【word2vec】Distributed Representation——词向量
Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。
其基本想法是:
通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入“距离”,则可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。
为更好地理解上述思想,我们来举一个通俗的例子:假设在二维平面上分布有 N 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点,我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标 (x,y);接着引入欧氏距离;最后分别计算这个词与其他 N-1 个词之间的距离,对应最小距离值的那个词便是我们要找的词了。
上面的例子中,坐标(x,y) 的地位相当于词向量,它用来将平面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的,然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量也依赖于训练语料、训练算法和词向量长度等因素。
一种生成词向量的途径是利用神经网络算法,当然,词向量通常和语言模型捆绑在一起,即训练完后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出。 这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR 上的 A Neural Probabilistic Language Model,其后有一系列相关的研究工作。
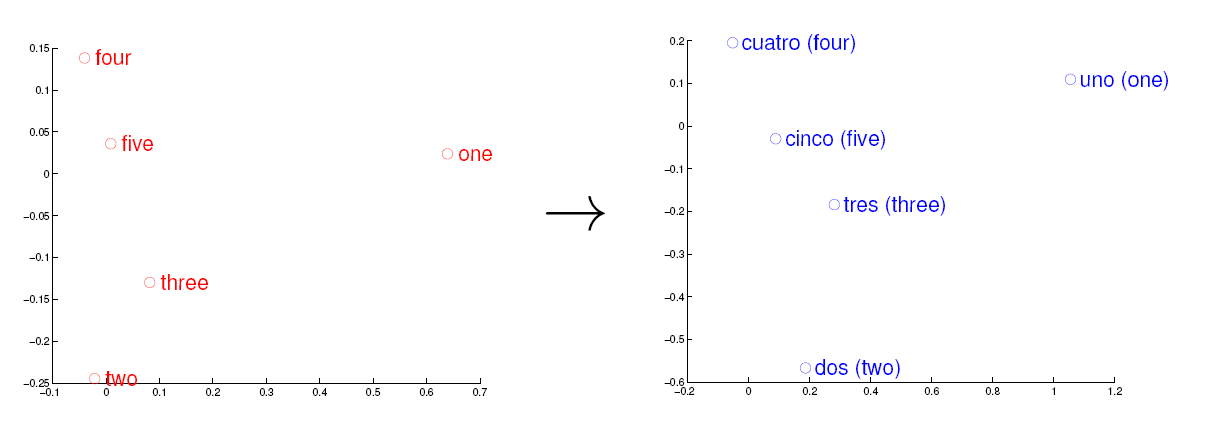
<img src="https://pic2.zhimg.com/469f845025ef071bba1a578565d8b261_b.jpg" data-rawwidth="1211" data-rawheight="445" class="origin_image zh-lightbox-thumb" width="1211" data-original="https://pic2.zhimg.com/469f845025ef071bba1a578565d8b261_r.jpg">观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
Tomas Mikolov在Google的时候发的这两篇paper:“Efficient Estimation of Word Representations in Vector Space”、“Distributed Representations of Words and Phrases and their Compositionality”。
这两篇paper中提出了一个word2vec的工具包,里面包含了几种word embedding的方法,这些方法有两个特点。一个特点是速度快,另一个特点是得到的embedding vectors具备analogy性质。analogy性质类似于“A-B=C-D”这样的结构,举例说明:“北京-中国 = 巴黎-法国”。Tomas Mikolov认为具备这样的性质,则说明得到的embedding vectors性质非常好,能够model到语义。
这两篇paper是2013年的工作,至今(2017.3),这两篇paper的引用量早已经超好几千,足以看出其影响力很大。当然,word embedding的方案还有很多
常见的word embedding的方法有:
1. Distributed Representations of Words and Phrases and their Compositionality
2. Efficient Estimation of Word Representations in Vector Space
3. GloVe Global Vectors forWord Representation
4. Neural probabilistic language models
5. Natural language processing (almost) from scratch
6. Learning word embeddings efficiently with noise contrastive estimation
7. A scalable hierarchical distributed language model
8. Three new graphical models for statistical language modelling
9. Improving word representations via global context and multiple word prototypes
word2vec中的模型至今(2017.3)还是存在不少未解之谜,因此就有不少papers尝试去解释其中一些谜团,或者建立其与其他模型之间的联系
paper list
2. Linguistic Regularities in Sparse and Explicit Word Representation
3. Random Walks on Context Spaces Towards an Explanation of the Mysteries of Semantic Word Embeddings
4. word2vec Explained Deriving Mikolov et al.’s Negative Sampling Word Embedding Method
链接:https://www.zhihu.com/question/21714667/answer/19433618
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【word2vec】Distributed Representation——词向量的更多相关文章
- 文本分类实战(一)—— word2vec预训练词向量
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- word2vec 构建中文词向量
词向量作为文本的基本结构——词的模型,以其优越的性能,受到自然语言处理领域研究人员的青睐.良好的词向量可以达到语义相近的词在词向量空间里聚集在一起,这对后续的文本分类,文本聚类等等操作提供了便利,本文 ...
