DOM基础+domReady+元素节点类型判断
DOM节点类型 nodeType
element 1 Node.ELEMENT_NODE 元素节点
attr 2 Node.ATTRIBUTE_NODE 属性节点
text 3 Node.TEXT_NODE 文本节点(标签之间的空白区域也属于文本节点)
comment 8 Node.COMMENT_NODE 注释节点
document 9 Node.DOCUMENT_NODE 文档节点(所有文档之上,即一个页面中最最前面的位置,在文档定义的前面)
documentType 10 Node.DOCUMENT_TYPE_NODE 文档类型节点(DOCTYPE)
documentFragment 11 Node.DOCUMENT_FRAGMENT_NODE 文档片段节点(不属于文档树,是最小片段,可以作为临时占位符,将它插入文档时,只会插入它的子孙元素,而不是它本身)
注意:IE8及以下没有node,使用常量来判断nodeType会报错:“Node”未定义
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style> </head>
<body>
<div id="container"></div>
<script>
window.onload=function(){ var container=document.getElementById("container");
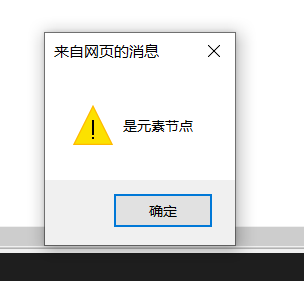
if(container.nodeType==Node.ELEMENT_NODE){
alert("是元素节点");
}
}
</script>
</body>
</html>
因此不建议使用常量来判断,建议使用数值
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style> </head>
<body>
<div id="container"></div>
<script>
window.onload=function(){ var container=document.getElementById("container");
// if(container.nodeType==Node.ELEMENT_NODE){
// alert("是元素节点");
// }
if(container.nodeType==1){
alert("是元素节点");
}
}
</script>
</body>
</html>
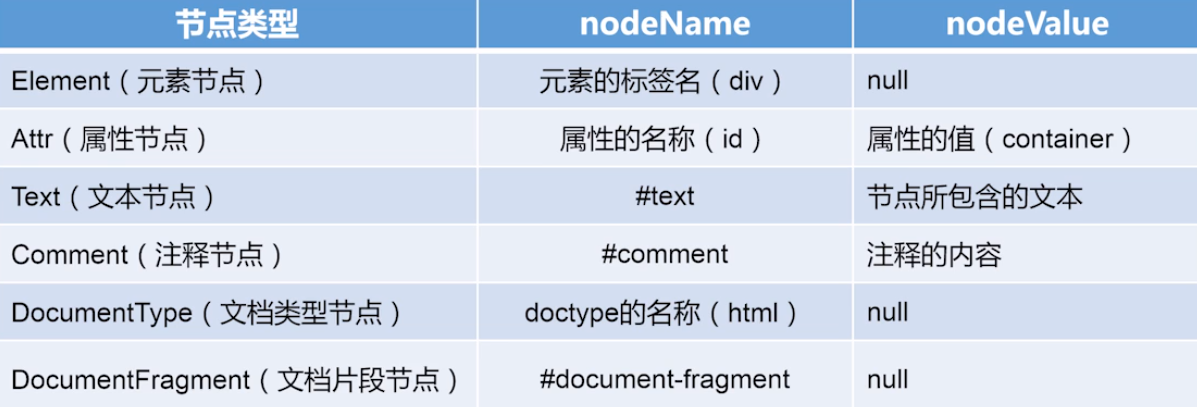
nodeName 节点名称
nodeValue 节点值
.attributes 保存元素的所有属性,可以使用数组下标访问某一个具体的属性
.chilsNodes 获取元素的所有子节点,可以使用数组下标访问某一个具体的属性
document.doctype 获取文档类型节点
document.createDocumentFlagment() 创建文档片段
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style> </head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div>
<script>
window.onload=function(){ var container=document.getElementById("container");
console.log("元素节点:"+container.nodeName+"/"+container.nodeValue);//元素节点:DIV/null
var attr=container.attributes[0];//获取元素的第一个属性
console.log("属性节点:"+attr.nodeName+"/"+attr.nodeValue);//属性节点:id/container
var text=container.childNodes[0];//获取元素的第一个子元素节点
console.log("文本节点:"+text.nodeName+"/"+text.nodeValue);//文本节点:#text/这是里面的文本鸭
var comment=document.body.childNodes[1];//获取body元素的第二个子元素节点(第一个子元素节点是空白文本节点)
console.log("注释节点:"+comment.nodeName+"/"+comment.nodeValue);//注释节点:#comment/ 这是一段注释哈
var doctype=document.doctype;//获取body元素的第二个子元素节点(第一个子元素节点是空白文本节点)
console.log("文档类型节点:"+doctype.nodeName+"/"+doctype.nodeValue);//文档类型节点:html/null
var docFragment=document.createDocumentFragment();//获取body元素的第二个子元素节点(第一个子元素节点是空白文本节点)
console.log("文档片段节点:"+docFragment.nodeName+"/"+docFragment.nodeValue);//文档片段节点:#document-fragment/null
}
</script>
</body>
</html>

当script脚本在DOM元素之前,会无法获取到DOM元素
因为把js代码放在head中,代码顺序执行,当页面在浏览器中打开时,会先执行js代码,再执行body里面的dom结构。如果js执行时要获取body中的元素,那么就会报错,因为页面的结构还没有加载进来。
可以使用window.onload解决
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script>
window.onload=function(){ var container=document.getElementById("container");
console.log(container);
}
</script>
</head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div> </body>
</html>
window.onload缺点:等待DOM树的加载和外部资源全部加载完成
如果页面引用了很多外部资源,会导致加载慢,影响用户体验
最佳解决方案,jquery的$(document).ready()
此处使用原生js仿写该方法
DOMContentLoaded 加载完dom树,但还没有开始加载外部资源
IE不支持该方法,使用:document.documentElement.doScroll("left")
监听document的加载状态 document.onreadystatechange
document加载完成 document.readyState=="complete"
arguments.callee 调用函数自身
自己写的DomReady.js
function myReady(fn){
/*
现代浏览器操作
*/
if(document.addEventListener){
//现代浏览器操作
document.addEventListener("DOMContentLoaded",fn,false);//false表示在冒泡阶段捕获
}else{
//IE环境操作
IEContentLoaded(fn);
}
/*
IE环境操作
*/
function IEContentLoaded(fn){
// init()--保证fn只调用一次
var loaded=false;
var init=function(){
if(!loaded){
loaded=true;
fn();
}
}
// 如果DOM树加载还没完成,就不停尝试
(function(){
try{
// 如果DOM树加载还没完成,会抛出异常
document.documentElement.doScroll("left");
}catch(e){
// 尝试失败,则再次尝试
setTimeout(arguments.callee,50);
return;//实现递归
}
//如果没有抛出异常,则立刻执行init()
init();
})();
