5.Mongodb聚合
聚合 aggregate
- 聚合(aggregate)主要用于计算数据,类似sql中的sum()、avg()
- 语法
db.集合名称.aggregate([{管道:{表达式}}])
1、管道
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入
ps ajx | grep mongo
- 在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
- 常用管道
- $group:将集合中的文档分组,可用于统计结果
- $match:过滤数据,只输出符合条件的文档
- $project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- $sort:将输入文档排序后输出
- $limit:限制聚合管道返回的文档数
- $skip:跳过指定数量的文档,并返回余下的文档
- $unwind:将数组类型的字段进行拆分
2、表达式
- 处理输入文档并输出
- 语法
表达式:'$列名'
- 常用表达式
- $sum:计算总和,$sum:1同count表示计数
- $avg:计算平均值
- $min:获取最小值
- $max:获取最大值
- $push:在结果文档中插入值到一个数组中
- $first:根据资源文档的排序获取第一个文档数据
- $last:根据资源文档的排序获取最后一个文档数据
3、$group
- 将集合中的文档分组,可用于统计结果
- _id表示分组的依据,使用某个字段的格式为'$字段'
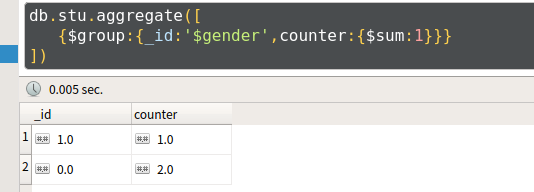
- 例1:统计男生、女生的总人数
db.stu.aggregate([
{$group:
{
_id:'$gender',
counter:{$sum:}
}
}
])
Group by null
- 将集合中所有文档分为一组
- 例2:求学生总人数、平均年龄
db.stu.aggregate([
{$group:
{
_id:null,
counter:{$sum:},
avgAge:{$avg:'$age'}
}
}
])
透视数据
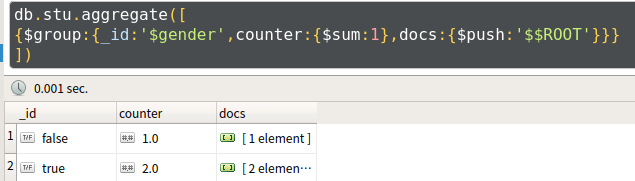
- 例3:统计学生性别及学生姓名
db.stu.aggregate([
{$group:
{
_id:'$gender',
name:{$push:'$name'}
}
}
])

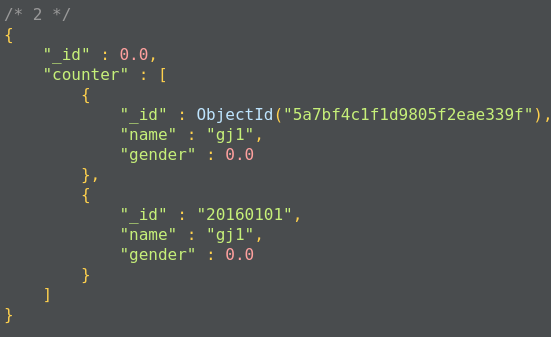
- 使用$$ROOT可以将文档内容加入到结果集的数组中,代码如下
db.stu.aggregate([
{$group:
{
_id:'$gender',
name:{$push:'$$ROOT'}
}
}
])

4、$match
- 用于过滤数据,只输出符合条件的文档
- 使用MongoDB的标准查询操作
例1:查询年龄大于20的学生
db.stu.aggregate([
{$match:{age:{$gt:}}}
])
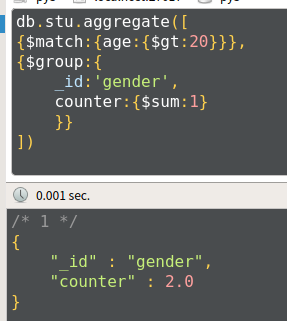
例2:查询年龄大于20的男生、女生人数
db.stu.aggregate([
{$match:{age:{$gt:}}},
{$group:{_id:'$gender',counter:{$sum:}}}
])
5、$project
- 修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
例1:查询学生的姓名、年龄
db.stu.aggregate([
{$project:{_id:,name:,age:}}
])
例2:查询男生、女生人数,输出人数
db.stu.aggregate([
{$group:{_id:'$gender',counter:{$sum:}}},
{$project:{_id:,counter:}}
])

