【Python3爬虫】一次应对JS反调试的记录
一、前言简介
在前面已经写过关于 JS 反调试的博客了,地址为:https://www.cnblogs.com/TM0831/p/12154815.html。但这次碰到的网站就不一样了,这个网站并不是通过不断调试消耗内存以反调试的,而是直接将页面替换修改掉,让人无法调试页面。

二、网页分析
本次爬取的网址为:https://www.aqistudy.cn/,但打开开发者工具后,页面变成了下面这样:

很明显这是触发了反爬,页面直接被替换掉了。当我们打开开发者工具时,程序检测到了开发者工具被打开了,所以触发反爬,将页面修改成了上面的样子。
页面被修改了,我们就没办法了吗?自然是有对策的,我们可以查看一下网页源码,在开发者工具中切换到 Source 选项,找到首页 index 的源码,如下图:
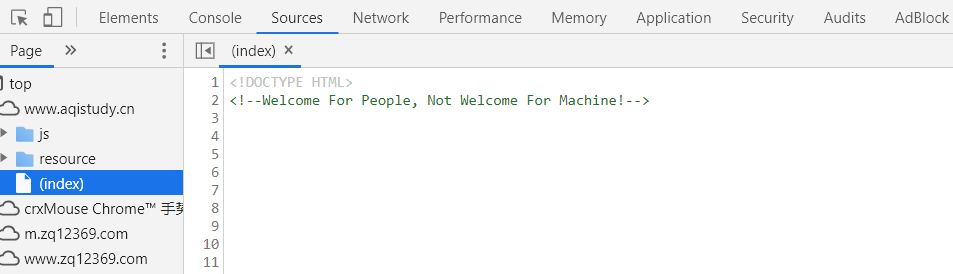
往下翻找,可以找到如下内容,可以看到在 endebug() 方法中就是修改页面的代码:

