第五章 标准I/O
5.1 引言
本章说明标准 I/O 库。因为不仅在 UNIX 上,而且在很多操作系统上都实现了此库,所以它由 ISO C 标准说明。
标准 I/O 库处理很多细节,例如缓冲区分配,以优化长度执行 I/O 等。这些处理使用户不必担心如何选择使用正确的块长度(如3.9节所述)。这使得它便于用户使用,但是如果不叫深入地了解 I/O 库函数的操作,也会带来一些问题。
标准 I/O 库是由 Dennis Ritchie 在1975年左右编写的。令人惊讶的是,经过30年后,对标准 I/O 库只做了极小的修改。
5.2 流和FILE对象
在第3章中,所有I/O函数都是针对文件描述符的。当打开一个文件时,即返回一个文件描述符,然后该文件描述符就用于后续的 I/O 操作。而对于标准 I/O 库,它们的操作则是围绕流(stream)进行的。当标准 I/O 库打开或创建一个文件时,我们已使一个流与一个文件相关联。
对于 ASCII 字符集,一个字符用一个字节表示。对于国际字符集,一个字符可用多个字节表示。标准 I/O 文件流可用于单字节或多字节的字符集。流的定向(stream's orientation)决定了所读、写的字符是单字节还是多字节的。当一个流最初被创建时,它并没有定向。如若在未定向的流上使用一个多字节 I/O 函数(减 <wchar.h>),则将该流的定向设置为宽定向。若在未定向的流上使用一个单字节 I/O 函数,则将该流的定向设置为字节定向的。只有两个函数可以改变流的定向。 freopen函数(参见5.5节)清除一个流的定向;fwide 函数设置流的定向。
int fwide(FILE *fp, int mode);
根据mode参数的不同值, fwide函数执行不同的工作:
(1)如若mode参数值为负,fwide将试图使指定的流是字节定向的。
(2)如果mode参数值为正,fwide将试图指定的流是宽定向的。
(3)如若mode参数值为0,fwide 将不试图设置流的定向,但返回标识该流定向的值。
注意,fwide并不改变已定向流的定向。还应注意的是,fwide无出错返回。试想如若流是无效的,那么将会发生什么呢?我们唯一可依靠的是,在调用 fwide 前先清除 errno,从fwide返回时检查 errno的值。在本书的其余部分,我们只涉及字节定向流。
当打开一个流时,标准 I/O 函数 fopen 返回一个指向 FILE 对象的指针。该对象通常是一个结构,它包含了标准 I/O 库为管理该流所需要的所有信息,包括:用于实际 I/O 的文件描述符、指向用于该流缓冲区的指针、缓冲区的长度、当前缓冲区中字节数以及出错标准等等。
应用程序没有必要检查 FILE 对象。为了引用一个流,需将 FILE 指针作为参数传递给每个标准 I/O 函数。在整本书中,我们称指向 FILE对象的指针(类型为 FILE *)为文件指针。
5.3 标准输入、标准输出、标准出错
对一个进程预定义了三个流,并且这三个流可以自动地被进程使用,它们是:标准输入、标准输出和标准出错。这些流引用地文件与3.2节中提到地文件描述符 STDIN_FILENO、STDOUT_FILENO和STDERR_FILENO所引用地文件相同。
这三个标准 I/O 流通过预定义文件指针 stdin、stdout和stderr加以引用。这三个文件指针同样定义在头文件 <stdio.h>中。
5.4 缓冲
标准 I/O 库提供缓冲地目的是尽可能减少使用 read 和write 调用次数。它也对每个 I/O 流自动地进行缓冲管理,从而避免了应用程序需要考虑这一点带来地麻烦。不幸的是,标准 I/O 库最令人迷惑地也是它地缓冲。
标准I/O 提供了三种类型地缓冲:
(1)全缓冲。这种情况下,在填满标准 I/O 缓冲区后才进行实际 I/O 操作。对于驻留在磁盘上的文件通常是由标准 I/O 库实施全缓冲的。 在一个流上执行第一次 I/O 操作时,相关标准 I/O 函数通常调用 malloc(见7.8节)获得需使用的缓冲区。
术语冲洗(flush)说明标准I/O 缓冲区的写操作。缓冲区可由标准 I/O 例程自动冲洗(例如当填满一个缓冲区时),或者可以调用函数 fflush 冲洗一个流。值得引起注意的是在 UNIX 环境中,flush有两种意思。在标准 I/O 库方面, flush 意味着将缓冲区中的内容写到磁盘上(该缓冲区可能只是局部填写的)。在终端驱动程序方面,flush表示丢弃已存储在缓冲区中的数据。
