k8s 中的 Pod 细节了解
- k8s中Pod的理解
k8s中Pod的理解
基本概念
Pod 是 Kubernetes 集群中能够被创建和管理的最小部署单元,它是虚拟存在的。Pod 是一组容器的集合,并且部署在同一个 Pod 里面的容器是亲密性很强的一组容器,Pod 里面的容器,共享网络和存储空间,Pod 是短暂的。
k8s 中的 Pod 有下面两种使用方式
1、一个 Pod 中运行一个容器,这是最常见的用法。一个 Pod 封装一个容器,k8s 直接对 Pod 管理即可;
2、一个 Pod 中同时运行多个容器,通常是紧耦合的我们才会放到一起。同一个 Pod 中的多个容器可以使用 localhost 通信,他们共享网络和存储卷。不过这种用法不常见,只有在特定的场景中才会使用。
k8s 为什么使用 Pod 作为最小的管理单元
k8s 中为什么不直接操作容器而是使用 Pod 作为最小的部署单元呢?
为了管理容器,k8s 需要更多的信息,比如重启策略,它定义了容器终止后要采取的策略;或者是一个可用性探针,从应用程序的角度去探测是否一个进程还存活着。基于这些原因,k8s 架构师决定使用一个新的实体,也就是 Pod,而不是重载容器的信息添加更多属性,用来在逻辑上包装一个或者多个容器的管理所需要的信息。
如何使用 Pod
1、自主式 Pod
我们可以简单的快速的创建一个 Pod 类似下面:
$ cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
创建
$ kubectl apply -f pod.yaml -n study-k8s
$ kubectl get pod -n study-k8s
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 2m
自主创建的 Pod ,因为没有加入控制器来管理,这样创建的 Pod,被删除,或者因为意外退出了,不会重启自愈,直接就会被删除了。所以,业务中,我们在创建 Pod 的时候都会加入控制器。
2、控制器管理的 Pod
因为我们的业务长场景的需要,我们需要 Pod 有滚动升级,副本管理,集群级别的自愈能力,这时候我们就不能单独的创建 Pod, 我们需要通过相应的控制器来创建 Pod,来实现 Pod 滚动升级,自愈等的能力。
对于 Pod 使用,我们最常使用的就是通过 Deployment 来管理。
Deployment 提供了一种对 Pod 和 ReplicaSet 的管理方式。Deployment 可以用来创建一个新的服务,更新一个新的服务,也可以用来滚动升级一个服务。借助于 ReplicaSet 也可以实现 Pod 的副本管理功能。
滚动升级一个服务,实际是创建一个新的 RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧 RS 中的副本数减小到 0 的复合操作;这样一个复合操作用一个 RS 是不太好描述的,所以用一个更通用的 Deployment 来描述。
$ vi deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
运行
$ kubectl apply -f deployment.yaml -n study-k8s
$ kubectl get pods -n study-k8s
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 67m
nginx-deployment-66b6c48dd5-24sbd 1/1 Running 0 59s
nginx-deployment-66b6c48dd5-wxkln 1/1 Running 0 59s
nginx-deployment-66b6c48dd5-xgzgh 1/1 Running 0 59s
因为上面定义了 replicas: 3 也就是副本数为3,当我们删除一个 Pod 的时候,马上就会有一个新的 Pod 被创建。
同样经常使用的到的控制器还有 DaemonSet 和 StatefulSet
DaemonSet:DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
StatefulSet:用来管理有状态应用的工作负载,和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
静态 Pod
静态 Pod 是由 kubelet 进行管理的仅存在与特定 node 上的 Pod,他们不能通过 api server 进行管理,无法与 rc,deployment,ds 进行关联,并且 kubelet 无法对他们进行健康检查。
静态 Pod 始终绑定在某一个kubelet,并且始终运行在同一个节点上。 kubelet会自动为每一个静态 Pod 在 Kubernetes 的 apiserver 上创建一个镜像 Pod(Mirror Pod),因此我们可以在 apiserver 中查询到该 Pod,但是不能通过 apiserver 进行控制(例如不能删除)。
为什么需要静态 Pod ?
