MATLAB实例:PCA(主成成分分析)详解
MATLAB实例:PCA(主成成分分析)详解
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
1. 主成成分分析


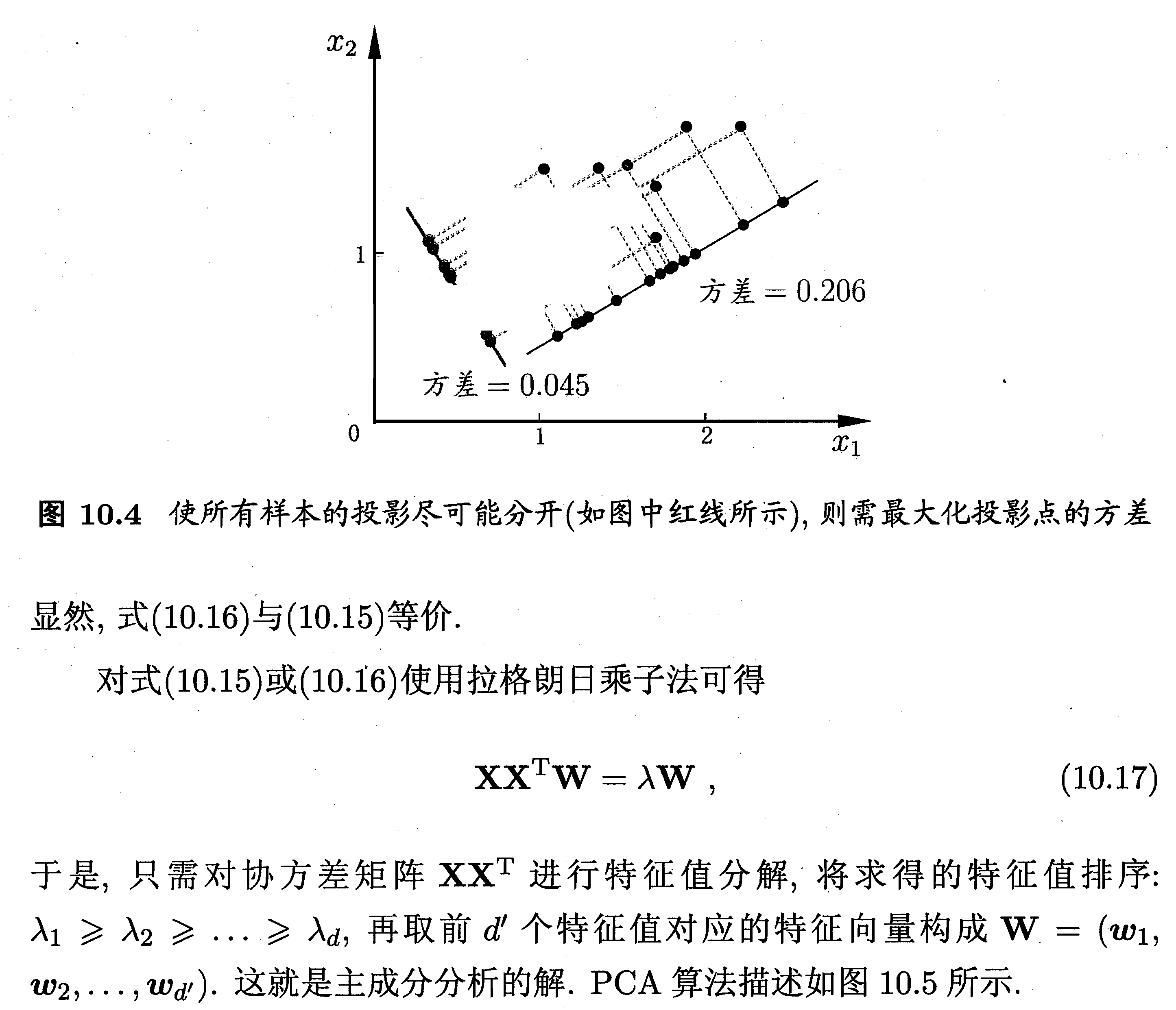


2. MATLAB解释
详细信息请看:Principal component analysis of raw data - mathworks
[coeff,score,latent,tsquared,explained,mu] = pca(X)
coeff = pca(X) returns the principal component coefficients, also known as loadings, for the n-by-p data matrix X. Rows of X correspond to observations and columns correspond to variables.
