Spark-day01
- Spark初始
- 什么是Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark是Scala编写,方便快速编程。
- 总体技术栈讲解
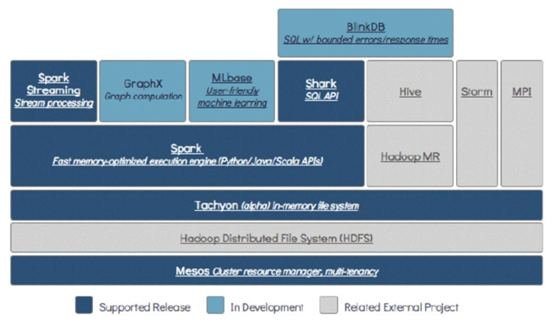
- Spark演变历史
- Spark与MapReduce的区别
- 都是分布式计算框架,Spark基于内存,MR基于HDFS。Spark处理数据的能力一般是MR的十倍以上,Spark中除了基于内存计算外,还有DAG有向无环图来切分任务的执行先后顺序。
- Spark运行模式
- Local
多用于本地测试,如在eclipse,idea中写程序测试等。
- Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。
- Yarn
Hadoop生态圈里面的一个资源调度框架,Spark也是可以基于Yarn来计算的。
- Mesos
资源调度框架。
- 要基于Yarn来进行资源调度,必须实现AppalicationMaster接口,Spark实现了这个接口,所以可以基于Yarn。
- SparkCore
- RDD
- 概念
RDD(Resilient Distributed Dateset),弹性分布式数据集。
- RDD的五大特性:
- RDD是由一系列的partition组成的。
- 函数是作用在每一个partition(split)上的。
- RDD之间有一系列的依赖关系。
- 分区器是作用在K,V格式的RDD上。
- RDD提供一系列最佳的计算位置。
- RDD理解图:

- 注意:
- textFile方法底层封装的是读取MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。
- RDD实际上不存储数据,这里方便理解,暂时理解为存储数据。
- 什么是K,V格式的RDD?
- 如果RDD里面存储的数据都是二元组对象,那么这个RDD我们就叫做K,V格式的RDD。
- 哪里体现RDD的弹性(容错)?
- partition数量,大小没有限制,体现了RDD的弹性。
- RDD之间依赖关系,可以基于上一个RDD重新计算出RDD。
- 哪里体现RDD的分布式?
- RDD是由Partition组成,partition是分布在不同节点上的。
- RDD提供计算最佳位置,体现了数据本地化。体现了大数据中"计算移动数据不移动"的理念。
- Spark任务执行原理
|
|
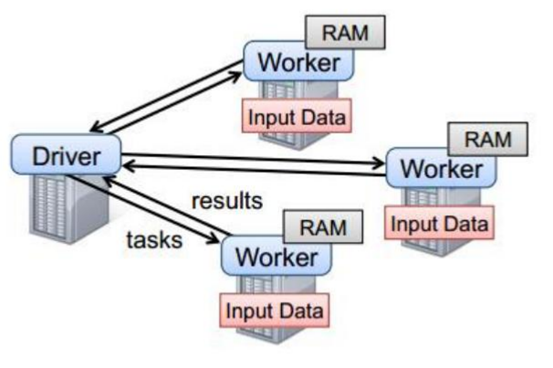
以上图中有四个机器节点,Driver和Worker是启动在节点上的进程,运行在JVM中的进程。
- Driver与集群节点之间有频繁的通信。
- Driver负责任务(tasks)的分发和结果的回收。任务的调度。如果task的计算结果非常大就不要回收了。会造成oom。
- Worker是Standalone资源调度框架里面资源管理的从节点。也是JVM进程。
- Master是Standalone资源调度框架里面资源管理的主节点。也是JVM进程。
- Spark代码流程
- 创建SparkConf对象
- 可以设置Application name。
- 可以设置运行模式及资源需求。
- 创建SparkContext对象
- 基于Spark的上下文创建一个RDD,对RDD进行处理。
- 应用程序中要有Action类算子来触发Transformation类算子执行。
- 关闭Spark上下文对象SparkContext。
- Transformations转换算子
- 概念:
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。
- Transformation类算子:
|
- Action行动算子
- 概念:
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
- Action类算子
将计算结果回收到Driver端。 |
- 思考:一千万条数据量的文件,过滤掉出现次数多的记录,并且其余记录按照出现次数降序排序。
文件:
|
|
代码:
|
|