主要是用来对集群中的组件进行容器化操作,例如 etcd kube-apiserver kube-controller-manager kube-scheduler 这些都是静态 Pod 资源。
因为这些 Pod 不受 apiserver 的控制,就不会不小心被删掉的情况,同时 kube-apiserver 也不能自己去控制自己。静态 Pod 的存在将集群中的容器化操作提供了可能。
静态 Pod 的创建有两种方式,配置文件和 HTTP 两种方式,具体参见。静态 Pod 的创建
Pod的生命周期
Pod 在运行的过程中会被定义为各种状态,了解一些状态能帮助我们了解 Pod 的调度策略。当 Pod 被创建之后,就会进入健康检查状态,当 Kubernetes 确定当前 Pod 已经能够接受外部的请求时,才会将流量打到新的 Pod 上并继续对外提供服务,在这期间如果发生了错误就可能会触发重启机制。
不过 Pod 本身不具有自愈能力,如果 Pod 因为 Node 故障,或者是调度器本身故障,这个 Pod 就会被删除。所以 Pod 中一般使用控制器来管理 Pod ,来实现 Pod 的自愈能力和滚动更新的能力。
Pod的重启策略包括
Always 只要失败,就会重启;
OnFile 当容器终止运行,且退出码不是0,就会重启;
Never 从来不会重启。
重启的时间,是以2n来算。比如(10s、20s、40s、...),其最长延迟为 5 分钟。 一旦某容器执行了 10 分钟并且没有出现问题,kubelet 对该容器的重启回退计时器执行 重置操作。
管理Pod的重启策略是靠控制器来完成的。
Pod 的几种状态
使用的过程中,会经常遇到下面几种 Pod 的状态。
Pending:Pod 创建已经提交给 k8s,但有一个或者多个容器尚未创建亦未运行,此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间。这个状态可能就是在下载镜像;
Running:Pod 已经绑定到一个节点上了,并且已经创建了所有容器。至少有一个容器仍在运行,或者正处于启动或重启状态;
Secceeded:Pod 中的所有容器都已经成功终止,并且不会再重启;
Failed:Pod 中所有的容器均已经终止,并且至少有一个容器已经在故障中终止;
Unkown:因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。
当 pod 一直处于 Pending 状态,可通过 kubectl describe pods <node_name> -n namespace 来获取出错的信息
Pod 如何直接暴露服务
Pod 一般不直接对外暴露服务,一个 Pod 只是一个运行服务的实例,随时可能在节点上停止,然后再新的节点上用一个新的 IP 启动一个新的 Pod,因此不能使用确定的 IP 和端口号提供服务。这对于业务来说,就不能根据 Pod 的 IP 作为业务调度。kubernetes 就引入了 Service 的概 念,它为 Pod 提供一个入口,主要通过 Labels 标签来选择后端Pod,这时候不论后端 Pod 的 IP 地址如何变更,只要 Pod 的 Labels 标签没变,那么 业务通过 service 调度就不会存在问题。
不过使用 hostNetwork 和 hostPort,可以直接暴露 node 的 ip 地址。
hostNetwork
这是一种直接定义 Pod 网络的方式,使用 hostNetwork 配置网络,Pod 中的所有容器就直接暴露在宿主机的网络环境中,这时候,Pod 的 PodIP 就是其所在 Node 的 IP。从原理上来说,当设定 Pod 的网络为 Host 时,是设定了 Pod 中 pod-infrastructure(或pause)容器的网络为 Host,Pod 内部其他容器的网络指向该容器。
cat <<EOF >./pod-host.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
hostNetwork: true
EOF
运行
$ kubectl apply -f pod-host.yaml -n study-k8s
$ kubectl get pods -n study-k8s -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6d47cff9fd-5bzjq 1/1 Running 0 6m25s 192.168.56.111 kube-server8.zs <none> <none>
$ curl http://192.168.56.111/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
一般情况下除非知道需要某个特定应用占用特定宿主机上的特定端口时才使用 hostNetwork: true 的方式。
hostPort
这是一种直接定义Pod网络的方式。
hostPort 是直接将容器的端口与所调度的节点上的端口路由,这样用户就可以通过宿主机的 IP 加上端口来访问 Pod。
cat <<EOF >./pod-hostPort.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
hostPort: 8000
EOF
运行
$ kubectl apply -f pod-hostPort.yaml -n study-k8s
$ kubectl get pods -n study-k8s -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6d47cff9fd-5bzjq 1/1 Running 0 3m25s 192.168.56.111 kube-server8.zs <none> <none>
$ curl http://192.168.56.111:8000/
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
这种网络方式可以用来做 nginx [Ingress controller]。外部流量都需要通过 kubenretes node 节点的 80 和 443 端口。
hostNetwork 和 hostPort 的对比
相同点
hostNetwork 和 hostPort 的本质都是暴露 Pod 所在的节点 IP 给终端用户。因为 Pod 的生命周期并不固定,随时都有被重构的可能。可以使用 DaemonSet 或者非亲缘性策略,来保证每个 node 节点只有一个Pod 被部署。
不同点
使用 hostNetwork,pod 实际上用的是 pod 宿主机的网络地址空间;
使用 hostPort,pod IP 并非宿主机 IP,而是 cni 分配的 pod IP,跟其他普通的 pod 使用一样的 ip 分配方式,端口并非宿主机网络监听端口,只是使用了 DNAT 机制将 hostPort 指定的端口映射到了容器的端口之上。
Label
Label 是 kubernetes 系统中的一个重要概念。它的作用就是在资源上添加标识,用来对它们进行区分和选择。
