python学习-Day20

今日内容详细
作业讲解
正则表达式在爬虫领域使用的较为广泛,在一个烦乱的页面中提取出目标数据
'''目前我们还没有学习第三方模块和爬虫知识 所以数据获取先直接拷贝'''
import re
# 1.模拟网络请求 读取文件数据
with open(r'a.txt', 'r', encoding='utf8') as f:
# 2.由于数据量不大 这里直接一次性读取
file_data = f.read() # file_data就是待筛选的数据
# 3.研究所需数据的特征 再编写相应的正则
# 3.1.匹配公司名称 首先拿到公司名称所在的数据区域 <h2>红牛杭州分公司</h2>
cp_title_list = re.findall('<h2>(.*?)</h2>', file_data)
'''findall优先展示括号内正则表达式匹配到的内容'''
# print(cp_title_list)
# 3.2.匹配公司地址 首先拿到公司地址所在的数据区域 <p class='mapIco'>杭州市上城区庆春路29号远洋大厦11楼A座</p>
cp_addr_list = re.findall("<p class='mapIco'>(.*?)</p>",file_data)
# print(cp_addr_list)
# 3.3.匹配公司邮编 首先拿到公司邮编所在的数据区域 <p class='mailIco'>310009</p>
cp_email_list = re.findall("<p class='mailIco'>(.*?)</p>",file_data)
# print(cp_email_list)
# 3.4.匹配公司电话 首先拿到公司电话所在的数据区域 <p class='telIco'>0571-87045279/7792</p>
cp_phone_list = re.findall("<p class='telIco'>(.*?)</p>",file_data)
# print(cp_phone_list)
# 4.有了四个列表 分别存储的时候公司名称 地址 电话 邮编 如何对应展示
# 4.1.使用zip先将每个公司所有的数据整合到一起
res = zip(cp_title_list,cp_addr_list,cp_email_list,cp_phone_list)
for t in res:
print("""
公司名称:%s
公司地址:%s
公司邮编:%s
公司电话:%s
"""%t)

re模块补充说明
findall的优先级查询
"""
findall默认是分组优先展示
正则表达式中如果有括号分组 那么在展示匹配结果的时候
默认只演示括号内正则表达式匹配到的内容!!!
也可以取消分组有限展示的机制
(?:) 括号前面加问号冒号
"""
import re
ret = re.findall('a(b)c', 'abcabcabcabc')
print(ret) # ['b', 'b', 'b', 'b']
ret = re.findall('a(?:b)c', 'abcabcabcabc')
print(ret) # ['abc', 'abc', 'abc', 'abc']
ret = re.findall('(a)(b)(c)', 'abcabcabcabc')
print(ret) # [('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c')]
ret = re.findall('(?P<aaa>a)(b)(c)', 'abcabcabcabc')
print(ret) # [('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c'), ('a', 'b', 'c')]
通过索引的方式单独获取分组内匹配到的数据
print(ret.group('aaa'))
ret = re.search('a(b)c', 'abcabcabcabc')
print(ret.group()) # abc
print(ret.group(0)) # abc
print(ret.group(1)) # b 可以通过索引的方式单独获取分组内匹配到的数据
ret = re.search('a(b)(c)', 'abcabcabcabc')
print(ret.group()) # abc
print(ret.group(0)) # abc
print(ret.group(1)) # b 可以通过索引的方式单独获取分组内匹配到的数据
print(ret.group(2)) # c 可以通过索引的方式单独获取分组内匹配到的数据
'''针对search和match有几个分组 group方法括号内最大就可以写几'''
分组之后还可以给组起别名
ret = re.search('a(?P<name1>b)(?P<name2>c)', 'abcabcabcabc')
print(ret.group('name1')) # b
print(ret.group('name2')) # c
split的优先级查询
import re
ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
print(ret) # ['www.oldboy.com']

