我不就是吃点肉,应该没事吧——爬取一座城市里的烤肉店数据(附完整Python爬虫代码)
写在前面的一点屁话:
对于肉食主义者,吃肉简直幸福感爆棚!特别是烤肉,看着一块块肉慢慢变熟,听着烤盘上“滋滋”的声响,这种期待感是任何其他食物都无法带来的。如果说甜点是“乍见之欢”,那肉则是“久处不厌”。
为了造福“烤肉控”们,今天就用Python爬取一座城市的烤肉店数据,选出最适合的一家烤肉店!
准备工作
环境
- python 3.6
- pycharm
- requests >>> 发送请求 pip install requests
- csv >>> 保存数据
了解爬虫最基本的思路
一. 数据来源分析
- 确定我们爬取的内容是什么?
爬取店铺数据 - 去找这些东西是从哪里来的
通过开发者工具进行抓包分析, 分析数据来源
二. 代码实现过程 - 发送请求, 对于找到数据包发送请求
- 获取数据, 根据服务器给你返回的response数据来的
- 解析数据, 提取我们想要的内容数据
- 保存数据, 保存到csv文件
- 多页爬取, 根据url地址参数变化
代码实现过程
- 发送请求
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': 32,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
# 请求头 都是可以从开发者工具里面直接复制粘贴
# ser-Agent: 浏览器的基本信息
headers = {
'Referer': 'https://chs.某tuan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
200 表示请求成功 状态码 403 你没有访问权限
2. 获取数据
print(response.json())
3. 解析数据
result = response.json()['data']['searchResult']
# [] 列表 把里面每个元素都提取出来 for循环遍历
for index in result:
# pprint.pprint(index)
# f'{}' 字符串格式化
index_url = f'https://www.某tuan.com/meishi/{index["id"]}/'
# ctrl + D
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)
4. 保存数据
f = open('烤肉数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader() # 写入表头
5.翻页
for page in range(0, 1025, 32):
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
运行代码得到数据

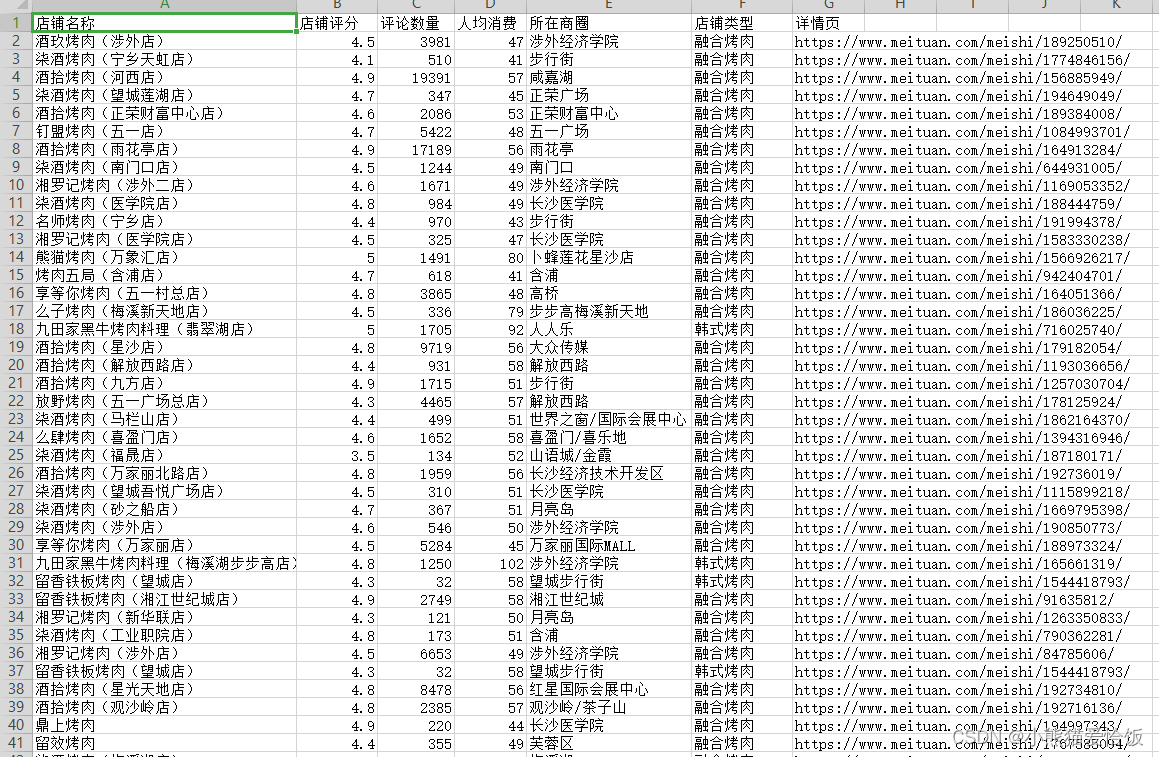
完整代码
f = open('烤肉数据1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'店铺评分',
'评论数量',
'人均消费',
'所在商圈',
'店铺类型',
'详情页',
])
csv_writer.writeheader() # 写入表头
for page in range(0, 1025, 32):