The coefficient matrix is p-by-p.
Each column of coeff contains coefficients for one principal component, and the columns are in descending order of component variance.
By default, pca centers the data and uses the singular value decomposition (SVD) algorithm.
coeff = pca(X,Name,Value) returns any of the output arguments in the previous syntaxes using additional options for computation and handling of special data types, specified by one or more Name,Value pair arguments.
For example, you can specify the number of principal components pca returns or an algorithm other than SVD to use.
[coeff,score,latent] = pca(___) also returns the principal component scores in score and the principal component variances in latent.
You can use any of the input arguments in the previous syntaxes.
Principal component scores are the representations of X in the principal component space. Rows of score correspond to observations, and columns correspond to components.
The principal component variances are the eigenvalues of the covariance matrix of X.
[coeff,score,latent,tsquared] = pca(___) also returns the Hotelling's T-squared statistic for each observation in X.
[coeff,score,latent,tsquared,explained,mu] = pca(___) also returns explained, the percentage of the total variance explained by each principal component and mu, the estimated mean of each variable in X.
coeff: X矩阵所对应的协方差矩阵的所有特征向量组成的矩阵,即变换矩阵或投影矩阵,coeff每列代表一个特征值所对应的特征向量,列的排列方式对应着特征值从大到小排序。
source: 表示原数据在各主成分向量上的投影。但注意:是原数据经过中心化后在主成分向量上的投影。
latent: 是一个列向量,主成分方差,也就是各特征向量对应的特征值,按照从大到小进行排列。
tsquared: X中每个观察值的Hotelling的T平方统计量。Hotelling的T平方统计量(T-Squared Statistic)是每个观察值的标准化分数的平方和,以列向量的形式返回。
explained: 由每个主成分解释的总方差的百分比,每一个主成分所贡献的比例。explained = 100*latent/sum(latent)。
mu: 每个变量X的估计平均值。
3. MATLAB程序
3.1 方法一:指定降维后低维空间的维度k
function [data_PCA, COEFF, sum_explained]=pca_demo_1(data,k)
% k:前k个主成分
data=zscore(data); %归一化数据
[COEFF,SCORE,latent,tsquared,explained,mu]=pca(data);
latent1=100*latent/sum(latent);%将latent特征值总和统一为100,便于观察贡献率
data= bsxfun(@minus,data,mean(data,1));
data_PCA=data*COEFF(:,1:k);
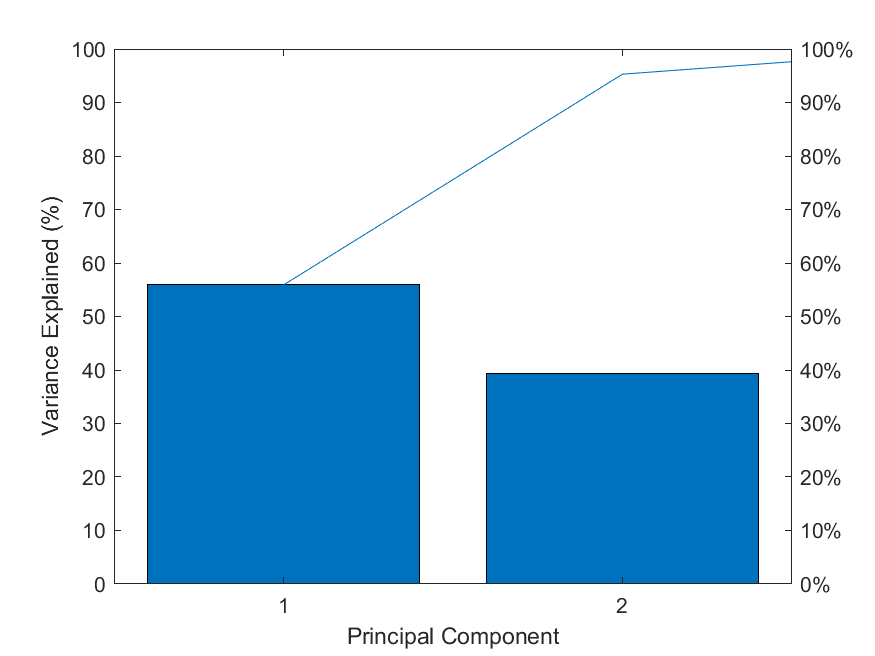
pareto(latent1);%调用matla画图 pareto仅绘制累积分布的前95%,因此y中的部分元素并未显示
xlabel('Principal Component');
ylabel('Variance Explained (%)');
% 图中的线表示的累积变量解释程度
print(gcf,'-dpng','PCA.png');
sum_explained=sum(explained(1:k));
3.2 方法二:指定贡献率percent_threshold
function [data_PCA, COEFF, sum_explained, n]=pca_demo_2(data)
%用percent_threshold决定保留xx%的贡献率