Label 可以添加到各种资源对象上,如 Node、Pod、Service、RC 等。Label 通常在资源对象定义时确定,也可以在对象创建后动态添加或删除。当我们给一个对象打了标签之后,随后就可以通过 Label Selector(标签选择器)查询和筛选拥有某些 Label 的资源对象。通过使用 Label 就能实现多维度的资源分组管理功能。
Label Selector 在 Kubernetes 中的重要使用场景如下:
1、Kube-controller 进程通过资源对象RC上定义的 Label Selector 来筛选要监控的 Pod 副本的数量,从而实现 Pod 副本的数量始终符合预期设定的全自动控制流程;
2、Kube-proxy 进程通过 Service 的 Label Selector 来选择对应的 Pod,自动建立起每个 Service 到对应 Pod 的请求转发路由表,从而实现 Service 的智能负载均衡机制;
3、通过对某些 Node 定义特定的 Label,并且在 Pod 定义文件中使用 NodeSelector 这种标签调度策略,kube-scheduler 进程可以实现 Pod “定向调度”的特性。
同时借助于 Label,k8s 中可以实现亲和(affinity)与反亲和(anti-affinity)调度。
亲和性调度
什么是亲和(affinity)与反亲和(anti-affinity)调度
Kubernetes 支持节点和 Pod 两个层级的亲和与反亲和。通过配置亲和与反亲和规则,可以允许您指定硬性限制或者偏好,例如将前台 Pod 和后台 Pod 部署在一起、某类应用部署到某些特定的节点、不同应用部署到不同的节点等等。
在学习亲和性调度之前,首先来看下如何进行打标签的操作
查看节点及其标签
$ kubectl get nodes --show-labels
给节点添加标签
$ kubectl label nodes <your-node-name> nodeName=node9
删除节点的标签
$ kubectl label nodes <your-node-name> nodeName-
查看某个标签的的分布情况
$ kubectl get node -L nodeName
NAME STATUS ROLES AGE VERSION NODENAME
kube-server7.zs Ready <none> 485d v1.19.9 node7
kube-server8.zs Ready <none> 485d v1.19.9 node8
kube-server9.zs Ready master 485d v1.19.9 node9
Node 亲和性调度策略
cat <<EOF >./pod-affinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodeName
operator: In
values:
- node7
- node8
EOF
重点看下下面的
affinity: // 表示亲和
nodeAffinity: // 表示节点亲和
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodeName
operator: In
values:
- node7
- node8
分析下具体的规则
requiredDuringSchedulingIgnoredDuringExecution 非常长,不过可以将这个分作两段来看:
前半段 requiredDuringScheduling 表示下面定义的规则必须强制满足(require)才会调度Pod到节点上;
后半段 IgnoredDuringExecution 表示已经在节点上运行的 Pod 不需要满足下面定义的规则,即去除节点上的某个标签,那些需要节点包含该标签的 Pod 不会被重新调度。
operator 有下面几种取值:
In:标签的值在某个列表中;
NotIn:标签的值不在某个列表中;
Exists:某个标签存在;
DoesNotExist:某个标签不存在;
Gt:标签的值大于某个值(字符串比较);
Lt:标签的值小于某个值(字符串比较)。
需要说明的是并没有 nodeAntiAffinity(节点反亲和),通过 NotIn 和 DoesNotExist 即可实现反亲和性地调度。
requiredDuringSchedulingIgnoredDuringExecution 是一种强制选择的规则。
preferredDuringSchedulingIgnoredDuringExecution 是优先选择规则,表示根据规则优先选择那些节点。
使用 preferredDuringSchedulingIgnoredDuringExecution 规则的时候,我们可以给 label 添加权重,这样 Pod 就能按照设计的规则调度到不同的节点中了。
cat <<EOF >./pod-affinity-weight.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: nodeName
operator: In
values:
- node7
- node9
- weight: 20
preference:
matchExpressions:
- key: nodeName
operator: In
values:
- node8
EOF
上面的栗子可以看到,可以给 label 添加 weight 权重,在 preferredDuringSchedulingIgnoredDuringExecution 的规则下,就能按照我们设计的权重,部署到 label 对应的节点中。
Pod 亲和性调度
除了支持 Node 的亲和性调度,k8s 中还支持 Pod 和 Pod 之间的亲和。
栗如:将应用的前端和后端部署在同一个节点中,从而减少访问延迟。
Pod 亲和同样有 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution 两种规则。
模拟后端的 Pod 部署
cat <<EOF >./pod-affinity-backend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
labels:
app: backend
spec:
replicas: 1
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
EOF
模拟前端的 Pod 部署,使得前端对应的业务使用 Pod 亲和性调度和后端 Pod 部署到一起
cat <<EOF >./pod-affinity-frontend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
replicas: 5
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- backend
EOF