通过查看上面的代码可以发现,debugflag 就是判断条件,而 loadTad() 则是获取数据的接口,当程序检测到开发者工具被打开时,debugflag 的值改为 true,endebug() 函数执行,页面也就被修改掉了。
那么 endebug() 方法的具体内容是什么呢?全局搜索“endebug”,可以找到一个 JavaScript 文件(连接为:https://www.aqistudy.cn/js/jquery.min.js?v=1.2),在其中能找到如下代码部分:
// debug detect
eval(function(p, a, c, k, e, d) {
e = function(c) {
return (c < a ? "" : e(parseInt(c / a))) + ((c = c % a) > 35 ? String.fromCharCode(c + 29) : c.toString(36))
}
;
if (!''.replace(/^/, String)) {
while (c--)
d[e(c)] = k[c] || e(c);
k = [function(e) {
return d[e]
}
];
e = function() {
return '\\w+'
}
;
c = 1;
}
;while (c--)
if (k[c])
p = p.replace(new RegExp('\\b' + e(c) + '\\b','g'), k[c]);
return p;
}('2 M(g,y){h(!g){!2(e){2 n(e){2 n(){j u}2 o(){4.8&&4.8.m&&4.8.m.H?t("9"):(a="g",v.G(d),v.F(),t(a))}2 t(e){u!==e&&(u=e,"2"==7 c.5&&c.5(e))}2 r(){l||(l=!0,4.I("k",o),L(f))}"2"==7 e&&(e={5:e});3 i=(e=e||{}).K||J,c={};c.5=e.5;3 a,d=B z;d.D("C",2(){a="9"});3 u="E";c.A=n;3 f=s(o,i);4.S("k",o);3 l;j c.N=r,c}3 o=o||{};o.x=n,"2"==7 6?(6.P||6.R)&&6(2(){j o}):"O"!=7 b&&b.p?b.p=o:4.q=o}(),q.x(2(e){3 a=0;3 n=s(2(){h("9"==e){w(2(){h(a==0){a=1;w(y)}},Q)}},T)})}}', 56, 56, '||function|var|window|onchange|define|typeof|Firebug|on||module|||||off|if||return|resize||chrome|||exports|jdetects||setInterval|||console|setTimeout|create|code|Image|getStatus|new|id|__defineGetter__|unknown|clear|log|isInitialized|removeEventListener|500|delay|clearInterval|endebug|free|undefined|amd|200|cmd|addEventListener|100'.split('|'), 0, {}))
解密出来可以发现这段代码就是用于检测开发者工具有没有打开,若打开了,则触发反调试,修改页面。
三、解决方案
首先在首页的源码中的如下位置打上断点,然后刷新页面,进入调试状态。
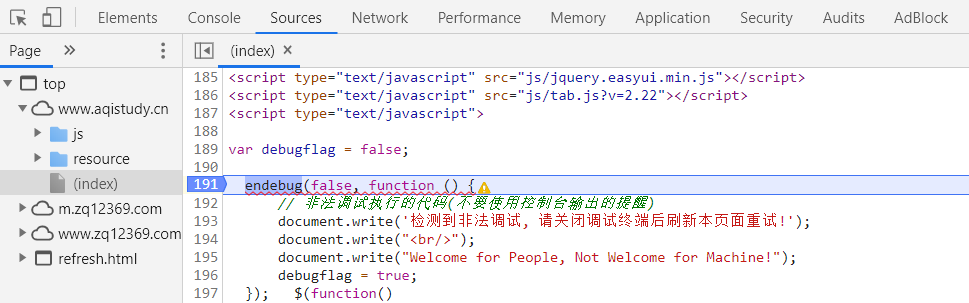
然后切换到 Console 选项页,在其中对 endebug() 方法进行重新定义,输入如下内容:
function endebug(){}
如下图所示,输入完回车,然后继续执行(Chrome 的快捷键是 F8):
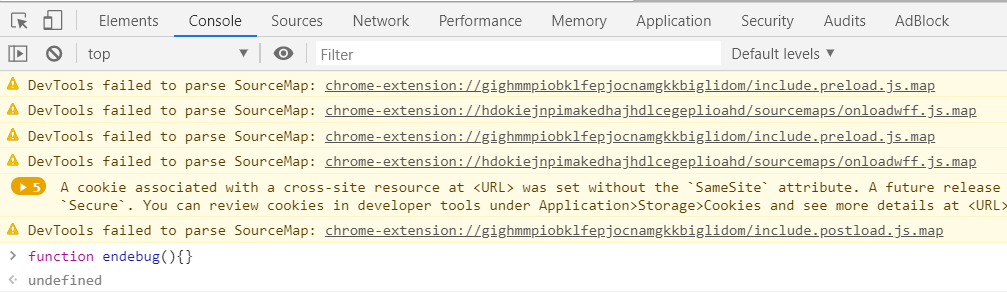
进行完上述步骤后,就能正常的抓包分析了。
【Python3爬虫】一次应对JS反调试的记录的更多相关文章
- 【Python3爬虫】突破反爬之应对前端反调试手段
一.前言 在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕: 此时网页暂停加载,自动跳转到 Source 页面并打开了一个 ...
- 使用KRPano资源分析工具强力加密KRPano项目(XML防破解,切片图保护,JS反调试)
软件交流群:571171251(软件免费版本在群内提供) krpano技术交流群:551278936(软件免费版本在群内提供) 最新博客地址:blog.turenlong.com 限时下载地址:htt ...
- 【Python3爬虫】反反爬之解决前端反调试问题
一.前言 在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕: 此时网页暂停加载,也就没法运行代码了,直接中断掉了,难道这就能阻止 ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- 爬虫之如何找js入口(一)
目标网页:https://m.gojoy.cn/pages/login/ 将我删除i ndex?from=%2Fpages%2Fuser%2Findex 需要工具:chrome和油猴 油猴代码: // ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
- 基于TLS的反调试技术
TLS(Thread Local Storage 线程局部存储) 一个进程中的每个线程在访问同一个线程局部存储时,访问到的都是独立的绑定于该线程的数据块.在PEB(进程环境块)中TLS存储槽共64个( ...
随机推荐
- 2019CSP复赛游记
Day 0 作为一个初三的小蒟蒻…… 什么算法都不会打…… 做一道LCA+生成树的图论题调了两个小时…… 明日裸考…… Day 1 Morning 买了两个士力架,带了一盒牛奶,准备在考场上食用(这个 ...
- [Other]THUWC2020 游记
Dec. 20th 一下飞机,\(\text{FJ}\) 选手感觉 \(\text{BJ}\) 好冷 下午去了鸟巢,晚上回 \(\text{GLHT}\) 酒店吃泡面 写了洛谷上的线段树分治模板题之后 ...
- 「 从0到1学习微服务SpringCloud 」08 构建消息驱动微服务的框架 Spring Cloud Stream
系列文章(更新ing): 「 从0到1学习微服务SpringCloud 」01 一起来学呀! 「 从0到1学习微服务SpringCloud 」02 Eureka服务注册与发现 「 从0到1学习微服务S ...
- robotframework从列表中循环读取数据,传入关键字执行
场景预设:从列表内读取手机号,自动化执行微信加好友,直至选择完所有数据后,脚本停止执行 1.建一个备选数据表,表内列待添加的手机号数据 2.脚本的主要流程新加好友-输入手机号-添加好友-判断好友是否存 ...
- python从excel中读取数据传给其他函数使用
首先安装xlrd库 pip install xlrd 方法1: 表格内容如下: 场景描述,读取该表格A列数据,然后打印出数据 代码何解析如下: import xlrd #引入xlrd库 def exc ...
- Linux 高压缩率工具 XZ 压缩详解
目录 一.XZ 基础信息 二.安装 三.详解 3.1.常用的参数 3.2. 常用命令 四.扩展 4.1.unxz 4.2.xzcat 4.3.lzma 4.4.unlzma 4.5.lzcat 一.X ...
- mysql5.7的基本使用
mysql的基本使用:最简单的增删改查 (建议用类似记事本的东西写代码,错了容易改) 以下就是这篇文章的代码 一,增和查 CREATE DATABASE one; 新建了一个名为one的数据库 S ...
- ios--->const 用法总结
const 用法总结 宏.变量.常量区分 宏:只是在预处理器里进行文本替换,没有类型,不做任何类型检查,编译器可以对相同的字符串进行优化.只保存一份到 .rodata 段.甚至有相同后缀的字符串也可以 ...
- X-CTF(REVERSE入门) re1
运行程序 32位ida打开,shift+f12查看运行时的中文,这里双击flag get字符串进入rdata段 双击后面的函数,进入text段,小的窗口视图里可以看见汇编代码调用函数的句子 右边的即是 ...
- vue-particles做背景,鼠标动画粒子连线填坑(按钮没有点击响应)
为了提高页面展示效果,登录界面内容比较单一的,粒子效果作为背景经常使用到,vue工程中利用vue-particles可以很简单的实现页面的粒子背景效果. 解决问题: 以背景方式显示 无法获取按钮焦点, ...