6、$sort
- 将输入文档排序后输出
例1:查询学生信息,按年龄升序
b.stu.aggregate([{$sort:{age:1}}])
例2:查询男生、女生人数,按人数降序
db.stu.aggregate([
{$group:{_id:'$gender',counter:{$sum:}}},
{$sort:{counter:-}}
])

7、$limit
- 限制聚合管道返回的文档数
- 例1:查询2条学生信息
db.stu.aggregate([{$limit:2}])
8、$skip
- 跳过指定数量的文档,并返回余下的文档
例2:查询从第3条开始的学生信息
db.stu.aggregate([{$skip:2}])
例3:统计男生、女生人数,按人数升序,取第二条数据
db.stu.aggregate([
{$group:{_id:'$gender',counter:{$sum:}}},
{$sort:{counter:}},
{$skip:},
{$limit:}
])
- 注意顺序:先写skip,再写limit

9、$unwind
- 将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法1
- 对某字段值进行拆分
db.集合名称.aggregate([{$unwind:'$字段名称'}])
- 构造数据
db.t2.insert({_id:1,item:'t-shirt',size:['S','M','L']})
- 查询
db.t2.aggregate([{$unwind:'$size'}])
语法2
- 对某字段值进行拆分
- 处理空数组、非数组、无字段、null情况
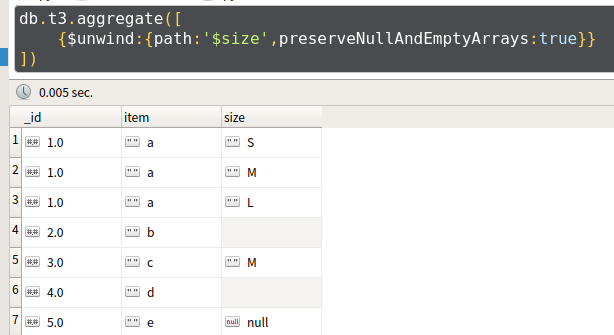
db.inventory.aggregate([{
$unwind:{
path:'$字段名称',
preserveNullAndEmptyArrays:<boolean>#防止数据丢失
}
}])
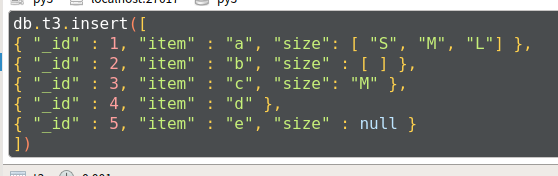
- 构造数据
db.t3.insert([
{ "_id" : , "item" : "a", "size": [ "S", "M", "L"] },
{ "_id" : , "item" : "b", "size" : [ ] },
{ "_id" : , "item" : "c", "size": "M" },
{ "_id" : , "item" : "d" },
{ "_id" : , "item" : "e", "size" : null }
])
- 使用语法1查询
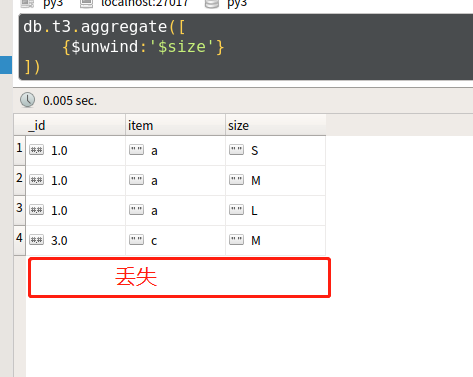
db.t3.aggregate([{$unwind:'$size'}])
- 查看查询结果,发现对于空数组、无字段、null的文档,都被丢弃了
- 问:如何能不丢弃呢?
- 答:使用语法2查询