这里把 backend 的 Pod 数量设置成 1,然后 frontend 的 Pod 数量设置成 5。这样来演示 frontend 向 backend 的亲和调度。
$ kubectl get pods -n study-k8s -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
backend-5f489d5d4f-xcv4d 1/1 Running 0 22s 10.233.67.179 kube-server8.zs <none> <none>
frontend-64846f7fbf-6nsmd 1/1 Running 0 33s 10.233.67.181 kube-server8.zs <none> <none>
frontend-64846f7fbf-7pfq7 1/1 Running 0 33s 10.233.67.182 kube-server8.zs <none> <none>
frontend-64846f7fbf-dg7wx 1/1 Running 0 33s 10.233.67.178 kube-server8.zs <none> <none>
frontend-64846f7fbf-q7jd5 1/1 Running 0 33s 10.233.67.177 kube-server8.zs <none> <none>
frontend-64846f7fbf-v4hf9 1/1 Running 0 33s 10.233.67.180 kube-server8.zs <none> <none>
这里有两个点需要注意下
1、topologyKey 表示的指定的范围,指定的也是一个 label,通过指定这个 label 来确定安装的范围;
2、matchExpressions 指定亲和的 Pod,例如上面的栗子就是 app=frontend。
不过这里有个先后顺序,首先匹配 topologyKey,然后匹配下面的 matchExpressions 规则。
Pod 的反亲和性调度
有时候我们希望 Pod 部署到一起,那么我们就会也有希望 Pod 不部署在一起的场景,这时候就需要用到反亲和性调度。
cat <<EOF >./pod-affinity-frontend.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
labels:
app: frontend
spec:
replicas: 5
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- backend
EOF
使用 podAntiAffinity 即可定义反亲和性调度的策略
$ kubectl get pods -n study-k8s -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
backend-5f489d5d4f-xcv4d 1/1 Running 0 108m 10.233.67.179 kube-server8.zs <none> <none>
frontend-567ddb4c45-6mf87 1/1 Running 0 23s 10.233.111.125 kube-server7.zs <none> <none>
frontend-567ddb4c45-fbj6j 1/1 Running 0 23s 10.233.111.124 kube-server7.zs <none> <none>
frontend-567ddb4c45-j5qpb 1/1 Running 0 21s 10.233.72.25 kube-server9.zs <none> <none>
frontend-567ddb4c45-qsc8m 1/1 Running 0 21s 10.233.111.126 kube-server7.zs <none> <none>
frontend-567ddb4c45-sfwjn 1/1 Running 0 23s 10.233.72.24 kube-server9.zs <none> <none>
NodeSelector 定向调度
kubernetes 中 kube-scheduler 负责实现 Pod 的调度,内部系统通过一系列算法最终计算出最佳的目标节点。如果需要将 Pod 调度到指定 Node 上,则可以通过 Node 的标签(Label)和 Pod 的 nodeSelector 属性相匹配来达到目的。
栗如:DaemonSet 中使用到了 NodeSelector 定向调度。
DaemonSet(守护进程),会在每一个节点中运行一个 Pod,同时也能保证只有一个 Pod 运行。
如果有新节点加入集群,Daemonset 会自动的在该节点上运行我们需要部署的 Pod 副本,如果有节点退出集群,Daemonset 也会移除掉部署在旧节点的 Pod 副本。
DaemonSet 适合一些系统层面的应用,例如日志收集,资源监控等,等这类需要每个节点都运行,且不需要太多的实例。
cat <<EOF >./pod-daemonset.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-daemonset
labels:
app: nginx-daemonset
spec:
selector:
matchLabels:
app: nginx-daemonset
template:
metadata:
labels:
app: nginx-daemonset
spec:
nodeSelector: # 节点选择,当节点拥有nodeName=node7时才在节点上创建Pod
nodeName: node7
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
EOF
可以看到 DaemonSet 也是通过 label 来选择部署的目标节点
nodeSelector: # 节点选择,当节点拥有nodeName=node7时才在节点上创建Pod
nodeName: node7
如果不添加目标节点,那么就是在所有节点中进行部署了。
资源限制
每个 Pod 都可以对其能使用的服务器上的计算资源设置限额,当前可以设置限额的计算资源有 CPU 和 Memory 两种,其中 CPU 的资源单位为 CPU(Core)的数量,是一个绝对值。
对于容器来说一个 CPU 的配额已经是相当大的资源配额了,所以在 Kubernetes 里,通常以千分之一的 CPU 配额为最小单位,用 m 来表示。通常一个容器的CPU配额被 定义为 100-300m,即占用0.1-0.3个CPU。与 CPU 配额类似,Memory 配额也是一个绝对值,它的单位是内存字节数。
对计算资源进行配额限定需要设定以下两个参数:
Requests:该资源的最小申请量,系统必须满足要求。
Limits:该资源最大允许使用的量,不能超过这个使用限制,当容器试图使用超过这个量的资源时,可能会被Kubernetes Kill并重启。
通常我们应该把 Requests 设置为一个比较小的数值,满足容器平时的工作负载情况下的资源需求,而把 Limits 设置为峰值负载情况下资源占用的最大量。下面是一个资源配额的简单定义:
