深度学习attention 机制了解
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制(Mechanism),一般称为Attention Mechanism。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(Image Caption)等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力,例如,在机器翻译、语音识别应用中,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活(soft),同时Attention本身可以做为一种对齐关系,解释翻译输入/输出句子之间的对齐关系,解释模型到底学到了什么知识,为我们打开深度学习的黑箱,提供了一个窗口,如图1所示。
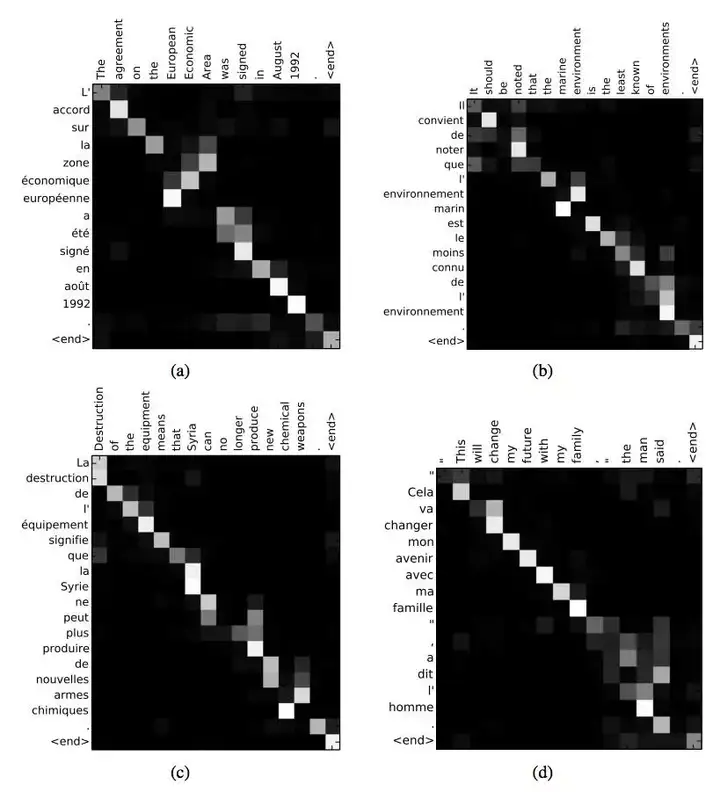
图1 NLP中的attention可视化
又比如在图像标注应用中,可以解释图片不同的区域对于输出Text序列的影响程度。

图2 图像标注中的attention可视化
通过上述Attention Mechanism在图像标注应用的case可以发现,Attention Mechanism与人类对外界事物的观察机制很类似,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attention到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。因此,Attention Mechanism可以帮助模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因。
有了这些背景知识的铺垫,接下来就一一介绍下Attention Mechanism其他细节,在接写来的内容里,我会主要介绍以下一些知识:
1. Attention Mechanism原理
1.1 Attention Mechanism主要需要解决的问题
1.2 Attention Mechanism原理
2. Attention Mechanism分类
基本attention结构
2.1 soft Attention 与Hard Attention
2.2 Global Attention 和 Local Attention
2.3 Self Attention
组合的attention结构
2.4 Hierarchical Attention
2.5 Attention in Attention
2.3 Multi-Step Attention
3. Attention的应用场景
3.1 机器翻译(Machine Translation)
3.2 图像标注(Image Captain)
3.3 关系抽取(EntailMent Extraction)
3.4 语音识别(Speech Recognition)
3.5 自动摘要生成(Text Summarization)
1. Attention Mechanism原理
1.1 Attention Mechanism主要需要解决的问题
《Sequence to Sequence Learning with Neural Networks》介绍了一种基于RNN的Seq2Seq模型,基于一个Encoder和一个Decoder来构建基于神经网络的End-to-End的机器翻译模型,其中,Encoder把输入X编码成一个固定长度的隐向量Z,Decoder基于隐向量Z解码出目标输出Y。这是一个非常经典的序列到序列的模型,但是却存在两个明显的问题:
1、把输入X的所有信息有压缩到一个固定长度的隐向量Z,忽略了输入输入X的长度,当输入句子长度很长,特别是比训练集中最初的句子长度还长时,模型的性能急剧下降。
2、把输入X编码成一个固定的长度,对于句子中每个词都赋予相同的权重,这样做是不合理的,比如,在机器翻译里,输入的句子与输出句子之间,往往是输入一个或几个词对应于输出的一个或几个词。因此,对输入的每个词赋予相同权重,这样做没有区分度,往往是模型性能下降。
同样的问题也存在于图像识别领域,卷积神经网络CNN对输入的图像每个区域做相同的处理,这样做没有区分度,特别是当处理的图像尺寸非常大时,问题更明显。因此,2015年,Dzmitry Bahdanau等人在《Neural machine translation by jointly learning to align and translate》提出了Attention Mechanism,用于对输入X的不同部分赋予不同的权重,进而实现软区分的目的。