collections模块
提供了更多的数据类型
具名元组(namedtuple)
生成可以使用名字来访问元素内容的tuple
from collections import namedtuple
# 1.先产生一个元组对象模板
point = namedtuple('坐标',['x','y'])
# 2.创建诸多元组数据
p1 = point(1,2)
p2 = point(10,8)
print(p1,p2) # 坐标(x=1, y=2) 坐标(x=10, y=8)
print(p1.x) # 1
print(p1.y) # 2
摆例子
person = namedtuple('人物','name age gender')
p1 = person('jojo',18,'male')
p2 = person('camellia',28,'female')
print(p1,p2) # 人物(name='jojo', age=18, gender='male') 人物(name='camellia', age=28, gender='female')
print(p1.name,p1.age) # jojo 18
具名元组的使用场景也非常的广泛 比如数学领域、娱乐领域等
card = namedtuple('扑克牌', ['花色', '点数'])
c1 = card('黑桃', 'A')
c2 = card('黑梅', 'K')
c3 = card('红心', 'A')
print(c1, c2, c3)
print(c1.点数)
双端队列 (deque)
队列:先进先出,默认是只有一端只能进另外一端只能出
双端队列:两端都可以进出(可以快速的从另外一侧追加和推出对象)
import queue
q = queue.Queue(3) # 最大只能放三个元素
# 存放元素
q.put(123)
q.put(321)
q.put(222)
q.put(444) # 如果队列满了 继续添加则原地等待
# 获取元素
print(q.get()) # 123
print(q.get()) # 321
print(q.get()) # 222
print(q.get()) # 如果队列空了 继续获取则原地等待
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
from collections import deque
q = deque([1,2,3])
print(q)
q.append(444) # 右边添加元素
print(q)
q.appendleft(666) # 左边添加元素
print(q)
q.pop() # 右边弹出元素
q.popleft() # 左边弹出元素

字典相关
正常的字典内部是无序的
d1 = dict([('name','jason'),('pwd',123),('hobby','study')])
print(d1) # {'pwd': 123, 'name': 'jason', 'hobby': 'study'}
print(d1.keys())
有序字典(OrderedDict)
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict
from collections import OrderedDict
# OrderedDict的Key会按照插入的顺序排列,不是Key本身排序
d2 = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
print(d2)
d2['x'] = 111
d2['y'] = 222
d2['z'] = 333
print(d2)
print(d2.keys())
带有默认值的字典(defaultdict)
"""
有如下值集合 [11,22,33,44,55,67,77,88,99,999],
将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
"""
常规写法
l1 = [11,22,33,44,55,67,77,88,99,999]
new_dict = {'k1':[],'k2':[]}
for i in l1:
if i > 66:
new_dict['k1'].append(i)
else:
new_dict['k2'].append(i)
print(new_dict)
使用带有默认值的字典
from collections import defaultdict
values = [11, 22, 33,44,55,67,77,88,99,90]
my_dict = defaultdict(list) # 字典所有的值默认都是列表 {'':[],'':[]}
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
计数器(Counter)
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
常规写法
res = 'abcdeabcdabcaba'
'''
统计字符串中所有字符出现的次数
{'a':3,'b':5...}
'''
new_dict = {}
for i in res:
if i not in new_dict:
# 字符第一次出现 应该创建一个新的键值对
new_dict[i] = 1
else:
new_dict[i] += 1
print(new_dict) # {'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1}
使用计数器
from collections import Counter
r = Counter(res)
print(r) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
print(r.get('a')) # 可以当成字典使用

