spider的run_spiders.py文件,编写运行爬虫模块
# 导入协程池
from gevent.pool import Pool
# 猴子补丁
from gevent import monkey
monkey.patch_all()
# 导入检测模块
import schedule
import time
import importlib
from proxy_reptile.mongo_pool import MongoPool
from project.utils.log import logger
from proxy_reptile.proxy_validate.httpbin_validator import check_proxy
from constant import PROXIES_SPIDERS,RUN_SPIDERS_INTERVAL
"""
实现运行爬虫模块
目标:根据配置文件信息,加载爬虫,抓取代理IP,进行校验,如果可用,写入数据库
1. 在run_spiders.py中,创建RunSpider类
2.提供运行爬虫run方法,作为运行爬虫入口
1.根据配置文件信息,获取爬虫对象列表
2.遍历爬虫对象列表,获取爬虫对象,遍历爬虫对象的get_proxies方法
3.检测代理IP
4.如果可用写入数据库
5.异常处理,防止爬虫出错
3.使用异步执行每一个爬虫任务,提高抓取代理ip效率
1.在init创建协程池对象
2.把处理一个代理爬虫的代码抽到一个方法
3.使用异步执行这个方法
4.调用协程的join方法,让当前线程等待 协程 任务
4.使用schedule模块,实现每隔一段时间,执行一次爬虫任务
1.定义一个start类方法
2.创建当前对象,调用run方法
3.使用schedule模块,每隔一段时间执行对象run
"""
class RunSpider(object):
def __init__(self):
# 创建MongoPool对象
self.mongo_pool = MongoPool()
# 创建协程池对象
self.coroutine_pool = Pool()
def run(self):
# 根据配置文件获取爬虫对象列表
spiders = self.get_spider_from_constant()
# 遍历爬虫对象列表,获取爬虫对象
for spider in spiders:
# 异步处理爬虫
self.coroutine_pool.apply_async(self._execute_non_spider_task(spider))
def _execute_non_spider_task(self,spider):
# 处理爬虫
try:
# 遍历爬虫对象的get_proxies方法,获取代理IP
for proxy in spider.get_proxies():
# 检测代理
proxy = check_proxy(proxy)
# 检测通过写入数据库
if proxy.speed != -1:
# 写入数据库
self.mongo_pool.insert_one(proxy)
except Exception as e:
logger.exception(e)
def get_spider_from_constant(self):
"""根据配置获取爬虫对象列表"""
for full_class_name in PROXIES_SPIDERS:
# 获取模块名
module_name,class_name = full_class_name.rsplit('.',maxsplit=1)
# 根据模块名导入模块
module = importlib.import_module(module_name)
# 根据类名从模块中获取类
cls = getattr(module,class_name)
# 创建爬虫对象
spider = cls()
yield spider
@classmethod
def start(cls):
# 1.定义一个start类方法
# 2.创建当前对象,调用run方法
rs = RunSpider()
rs.run()
# 3.使用schedule模块,每隔一段时间执行对象run
schedule.every(RUN_SPIDERS_INTERVAL).hours.do(rs.run)
while True:
schedule.run_pending()
time.sleep(5)
5.代理检测
目的:检测数据库中的代理ip的可用性,确保数据库中的代理高可用
在proxy_reptile爬虫项目下的新建proxy_test.py文件,用于对数据库中的代理进行检测
from gevent import monkey
monkey.patch_all()
from gevent.pool import Pool