percent_threshold=95; %百分比阈值,用于决定保留的主成分个数;
data=zscore(data); %归一化数据
[COEFF,SCORE,latent,tsquared,explained,mu]=pca(data);
latent1=100*latent/sum(latent);%将latent特征值总和统一为100,便于观察贡献率
A=length(latent1);
percents=0; %累积百分比
for n=1:A
percents=percents+latent1(n);
if percents>percent_threshold
break;
end
end
data= bsxfun(@minus,data,mean(data,1));
data_PCA=data*COEFF(:,1:n);
pareto(latent1);%调用matla画图 pareto仅绘制累积分布的前95%,因此y中的部分元素并未显示
xlabel('Principal Component');
ylabel('Variance Explained (%)');
% 图中的线表示的累积变量解释程度
print(gcf,'-dpng','PCA.png');
sum_explained=sum(explained(1:n));
4. 结果
数据来源于MATLAB自带的数据集hald
>> load hald
>> [data_PCA, COEFF, sum_explained]=pca_demo_1(ingredients,2) data_PCA = -1.467237802258083 -1.903035708425560
-2.135828746398875 -0.238353702721984
1.129870473833422 -0.183877154192583
-0.659895489750766 -1.576774209965747
0.358764556470351 -0.483537878558994
0.966639639692207 -0.169944028103651
0.930705117077330 2.134816511997477
-2.232137996884836 0.691670682875924
-0.351515595975561 1.432245069443404
1.662543014130206 -1.828096643220118
-1.640179952926685 1.295112751426928
1.692594091826333 0.392248821530480
1.745678691164958 0.437525487914425 COEFF = 0.475955172748970 -0.508979384806410 0.675500187964285 0.241052184051094
0.563870242191994 0.413931487136985 -0.314420442819292 0.641756074427213
-0.394066533909303 0.604969078471439 0.637691091806566 0.268466110294533
-0.547931191260863 -0.451235109330016 -0.195420962611708 0.676734019481284 sum_explained = 95.294252628439153 >> [data_PCA, COEFF, sum_explained, n]=pca_demo_2(ingredients) data_PCA = -1.467237802258083 -1.903035708425560
-2.135828746398875 -0.238353702721984
1.129870473833422 -0.183877154192583
-0.659895489750766 -1.576774209965747
0.358764556470351 -0.483537878558994
0.966639639692207 -0.169944028103651
0.930705117077330 2.134816511997477
-2.232137996884836 0.691670682875924
-0.351515595975561 1.432245069443404
1.662543014130206 -1.828096643220118
-1.640179952926685 1.295112751426928
1.692594091826333 0.392248821530480
1.745678691164958 0.437525487914425 COEFF = 0.475955172748970 -0.508979384806410 0.675500187964285 0.241052184051094
0.563870242191994 0.413931487136985 -0.314420442819292 0.641756074427213
-0.394066533909303 0.604969078471439 0.637691091806566 0.268466110294533
-0.547931191260863 -0.451235109330016 -0.195420962611708 0.676734019481284 sum_explained = 95.294252628439153 n = 2
5. 参考
[1] 周志华,《机器学习》.
