5.4.1 sequenceFile读写文件、记录边界、同步点、压缩排序、格式
5.4.1 sequenceFile读写文件、记录边界、同步点、压缩排序、格式
HDFS和MapReduce是针对大文件优化的存储文本记录,不适合二进制类型的数据。SequenceFile作为小文件的容器,SequenceFile类型将小文件包装起来,可以获得更高效率的存储和处理。sequenceFile类非常适合日志形式的存储方式,将日志记录按照【key,value】(key对应行号,valuse内容,key和value不一定需要writable类型,可以任意可序列化的类型)对格式存储,sequenceFile可以高效存储小文件。
(1)写入数据到文件
通过createWriter创建写入对象writer,通过writer的append函数追加到文件末尾,写完后调用close关闭。
public class SequenceFileWriteDemo {
private static final String[] DATA = { "One, two, buckle my shoe",
"Three, four, shut the door", "Five, six, pick up sticks",
"Seven, eight, lay them straight", "Nine, ten, a big fat hen" };
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
//根据文件系统,配置,路径,键值的类名创建writer
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key,
value);
//append追加数据
writer.append(key, value);
}
} finally {
//关闭数据流
IOUtils.closeStream(writer);
}
}
}
(2)从文件读取数据
通过SequenceFile.Reader reader =SequenceFile.Reader(fs, path, conf);函数返回reader对象,然后通过reader.next(key,value)去遍历获取数据,末尾返回false;
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable) ReflectionUtils.newInstance(
reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(
reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key,
value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
(3)其他序列化框架调用方法
对于其他非Writable类型的序列化框架(比如Apache Thrift),则应该使用下面两个方法:
public Object next(Object key) throws IOException
public Object getCurrentValue(Object val) throws IIOException
在这种情况下,需要确保io.serializations属性已经设置了你想使用的序列化框架。如果next()方法返回的是非null对象,则可以从数据流中读取键、值对,并且可以通过getCurrentValue()方法读取该值。否则,如果next()返回null值,则表示已经读到文件末尾。
(4)记录边界和同步点
记录边界:是每条记录和前后记录交界的地方,是一记录开始或结束的地方。使用reader.next()获取记录时需要从记录边界开始读取,否则会出现IOException。
同步点:同步点是由SequenceFile.Writer记录的,在顺序文件写入过程中插入一个特殊项以便每隔几个记录便有一个同步标识。同步点会占用很小的存储空间。同步点是为了方便读取数据而设立的,读取数据时,由于搜索而跑到任意位置,非记录边界读取会引起异常,这时就需要通过同步点找下一个记录边界。
通过同步点查找记录边界。SequenceFile.Reader记录sync(long position)方法可以将读取位置定位到position之后的下一个同步点。如果position之后没有同步了,那么当前读取位置将指向文件末尾。这样,我们对数据流中的任意位置调用sync()方法(不一定是一个记录的边界)而且可以重新定位到下一个同步点并继续向后读取:
reader.sync(360);
assertThat(reader.getPosition(), is(2021L));
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(59));
SequenceFile.Writer对象有一个Sync()方法,该方法可以在数据流的当前位置插入一个同步点。
另外一种搜索记录边界的方法是调用seek(int position)方法,但是只能知道提前知道记录边界的指定位置。该方法将读指针指向文件中指定的position位置。例如,可以按如下方式搜查记录边界:
reader.seek(359);
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(95));
但如果给定位置不是记录边界,调用next()方法时就会出错:
reader.seek(360);
reader.next(key, value); // fails with IOException
(5)查看序列化文件
可以用hadoop fs –text number.seq | head查看文件的文本。可以识别gzip压缩文件,顺序文件和Avro数据文件。
(6)输出排序后的sequenceFile文件
Hadoop执行mapreduce任务时,指定sort -r进行排序,inFormat指定指定输入文件类型,outFormat指定输出文件类型,outKey指定输出键类型,outValue指定输出值类型,最后加上出入文件和输出文件路径,执行完任务后,在输出文件夹sorted中有生成的输出文件,是排好序的。
(7)sequenceFile文件格式
SequenceFile文件内容由文件头hearder(SEQ、版本、键和值类的名称、数据压缩细节、用户定义的元数据),记录,同步标识组成。
记录的内部结构取决于是否启用压缩。压缩方式有记录压缩和数据块压缩。记录压缩是单挑记录值进行压缩,数据块压缩是一次性对多条记录压缩,可以不断向数据块中压缩记录,直到块的字节数不小于io.seqfile.compress.blocksize属性中设置的字节数:默认为1MB。每一个新块的开始处都需要插入同步标识。
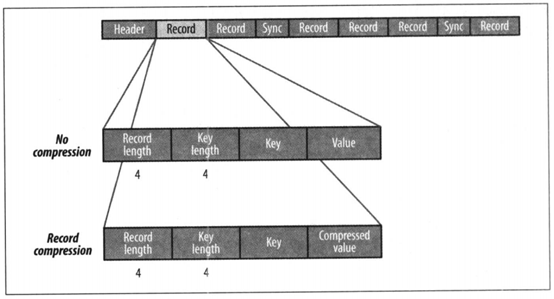
记录压缩
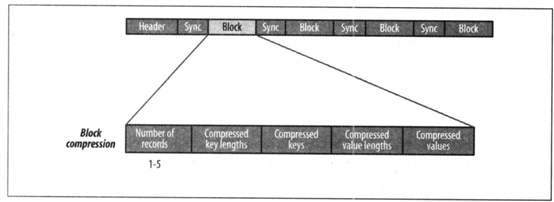
数据块压缩
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
5.4.1 sequenceFile读写文件、记录边界、同步点、压缩排序、格式的更多相关文章
- Inno Setup 如何读写文件
软件安装的实质就是拷贝,对于简单的打包当然不需要考虑修改某(配置)文件.通过inno修改文件的目的在于把安装时相关信息写入文件中,提供其它应用的读取,而这些信息也只能在安装时才能确定,比如安装用户选择 ...