(2)行缓冲。在这种情况下,当输入和输出中遇到换行符时,标准 I/O 库执行 I/O 操作。这允许我们一次输出一个字符(用标准I/O fputc函数),但只有在写了一行之后才进行实际 I/O 操作。当流涉及一个终端时(例如标准输入和标准出错),通常使用行缓冲。
对于行缓冲有两个限制。第一,因为标准 I/O 库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行 I/O 操作。第二,任何时候只要通过标准 I/O 库要求从 (a) 一个不带缓冲的流,或者 (b)一个行缓冲的流(它要求从内核得到数据)得到输入数据,那么就会造成冲洗所有行缓冲输出流。在(b)中带了一个括号中的说明,其理由是,所需的数据可能已在该缓冲区中,它并不要求在需要数据时才从内核读数据。很明显,从不带缓冲的一个流中进行输入 要求当时从内核得到数据。
(3)不带缓冲。标准 I/O 库不对字符进行缓冲存储。例如,如果用标准 I/O 函数 fputs 写15个字符到不带缓冲的流中,则该函数很可能用 write 系统调用函数将这些字符立即写至相关联的打开文件上。
对于任何给定的流,可调用下列函数更改缓冲类型:
void setbuf(FILE *restrict fp, char *restrict buf);
int setvbuf(FILE *restrict fp, char *restrict buf, int mode,
size_t size);
任何时候,我们都可强制冲洗一个流。
int fflush(FILE *fp);
函数使该流所有未写的数据都被传送至内核。作为一个特例,如若 fp 使 NULL,则此函数将导致所有输出流被冲洗。
5.5 打开流
下列三个函数打开一个标准 I/O 流。
FILE *fopen(const char *restrict pathname, const char *restrict type);
FILE *freopen(const char *restrict pathname, const char *restrict type,
FILE *restrict fp);
FILE *fdopen(int filedes, const char *type);
三个函数的区别是:
(1)fopen打开一个指定的文件。
(2)freopen在一个指定的流上打开一个指定的文件,如若该流已经打开,则先关闭该流。若该流已经定向,则 freopen 清除该定向。此函数一般用于将一个指定的文件打开为一个预定义的流:标准输入、标准出错、标准出错。
(3)fdopen获取一个现有文件描述符,并使一个标准 I/O 流与该描述符相结合。此函数常用于由创建管道和网络通信函数返回的描述符。因为这些特殊类型的文件不能用标准 I/O fopen函数打开,所以我们必须先调用设备专门函数以获得一个文件描述符,然后用 fdopen 使一个标准 I/O 流与该描述符相关联。
type参数指定对该I/O流的读、写方式,ISO C规定type参数可以有15种不同的值,它们示于下表:

使用字符 b 作为 type 的一部分,这使得标准 I/O 可以区分文本文件和二进制文件。因为 UNIX内核并不对这两种文件进行区分,所以在 UNIX 系统环境下指定字符 b 作为 type 的一部分实际上并无作为。
对于 fdopen,type参数的意义稍有区别。因为描述符已经被打开,所以fdopen为写而打开并不截短该文件(例如,若该描述符原来是由 open 函数创建的,而且该文件那时已经存在,则其 O_TRUNC标志将决定是否截短该文件。fdopen函数不能截短它为写而打开的任一文件。)另外,标志 I/O 添写方式也不能用于创建该文件(因为如若一个描述符引用一个文件,则该文件一定已经存在)。
当用添写类型打开一文件后,则每次写都将数据写到文件的尾端处。如若有多个进程用标志 I/O 添写方式打开了同一文件,那么来自每个进程的数据都将正确地写到文件中。
注意,在指定 w 或 a 类型创建一个新文件时,我们无法说明该文件地访问权限位(open函数和creat函数则能做到)。
除非流引用终端设备,否则按系统默认情况,流被打开时是全缓冲的。若流引用终端设备,则该流是行缓冲的。一旦打开了流,那么在对流执行任何操作之前,如果希望,则可使用上一节所述的 setbuf和setvbuf改变缓冲类型。
调用 fclose关闭一个打开的流
int fclose(FILE *fp);
在该文件被关闭之前,冲洗缓冲区中的输出数据。丢弃缓冲区中的任何输入数据。如果标志 I/O库已经为流自动分配了一个缓冲区,则释放此缓冲区。