- 控制算子
- 概念:
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
- cache
默认将RDD的数据持久化到内存中。cache是懒执行。
- 注意:chche () = persist()=persist(StorageLevel.Memory_Only)
- 测试cache文件:
文件:见"NASA_access_log_Aug95"文件。
测试代码:
|
SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("CacheTest"); JavaSparkContext jsc = new JavaSparkContext(conf); JavaRDD<String> lines = jsc.textFile("./NASA_access_log_Aug95");
lines = lines.cache(); long long long System.out.println("共"+count+ "条数据,"+"初始化时间+cache时间+计算时间="+ (endTime-startTime));
long long long System.out.println("共"+countrResult+ "条数据,"+"计算时间="+ (countEndTime- countStartTime));
jsc.stop(); |
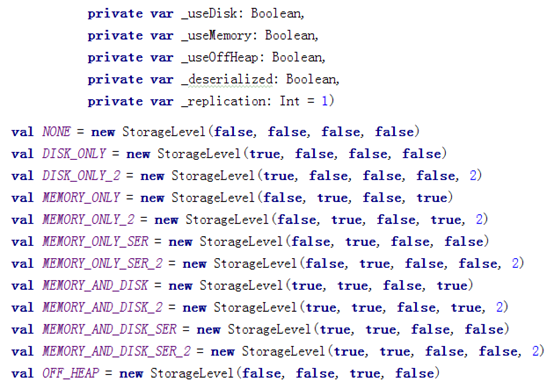
- persist:
可以指定持久化的级别。最常用的是MEMORY_ONLY和MEMORY_AND_DISK。"_2"表示有副本数。
持久化级别如下:
- cache和persist的注意事项:
- cache和persist都是懒执行,必须有一个action类算子触发执行。
- cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
- cache和persist算子后不能立即紧跟action算子。
错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
- checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。
- checkpoint 的执行原理:
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
- 优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
- 使用:
|
SparkConf conf = new SparkConf(); conf.setMaster("local").setAppName("checkpoint"); JavaSparkContext sc = new JavaSparkContext(conf); sc.setCheckpointDir("./checkpoint"); JavaRDD<Integer> parallelize = sc.parallelize(Arrays.asList(1,2,3)); parallelize.checkpoint(); parallelize.count(); sc.stop(); |
- 集群搭建以及测试
- 搭建
- Standalone
1).下载安装包,解压
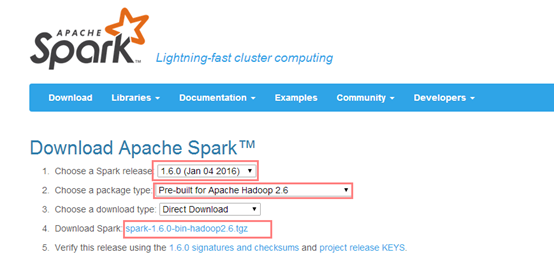
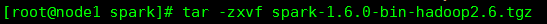
2).改名
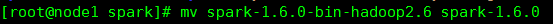
3).进入安装包的conf目录下,修改slaves.template文件,添加从节点。保存。


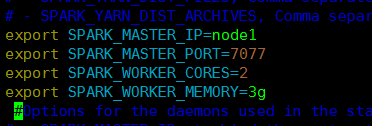
4).修改spark-env.sh
SPARK_MASTER_IP:master的ip
SPARK_MASTER_PORT:提交任务的端口,默认是7077
SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数
SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存数
5).同步到其他节点上


6).启动集群
进入sbin目录下,执行当前目录下的./start-all.sh
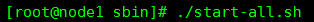
7).搭建客户端
将spark安装包原封不动的拷贝到一个新的节点上,然后,在新的节点上提交任务即可。
注意:
- 8080是Spark WEBUI界面的端口,7077是Spark任务提交的端口。
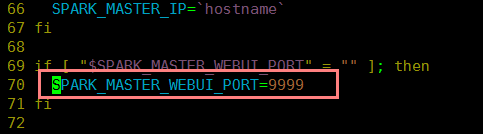
- 修改master的WEBUI端口:
- 修改start-master.sh即可。
- 也可以在Master节点上导入临时环境变量,只是作用于之后的程序,重启就无效了。