from queue import Queue
import schedule
import time
from proxy_reptile.mongo_pool import MongoPool
from proxy_reptile.proxy_validate.httpbin_validator import check_proxy
from constant import MAX_SCORE,TEST_PROXIES_ASYNC_COUNT,TEST_PROXIES_INTERVAL
"""
实现代理池的检测
目的:检查代理IP可用性,保证代理池中IP基本可用
1.在proxy_test.py文件创建ProxyTester类
2.提供一个run方法,用于处理检测代理IP核心逻辑
1.从数据库中获取所有代理IP
2.遍历代理IP列表
3.检查代理可用性
1.如果代理不可用,让代理分数-1,如果代理分数等于0就从数据库中上次该代理,否则更新
2.如果代理可用,恢复该代理分数,更新到数据库中
3.提高检查速度,使用异步来执行检查任务
在init方法中创建队列和协程池
1.检查代理ip,放到队列中
2.检查代理可用性代码,抽取放到方法中;从队列中获取代理IP,进行检测,检测完毕,调度队列的task_done方法
3.通过异步回调,使用死循环不断执行这个方法
4.开启多个异步任务,来处理代理IP的检测,可以通过配置文件指定异步数量
4.使用schedule模块,每隔一段时间,执行一次检测任务
1.定义start类方法,用于启动检测模块
2.在start方法中
1.创建本类对象
2.调用run方法
3.每隔一定时间,执行以下run方法
"""
class ProxyTester(object):
def __init__(self):
# 创建数据库MongoPool对象
self.mongo_pool = MongoPool()
# 创建队列
self.queue = Queue()
# 创建协程池
self.coroutine_pool = Pool()
def __check_callback(self):
self.coroutine_pool.apply_async(self.__check_one_proxy,callback=self.__check_callback)
def __check_one_proxy(self):
# 检测代理ip的可用性
# 从队列获取代理ip
proxy = self.queue.get()
# 检查代理可用性
proxy = check_proxy(proxy)
if proxy.speed == -1:
proxy.score -= 1
if proxy.score == 0:
self.mongo_pool.delete_one(proxy)
else:
self.mongo_pool.update_one(proxy)
else:
proxy.score = MAX_SCORE
self.mongo_pool.update_one(proxy)
# 检测完毕,调用队列的task_done方法
self.queue.task_done()
def run(self):
"""用于处理检测代理IP核心逻辑"""
# 从数据库中获取所有代理IP
proxies = self.mongo_pool.find_all()
# 遍历代理ip列表
for proxy in proxies:
# 把代理IP添加到队列中
self.queue.put(proxy)
# 开启多个异步任务,来处理IP检测
for i in range(TEST_PROXIES_ASYNC_COUNT):
# 通过异步回调
self.coroutine_pool.apply_async(self.__check_one_proxy,callback=self.__check_callback)
# 让当前线程等待队列完成
self.queue.join()
@classmethod
def start(cls):
# 1.创建本类对象
proxy_tester = cls()
# 2.调用run方法
proxy_tester.run()
# 3.每隔一定时间,执行以下run方法
schedule.every(TEST_PROXIES_INTERVAL).hours.do(proxy_tester.run)
while True:
schedule.run_pending()
time.sleep(2)
五、web页面的实现
1.页面展示(相关代码不展示)
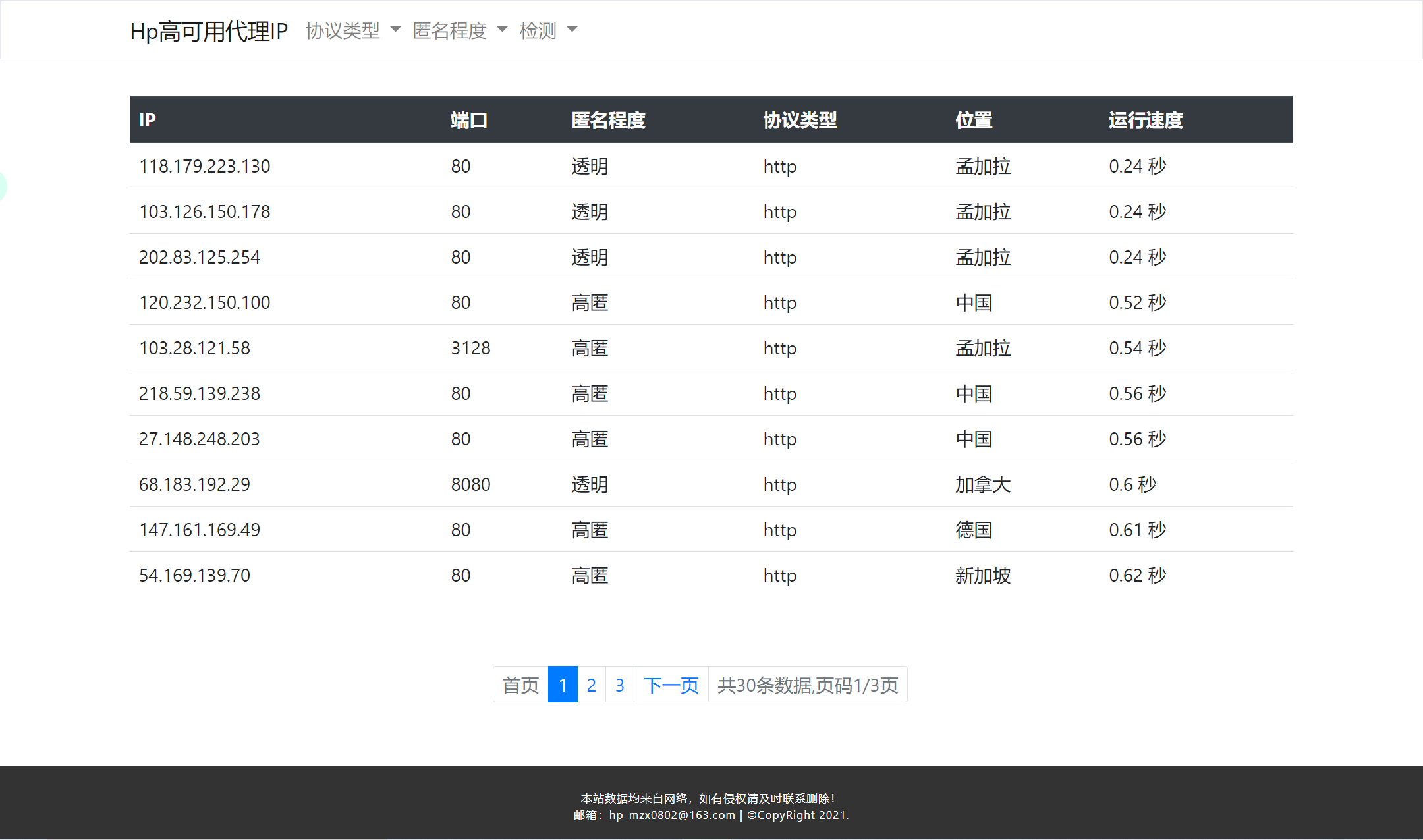
2.后端处理
在蓝图模块编写后端代理
from . import api
import random
import json