// DOM树加载完成之后,调用init()方法
document.onreadystatechange=function(){
if(document.readyState=="complete"){
document.onreadystatechange=null;//清除监听事件
init();
}
}
}
}
调用该js
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script>
<script>
myReady(function(){
var container=document.getElementById("container");
console.log(container);
});
</script>
</head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div> </body>
</html>
实现各浏览器都能成功获取到~
下面来真实感受下window.onload 和domReady的区别!!!
使用多张大图图片来模拟加载时长
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div>
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg"> <script> myReady(function(){
alert("domReady!");
domready=new Date().getTime();
}); window.onload=function(){
alert("windowLoaded!");
windowload=new Date().getTime();
} </script>
</body>
</html>
发现先弹出domReady
等到图片加载完成之后,才弹出windowLoaded
证实windowLoaded耗时比较久
元素节点的类型判断
isElement() 判断是否是元素节点
isHTML() 判断是否是html文档的元素节点
isXML() 判断是否是xml文档的元素节点
contains() 判断元素节点之间是否是包含关系
.nextSibling 获取元素的兄弟节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div id="container">这是里面的文本鸭</div><!-- 这是一段注释哈 --> <script> myReady(function(){ function isElement(el){
return !!el && el.nodeType===1;
} console.log(isElement(container));
console.log(isElement(container.nextSibling));
}); </script>
</body>
</html>
该方法有一个Bug,即如果有一个对象设置了nodeType属性,会导致判断错误
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div id="container">这是里面的文本鸭</div><!-- 这是一段注释哈 --> <script> myReady(function(){ function isElement(el){
return !!el && el.nodeType===1;
} var obj={
nodeType:1
}
console.log(isElement(obj));//true
}); </script>
</body>
</html>
isXML() 最严谨的写法
.createElement() 创建元素
如果不区分大小写,则为html文档的元素节点;
如果区分大小写,则为xml文档的元素节点
.ownerDocument返回元素自身的文档对象
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div id="container">这是里面的文本鸭</div><!-- 这是一段注释哈 --> <script> myReady(function(){
// 判断是否是元素节点
function isElement(el){
return !!el && el.nodeType==1;
}
// 判断是否是xml文档
function isXML(el){
return el.createElement("p").nodeName!==el.createElement("P").nodeName;
}
// 判断是否是html文档
function isHTML(el){
return el.createElement("p").nodeName===el.createElement("P").nodeName;
}
// 判断是否是html文档的元素节点
function isHTMLNode(el){
if(isElement(el)){
return isHTML(el.ownerDocument);
}
return false;
}
console.log(isXML(document));//false
console.log(isHTML(document));//true
console.log(isHTMLNode(container));//true
}); </script>
</body>
</html>
.containers 判断某个节点是否包含另一个节点
谷歌浏览器表现正常,而IE浏览器要求两个节点都必须是元素节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div class="parent" id="parent">
<div class="child" id="child">这是文本节点</div>
</div> <script> myReady(function(){
var parent=document.getElementById("parent");
var child=document.getElementById("child");
console.log(parent.contains(child));//true var text=child.childNodes[0];
console.log(parent.contains(text));//谷歌浏览器true,IE浏览器为false
}); </script>
</body>
</html>
接下来给出兼容性写法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div class="parent" id="parent">
<div class="child" id="child">这是文本节点</div>
</div> <script> myReady(function(){
var parent=document.getElementById("parent");
var child=document.getElementById("child");
console.log(parent.contains(child));//true var text=child.childNodes[0];
console.log(parent.contains(text));//谷歌浏览器true,IE浏览器为false function fixContains(pNode,cNode){
try{
while(cNode=cNode.parentNode){
if(pNode===cNode) return true;
}
return false;
}catch(e){
return false;
}
}
console.log(fixContains(parent,text));//谷歌浏览器true,IE浏览器为true
}); </script>
</body>
</html>
在所有浏览器里都能返回true,哪怕不是元素节点
DOM基础+domReady+元素节点类型判断的更多相关文章
- 第10章 文档对象模型DOM 10.1 Node节点类型
DOM是针对 HTML 和 XML 文档的一个 API(应用程序编程接口) .DOM描绘了一个层次化的节点树,允许开发人员添加.移除和修改页面的某一部分.DOM 脱胎于Netscape 及微软公司创始 ...