当一个进程正常终止时(直接调用 exit函数,或从 main 函数返回),则所有带未写缓冲数据的标志 I/O 流都会被冲洗,所有打开的标志 I/O 流都会被关闭。
5.6 读和写流
一旦打开了流,则可在三种不同类型的非格式化I/O中进行选择,对其进行读、写操作:
(1)每次一个字符的I/O。一次读或写一个字符,如果流是带缓冲的,则标准I/O函数会处理所有缓冲。
(2)每次一行的I/O。如果想要一次读或写一行,则使用fgets和fputs。每行都以一个换行符终止。当调用 fgets时,应说明能处理的最大行长。
(3)直接I/O。fread和fwrite函数支持这种类型的I/O。每次I/O操作读或写某种数量的对象,而每个对象具有指定的长度。这两个函数常用于从二进制文件中每次读或写一个结构。
1.输入函数
int getc(FILE *fp); int fgetc(FILE *fp); int getchar(void);
函数getchar等价于getc(stdin)。前面两个函数的区别是getc可被实现为宏,而fgetc则不能实现为宏。这意味着:
(1)getc的参数不应当是具有副作用的表达式
(2)因为fgetc一定是一个函数,所以可以得到其地址。这就允许将fgetc的地址作为一个参数传送给另一个函数。
(3)调用fgetc所需时间很可能长于调用getc,因为调用函数通常所需的时间长于调用宏。
这三个函数在返回下一个字符时,会将其 unsigned char 类型转换成 int 类型。说明为不带符合的理由是,如果最高位为1也不会使返回值为负。要求整形返回值的理由是,这样就可以返回所有可能的字符值再加上一个已出错或已达到文件尾端的指示值。在 <stdio.h> 中的常量 EOF被要求是一个负值,其值经常是-1.这就意味着不能将这三个函数的返回值存放在一个字符变量中,以后还要将这些函数的返回值与常量 EOF 相比较。
注意,不管是出错还是到达文件尾端,这三个函数都返回同样的值。为了区分这两种不同的情况,必须调用 ferror 或 feof
int ferror(FILE *fp); int feof(FILE *fp); void clearerr(FILE *fp);
在大多数实现中,为每个流在FILE对象中维持了两个标志:
(1)出错标志。
(2)文件结束标志。
调用 clearerr 则清除这两个标志。
从流中读取数据以后,可以调用 ungetc 将字符再压送回流中。
int ungetc(int c, FILE *fp);
压送回流中的字符以后又可从流中读出,但读出字符的顺序与压送回流的顺序相反。应当了解,虽然 ISO C允许实现支持任何次数的回送,但是它要求实现提供一次只送回一个字符。我们不能期望一次能送回多个字符。
回送的字符不必一定是上一次读到的字符。不能回送EOF。但是当已经到达文件尾端时,仍可以回送一字符。下次读将返回该字符,再次读则返回EOF。之所以能这样做的原因是一次成功的ungetc调用会清除流的文件结束标志。
当正在读一个输入流,并进行某种形式的分字或分记号操作时,会经常用到回送字符操作。有时需要先看一看下一个字符,以决定如何处理当前字符。然后就需要方便地将刚查看地字符送回,以便下一次调用getc时返回该字符。如果标志I/O库不提供回送能力,就需将该字符存放到一个我们自己的变量中,并设置一个标志以便判别在下一次需要一个字符时是调用getc还是从我们自己的变量中取用。
用ungetc压送回字符时,并没有将它们写到文件中或设备上,只是将它们写回标志I/O库的流缓冲区中。
2. 输出函数
int putc(int c, FILE *fp); int fputc(int c, FILE *fp); int putchar(int c);
与输入函数一样,putchar(c)等效于putc(c, stdout),putc可实现为宏,而fputc则不能实现为宏。
5.7 每次一行I/O
下面两个函数提供每次输入一行的功能
char *fgets(char *restrict buf, int n, FILE *restrict fp); char *gets(char *buf);
这两个函数都指定了缓冲区的地址,读入的行将送入其中。gets从标准输入读,而fgets则从指定的流读。
对于fgets,必须指定缓冲区的长度n,此函数一直读到下一个换行符为止,但是不超过n-1个字符,读入的字符被送入缓冲区。该缓冲区以null字符结尾。如若改行(包括最后一个换行符)的字符数超过n-1,则fgets只返回一个不完整的行,但是缓冲区总时以null字符结尾。对fgets的下一次调用会继续读该行。