10、实验

5.Mongodb聚合的更多相关文章
- MongoDB 聚合管道(Aggregation Pipeline)
管道概念 POSIX多线程的使用方式中, 有一种很重要的方式-----流水线(亦称为"管道")方式,"数据元素"流串行地被一组线程按顺序执行.它的使用架构可参考 ...
- Mongodb学习笔记四(Mongodb聚合函数)
第四章 Mongodb聚合函数 插入 测试数据 ;j<;j++){ for(var i=1;i<3;i++){ var person={ Name:"jack"+i, ...
- mongodb MongoDB 聚合 group
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- MongoDB 聚合
聚合操作过程中的数据记录和计算结果返回.聚合操作分组值从多个文档,并可以执行各种操作,分组数据返回单个结果.在SQL COUNT(*)和group by 相当于MongoDB的聚集. aggregat ...
- MongoDB聚合
--------------------MongoDB聚合-------------------- 1.aggregate(): 1.概念: 1.简介 ...
- MongoDB 聚合分组取第一条记录的案例及实现
关键字:MongoDB: aggregate:forEach 今天开发同学向我们提了一个紧急的需求,从集合mt_resources_access_log中,根据字段refererDomain分组,取分 ...
- mongodb MongoDB 聚合 group(转)
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- mongodb聚合 group
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.collection.agg ...
- MongoDB 聚合(管道与表达式)
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). aggregate() 方法 MongoDB中 ...
- 【Mongodb教程 第十一课 】MongoDB 聚合
聚合操作过程中的数据记录和计算结果返回.聚合操作分组值从多个文档,并可以执行各种操作,分组数据返回单个结果.在SQL COUNT(*)和group by 相当于MongoDB的聚集. aggregat ...
随机推荐
- centos7.4 系统安装指导
centos7 系统安装指导 安装前规划 下载安装文件 安装过程设置 安装后系统基本设置 安装前规划 CentOS 7.x系列只有64位系统,没有32位. 生产服务器建议安装CentOS-7-x86_ ...
- ICCV 2017 Best Paper Awards
[ICCV 2017 Best Paper Awards]今年的ICCV不久前公布了Best Paper得主,來自Facebook AI Research的Mask R-CNN[1],與RetineN ...
- 温故而知新:Asp.Net中如何正确使用Session
原文链接作者:菩提树下的杨过出处:http://yjmyzz.cnblogs.com Asp.Net中的Session要比Asp中的Session灵活和强大很多,同时也复杂很多:看到有一些Asp.Ne ...
- 【BZOJ1858】[SCOI2010] 序列操作(ODT裸题)
点此看题面 大致题意: 给你一个\(01\)序列,让你支持区间赋值.区间取反.区间求和以及求一段区间内最多有多少连续的\(1\)这些操作. \(ODT\) 这道题正解似乎是线段树,但码量较大,而且细节 ...
- DOM(四):h5扩展方法
getElementByClassName()方法getElementByClassName()方法接收一个参数,即一个包含一或多个类名的字符串,返回带有指定类的所有元素的NodeList //取得所 ...
- frcnn_train_data_param的distort_param实现
frcnn_train_data_param frcnn_train_data_param { source: "./data/train_list.txt" root_folde ...
- Mybatis之批量更新操作
更新单条记录 UPDATE course SET name = 'course1' WHERE id = 'id1'; 更新多条记录的同一个字段为同一个值 UPDATE course SET name ...
- 2.1-Java语言基础(keyword)
2.1 keyword watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvbXNpcmVuZQ==/font/5a6L5L2T/fontsize/400/fi ...
- ZIGBEE report机制分析
ZIGBEE提供了report机制(现在只学习了send, receive还没学习) 主要目的是实现attribute属性的report功能,即提供了一种服务端和客户端数据同步的机制 以EMBER的H ...
- Webpack4 学习笔记五 图片解析、输出的文件划分目录
前言 此内容是个人学习笔记,以便日后翻阅.非教程,如有错误还请指出 webpack打包图片和划分文件路径 使用图片的方式 通过 new Image() 在 css中设置 background-imag ...