spec:
containers:
- name: db
image: mysql
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
最小0.25个CPU及64MB内存,最大0.5个CPU及128MB内存。
当然 CPU 的指定也可以不使用 m。cpu: "2",就表示 2 个 cpu。
添加资源限制的目的
在业务流量请求较低的时候,释放多余的资源。当有一些突发性的活动,就能根据资源占用情况,申请合理的资源。
Pod 的持久化存储
volume 是 kubernetes Pod 中多个容器访问的共享目录。volume 被定义在 pod 上,被这个 pod 的多个容器挂载到相同或不同的路径下。volume 的生命周期与 pod 的生命周期相同,pod 内的容器停止和重启时一般不会影响 volume 中的数据。所以一般 volume 被用于持久化 pod 产生的数据。Kubernetes 提供了众多的 volume 类型,包括 emptyDir、hostPath、nfs、glusterfs、cephfs、ceph rbd 等。
1、emptyDir
emptyDir 类型的 volume 在 pod 分配到 node 上时被创建,kubernetes 会在 node 上自动分配 一个目录,因此无需指定宿主机 node 上对应的目录文件。这个目录的初始内容为空,当 Pod 从 node 上移除时,emptyDir 中的数据会被永久删除。emptyDir Volume 主要用于某些应用程序无需永久保存的临时目录,多个容器的共享目录等。
容器的 crashing 事件并不会导致 emptyDir 中的数据被删除。
配置示例
cat <<EOF >./pod-emptyDir.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: liz2019/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
EOF
2、hostPath
hostPath Volume 为 pod 挂载宿主机上的目录或文件,使得容器可以使用宿主机的高速文件系统进行存储。缺点是,在 k8s 中,pod 都是动态在各 node 节点上调度。当一个 pod 在当前 node 节点上启动并通过 hostPath 存储了文件到本地以后,下次调度到另一个节点上启动时,就无法使用在之前节点上存储的文件。
配置示例
cat <<EOF >./pod-hostPath.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: liz2019/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: test-volume
volumes:
- name: test-volume
hostPath:
# directory location on host
path: /data-test
EOF
3、Pod 持久化存储
1、 pod直接挂载nfs-server
我们能将 NFS (网络文件系统) 挂载到Pod 中,不像 emptyDir 那样会在删除 Pod 的同时也会被删除,nfs 卷的内容在删除 Pod 时会被保存,卷只是被卸载。 这意味着 nfs 卷可以被预先填充数据,并且这些数据可以在 Pod 之间共享,NFS 卷可以由多个pod同时挂载。
cat <<EOF >./pod-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: liz2019/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: test-nfs
volumes:
- name: test-nfs
nfs:
path: /data-test
server: 192.268.56.111
EOF
2、pv 和 pvc
具体什么是 pv 和 pvc,可参见 pv和pvc
创建 pv
cat <<EOF >./pv-demp.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv001
labels:
name: pv001
spec:
nfs:
path: /data/volumes/v1
server: nfs
accessModes: ["ReadWriteMany","ReadWriteOnce"]
capacity:
storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv002
labels:
name: pv002
spec:
nfs:
path: /data/volumes/v2
server: nfs
accessModes: ["ReadWriteOnce"]
capacity:
storage: 1Gi
EOF
创建 pvc
cat <<EOF >./pvc-demp.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: testpvc
namespace: default
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 1Gi
EOF
业务绑定 pvc
cat <<EOF >./pod-pvc-cache.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: liz2019/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: test-pvc-cache
volumes:
- name: test-pvc-cache
persistentVolumeClaim:
claimName: testpvc
EOF
Pod 的探针
k8s 中当 Pod 的运行出现异常的时候,需要能够检测到 Pod 的这种状态,将流量路由到其他正常的 Pod 中,同时去恢复损坏的组件。
默认情况下,Kubernetes 会观察 Pod 生命周期,并在容器从挂起(pending)状态转移到成功(succeeded)状态时,将流量路由到 Pod。Kubelet 会监控崩溃的应用程序,并重新启动 Pod 进行恢复。
但是 Pod 的健康并不代表,Pod 中所有的容器都已经专准备好了,例如,这时候的应用可能正在启动,处于连接数据库的状态中,处于编译的状态中,这时候打进来的流量,得到的返回肯定就是异常的了。
k8s 中引入了活跃(Liveness)、就绪(Readiness)和启动(Startup)探针来解决上面的问题。
存活探针:主要来检测容器中的应用程序是否正常运行,如果检测失败,就会使用 Pod 中设置的 restartPolicy 策略来判断,Pod是否要进行重启, 例如,存活探针可以探测到应用死锁。