gets是一个不推荐使用的函数。其问题是调用者在使用gets时不能指定缓冲区的长度。这样就可能造成缓冲区溢出(如若该行长于缓冲区长度),写到缓冲区之后的存储空间中,从而产生不可预料的后果。这种缺陷曾被利用,造成1988年的因特网蠕虫事件。gets和fgets的另一个区别是,gets并不将换行符存入缓冲区中。
即使ISO C要求实现提供gets,但请使用fgets,而不要使用gets。
fputs和puts提供每次输出一行的功能。
int fputs(const char *restrict str, FILE *restrict fp); int puts(const char *str);
函数fputs将一个以null符终止的字符串写到指定的流,尾端的终止符null不写出。注意,这并不一定是每次输出一行,因为它并不要求在null符之前一定是换行符。通常,在null符之前是一个换行符,但并不要求总是如此。
puts将一个以null符终止的字符串写到标准输出,终止符不写出。但是,puts然后又将一个换行符写到标准输出。
puts并不像它所对应的gets那样不安全。但是我们还是应避免使用它,以免需要记住它在最后是否添加一个换行符。如果总是使用 fgets 和 fputs,那么就会熟知在每行终止处我们必须自己处理换行符。
5.8 标准I/O的效率
使用上一节所述的函数,我们能对标准I/O系统的效率有所了解。
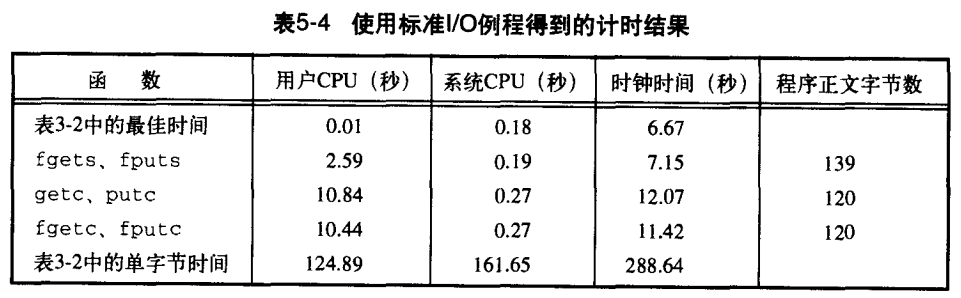
不在本文章中解释原因和探究细节。
5.9 二进制 I/O
5.6节和5.7节中的函数以一次一个字符或一次一行的方式进行操作。如果进行二进制 I/O 操作,那么我们更愿意一次读或写整个结构。如果使用getc或putc读、写一个结构,那么必须循环通过整个结构,每次循环处理一个字节,一次读或写一个字节,这会非常麻烦且费时。如果使用fputs和fgets,那么因为fputs在遇到null字节时就停止,而在结构中可能含有null字节,所以不能使用它实现读结构的要求。类似地,如果输入数据中包含null字节或换行符,则fgets也不能正确工作。因此,提供了下列两个函数以执行二进制I/O操作。
size_t fread(void *restrict ptr, size_t size, size_t nobj,
FILE *restrict fp);
size_t fwrite(const void *restrict ptr, size_t size, size_t nobj,
FILE *restrict fp);
这些函数有两种常见地用法:
(1)读或写一个二进制数组。例如,为了将一个浮点数组的第2~5个元素写至一个文件上,可以编写如下程序:
];
], , fp) != )
err_sys("fwrite error");
其中,指定size为数组元素的长度,nobj为欲写的元素数。
(2)读或写一个结构,例如,可以编写如下程序:
struct {
short count;
long total;
char name[NAMESIZE];
} item;
, fp) != )
err_sys("fwrite error");
将这两个例子结合起来就可读或写一个结构数组。为了做到这一点,size应当是该结构的sizeof,nobj应是该数组中元素个数。
fread和fwrite返回读或写的对象数。对于读,如果出错或到达文件尾端,则此数字可以少于nobj。在这种情况下,应调用ferror或feof以判断究竟属于哪一种情况。对于写,如果返回值少于所要求的nobj,则出错。
使用二进制I/O的基本问题是,他只能用于读在同一个系统已写的数据。所以在异构系统(多台主机通过网络互相连接起来,构成一个系统)中,在一个系统上写的数据,要在另一个系统上进行处理,则可能出错,原因是:
(1)在一个结构中,同一成员的偏移量可能因编译器或系统而异(由于不同的对准要求)。
(2)用来存储多个字节整数和浮点值得二进制格式在不同机器体系结构间也可能不同。
5.10 定位流
有三种方法定位标准I/O流。
(1)ftell和fseek函数。它们都假定文件的位置可以存放在一个长整型中。
(2)ftello和fseeko函数。可以使文件偏移量不必一定使用长整型。它们使用off_t数据类型代替长整型。
(3)fgetpos和fsetpos函数。它们使用一个抽象数据类型fpos_t记录文件位置。这种数据类型可以定义为记录一个文件位置所需的长度。
