spark-sklearn(spark扩展scikitlearn)
(1)官方规定安装条件:此包装具有以下要求:
-*最新版本的scikit学习。 版本0.17已经过测试,旧版本也可以使用。
- *Spark> = 2.0。 Spark可以从对应官网下载
[Spark官方网站](http://spark.apache.org/)
-*为了使用spark-sklearn,您需要使用pyspark解释器或其他Spark兼容的python解释器。
有关详细信息,请参阅[Spark指南](https://spark.apache.org/docs/latest/programming-guide.html#overview)。
- (https://nose.readthedocs.org)(仅测试依赖关系)
英文原文:This package has the following requirements:
- a recent version of scikit-learn. Version 0.17 has been tested, older versions may work too.
- Spark >= 2.0. Spark may be downloaded from the
[Spark official website](http://spark.apache.org/) In order to use spark-sklearn, you need to use the pyspark interpreter or another Spark-compliant python interpreter. See the [Spark guide](https://spark.apache.org/docs/latest/programming-guide.html#overview) for more details.
- [nose](https://nose.readthedocs.org) (testing dependency only)
(2)首先安装pyspark:
参考为的博客:http://www.cnblogs.com/jackchen-Net/p/6667205.html#_label5
(3)访问网址:https://pypi.python.org/pypi/spark-sklearn
目前Spark集成了Scikit-learn包,这样可以极大的简化了python数据科学家们的工作,这个包可以在Spark集群上自动分配模型参数优化计算任务
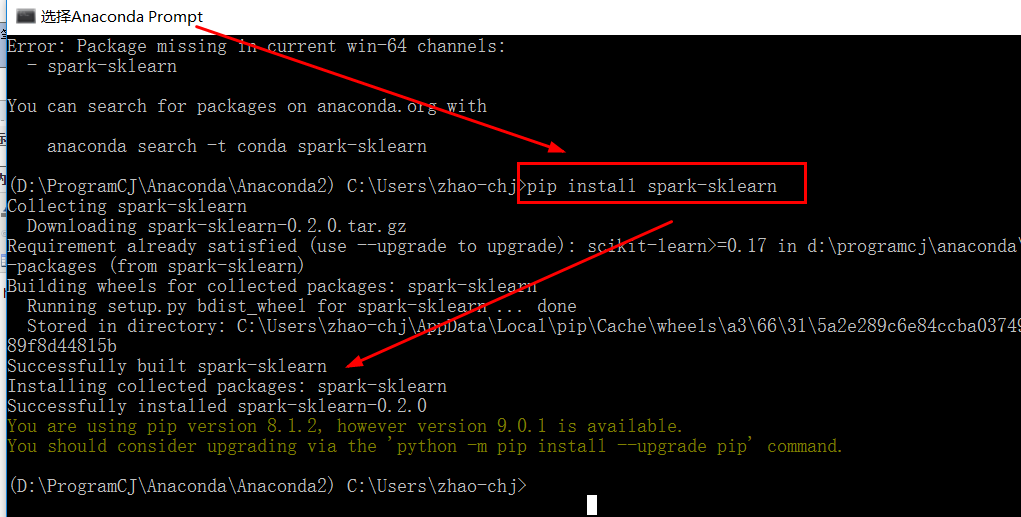
(4)官方文档的例子测试
## Example Here is a simple example that runs a grid search with Spark. See the [Installation](#Installation) section on how to install spark-sklearn. ```python
from sklearn import svm, grid_search, datasets
from spark_sklearn import GridSearchCV
iris = datasets.load_iris()
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
svr = svm.SVC()
clf = GridSearchCV(sc, svr, parameters)
clf.fit(iris.data, iris.target)
``` This classifier can be used as a drop-in replacement for any scikit-learn classifier, with the same API.
END~
spark-sklearn(spark扩展scikitlearn)的更多相关文章
- 基于Spark自动扩展scikit-learn (spark-sklearn)(转载)
转载自:https://blog.csdn.net/sunbow0/article/details/50848719 1.基于Spark自动扩展scikit-learn(spark-sklearn)1 ...