time模块
和时间有关系的我们就要用到时间模块。
常用方法
1.time.sleep(secs)
推迟指定的时间运行,单位为秒
ps:该方法贯穿前后(基础、后期)
2.time.time()
获取当前时间戳
表示时间的三种方式
彼此之间可以转换
时间戳(timestamp)
# 距离1970年1月1日0时0分0秒至此相差的秒数
# 我们运行“ type(time.time()) ”,返回的是float类型。
time.time()
结构化时间
time.localtime()
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
格式化时间
# 人最容易接收的一种时间格式 2000/1/21 11:11:11
time.strftime()
'%Y-%m-%d %H:%M:%S' # 2022-03-29 11:31:30
'%Y-%m-%d %X' # 2022-03-29 11:31:30
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
时间类型的转换
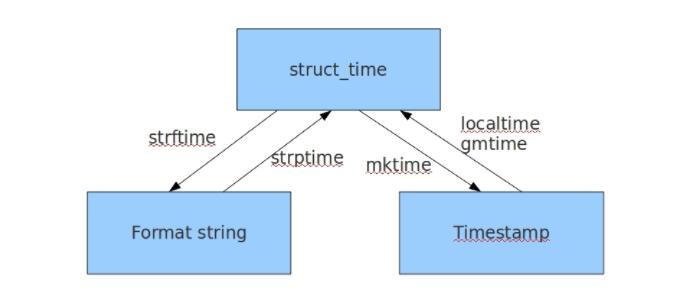
格式化时间 <==> 结构化时间 <==> 时间戳
# 时间戳 <--> 结构化时间
gmtime
localtime
# 结构化时间 <--> 格式化时间
strftime
strptime
time.strptime("2017-03-16","%Y-%m-%d")
time.strptime("2017/03","%Y/%m") 前后必须一致
ps:UTC时间比我所在的区域时间早八个小时(时区划分)

datetime模块
基本操作
import datetime
print(datetime.date.today()) # 2022-03-29
print(datetime.datetime.today()) # 2022-03-29 11:55:50.883392
"""
date 意思就是年月日
datetime 意思就是年月日 时分秒
ps:后期很多时间相关的操作都是跟date和time有关系
"""
res = datetime.date.today()
print(res.year) # 2022
print(res.month) # 3
print(res.day) # 29
print(res.weekday()) # 1 星期0-6
print(res.isoweekday()) # 2 星期1-7
时间差
ctime = datetime.datetime.today()
time_tel = datetime.timedelta(days=4) # 有很多时间选项
print(ctime) # 2022-03-29 12:01:52.279025
print(ctime + time_tel) # 2022-04-02 12:01:52.279025
print(ctime - time_tel) # 2022-03-25 12:03:34.495813
"""
针对时间计算的公式
日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象
"""
res = ctime + time_tel
print(res - ctime) # 4 days, 0:00:00
random模块
又称:随机数模块
import random
随机小数
print(random.random()) # 随机产生一个0到1之间的小数
print(random.uniform(2,4)) # 随机产生一个2到4之间的小数
随机整数
print(random.randint(0,9)) # 随机产生一个0到9之间的整数(包含0和9)
print(random.randint(1,6)) # 掷骰子
打乱列表顺序
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
random.shuffle(l) # 随机打乱一个数据集合 洗牌
print(l)
随机选择返回
ll1 = ['特等奖','张飞抱回家','如花','百万现金大奖','群内配对']
print(random.choice(ll1)) # 随机抽取一个 抽奖
ll = ['如花','C老师','R老师','J老师','M老师','张飞','龙龙']
print(random.sample(ll, 2)) # 随机指定个数抽样 抽样