long ftell(FILE *fp); int seek(FILE *fp, long offset, int whence); void rewind(FILE *fp);
对于一个二进制文件,其文件位置指示器是从文件起始位置开始度量,并以字节为计量单位。ftell用于二进制文件时,其返回值就是这种字节位置。为了用fseek定位一个二进制文件,必须指定一个字节offset,以及解释这种偏移量的方式。whence的值与3.6节中lseek函数的相同:SEEK_SET表示从文件的起始位置开始,SEEK_CUR表示从当前文件位置开始,SEEK_END表示从文件尾端开始。
使用rewind函数也可将一个流设置到文件的起始位置。
除了offset的类型是off_t而非long以外,ftello函数与ftell相同,fseeko函数与fseek相同。
off_t ftello(FILE *fp); int fseeko(FILE *fp, off_t offset, int whence);
fgetpos和fsetpos这两个函数是C标准引进的。
int fgetpos(FILE *restrict fp, fpos_t *restrict pos); int fsetpos(FILE *fp, const fpos_t *pos);
fgetpos将文件的位置指示器的当前值存入由pos指向的对象中。在以后调用fsetpos时,可以使用此值将流重定位至该位置。
5.11 格式化I/O
1.格式化输出
执行格式化处理的是4个printf函数
int printf(const char *restrict format, ...);
int fprintf(FILE *restrict fp, const char *restrict format, ...);
int sprintf(char *restrict buf, const char *restrict format, ...);
int sprintf(char *restrict buf, size_t n,
const char *restrict format, ...);
printf将格式化数据写到标准输出,fprintf写至指定的流,sprintf将格式化的字符送入数组buf中。sprintf在该数组的尾端自动加一个null字节,但该字节不包括在返回值中。
sprintf函数可能会造成缓冲区溢出,snprintf函数解决了该问题,缓冲区的长度是一个显示参数,超过缓冲区的字符数会被丢弃。snprintf函数会返回写入缓冲区的字符数,与sprintf相同,该返回值不包括结尾的null字节。若snprintf函数返回小于缓冲区长度n的正值,那么没有截短输出。若发生了一个编码错误,snprintf则返回负值。
2.格式化输入
执行格式化输入处理的是三个scanf函数
int scanf(const char *restrict format, ...);
int fscanf(FILE *restrict fp, const char *restrict format, ...);
int sscanf(const char *restrict buf, const char *restrict format,
...);
5.12 实现细节
正如前述,在UNIX系统中,标准I/O库最终都要调用第3章中说明的I/O例程。每个标准I/O流都有一个与其相关联的文件描述符,可以对一个流调用fileno函数以获得其描述符。
int fileno(FILE *fp);
如果要调用dup或fcntl等函数,则需要此函数。
5.13 临时文件
ISO C标准I/O库提供了两个函数以帮助创建临时文件。
char *tmpnam(char *ptr); FILE *tmpfile(void);
第五章 标准I/O的更多相关文章
- 《APUE》-第五章标准IO库
大多数UNIX应用程序都使用I/O库,本章说明了该库所包含的所有函数,以及某些实现细节和效率方面的考虑.同时需要重点关注标准I/O使用了缓冲的技术,但同时也是因为它的出现,产生了很多细节上的问题. 流 ...
- apue学习笔记(第五章 标准I/O)
本章讲述标准I/O库 流和FILE对象 对于标准I/O库,它们的操作是围绕流进行的.流的定向决定了所读.写的字符是单字节还是多字节的. #include <stdio.h> #includ ...