就绪探针:可以判断容器已经启动就绪能够接收流量请求了,当一个 Pod 中所有的容器都就绪的时候,才认为该 Pod 已经就绪了。就绪探针就能够用来避免上文中提到的,应用程序未完全就绪,然后就有流量打进来的情况发生。
启动探针:kubelet 使用启动探针来了解应用容器何时启动。启动探针主要是用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。
如果启动探测失败,kubelet 将杀死容器,而容器依其重启策略进行重启。
在配置探针之前先来看下几个主要的配置
initialDelaySeconds:容器启动后要等待多少秒后才启动存活和就绪探针, 默认是 0 秒,最小值是 0;
periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1;
timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1;
successThreshold:探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1;
failureThreshold:将探针标记为失败之前的重试次数。对于 liveness 探针,这将导致 Pod 重新启动。对于 readiness 探针,将标记 Pod 为未就绪(unready)。
目前 ReadinessProbe 和 LivenessProbe 都支持下面三种探测方法
ExecAction:在容器中执行指定的命令,如果能成功执行,则探测成功;
HTTPGetAction:通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码200-400,则认为容器探测成功;
TCPSocketAction:通过容器IP地址和端口号执行TCP检查,如果能建立TCP连接,则探测成功;
gRPC 活跃探针:在 Kubernetes v1.24 [beta]中引入了,gRPC 活跃探针,如果应用实现了 gRPC 健康检查协议 ,kubelet 可以配置为使用该协议来执行应用活跃性检查。不过使用的时候需要先开启。
这里来看下使用 HTTPGetAction 的方式,来看下存活探针和就绪探针的配置,其他的可参考配置存活、就绪和启动探针
cat <<EOF >./pod-test-go-liveness.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: test-go-liveness
name: test-go-liveness
namespace: study-k8s
spec:
replicas: 5
selector:
matchLabels:
app: go-web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: go-web
spec:
containers:
- image: liz2019/test-go-liveness
name: test-go-liveness
livenessProbe: # 活跃探针
httpGet:
path: /healthz
port: 8001
initialDelaySeconds: 15
periodSeconds: 10
timeoutSeconds: 5
readinessProbe: # 存活探针
httpGet:
path: /healthz
port: 8001
initialDelaySeconds: 5 # 容器启动后多少秒启动探针
periodSeconds: 10 # 执行探针检测的时间建个间隔
timeoutSeconds: 5 # 探测的超时后等待多少秒
status: {}
EOF
可以看到上面同时设置了存活探针和就绪探针;
对于镜像中的代码设置了超过十秒即返回错误,这样上面的示例就能模拟探针检测失败,然后重启的效果了
func healthz(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
w.Header().Set("Content-Type", "application/json; charset=utf-8")
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
}
查看 Pod 的重启情况
kubectl get pods -n study-k8s
NAME READY STATUS RESTARTS AGE
test-go-liveness-66755487cd-ck4mz 0/1 CrashLoopBackOff 6 11m
test-go-liveness-66755487cd-f54lz 0/1 CrashLoopBackOff 6 11m
test-go-liveness-66755487cd-hts8k 0/1 CrashLoopBackOff 7 11m
test-go-liveness-66755487cd-jzsmb 0/1 Running 7 11m
test-go-liveness-66755487cd-k9hdk 1/1 Running 7 11m
下面在简单看下启动探针的配置
ports:
- name: liveness-port
containerPort: 8080
hostPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30 # 将探针标记为失败之前的重试次数
periodSeconds: 10 # 执行探测的时间间隔(单位是秒)
上面配置了启动探针,那么程序就会有 30 * 10 = 300s 来完成启动过程。 一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁作出快速响应。 如果启动探测一直没有成功,容器会在 300 秒后被杀死,并且根据 restartPolicy 来 执行进一步处置。
使用 HPA 实现 Pod 的自动扩容
我们通过手动更改 RS 副本集的大小就能实现 Pod 的扩容,但是这是我们手动操作的,人工不可能24小时不间断的检测业务的复杂变化。所以需要自动扩容的机制,能够根据业务的变化,自动的实现 Pod 的扩容和缩容。
Kubernetes 提供 Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称 HPA。通过使用 HPA 可以自动缩放在 Replication Controller,Deployment 或者 Replica Set 中的 Pod。HPA 将自动缩放正在运行的 Pod 的数量,以实现最高效率。
HPA 中影响 Pod 数量的因素包括:
用户定义的允许运行的 Pod 的最小和最大数量;
资源指标中报告的观察到的 CPU 或内存使用情况;
第三方指标应用程序(例如 Prometheus,Datadog 等)提供的自定义指标。
HPA 是如何工作的
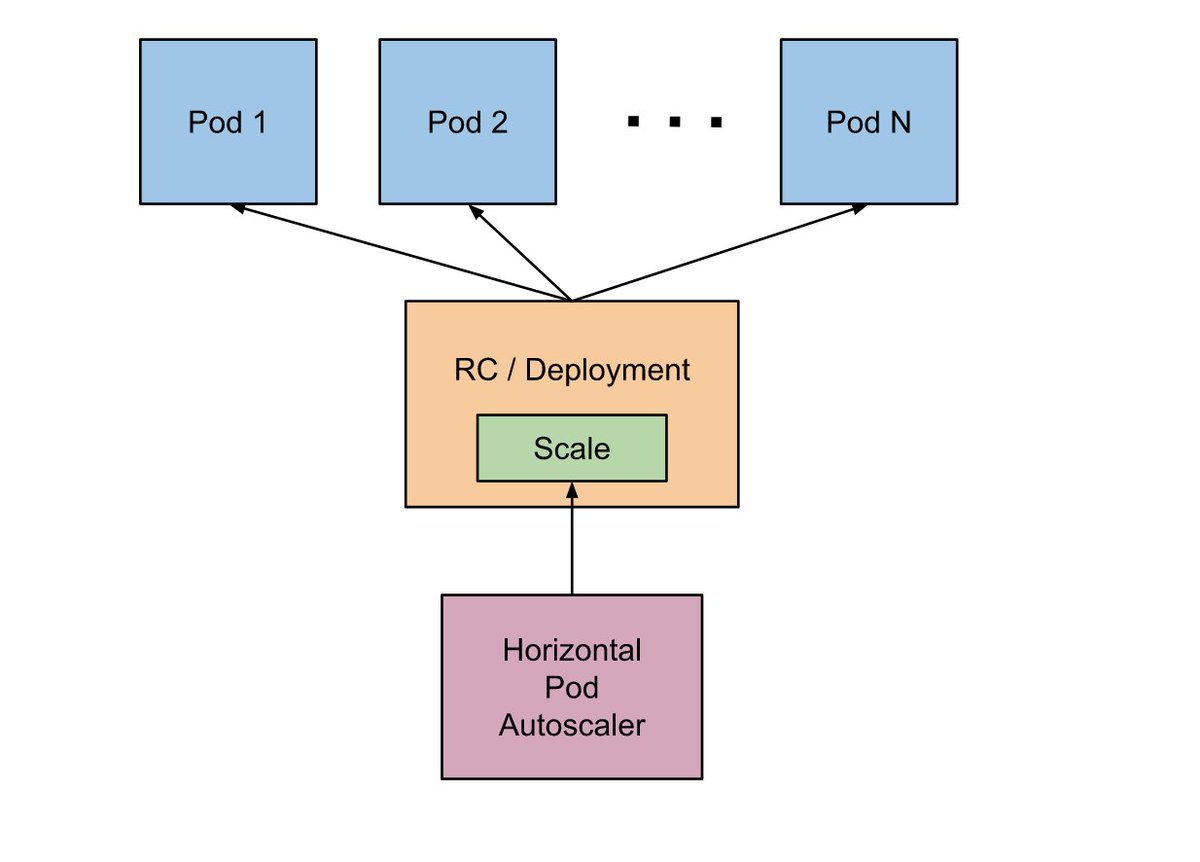
