吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd
# 导入第三方模块
from sklearn import svm
from sklearn import model_selection
from sklearn import metrics
# 读取外部数据
letters = pd.read_csv(r'F:\\python_Data_analysis_and_mining\\13\\letterdata.csv')
print(letters.shape)
# 数据前5行
print(letters.head())
# 将数据拆分为训练集和测试集
predictors = letters.columns[1:]
X_train,X_test,y_train,y_test = model_selection.train_test_split(letters[predictors], letters.letter, test_size = 0.25, random_state = 1234)
# 使用网格搜索法,选择线性可分SVM“类”中的最佳C值
C=[0.05,0.1,0.5,1,2,5]
parameters = {'C':C}
grid_linear_svc = model_selection.GridSearchCV(estimator = svm.LinearSVC(),param_grid =parameters,scoring='accuracy',cv=5,verbose =1)
# 模型在训练数据集上的拟合
grid_linear_svc.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_linear_svc.best_params_, grid_linear_svc.best_score_)
# 模型在测试集上的预测
pred_linear_svc = grid_linear_svc.predict(X_test)
# 模型的预测准确率
metrics.accuracy_score(y_test, pred_linear_svc)
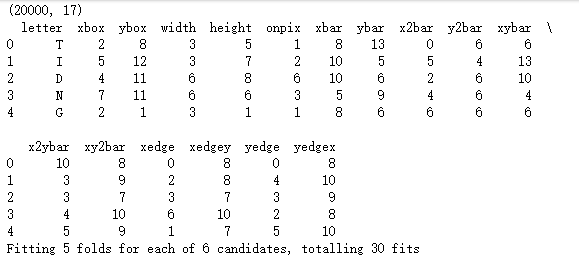
# 使用网格搜索法,选择非线性SVM“类”中的最佳C值
kernel=['rbf','linear','poly','sigmoid']
C=[0.1,0.5,1,2,5]
parameters = {'kernel':kernel,'C':C}
grid_svc = model_selection.GridSearchCV(estimator = svm.SVC(),param_grid =parameters,scoring='accuracy',cv=5,verbose =1)
# 模型在训练数据集上的拟合
grid_svc.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_svc.best_params_, grid_svc.best_score_)
# 模型在测试集上的预测
pred_svc = grid_svc.predict(X_test)
# 模型的预测准确率
metrics.accuracy_score(y_test,pred_svc)
# 读取外部数据
forestfires = pd.read_csv(r'F:\\python_Data_analysis_and_mining\\13\\forestfires.csv')
print(forestfires.shape)
# 数据前5行
print(forestfires.head())
# 删除day变量
forestfires.drop('day',axis = 1, inplace = True)
# 将月份作数值化处理
forestfires.month = pd.factorize(forestfires.month)[0]
# 预览数据前5行
print(forestfires.head())
# 导入第三方模块
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
# 绘制森林烧毁面积的直方图
sns.distplot(forestfires.area, bins = 50, kde = True, fit = norm, hist_kws = {'color':'steelblue'},
kde_kws = {'color':'red', 'label':'Kernel Density'},
fit_kws = {'color':'black','label':'Nomal', 'linestyle':'--'})
# 显示图例
plt.legend()
# 显示图形
plt.show()
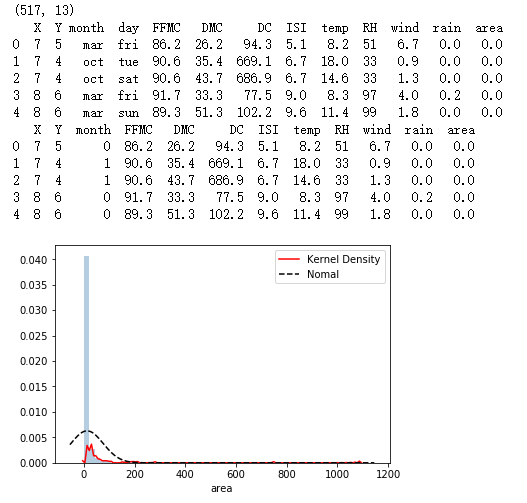
# 导入第三方模块
from sklearn import preprocessing
import numpy as np
from sklearn import neighbors
# 对area变量作对数变换
y = np.log1p(forestfires.area)
# 将X变量作标准化处理
predictors = forestfires.columns[:-1]
X = preprocessing.scale(forestfires[predictors])
print(X.shape)
print(X)
# 将数据拆分为训练集和测试集
X_train,X_test,y_train,y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234)
# 构建默认参数的SVM回归模型
svr = svm.SVR()