[2] MATLAB实例:PCA降维
MATLAB实例:PCA(主成成分分析)详解的更多相关文章
- 数字图像处理-----主成成分分析PCA
主成分分析PCA 降维的必要性 1.多重共线性--预测变量之间相互关联.多重共线性会导致解空间的不稳定,从而可能导致结果的不连贯. 2.高维空间本身具有稀疏性.一维正态分布有68%的值落于正负标准差之 ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- wav文件格式分析详解
wav文件格式分析详解 文章转载自:http://blog.csdn.net/BlueSoal/article/details/932395 一.综述 WAVE文件作为多媒体中使用的声波文件格式 ...
- HanLP中人名识别分析详解
HanLP中人名识别分析详解 在看源码之前,先看几遍论文<基于角色标注的中国人名自动识别研究> 关于命名识别的一些问题,可参考下列一些issue: l ·名字识别的问题 #387 l ·机 ...
- Vue实例初始化的选项配置对象详解
Vue实例初始化的选项配置对象详解 1. Vue实例的的data对象 介绍 Vue的实例的数据对象data 我们已经用了很多了,数据绑定离不开data里面的数据.也是Vue的核心属性. 它是Vue绑定 ...
- Memcache的使用和协议分析详解
Memcache的使用和协议分析详解 作者:heiyeluren博客:http://blog.csdn.NET/heiyeshuwu时间:2006-11-12关键字:PHP Memcache Linu ...
- 线程组ThreadGroup分析详解 多线程中篇(三)
线程组,顾名思义,就是线程的组,逻辑类似项目组,用于管理项目成员,线程组就是用来管理线程. 每个线程都会有一个线程组,如果没有设置将会有些默认的初始化设置 而在java中线程组则是使用类ThreadG ...
- DOS文件转换成UNIX文件格式详解
转:DOS文件转换成UNIX文件格式详解 由windows平台迁移到unix系统下容易引发的问题:Linux执行脚本却提示No such file or directory dos格式文件传输到uni ...
- GC日志分析详解
点击返回上层目录 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 GC日志分析详解 以ParallelGC为例,YoungGC日志解释如下 ...
随机推荐
- Bert系列(二)——源码解读之模型主体
本篇文章主要是解读模型主体代码modeling.py.在阅读这篇文章之前希望读者们对bert的相关理论有一定的了解,尤其是transformer的结构原理,网上的资料很多,本文内容对原理部分就不做过多 ...
- JAVA之NIO按行读写大文件,完美解决中文乱码问题
;//一次读取的字节长度 File fin = new File("D:\\test\\20160622_627975.txt");//读取的文件 File fout = new ...
- windows/Linux/Mac下安装maven,maven作用
Linux下安装maven 1.首先到Maven官网下载安装文件,目前最新版本为3.0.3,下载文件为apache-maven-3.3.9-bin.tar.gz,下载可以使用wget命令: 2.进入下 ...
- canvas实现碰壁反弹(单个小方块)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Python--day20--序列化模块
序列化:转向一个字符串数据类型 序列 ———— 字符串 序列化和反序列化的概念: 序列化三种方法:json pickle shelve json模块:json模块提供了四个方法dumps和load ...
- 2002年NOIP普及组复赛题解
题目涉及算法: 级数求和:入门题: 选数:搜索: 产生数:搜索.高精度: 过河卒:动态规划. 级数求和 题目链接:https://www.luogu.org/problemnew/show/P1035 ...
- git clone出现Permission denied (publickey)解决办法
一.错误 git clone git@gitee.com:wangzaiplus/xxx.git, 出现Permission denied (publickey) 二.原因 无权限, 未将公钥添加至G ...
- Roslyn 如何使用 MSBuild Copy 复制文件
本文告诉大家如何在 MSBuild 里使用 Copy 复制文件 需要知道 Rosyln 是 MSBuild 的 dotnet core 版本. 在 MSBuild 里可以使用很多命令,本文告诉大家如何 ...
- 【9101】求n!的值
Time Limit: 10 second Memory Limit: 2 MB 问题描述 用高精度的方法,求n!的精确值(n的值以一般整数输入). Input 文件输入仅一行,输入n. Output ...
- 打地鼠游戏(2)之定义地鼠函数及函数原型 prototype
在JavaScript中,prototype对象是实现面向对象的一个重要机制. 每个函数就是一个对象(Function),函数对象都有一个子对象 prototype对象,类是以函数的形式来定义的.pr ...