python爬取猫眼电影Top100榜单的信息
爬取并写入MySQL中
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
connect = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='root',
db='python',
charset='utf8'
)
# 获取游标
cursor = connect.cursor()
def toMySQL(imgBlob, titleSQL, starringSQL, releaseTimeSQL, scoreSQL):
print(requests.get(imgBlob).content)
print(imgBlob)
print(titleSQL)
print(starringSQL[3:])
print(releaseTimeSQL[5:])
print(scoreSQL)
insertSql = """INSERT INTO `python`.`maoyan`(`img`, `title`, `starring`, `release_time`, `score`) VALUES ('{a}','{b}','{c}','{d}','{e}')"""
cursor.execute(
insertSql.format(a=r'' + str(requests.get(imgBlob).content), b=titleSQL, c=starringSQL[3:], d=releaseTimeSQL[5:],
e=scoreSQL))
print("------------------执行了插入")
connect.commit()
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
toMySQL(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(30, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
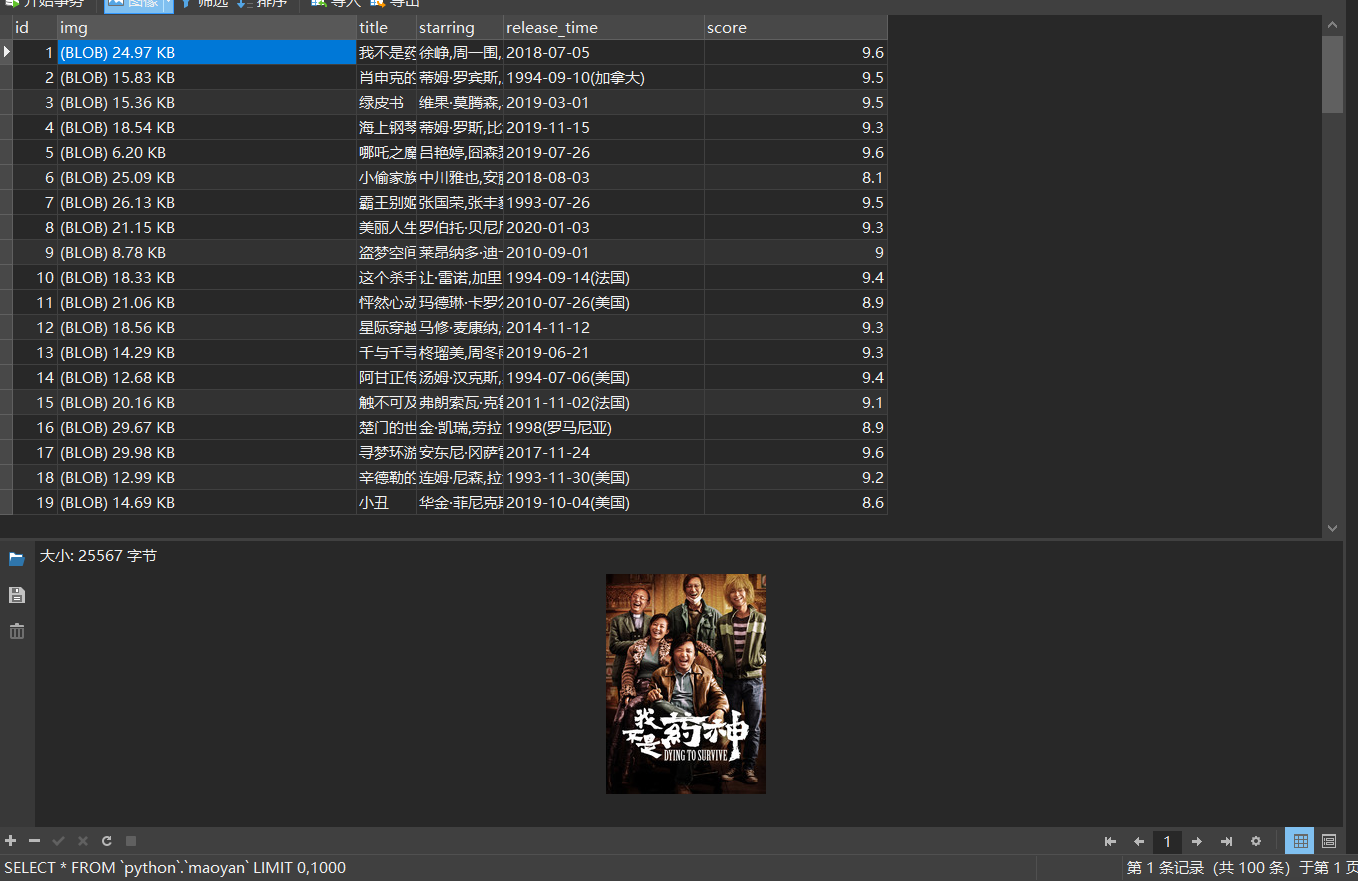
库表信息

运行结果:
爬取后写入MongoDB
import pymongo
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
def toMongoDB(imgSrc, Title, starring, releaseTime, score):
print(imgSrc)
print(Title)
print(starring[3:])
print(releaseTime[5:])
print(score)
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
myDb = myClient["maoyan"]
myCollection = myDb["maoyanTop100"]
myDictionary = {
"imgSrc": imgSrc,
"Title": Title,
"starring": starring[3:],
"releaseTime": releaseTime[5:],
"score": score
}