from flask import render_template,request,jsonify
from proxy_reptile.mongo_pool import MongoPool
from project.utils.pangination import Pagination
from proxy_reptile.proxy_validate.httpbin_validator import check_proxy
from proxy_reptile.domain import Proxy
from project.utils.checkIP import check_ip,check_port
mongo_pool = MongoPool()
@api.route("/index")
def index():
"""
随机获取高可用代理IP
:return:
"""
page = request.args.get('page','1')
protocol = request.args.get('protocol')
nick_type = request.args.get('nick_type')
conditions = {'score': 50}
# 判断页数
if page.isdigit():
page = int(page)
else:
page = 1
# 判断是否值得代理协议
if protocol:
if protocol.lower() == 'http':
conditions['protocol'] = 0
elif protocol.lower() == 'https':
conditions['protocol'] = 1
# 判断是否有匿名程度
if nick_type:
if nick_type.isdigit():
if nick_type == '0':
conditions['nick_type'] = 0
elif nick_type == '1':
conditions['nick_type'] = 1
elif nick_type == '2':
conditions['nick_type'] = 2
proxy_list,total =mongo_pool.find(conditions,page=page,count=10)
proxies = [proxy.__dict__ for proxy in proxy_list]
# 分页管理
page_html = Pagination(request, total, per_num=10,max_show=7).page_html
return render_template('index.html',proxies=proxies,total=total,page_html=page_html)
@api.route('/checkProxy')
def checkProxy():
proxyIp = request.args.get('proxyIp')
proxyPort = request.args.get('proxyPort')
check_ip_res = check_ip(proxyIp)
check_port_res = check_port(proxyIp)
if not check_ip_res and not check_port_res:
result = {
"code": -1,
"msg": "ip地址或端口号不符合规则",
"data": {}
}
return jsonify(result)
# 尝试重数据库中获取
proxy_list , _ = mongo_pool.find({'ip':proxyIp,'port':proxyPort})
# 如果数据库中存在该代理
if proxy_list:
res = check_proxy(proxy_list[0])
# 数据库中不存在该代理
else:
proxy = Proxy(ip=proxyIp, port=proxyPort)
res = check_proxy(proxy)
result = {
"code": 1,
"msg": "检测成功",
"data": res.__dict__
}
return jsonify(result)
Flask 之 高可用IP代理网站的更多相关文章
- 被IP代理网站屏蔽了,真是跪了
被IP代理网站http://www.xicidaili.com/nn/屏蔽了,真是跪了 T T
- keepalived高可用反向代理的nginx
实验系统: (1)CentOS 6.6_x86_64: (2)共有三台主机,本实验以ip地址来命名主机,即131主机.132主机.133主机. 实验前提:防火墙和selinux都关闭,主机之间时间同步 ...