HPA 是用来控制 Pod 水平伸缩的控制器,基于设定的扩缩容规则,实时采集监控指标数据,根据用户设定的指标阈值计算副本数,进而调整目标资源的副本数量,完成扩缩容操作。
算法的细节
Pod 水平自动扩缩控制器根据当前指标和期望指标来计算扩缩比例
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]
例如,如果当前指标值为 200m,而期望值为 100m,则副本数将加倍, 因为 200.0 / 100.0 == 2.0 如果当前值为 50m,则副本数将减半, 因为 50.0 / 100.0 == 0.5。如果比率足够接近 1.0(在全局可配置的容差范围内,默认为 0.1), 则控制平面会跳过扩缩操作。
如果 HorizontalPodAutoscaler 指定的是 targetAverageValue 或 targetAverageUtilization, 那么将会把指定 Pod 度量值的平均值做为当前指标。
HPA 控制器执行扩缩操作并不是马上完成的,会有一个扩缩操作的时间窗口。首先每次的扩缩操作建议会被记录,在扩缩操作的时间窗口内,会根据规则选出一个缩容的策略。这样就能让系统更平滑的进行扩缩操作,消除短时间内指标波动带来的影响。时间窗口的值可通过 kube-controller-manager 服务的启动参数 --horizontal-pod-autoscaler-downscale-stabilization 进行配置, 默认值为 5 分钟。
来个栗子实践下
cat <<EOF >./pod-hpa.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: go-web
name: go-web
namespace: study-k8s
spec:
replicas: 5
selector:
matchLabels:
app: go-web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: go-web
spec:
containers:
- image: liz2019/test-docker-go-hub
name: go-app-container
resources:
requests:
cpu: 0.1
memory: 50Mi
limits:
cpu: 0.2
memory: 100Mi
status: {}
---
apiVersion: v1
kind: Service
metadata:
name: go-web-svc
labels:
run: go-web-svc
spec:
selector:
app: go-web
type: NodePort # 服务类型
ports:
- protocol: TCP
port: 8000
targetPort: 8000
nodePort: 30001 # 对外暴露的端口
name: go-web-http
EOF
配置 HPA 策略
cat <<EOF >./pod-hpa-config.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: go-web-hpa
namespace: study-k8s
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: go-web
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
EOF
关于 HPA 的版本支持
autoscaling/v1只支持CPU一个指标的弹性伸缩;
autoscaling/v2beta1支持自定义指标;
autoscaling/v2beta2支持外部指标;
总结
1、Pod 是 Kubernetes 集群中能够被创建和管理的最小部署单元;
2、通常使用控制起来管理 Pod,来实现 Pod 的滚动升级,副本管理,集群级别的自愈能力;
3、Deployment 可以用来创建一个新的服务,更新一个新的服务,也可以用来滚动升级一个服务。借助于 ReplicaSet 也可以实现 Pod 的副本管理功能;
4、静态 Pod 是由 kubelet 进行管理的仅存在与特定 node 上的 Pod,他们不能通过 api server 进行管理,无法与 rc,deployment,ds 进行关联,并且 kubelet 无法对他们进行健康检查;
5、静态 Pod 主要是用来对集群中的组件进行容器化操作,例如 etcd kube-apiserver kube-controller-manager kube-scheduler 这些都是静态 Pod 资源;
6、Pod 一般不直接对外暴露服务,一个 Pod 只是一个运行服务的实例,随时可能在节点上停止,然后再新的节点上用一个新的 IP 启动一个新的 Pod,因此不能使用确定的 IP 和端口号提供服务;
7、Pod 中可以使用 hostNetwork 和 hostPort,可以直接暴露 node 的 ip 地址;
8、Label 是 kubernetes 系统中的一个重要概念。它的作用就是在资源上添加标识,用来对它们进行区分和选择;
9、Kubernetes 支持节点和 Pod 两个层级的亲和与反亲和。通过配置亲和与反亲和规则,可以允许您指定硬性限制或者偏好,例如将前台 Pod 和后台 Pod 部署在一起、某类应用部署到某些特定的节点、不同应用部署到不同的节点等等;
10、为了合理的利用 k8s 中的资源,一般会对 Pod 添加资源限制;
11、k8s 中当 Pod 的运行出现异常的时候,需要能够检测到 Pod 的这种状态,将流量路由到其他正常的 Pod 中,同时去恢复损坏的组件,这种情况可以通过 K8s 中的探针去解决;
12、面对业务情况的变化,使用 HPA 实现 Pod 的自动扩容;
参考
【初识Kubernetes(K8s):各种资源对象的理解和定义】https://blog.51cto.com/andyxu/2329257
【Kubernetes系列学习文章 - Pod的深入理解(四)】https://cloud.tencent.com/developer/article/1443520
【详解 Kubernetes Pod 的实现原理】https://draveness.me/kubernetes-pod/
【Kubernetes 之Pod学习】https://www.cnblogs.com/kevingrace/p/11309409.html
【亲和与反亲和调度】https://support.huaweicloud.com/intl/zh-cn/basics-cce/kubernetes_0018.html
【hpa】https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
【k8s中的Pod细节了解】https://boilingfrog.github.io/2022/09/23/k8s中的Pod细节了解/
k8s 中的 Pod 细节了解的更多相关文章
- 如何为k8s中的pod配置QoS等级?