- 《UNIX环境高级编程》(APUE) 笔记第五章 - 标准I/O库
5 - 标准I/O库 Github 地址 1. 标准 I/O 库作用 缓冲区分配 以优化的块长度执行 I/O 等 使用户不必担心如何选择使用正确的块长度 标准 I/O 最终都要调用第三章中的 I/O ...
- UNIX系统高级编程——第五章-标准I/O库-总结
基础: 标准I/O库在ANSI C中定义,可移植在不同的系统 文件指针(FILE):标准I/O库操作的不是文件描述符,而是流.FILE文件指针包含的是维护流所需的信息 通过函数fileno获取流的文件 ...
- Python 3标准库 第五章 数学运算
第五章数学运算-----------------------上下文解释:编程时,我们一般也是先给程序定义一些前提(环境变量.描述环境变化的全局变量等),这些“前提”就是上文,然后再编写各功能模块的代码 ...
- 精通Web Analytics 2.0 (7) 第五章:荣耀之钥:度量成功
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第五章:荣耀之钥:度量成功 我们的分析师常常得不到我们应得的喜欢,尊重和资金,因为我们没有充分地衡量一个黄金概念:成果.因为我们 ...
- 读《编写可维护的JavaScript》第五章总结
第五章 UI层的松耦合 5.1 什么是松耦合 在Web开发中,用户界面是由三个彼此隔离又相互作用的层定义的: HTML是用来定义页面的数据和语义 CSS用来给页面添加样式 JavaScript用来给页 ...
- 《Linux内核设计与实现》课本第五章学习笔记——20135203齐岳
<Linux内核设计与实现>课本第五章学习笔记 By20135203齐岳 与内核通信 用户空间进程和硬件设备之间通过系统调用来交互,其主要作用有三个. 为用户空间提供了硬件的抽象接口. 保 ...
- 《APUE》第五章笔记
第五章具体介绍了标准I/O库的各种细节,要是一一列出来,有费精力且可能列不全,故只讲平常多用到的.标准输入输出是由一大批函数组成的. 要记住,标准输入输出是有缓冲的,就是当缓冲区的数据满了的时候,才会 ...
随机推荐
- 从零开始的全栈工程师——js篇2.21(事件对象 arguments 阻止事件默认行为兼容 事件委托 事件源对象)
一.事件对象 1.常用的事件2.每个元素身上的事件都是天生存在的 不需要我们去定义 只需要我们给这个事件绑定一个方法 当事件触发的时候就会执行这个方法 3.事件绑定的写法 ①div.onclick=f ...
- svg保存为图片下载到本地
今天给大家说一个将svg下载到本地图片的方法,这里我不得不吐槽一下,为啥博客园不可以直接上传本地文件给大家用来直接下载分享呢,好,吐槽到此为止! 这里需要用到一个js文件,名字自己起,内容如下: (f ...
- node-sass 安装报错解决办法
npm install安装node-sass时出现以下问题: Cannot download https://github.com/sass/node-sass/releases/download/v ...
- (四)JavaScript之[break和continue]与[typeof、null、undefined]
7].break和continue /** * JavaScript 的break和continue语句 * break 跳出switch()语句 * break 用于跳出循环 * continue ...
- 必须夸夸Sublime,大文件打开
今天有个问题的事情日志文件67.8M大文件打开问题开始: 1.vscode必须挨批:直接就给个错误the file cannt be displayed in the editor because i ...
- linux下搭建svn并同步更新至web目录
安装svn 使用yum安装 yum install subversion -y 安装成功后查看版本库 svnserve --version 生成目录 cd /var mkdir svn cd svn ...
- 前端必须要掌握的几个CSS3的属性
随着Css3和html5的风靡,越来越多的前端人员开始学习Css3,今天的文章就是来说说前端应该掌握10个Css3属性. 1. Border-radius Border-radius是一大堆CSS3属 ...
- javascript中的循环引用对象处理
先说明一下什么是循环引用对象: var a={"name":"zzz"}; var b={"name":"vvv"}; ...
- .net 开源的网站
https://www.zhihu.com/question/24408855 https://www.zhihu.com/question/19840134 这两个知乎的答案 介绍部分经典的.net ...
- js实现弹窗一个ip在24小时只弹出一次的代码
function cookieGO(name) { var today = new Date(); var expires = new Date(); expires.setTime(today.ge ...