result = myCollection.insert_one(myDictionary)
print(result)
pass
def mingzihaonanqi(page):
url = 'https://maoyan.com/board/4?offset=' + str(page)
res = requests.get(url, headers=headers)
# 页面session失效, 需要重新验证, 打印出来方便使用
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('dd')
for resultSet in ResultSets:
tag = resultSet
soupTag = BeautifulSoup(str(tag), 'html.parser')
Title = soupTag.find('a').get('title')
imgSrc = soupTag.find('img', class_='board-img').get('data-src')
starring = soupTag.find('p', class_='star').text.strip()
releaseTime = soupTag.find('p', class_='releasetime').text.strip()
score = soupTag.find('p', class_='score').text.strip()
# 写入MongoDB
toMongoDB(imgSrc, Title, starring, releaseTime, score)
print(str(page) + "----------")
if __name__ == '__main__':
for i in range(0, 100, 10):
print(i) # 0 10 20 ````
mingzihaonanqi(i)
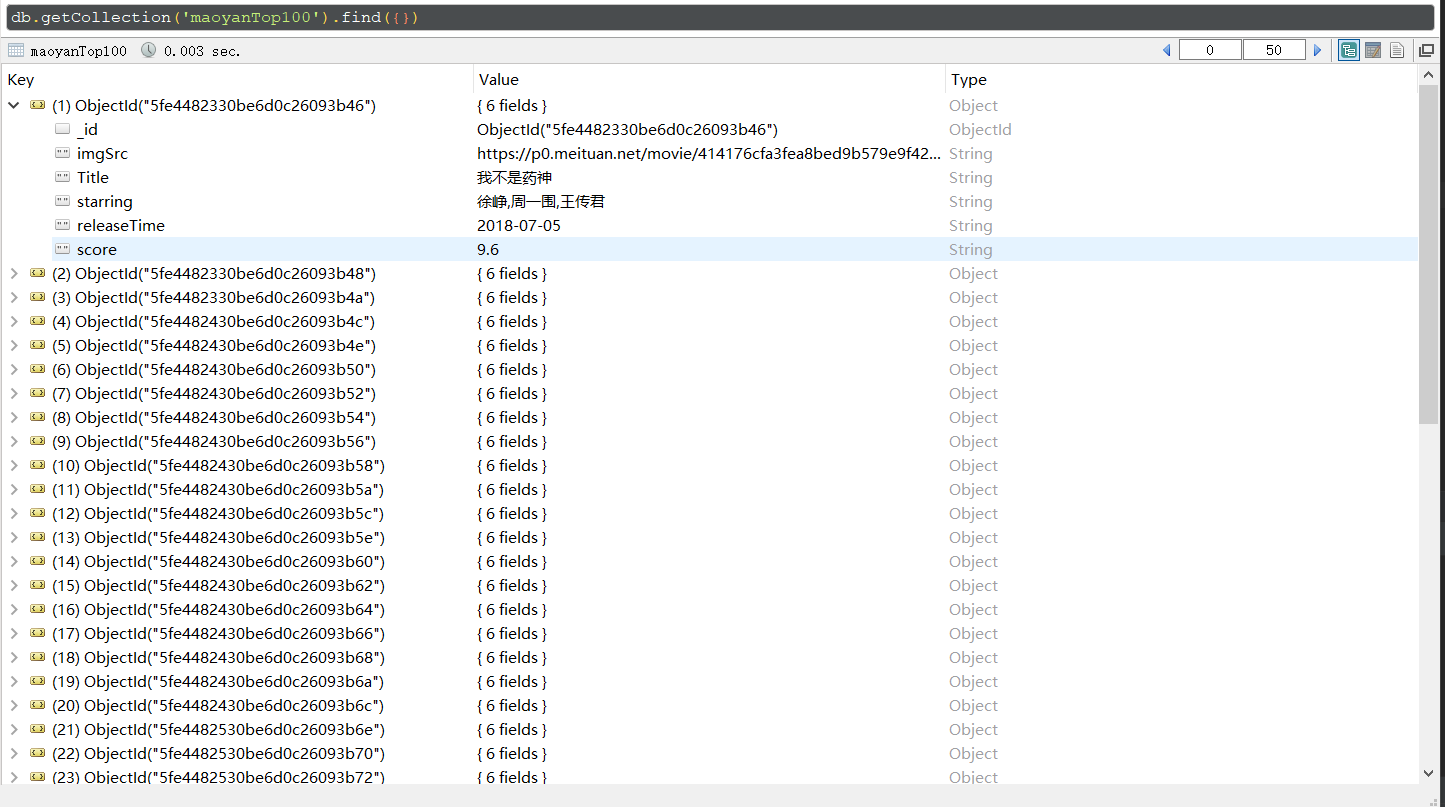
运行结果
python爬取猫眼电影Top100榜单的信息的更多相关文章
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 使用requests爬取猫眼电影TOP100榜单
Requests是一个很方便的python网络编程库,用官方的话是"非转基因,可以安全食用".里面封装了很多的方法,避免了urllib/urllib2的繁琐. 这一节使用reque ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- Requests+正则表达式爬取猫眼电影(TOP100榜)
猫眼电影网址:www.maoyan.com 前言:网上一些大神已经对猫眼电影进行过爬取,所用的方法也是各有其优,最终目的是把影片排名.图片.名称.主要演员.上映时间与评分提取出来并保存到文件或者数据库 ...
- Python爬取猫眼电影100榜并保存到excel表格
首先我们前期要导入的第三方类库有; 通过猫眼电影100榜的源码可以看到很有规律 如: 亦或者是: 根据规律我们可以得到非贪婪的正则表达式 """<div class ...
- python爬取猫眼电影top100
最近想研究下python爬虫,于是就找了些练习项目试试手,熟悉一下,猫眼电影可能就是那种最简单的了. 1 看下猫眼电影的top100页面 分了10页,url为:https://maoyan.com/b ...