# 模型在训练数据集上的拟合
svr.fit(X_train,y_train)
# 模型在测试上的预测
pred_svr = svr.predict(X_test)
# 计算模型的MSE
a = metrics.mean_squared_error(y_test,pred_svr)
print(a)
# 使用网格搜索法,选择SVM回归中的最佳C值、epsilon值和gamma值
epsilon = np.arange(0.1,1.5,0.2)
C= np.arange(100,1000,200)
gamma = np.arange(0.001,0.01,0.002)
parameters = {'epsilon':epsilon,'C':C,'gamma':gamma}
grid_svr = model_selection.GridSearchCV(estimator = svm.SVR(),param_grid =parameters,
scoring='neg_mean_squared_error',cv=5,verbose =1, n_jobs=2)
# 模型在训练数据集上的拟合
grid_svr.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_svr.best_params_, grid_svr.best_score_)
# 模型在测试集上的预测
pred_grid_svr = grid_svr.predict(X_test)
# 计算模型在测试集上的MSE值
print(metrics.mean_squared_error(y_test,pred_grid_svr))
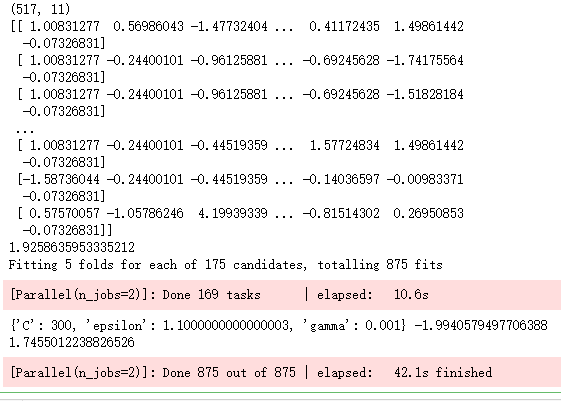
吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfr ...
- 吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包import pandas as pd # 导入数据Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\1 ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
- 吴裕雄 数据挖掘与分析案例实战(2)——python数据结构及方法、控制流、字符串处理、自定义函数
list1 = ['张三','男',33,'江苏','硕士','已婚',['身高178','体重72']]# 取出第一个元素print(list1[0])# 取出第四个元素print(list1[3] ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt # 自定义绘制ks曲线的函数def plot_ks(y_tes ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
随机推荐
- golang panic的捕获
panic发生时, 会导致进程挂掉.为了处理panic, 可以使用recover捕获,然后处理. 下面以下标引用越界问题为例进行说明. 正常情况下,代码中如果出现下标越界,会直接触发panic, 导致 ...
- webpack4构建react脚手架
create-react-app 脚手架还没有更新到webpack4,但是猛然间发现webpack4已经到 v4.12.0 版本了!!!慌得不行,正好端午有空所以研究了一波,自己搭建了一个简单的rea ...
- bzoj2656 数列
Description 小白和小蓝在一起上数学课,下课后老师留了一道作业,求下面这个数列的通项公式: A[0]=0 A[1]=1 A[2n]=A[n] A[2n+1]=A[n]+A[n+1] 小白作为 ...
- web中显示中文名称的图片,可以这样配置filter
com.cy.filter.UrlFilter: package com.cy.filter; import java.io.IOException; import java.net.URLDecod ...
- python-并发测试用例
以前看了虫师的并发,然后觉得以后如果遇上领导要求一个模块里的并发怎么办,然后就想到了下面的方法: 代码: 在原有的基础下再往casedir数组加模块三里面细分的对象.(这里可以封装成函数调用,工作需要 ...
- [UE4]角色增加挂点、增加枪
人物骨骼增加Socket(骨骼) 增加手持武器预览: 角色蓝图增加组件“Skeletal Mesh”(好像这叫骨骼模型吧),并拖放至人物“Mesh”下面作为子组件. 选中刚建好的“SkeletalMe ...
- application/xml 和 text/xml的区别
application/xml and text/xml的区别 经常看到有关xml时提到"application/xml" 和 "text/xml"两种类型, ...
- 样本稳定指数PSI
信用评定等级划分之后需要对评级的划分做出评价,分析这样的评级划分结果是否具有实用价值,即分析样本分布的稳定程度.样本分布稳定,则信用评定等级划分结果的实用价值就高.采用样本稳定指数( PSI )检验样 ...
- css border
CSS border用于设置HTML元素(如div)的边框,包括边框的宽度.颜色和样式.本文章向码农介绍CSS border边框属性详细内容,感兴趣的码农可以参考一下. CSS 边框即CSS bord ...
- mysql更新(五) 完整性约束 外键的变种 三种关系 数据的增删改
11-数据的增删改 本节重点: 插入数据 INSERT 更新数据 UPDATE 删除数据 DELETE 再来回顾一下之前我们练过的一些操作,相信大家都对插入数据.更新数据.删除数据有了全面的认识. ...