- Spark Streaming揭秘 Day9 从Receiver的设计到Spark框架的扩展
Spark Streaming揭秘 Day9 从Receiver的设计到Spark框架的扩展 Receiver是SparkStreaming的输入数据来源,从对Receiver整个生命周期的设计,我们 ...
- Spark RDD API扩展开发
原文链接: Spark RDD API扩展开发(1) Spark RDD API扩展开发(2):自定义RDD 我们都知道,Apache Spark内置了很多操作数据的API.但是很多时候,当我们在现实 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark记录-spark介绍
Apache Spark是一个集群计算设计的快速计算.它是建立在Hadoop MapReduce之上,它扩展了 MapReduce 模式,有效地使用更多类型的计算,其中包括交互式查询和流处理.这是一个 ...
- Spark之 spark简介、生态圈详解
来源:http://www.cnblogs.com/shishanyuan/p/4700615.html 1.简介 1.1 Spark简介Spark是加州大学伯克利分校AMP实验室(Algorithm ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- Spark Streaming——Spark第一代实时计算引擎
虽然SparkStreaming已经停止更新,Spark的重点也放到了 Structured Streaming ,但由于Spark版本过低或者其他技术选型问题,可能还是会选择SparkStreami ...
- Spark—初识spark
Spark--初识spark 一.Spark背景 1)MapReduce局限性 <1>仅支持Map和Reduce两种操作,提供给用户的只有这两种操作 <2>处理效率低效 Map ...
- Spark Shell & Spark submit
Spark 的 shell 是一个强大的交互式数据分析工具. 1. 搭建Spark 2. 两个目录下面有可执行文件: bin 包含spark-shell 和 spark-submit sbin 包含 ...
随机推荐
- matlab矩阵内存预分配
matlab矩阵内存预分配就意味着,划定一个固定的内存块,各数据可直接按"行.列指数"存放到对应的元素中.若矩阵中不预配置内存.则随着"行.列指数"的变大.MA ...
- mysql asyn 实战
创建configuration时,发现URLParser找不到,于是只能使用配置文件来,当然使用配置文件比使用URL初始化还要直观些 def configurationWithPassword = n ...
- Eclipse cdt解决github导入的项目无法打开声明的bug (cannot open declaration)
概述: 我利用eclipse 的git插件clone github上的远程项目(C++)到本地时遇到一个问题:clone下来的项目没有C++特性,无法使用open declaration等操作,下面是 ...
- 【Ubuntu】Windows 远程桌面连接ubuntu及xrdp的一些小问题(远程桌面闪退、连接失败、tab补全功能,无菜单栏,error - problem connecting )【转】
转:https://blog.csdn.net/u014447845/article/details/80291678 1.远程桌面闪退,shell可以用的问题:(1)需要在该用户目录创建一个.xse ...
- 【应用安全】微软的安全开发生命周期(SDL)
0x01 SDL介绍 安全开发生命周期(SDL)即Security Development Lifecycle,是一个帮助开发人员构建更安全的软件和解决安全合规要求的同时降低开发成本的软件开发过程. ...
- RF变量列表类型@{}和${}列表类型的关系
总结:@{}列表类型和${}列表类型都可以表示list类型,均可以通过 set variable 和 create list 创建,区别主要是展示格式和引用格式: @{}类型可以通过 set vari ...
- [Python] NotImplemented 和 NotImplementedError 区别
NotImplemented 是一个非异常对象,NotImplementedError 是一个异常对象. >>> NotImplemented NotImplemented > ...
- 分布式计算开源框架Hadoop入门实践
目录(?)[+] Author :岑文初 Email: wenchu.cenwc@alibaba-inc.com msn: cenwenchu_79@hotmail.com blog: http:// ...
- Elasticsearch 配置同义词
配置近义词 近义词组件已经是elasticsearch自带的了,所以不需要额外安装插件,但是想要让近义词和IK一起使用,就需要配置自己的分析器了. 首先创建近义词文档 在config目录下 mkdir ...
- Python错误和异常 学习笔记
错误和异常概念 错误: 1.语法错误:代码不符合解释器或者编译器语法 2.逻辑错误:不完整或者不合法输入或者计算出现问题 异常:执行过程中出现万体导致程序无法执行 1.程序遇到 ...