- DOM-判断元素节点类型
http://stackoverflow.com/questions/384286/javascript-isdom-how-do-you-check-if-a-javascript-object-i ...
- JS 清除DOM 中空白元素节点
HTML中的空白节点会影响整体的HTML的版面排榜 例如: 制作百度首页时,两个input之间的空白节点将本来是要整合在一起的搜索栏硬是把按钮和搜索框分离出现好丑的间隙 这时我们就可以用js清除这个空 ...
- DOM基础2——元素
1.造元素 document.createElement("标签名") 例:var div_new=document.createElement("div"); ...
- 深入理解DOM节点类型第七篇——文档节点DOCUMENT
× 目录 [1]特征 [2]快捷访问 [3]文档写入 前面的话 文档节点document,隶属于表示浏览器的window对象,它表示网页页面,又被称为根节点.本文将详细介绍文档节点document的内 ...
- DOM节点类型
DOM1级定义了一个Node接口,该接口将由DOM中的所有节点类型实现.这个Node接口在JavaScript中是作为Node类型实现的:除了IE外,在其他所有浏览器中都可以访问到这个类型.JavaS ...
- javascript DOM中的节点层次和节点类型概述
针对JS高级程序设计这本书,主要是理解概念,大部分要点源自书内.写这个主要是当个笔记加总结 存在的问题请大家多多指正! 因为DOM这方面的对象方法操作性都特别强,但是逻辑很简单,所以就没有涉及到实际的 ...
- js文本对象模型[DOM]【续】(Node节点类型)
一.Document类型 document实例1.常用的一些属性documentElement 始终指向HTML页面中的<html>元素.body 直接指向<body>元 ...
- 深入浅出DOM基础——《DOM探索之基础详解篇》学习笔记
来源于:https://github.com/jawil/blog/issues/9 之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西 ...
随机推荐
- MCMC&Gibbs sampling
Note of Markov Chain Monte Carlo and Gibbs Sampling : http://pan.baidu.com/s/1jHpWY1o 序:A major lim ...
- Shell case语法结构解析
case ... esac 与其他语言中的 switch ... case 语句类似,是一种多分枝选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 ...
- Arduino系列之按键模块(二)
上一节简单介绍啦一下按键模块怎么使用 但是在使用过程中会常常出现延时时间过长,有时候按键会失灵 所以,接下来,我将优化程序,使得按键按下时,就能使count加1 下面是程序思路:同样的定义按键脚: 定 ...
- Nginx之keepalived高可用工具
1.创建两台虚拟机,分别为主机和从机,区别两台虚拟机的IP地址 2. 将keepalived上传到linux系统当中 3. cd /usr/local目录 4. tar -zxvf keepalive ...
- Python爬虫小结
有些数据是没有专门的数据集的,为了找到神经网络训练的数据,自然而然的想到了用爬虫的方法开始采集数据.一开始采用了网上的一个动态爬虫的代码,发现爬取的图片大多是重复的,有效图片很少. 动态爬虫: fro ...
- DBA常用SQL之DDL生成语句-2
------数据迁移常用SQL SELECT 'DROP USER '||u.username ||' CASCADE;' AS dropstrs FROM DBA_USERS U where u.u ...
- Go语言实现:【剑指offer】包含min函数的栈
该题目来源于牛客网<剑指offer>专题. 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数. 时间复杂度应为O(1). Go语言实现: var myList = ...
- android 基础学习笔记3
1.XML解析 与 Json 解析 (文件读取一般较耗时 可将相应的解析做成方法 用线程调用) 一.XML解析 (pull解析)res/xml(资源文件 需用到Resources) Xml文本 ...
- liunx 上守护进程的设置
*/2 * * * * root /data/autojobsh/auto_ck_pms_10250.sh */2 * * * * root /data/autojobsh/auto_ck_ipms_ ...
- Python Special Methods - 特殊方法
特殊方法 特殊方法的存在是为了给 Python 解释器调用的,通常自己并不需要直接调用它们.也就是说不应该使用 my_object.__len__() 这种写法,而应该使用 len(my_object ...