url = 'https://apimobile.某tuan.com/group/v4/poi/pcsearch/70'
data = {
'uuid': '6e481fe03995425389b9.1630752137.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '烤肉',
'token': '4MJy5kaiY_0MoirG34NJTcVUbz0AAAAAkQ4AAF4NOv8TNNdNqymsxWRtJVUW4NjQFW35_twZkd49gZqFzL1IOHxnL0s4hB03zfr3Pg',
}
headers = {
'Referer': 'https://chs.某tuan.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, params=data, headers=headers)
# 200 表示请求成功 状态码 403 你没有访问权限
result = response.json()['data']['searchResult']
# [] 列表 把里面每个元素都提取出来 for循环遍历
for index in result:
# pprint.pprint(index)
# f'{}' 字符串格式化
index_url = f'https://www.meituan.com/meishi/{index["id"]}/'
# ctrl + D
dit = {
'店铺名称': index['title'],
'店铺评分': index['avgscore'],
'评论数量': index['comments'],
'人均消费': index['avgprice'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)我不就是吃点肉,应该没事吧——爬取一座城市里的烤肉店数据(附完整Python爬虫代码)的更多相关文章
- 32个Python爬虫项目让你一次吃到撑
整理了32个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快~O(∩_∩)O WechatSogou [1]- 微信公众 ...
- python多线程爬取世纪佳缘女生资料并简单数据分析
一. 目标 作为一只万年单身狗,一直很好奇女生找对象的时候都在想啥呢,这事也不好意思直接问身边的女生,不然别人还以为你要跟她表白啥的,况且工科出身的自己本来接触的女生就少,即使是挨个问遍,样本量也 ...
- 用Python来揭秘吃瓜群众是如何看待罗志祥事件的
前言 最近娱乐圈可以说得上是热闹非凡,前有霸道总裁爱小三,正宫撕逼网红女,后有阳光大男孩罗志祥,被周扬青扒的名声扫地.贵圈的爱情故事,常人是难以理解的,正如贾旭明张康这段相声所说的这样,娱乐圈的爱情总 ...
- 【转】亿欧盘点:杭州十家代表性O2O企业
[ 亿欧导读 ] 11月13日亿欧网将走入杭州,联合B座12楼.正和岛召开“2014 中国O2O新商业峰会“.亿欧网据O2O产业图谱,整理出杭州十家O2O企业:点我吧.快的打车.杭州19楼.婚礼纪.淘 ...
- linux就是这个范儿之融于心而表于行(1)
原创作品,允许转载,转载时请务必以超链接形式标明文章原始出处 .作者信息和本声明.否则将追究法律责 时间总是过得那么快,如流水一般哗啦啦的就淌走了一大堆!周遭事事沧桑变迁喧哗或耳语中流传的故事已渐模糊 ...