1.2 Attention Mechanism原理
要介绍Attention Mechanism结构和原理,首先需要介绍下Seq2Seq模型的结构。基于RNN的Seq2Seq模型主要由两篇论文介绍,只是采用了不同的RNN模型。Ilya Sutskever等人与2014年在论文《Sequence to Sequence Learning with Neural Networks》中使用LSTM来搭建Seq2Seq模型。随后,2015年,Kyunghyun Cho等人在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》提出了基于GRU的Seq2Seq模型。两篇文章所提出的Seq2Seq模型,想要解决的主要问题是,如何把机器翻译中,变长的输入X映射到一个变长输出Y的问题,其主要结构如图3所示。
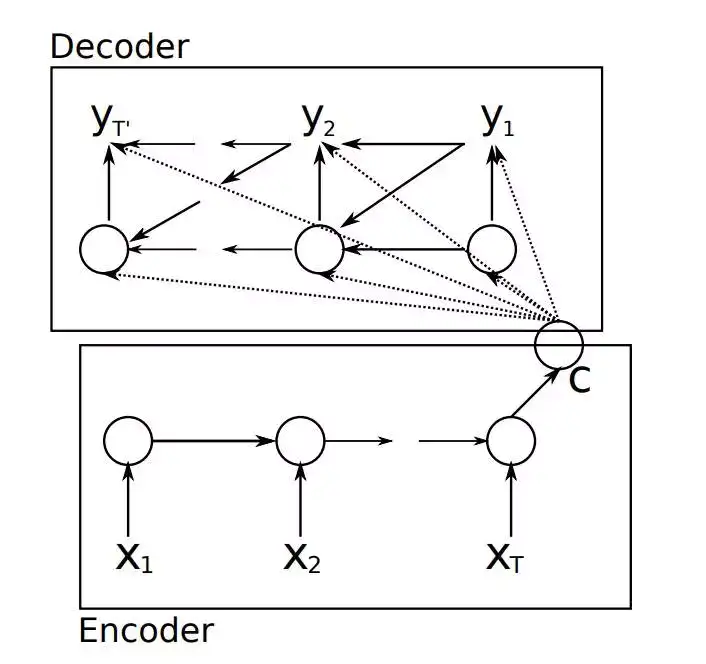
图3 传统的Seq2Seq结构
其中,Encoder把一个变成的输入序列x1,x2,x3....xt编码成一个固定长度隐向量(背景向量,或上下文向量context)c,c有两个作用:1、做为初始向量初始化Decoder的模型,做为decoder模型预测y1的初始向量。2、做为背景向量,指导y序列中每一个step的y的产出。Decoder主要基于背景向量c和上一步的输出yt-1解码得到该时刻t的输出yt,直到碰到结束标志(<EOS>)为止。
如上文所述,传统的Seq2Seq模型对输入序列X缺乏区分度,因此,2015年,Kyunghyun Cho等人在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中,引入了Attention Mechanism来解决这个问题,他们提出的模型结构如图4所示。
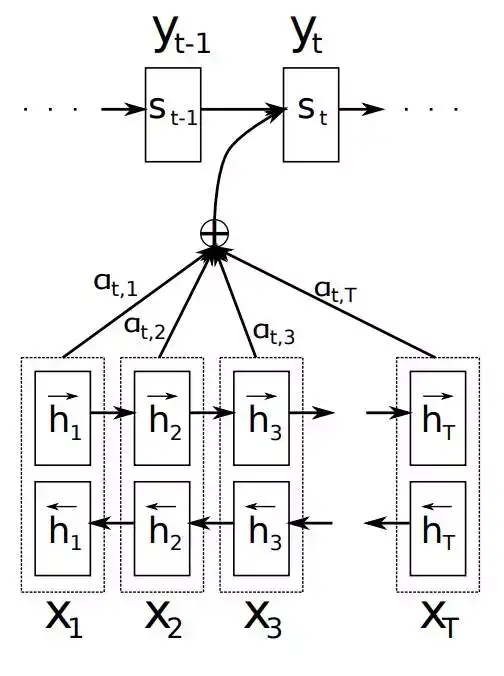
图4 Attention Mechanism模块图解
在该模型中,定义了一个条件概率:
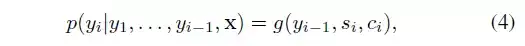
其中,si是decoder中RNN在在i时刻的隐状态,如图4中所示,其计算公式为:
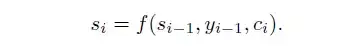
这里的背景向量ci的计算方式,与传统的Seq2Seq模型直接累加的计算方式不一样,这里的ci是一个权重化(Weighted)之后的值,其表达式如公式5所示:
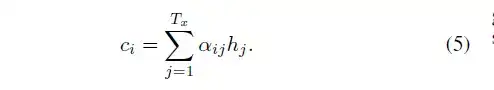
其中,i表示encoder端的第i个词,hj表示encoder端的第j和词的隐向量,aij表示encoder端的第j个词与decoder端的第i个词之间的权值,表示源端第j个词对目标端第i个词的影响程度,aij的计算公式如公式6所示:
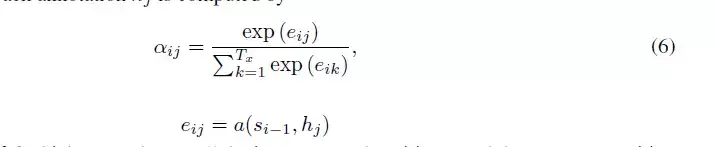
在公式6中,aij是一个softmax模型输出,概率值的和为1。eij表示一个对齐模型,用于衡量encoder端的位置j个词,对于decoder端的位置i个词的对齐程度(影响程度),换句话说:decoder端生成位置i的词时,有多少程度受encoder端的位置j的词影响。对齐模型eij的计算方式有很多种,不同的计算方式,代表不同的Attention模型,最简单且最常用的的对齐模型是dot product乘积矩阵,即把target端的输出隐状态ht与source端的输出隐状态进行矩阵乘。常见的对齐计算方式如下:
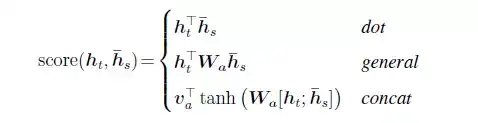
其中,Score(ht,hs) = aij表示源端与目标单单词对齐程度。可见,常见的对齐关系计算方式有,点乘(Dot product),权值网络映射(General)和concat映射几种方式。
https://zhuanlan.zhihu.com/p/31547842
https://blog.csdn.net/jteng/article/details/52864401
深度学习attention 机制了解的更多相关文章
- 深度学习之注意力机制(Attention Mechanism)和Seq2Seq
这篇文章整理有关注意力机制(Attention Mechanism )的知识,主要涉及以下几点内容: 1.注意力机制是为了解决什么问题而提出来的? 2.软性注意力机制的数学原理: 3.软性注意力机制. ...