python学习-Day20的更多相关文章
- python学习 day20 (3月27日)----(单继承多继承c3算法)
继承: 提高代码的重用性,减少了代码的冗余 这两个写法是一样的 Wa('青蛙').walk() #青蛙 can walk wa = Wa('青蛙') wa.walk() #青蛙 can walk 1. ...
- Python学习-day20 django进阶篇
Model 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去调用数据访问层执行 ...
- python学习-day20、装饰器【图片缺失可看】印象笔记博客备份
前言: 装饰器用于装饰某些函数或者方法,或者类.可以在函数执行之前或者执行之后,执行一些自定义的操作. 1.定义:装饰器就是一个函数,为新定义的函数.把原函数嵌套到新函数里面.以后就可以在执行新函数的 ...
- python学习day20 面向对象(二)类成员&成员修饰符
1.成员 类成员 类变量 绑定方法 类方法 静态方法 属性 实例成员(对象) 实例变量 1.1实例变量 类实例化后的对象内部的变量 1.2类变量 类中的变量,写在类的下一级和方法同一级. 访问方法: ...
- python学习博客地址集合。。。
python学习博客地址集合... 老师讲课博客目录 http://www.bootcdn.cn/bootstrap/ bootstrap cdn在线地址 http://www.cnblogs. ...
- Python学习--04条件控制与循环结构
Python学习--04条件控制与循环结构 条件控制 在Python程序中,用if语句实现条件控制. 语法格式: if <条件判断1>: <执行1> elif <条件判断 ...
- Python学习--01入门
Python学习--01入门 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.和PHP一样,它是后端开发语言. 如果有C语言.PHP语言.JAVA语言等其中一种语言的基础,学习Py ...
- Python 学习小结
python 学习小结 python 简明教程 1.python 文件 #!/etc/bin/python #coding=utf-8 2.main()函数 if __name__ == '__mai ...
- Python学习路径及练手项目合集
Python学习路径及练手项目合集 https://zhuanlan.zhihu.com/p/23561159
随机推荐
- DWR是什么?有什么作用?
DWR(Direct Web Remoting)是一个用于改善web页面与Java类交互的远程服务器端Ajax开源框架,可以帮助开发人员开发包含AJAX技术的网站. 它可以允许在浏览器里的代码使用运行 ...
- 手撕代码:leetcode70爬楼梯
装载于:https://blog.csdn.net/qq_35091252/article/details/90576779 题目描述 假设你正在爬楼梯.需要n阶你才能到达楼顶. 每次你可以爬1或2个 ...
- 什么是 ThreadLocal 变量?
ThreadLocal 是 Java 里一种特殊的变量.每个线程都有一个 ThreadLocal 就是每 个线程都拥有了自己独立的一个变量,竞争条件被彻底消除了.它是为创建代价 高昂的对象获取线程安全 ...
- it-术语
QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准. 因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS. 对应fetches/sec,即每秒的 ...
- kafka producer的batch.size和linger.ms
1.问题 batch.size和linger.ms是对kafka producer性能影响比较大的两个参数.batch.size是producer批量发送的基本单位,默认是16384Bytes,即16 ...
- List、Map、Set 三个接口存取元素时,各有什么特点?
List 以特定索引来存取元素,可以有重复元素.Set 不能存放重复元素(用对象的 equals()方法来区分元素是否重复).Map 保存键值对(key-value pair)映射, 映射关系可以是一 ...
- jsp技术之隐藏域
隐藏域 hidden:隐藏域属性,不显示到页面上,但是会提交的表单项 注意:表单中增加了一个隐藏域,是用户的id.稍后修改联系人信息,提交表单时需要使用到 <!-- hidden:隐藏域,不显示 ...
- Linux网络配置:Nat和桥接模式详解
Linux网络配置:Nat和桥接模式详解 一.我们首先说一下VMware的几个虚拟设备: Centos虚拟网络编辑器中的虚拟交换机: VMnet0:用于虚拟桥接网络下的虚拟交换机: VMnet1:用于 ...
- link和@import的区别浅析
我们都知道,外部引入 CSS 有2种方式,link标签和@import.它们有何本质区别,有何使用建议,在考察外部引入 CSS 这部分内容时,经常被提起. 如今,很多学者本着知其然不欲知其所以然的学习 ...
- java中hashCode和equals什么关系,hashCode到底怎么用的
Object类的hashCode的用法:(新手一定要忽略本节,否则会很惨) 马 克-to-win:hashCode方法主要是Sun编写的一些数据结构比如Hashtable的hash算法中用到.因为ha ...