- 【原创】Thinking in BigData (1)大数据简介
提到大数据,就不得不提到Hadoop,提到Hadoop,就不得不提到Google公布的3篇研究论文:GFS.MapReduce.BigTable,Google确实是一家伟大的公司,开启了全球的大数据时 ...
- python之路——16
王二学习python的笔记以及记录,如有雷同,那也没事,欢迎交流,wx:wyb199594 学习内容 1.内置函数 1. python 数据类型:int bool 数据结构:dic list tupl ...
- 一入爬虫深似海,从此游戏是路人!总结我的python爬虫学习笔记!
前言 还记得是大学2年级的时候,偶然之间看到了学长在学习python:我就坐在旁边看他敲着代码,感觉很好奇.感觉很酷,从那之后,我就想和学长一样的厉害,就想让学长教我,请他吃了一周的饭,他答应了.从此 ...
- 年薪20万Python工程师进阶(7):Python资源大全,让你相见恨晚的Python库
我是 环境管理 管理 Python 版本和环境的工具 pyenv – 简单的 Python 版本管理工具. Vex – 可以在虚拟环境中执行命令. virtualenv – 创建独立 Python 环 ...
随机推荐
- Blazor Bootstrap 组件库语音组件介绍
Speech 语音识别与合成 通过麦克风语音采集转换为文字(STT),或者通过文字通过语音朗读出来(TTS) 本组件依赖于 BootstrapBlazor.AzureSpeech,使用本组件时需要引用 ...
- SSM整合_年轻人的第一个增删改查_查找
写在前面 SSM整合_年轻人的第一个增删改查_基础环境搭建 SSM整合_年轻人的第一个增删改查_查找 SSM整合_年轻人的第一个增删改查_新增 SSM整合_年轻人的第一个增删改查_修改 SSM整合_年 ...
- 代码源 BFS练习1
BFS练习1 http://oj.daimayuan.top/course/11/problem/147 题目 思路 四个方向进行BFS 注意:此题读写量大,cin会被卡 代码 #include &l ...
- Hoo Smart Chain 万物生长计划火热报名中,可视化公链迸发勃勃生机
在DeFi越来越趋向同质化和静态化时,Hoo Smart Chain决定充当破局者,宣布决定All In元宇宙,并于2022年3月份开启面向全球去中心化开发者的奖励计划--「万物生长计划」 目前Ter ...
- 终极套娃 2.0|云原生 PaaS 平台的可观测性实践分享
某个周一上午,小涛像往常一样泡上一杯热咖啡 ️,准备打开项目协同开始新一天的工作,突然隔壁的小文喊道:"快看,用户支持群里炸锅了 -" 用户 A:"Git 服务有点问题, ...
- Linux根目录下各文件目录的作用
bin 用户二进制可执行文件 boot 系统启动引导文件 dev[device] 系统中使用的外部设备,但不是放的外部设备的驱动.一个访问这些外部 ...
- Linux学习教程 | 全文目录
本教程最大的特点是通俗易懂,并且非常详细,花费 7 天时间即可快速了解 Linux. 第一章 Linux简介 1.1 操作系统是什么,操作系统概述 1.2 Linux是什么,有哪些特点? 1.3 Li ...
- epoll 函数解析
本文参考社长的 TinyWebServer 庖丁解牛 epoll 常用API epoll_create 函数 #include <sys/epoll.h> int epoll_create ...
- Docker 与 K8S学习笔记(二十三)—— Kubernetes集群搭建
小伙伴们,好久不见,这几个月实在太忙,所以一直没有更新,今天刚好有空,咱们继续k8s的学习,由于我们后面需要深入学习Pod的调度,所以我们原先使用MiniKube搭建的实验环境就不能满足我们的需求了, ...
- flask实现python方法转换服务
一.flask安装 pip install flask 二.flask简介: flask是一个web框架,可以通过提供的装饰器@server.route()将普通函数转换为服务 flask是一个web ...