- PHP如何打造一个高可用高性能的网站呢?
https://blog.csdn.net/jwq101666/article/details/80162245 1. 说到高可用的话要提一下redis,用过的都知道redis是一个具备数据库特征的n ...
- keepalived 高可用(IP飘移)
什么是keepalived? keepalived是一个在c中编写的路由软件,该项目的主要目标是为Linux系统和基于Linux的基础架构提供简单和强大的设备,用于loadbalance和高可用性.l ...
- Flask开发系列之Flask+redis实现IP代理池
Flask开发系列之Flask+redis实现IP代理池 代理池的要求 多站抓取,异步检测:多站抓取:指的是我们需要从各大免费的ip代理网站,把他们公开的一些免费代理抓取下来:一步检测指的是:把这些代 ...
- ip代理池的爬虫编写、验证和维护
打算法比赛有点累,比赛之余写点小项目来提升一下工程能力.顺便陶冶一下情操 本来是想买一个服务器写个博客或者是弄个什么FQ的东西 最后刷知乎看到有一个很有意思的项目,就是维护一个「高可用低延迟的高匿IP ...
- nginx+keepalived实现nginx双主高可用的负载均衡
http://kling.blog.51cto.com/3320545/1253474 一.前言: 在互联网上面,网站为用户提供原始的内容访问,同时为用户提供交互操作.提供稳定可靠的服务,可以给用户带 ...
- Linux IP代理筛选系统(shell+proxy)
代理的用途 其实,除了抓取国外网页需要用到IP代理外,还有很多场景会用到代理: 通过代理访问一些国外网站,绕过被某国防火墙过滤掉的网站 使用教育网的代理服务器,可以访问到大学或科研院所的内部网站资源 ...
- 记一次企业级爬虫系统升级改造(六):基于Redis实现免费的IP代理池
前言: 首先表示抱歉,春节后一直较忙,未及时更新该系列文章. 近期,由于监控的站源越来越多,就偶有站源做了反爬机制,造成我们的SupportYun系统小爬虫服务时常被封IP,不能进行数据采集. 这时候 ...
随机推荐
- UML与面向对象程序设计原则
[实验任务一]:UML复习 阅读教材第一章复习UML,回答下述问题: 面向对象程序设计中类与类的关系都有哪几种?分别用类图实例说明. 1. 关联关系 (1) 双向关联 (2) 单向关联 (3) ...
- java多线程的状态转换以及基本操作
1. 新建线程 一个java程序从main()方法开始执行,然后按照既定的代码逻辑执行,看似没有其他线程参与,但实际上java程序天生就是一个多线程程序,包含了:(1)分发处理发送给给JVM信号的线程 ...
- TINY语言采用递归下降分析法编写语法分析程序
目录 自顶向下分析方法 TINY文法 消左提左.构造first follow 基本思想 python构造源码 运行结果 参考来源:聊聊编译原理(二) - 语法分析 自顶向下分析方法 自顶向下分析方法: ...
- DC-1 靶机渗透
DC-1 靶机渗透 *概况*: 下载地址 https://www.vulnhub.com/entry/dc-1,292/ *官方描述:* DC-1 is a purposely built vulne ...
- SpringBoot内外部配置文件加载和优先级
直接附链接:https://www.pianshen.com/article/28711537583/
- QT类使用记录
QT类使用记录 1.QSharedMemory 提供了对一段共享内存的访问.既提供了被多进程和多线程共享的一段内存的访问.也为单线程或单进程锁定内存以实现互斥访问提供了方法. QSharedMemor ...
- 【.NET6+Modbus】Modbus TCP协议解析、仿真环境以及基于.NET实现基础通信
前言:随着工业化的发展,目前越来越多的开发,从互联网走向传统行业.其中,工业领域也是其中之一,包括各大厂也都在陆陆续续加入工业4.0的进程当中. 工业领域,最核心的基础设施,应该是与下位硬件设备或程序 ...
- Go xmas2020 学习笔记 06、Control Statements、Declarations & Types
06-Control Statements. If-then-else. Loop. for. range array. range map. infinite loop. common mistak ...
- Python 连接Mysql数据库执行语句操作
学习Mysql模块的使用,模块命名的坑,解决SHA加密错误无法连接
- Java学习day40
跟着视频回顾了整个JavaSE的学习过程