删除临时环境变量:
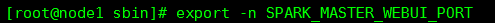
- yarn
1). 1,2,3,4,5,7步同standalone。
2).在客户端中配置:
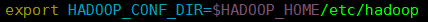
- 测试
PI案例:
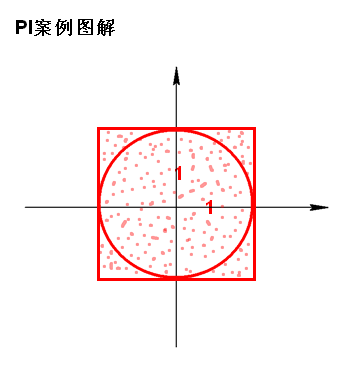
Standalone提交命令:
|
./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000 |
YARN提交命令:
|
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000 |
Spark-day01的更多相关文章
- Spark(一)【spark-3.0安装和入门】
目录 一.Windows安装 1.安装 2.使用 二.Linux安装 Local模式 1.安装 2.使用 yarn模式 1.安装 2.使用 3.spark的历史服务器集成yarn 一.Windows安 ...
- 大数据学习——spark笔记
变量的定义 val a: Int = 1 var b = 2 方法和函数 区别:函数可以作为参数传递给方法 方法: def test(arg: Int): Int=>Int ={ 方法体 } v ...
- Spark Core知识点复习-1
Day1111 Spark任务调度 Spark几个重要组件 Spark Core RDD的概念和特性 生成RDD的两种类型 RDD算子的两种类型 算子练习 分区 RDD的依赖关系 DAG:有向无环图 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
随机推荐
- iframe加载完成事件
var iframe = document.createElement("iframe"); iframe.src = "http://www.jb51.net" ...
- R语言之数据处理
R语言之数据处理 一.向量处理 1.选择和显示向量 data[1] data[3] data[1:3] data[-1]:除第一项以外的所有项 data[c(1,3,4,6)] data[data&g ...
- Maven实战05_背景案例学Maven模块化
1:简单的账户注册服务 注册互联网账户是日常生活中再熟悉不过的一件事,作为一个用户,注册账户的时候需要进行以下操作,提供以下信息. 提供一个未被使用的帐号ID 提供一个未被使用的email地址. 提供 ...
- Java常用的数据结构
collection : List:arrayList,linkedList,vector set:treeSet ,hashSet; map: hashMap treeMap linkedHashM ...
- IO流14 --- 打印流的使用 --- 技术搬运工(尚硅谷)
PrintStream 字节打印流PrintWriter 字符打印流 @Test public void test9() throws Exception { FileOutputStream fos ...
- centos安装消息队列beanstalkd
起因:开始想在windows安装beanstalkd,可以找了很多资料都没有成功.最终还是妥协.在虚拟机上装一个centos系统,然后在centos上安装beanstalkd供windows使用 yu ...
- 一探前端开发中的JS调试技巧(转)
有请提示:文中涉及较多Gif演示动画,移动端请尽量在Wifi环境中阅读 前言:调试技巧,在任何一项技术研发中都可谓是必不可少的技能.掌握各种调试技巧,必定能在工作中起到事半功倍的效果.譬如,快速定位问 ...
- PHP实现微信申请退款流程实例源码
https://www.jb51.net/article/136476.htm 目录 前期准备: 前面讲了怎么实现微信支付,详见博文:PHP实现微信支付(jsapi支付)流程 和ThinkPHP中实 ...
- 通过http路径获取文本内容(Java)
public static String readFileByUrl(String urlStr) { String res = null; try { URL url = new URL(urlSt ...
- Oracle ORA-01861
Oracle 插入时间时 报错:ORA-01861: 文字与格式字符串不匹配 的解决办法 解决方法: 这个错误一般出现在时间字段上,即你插入的时间格式和数据库现有的时间格式不一致,解决的方法是格式 ...