- 使用word2vec训练中文词向量
https://www.jianshu.com/p/87798bccee48 一.文本处理流程 通常我们文本处理流程如下: 1 对文本数据进行预处理:数据预处理,包括简繁体转换,去除xml符号,将单词 ...
- word2vec预训练词向量
NLP中的Word2Vec讲解 word2vec是Google开源的一款用于词向量计算 的工具,可以很好的度量词与词之间的相似性: word2vec建模是指用CBoW模型或Skip-gram模型来计算 ...
- gensim的word2vec如何得出词向量(python)
首先需要具备gensim包,然后需要一个语料库用来训练,这里用到的是skip-gram或CBOW方法,具体细节可以去查查相关资料,这两种方法大致上就是把意思相近的词映射到词空间中相近的位置. 语料库t ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 文本分布式表示(二):用tensorflow和word2vec训练词向量
看了几天word2vec的理论,终于是懂了一些.理论部分我推荐以下几篇教程,有博客也有视频: 1.<word2vec中的数学原理>:http://www.cnblogs.com/pegho ...
- 基于word2vec训练词向量(二)
转自:http://www.tensorflownews.com/2018/04/19/word2vec2/ 一.基于Hierarchical Softmax的word2vec模型的缺点 上篇说了Hi ...
- 文本情感分析(二):基于word2vec、glove和fasttext词向量的文本表示
上一篇博客用词袋模型,包括词频矩阵.Tf-Idf矩阵.LSA和n-gram构造文本特征,做了Kaggle上的电影评论情感分类题. 这篇博客还是关于文本特征工程的,用词嵌入的方法来构造文本特征,也就是用 ...
随机推荐
- 谈UIView Animation编程艺术
一.大小动画(改变frame) -(void)changeFrame{ CGRect originalRect = self.anView.frame; CGRect rect = CGRectMak ...
- VI 基本可视模式
可视模式让你可以选择文件的一部分内容,以便作比如删除,复制等工作. 进入可视模式 v 用v命令进入可视模式.当光标移动时,就能看到有一些文本被高亮显示了,它们就是被选中的内容. 三种可视模式 v 一个 ...
- php bccomp的替换函数
if (!function_exists('bccomp')) { /** * 支持正数和负数的比较 * ++ -- +- * @param $numOne * @param $numTwo * @p ...
- android异步处理机制
昨天面试被提问android的异步处理机制有哪些,他说处理new thread还有哪种方式,我说implement runnable,他说不是,比如intentservice. 我说那还有asyncT ...
- java 高性能读模式(译)
原文地址:http://tutorials.jenkov.com/java-performance/read-patterns.html 好久没翻译了,逛知乎,无意间发现的一个链接,写的太好了,而且内 ...
- Unix考古记:一个“遗失”的shell
谨以此文纪念伟大的计算机科学巨匠Ken Thompson和Dennis Ritchie,并同时向其他所有为Unix发展做出贡献的黑客致敬. 历史的尘埃 Unix作为一个举世闻名的操作系统已有40余年的 ...
- VC下加载JPG/GIF/PNG图片的两种方法
转载自:http://blog.sina.com.cn/s/blog_6582aa410100huil.html 仅管VC有提供相应的API和类来操作bmp位图.图标和(增强)元文件,但却不支持jpg ...
- Python 文件 next() 方法
描述 Python 3 中的 文件 对象不支持 next() 方法. Python 3 的内置函数 next() 通过迭代器调用 __next__() 方法返回下一项. 在循环中,next()方法会在 ...
- netty服务端实现心跳超时的主动拆链
一.服务器启动示例: public class MySocketServer { protected static Logger logger = LoggerFactory.getLogger(My ...
- 【转载】centos 安装及配置 mysql5.5.3 - rpm安装server和client
安装 https://blog.csdn.net/cxy1238/article/details/2518480 1. 设置root用户的密码 方法一: # mysqladmin -u root -p ...