- python 爬取猫眼下的榜单(一)--单个页面
#!/usr/bin/env python # -*- coding: utf- -*- # @Author: Dang Kai # @Date: -- :: # @Last Modified tim ...
随机推荐
- Simple Algebra
题意 给定方程\(f(x)=ax^2+bxy+cy^2\)和参数\(a\),\(b\),\(c\),试确定该方程的取值是否恒非负. 题解 参照文章http://math.mit.edu/~mckern ...
- 问题:配置apache的相关配置文件报错:Invalid command 'Order' (已解决)
1. 问题描述 在虚拟文件httpd-vhosts.conf里面,directory里加入Order allow,deny,重启apache,出现Invalid command 'Order', pe ...
- flutter TextField 使用prefixIcon图标和文字间距问题
可以看到使用prefixIcon图标就出现间距问题.网上看了很多文章,好像是没有什么好的解决办法,也有可能是太简单了,别人懒的发(哭笑). 我把我知道的方法写出来吧 decoration: Input ...
- 1.1 安装gin框架&使用gin编写简单服务端
01.安装gin框架 1)go环境配制 a)配制环境变量 GOPATH修改为go的工作文件夹路径 D:\Golang\goproject GOROOT修改为go的安装路径 D:\Golang\go1. ...
- 波利亚(George Pólya)的一些链接
忽然决定还是要写个博客. 第一篇献给波利亚. 他最有名的应该是<怎样解题>(How to solve it)这本书了.我认为只要读了前面几页就能提高普通人解决问题的能力,真的应该列为中学必 ...
- postman收藏 -大佬玩法。
请求顺序: https://www.cnblogs.com/superhin/p/11454832.html 在Postman脚本中发送请求(pm.sendRequest) : https:// ...
- HTTP请求向服务器传参方式
请求HttpRequest 提示: 用户发送请求时携带的参数后端需要使用,而不同的发送参数的方式对应了不同的提取参数的方式 所以要学会如何提取参数,我们就需要先了解前端传参数有哪些方式 回想一下,利用 ...
- C#中的范围类型(Range Type)
//语法糖Rangestatic void Main(string[] args) { var myArray = new string[] { "Item1", "It ...
- md5信息摘要算法实现(python 和 go版本)
纯手写实现的md5信息摘要算法 github地址如下 https://github.com/kittysmith5/dgst/blob/main/md5 python3版本代码 #!/usr/bin/ ...
- Markdown基础使用学习
Mark Down学习 标题:#+标题名字 二级标题:## +标题名字 三级... 字体 两个*+字+两个=加粗 一个=斜体 引用 一个大于号+内容 图片  符号全部小写 超链接 ...