- Attention机制在深度学习推荐算法中的应用(转载)
AFM:Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Ne ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- 深度学习之seq2seq模型以及Attention机制
RNN,LSTM,seq2seq等模型广泛用于自然语言处理以及回归预测,本期详解seq2seq模型以及attention机制的原理以及在回归预测方向的运用. 1. seq2seq模型介绍 seq2se ...
- 深度学习中的Attention机制
1.深度学习的seq2seq模型 从rnn结构说起 根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合.如下图, one to one 结构,仅仅只是简单的给一个输入 ...
- 深度学习之Attention Model(注意力模型)
1.Attention Model 概述 深度学习里的Attention model其实模拟的是人脑的注意力模型,举个例子来说,当我们观赏一幅画时,虽然我们可以看到整幅画的全貌,但是在我们深入仔细地观 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理.分类及应用 lqfarmer 深度学习研究员.欢迎扫描头像二维码,获取更多精彩内容. 946 人赞同了该文章 Atte ...
随机推荐
- LintCode: Unique Characters
C++, time: O(n^2) space: O(0) class Solution { public: /** * @param str: a string * @return: a boole ...
- JQuery 之 在数据加载完成后才自动执行函数
数据加载完成执行: $(window).load(function(){ ... }); 进入页就执行,不论等数据是否加载完成: $(document).ready(function(){ ... } ...
- Maven仓库下载jar包失败的处理方案
Maven仓库下载jar包失败的处理方案 在使用Maven项目的时候,有时候中央仓库并没有对应的包比如kaptcha-2.3.2.jar: 为了使我们的 项目能够正常运行下去,我们可以去别的地方下载对 ...
- jqGrid动态增加列,使用在根据条件筛选而出现不同的列的场景
function GetGrid2() { var jqdata = [ { Encode:"20180100", FullName: "BYD", SpecT ...
- selenium 定制启动 chrome 的选项
序 使用 selenium 时,我们可能需要对 chrome 做一些特殊的设置,以完成我们期望的浏览器行为,比如阻止图片加载,阻止JavaScript执行 等动作.这些需要 selenium的 Chr ...
- Win7 64bit下值得推荐的免费看图软件
自从更换到Win7 64bit后, 用了十多年的AcdSee3.x不能再正常工作了. 找到了两个替代品: Faststone Image Viewer 和 XnView Faststone Image ...
- Java微信分享接口开发
发布时间:2018-11-07 技术:springboot+maven 概述 微信JS-SDK实现自定义分享功能,分享给朋友,分享到朋友圈 详细 代码下载:http://www.demodas ...
- uitableview 和UISearchBar 下拉提示结合使用
自定cell的代码 餐厅的实体和餐厅对应控件的frame #import <Foundation/Foundation.h> @class RestaurantFrame; @interf ...
- java非web应用修改 properties/xml配置文件后,无需重启应用即可生效---自动加载
实现时主要使用Commons-Configuration.jar包,还需要commons-lang,disgestor,beanutils,collections等, package propFile ...
- iOS刻度尺换算之1mm等于多少像素理解
刚好看到一个刻度尺文章,实现手机屏幕上画刻度尺. 然后就有一个疑问:这个现实中的1mm(1毫米)长度与手机像素之间的换算比怎么来的呢? 看了下demo代码,发现这样写的: CGFloat sc_w = ...