1.概述 本文介绍如何为pod分配特定的QoS等级. 我们知道,在k8s的环境中,通过使用QoS等级来做决定,在资源紧张的时候,将哪些的pod进行驱逐,或者说如何对pod进行调度. OK,话不多说,让 ...
- k8s中删除pod后仍然存在问题
分析: 是因为删除了pod,但是没有删除对应的deployment,删除对应的deployment即可 实例如下: 删除pod [root@test2 ~]# kubectl get pod -n j ...
- 在k8s中收集jvm异常dump文件到OSS
现状 加参数 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=logs/test.dump 可以实现在jvm发生内存错误后 会生成dump文件 方便开 ...
- k8s 中的 ingress 使用细节
k8s中的ingress 什么是ingress Ingress 如何使用 ingress 使用细节 参考 k8s中的ingress 什么是ingress k8s 中使用 Service 为相同业务的 ...
- 新版的K8S中的flannel.yaml文件中要注意的细节
部署flannel作为k8s中的网络插件,yaml文件都大小同异. 但在要注意以下细节. 以前,只需要前面master判断. 现在也需要有not-ready状态了. tolerations: - ke ...
- k8s中pod内dns无法解析的问题
用k8s创建了pod,然后进入pod后,发现在pod中无法解析www.baidu.com,也就是出现了无法解析外面的域名的问题.经过高人指点,做个小总结.操作如下. 一,将CoreDNS 的Confi ...
- K8s中Pod健康检查源代码分析
了解k8s中的Liveness和Readiness Liveness: 表明是否容器正在运行.如果liveness探测为fail,则kubelet会kill掉容器,并且会触发restart设置的策略. ...
- k8s中ingress,service,depoyment,pod如何关联
k8s中pod通过label标签名称来识别关联,它们的label name一定是一样的.ingress,service,depoyment通过selector 中app:name来关联 1.查询发布 ...
- k8s中几个基本概念的理解,pod,service,deployment,ingress的使用场景
k8s 总体概览 前言 Pod 副本控制器(Replication Controller,RC) 副本集(Replica Set,RS) 部署(Deployment) 服务(Service) ingr ...
随机推荐
- 一文读懂数仓中的pg_stat
摘要:GaussDB(DWS)在SQL执行过程中,会记录表增删改查相关的运行时统计信息,并在事务提交或回滚后记录到共享的内存中.这些信息可以通过 "pg_stat_all_tables视图& ...
- Spring Boot 知识点总结
现在仅总结重要和实用的知识点,更加全面的请见链接:1.:2.. 微服务:架构风格(服务微化):一个应用应该是一组小型服务:可以通过HTTP的方式进行互通:微服务:每一个功能元素终都是一个可独立替换和独 ...
- C++实现ETW进行进程变动监控
C++实现ETW进行进程变动监控 文章地址:https://www.cnblogs.com/Icys/p/EtwProcess.html 何为Etw ETW(Event Tracing for Win ...
- day02 Java_变量
参考: 变量的练习: 声明一个变量,一次声明多个变量. 声明变量直接初始化,先声明变量,而后再给变量初始化. 声明整型变量g,声明另一个整型变量h并赋值为h+10,输出变量h的值. 声明整型变量i,在 ...
- 开发中常用的两个JSON方法
参考文章:https://juejin.cn/post/6844903711127404557 在前端开发过程中,有两个非常有用的方法来处理 JSON 格式的内容: JSON.parse(string ...
- AI全流程开发难题破解之钥
摘要:通过对ModelArts.盘古大模型.ModelBox产品技术的解读,帮助开发者更好的了解AI开发生产线. 本文分享自华为云社区<[大厂内参]第16期:华为云AI开发生产线,破解AI全流程 ...
- python面向对象的特征及反射
目录 派生类实操 面向对象特征之封装 property伪装属性(python内置装饰器) 面向对象特征之多态 面向对象之反射 派生类实操 1.将时间字典序列化成json格式,由于序列化数据类型的要求, ...
- doc或docx(word)或image类型文件批量转PDF脚本
doc或docx(word)或image类型文件批量转PDF脚本 1.实际生产环境中遇到文件展示只能适配PDF版本的文件,奈何一万个文件有七千个都是word或者image类型的,由此搞个脚本批量转换下 ...
- Apache DolphinScheduler之最美好的遇见
关于 Apache DolphinScheduler社区 Apache DolphinScheduler(incubator) 于17年在易观数科立项,19年3月开源, 19 年8月进入Apache ...
- C#/VB.NET 替换 PDF 文件上的现有图像
我们都知道对PDF文件进行修改和编辑不是一件容易的事.但有时当我们想用新的图像来替换PDF文件上的现有图像时,该怎么办呢?别担心,本文将向您展示如何在 C#/VB.NET 中替换 PDF 文件中的现有 ...