- 计算机程序的思维逻辑 (60) - 随机读写文件及其应用 - 实现一个简单的KV数据库
57节介绍了字节流, 58节介绍了字符流,它们都是以流的方式读写文件,流的方式有几个限制: 要么读,要么写,不能同时读和写 不能随机读写,只能从头读到尾,且不能重复读,虽然通过缓冲可以实现部分重读,但 ...
- php中并发读写文件冲突的解决方案
在这里提供4种高并发读写文件的方案,各有优点,可以根据自己的情况解决php并发读写文件冲突的问题. 对于日IP不高或者说并发数不是很大的应用,一般不用考虑这些!用一般的文件操作方法完全没有问题.但如果 ...
- C#常用IO流与读写文件
.文件系统 ()文件系统类的介绍 文件操作类大都在System.IO命名空间里.FileSystemInfo类是任何文件系统类的基类:FileInfo与File表示文件系统中的文件:Directory ...
- php中并发读写文件冲突的解决方案(文件锁应用示例)
PHP(外文名: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言.语法吸收了C语言.Java和Perl的特点,入门门槛较低,易于学习,使用广泛,主要适 ...
- 你好,C++(5)如何输出数据到屏幕、从屏幕输入数据与读写文件?
2.2 基本输入/输出流 听过HelloWorld.exe的自我介绍之后,大家已经知道了一个C++程序的任务就是描述数据和处理数据.这两大任务的对象都是数据,可现在的问题是,数据不可能无中生有地产生 ...
- Linux一个简单的读写文件
(1)linux中的文件描述符fd的合法范围是或者一个正正数,不可能是一个负数. (2)open返回的fd程序必须记录好,以后向这个文件的所有操作都要靠这个fd去对应这个文件,最后关闭文件时也需要fd ...
- Qt的Model/View Framework解析(数据是从真正的“肉(raw)”里取得,Model提供肉,所以读写文件、操作数据库、网络通讯等一系列与数据打交道的工作就在model中做了)
最近在看Qt的Model/View Framework,在网上搜了搜,好像中文的除了几篇翻译没有什么有价值的文章.E文的除了Qt的官方介绍,其它文章也很少.看到一个老外在blog中写道Model/Vi ...
- Verilog读写文件
在通过编写Verilog代码实现ram功能时,需要自己先计算寄存器的位数和深度再编写代码. 而如果需要在编写的ram中预置值的话,就需要使用Verilog语言编写程序读写文件,来将相应的数据赋给寄存器 ...
随机推荐
- Android蓝牙遥控器APP关键代码 guihub项目
package com.car.demo; import java.io.IOException; import java.io.OutputStream; import java.util.UUID ...
- 从零开始搭建自己的.NET Core Api框架-1目录
https://www.cnblogs.com/RayWang/p/9216820.html 系列目录 一. 创建项目并集成swagger 1.1 创建 1.2 完善 二. 搭建项目整体架构 三. ...
- eclipse复制工作空间配置步骤
多个workspace,把每个workspace的设置共享,省去每次都重新配置一次. 总结一下,复制工作空间配置步骤如下: [最好是在新的workspace创建项目之前操作] 1 使用eclipse新 ...
- 关于linux中关在共享文件的NFS 提示错误解决办法
0. 查看挂载情况命令 : findmnt 1. 如果在客户机上遇到如下这样的提示错误,有可能的原因是因为没有安装nfs-utils 只需要yum install nfs-utils 就解决了 ...
- 二、eureka服务端注册服务
所有文章 https://www.cnblogs.com/lay2017/p/11908715.html 正文 入口 上文我们说到,eureka是使用jersey来对外提供restful风格的rpc调 ...
- Async await 解析
Async 定义:使异步函数以同步函数的形式书写(Generator函数语法糖) 原理:将Generator函数和自动执行器spawn包装在一个函数里 形式:将Generator函数的*替换成asyn ...
- 与app交互因异步造成的坑记录
一.问题产生背景: 在app内跳转到H5页面,初始页面获取用户等各种信息,前端除了可以获取链接上的参数去请求接口,接着进行数据的缓存等,也可以去获取app写入window的数据,然后进行其他的操作.公 ...
- 图像处理库GPUImage简单使用
一.介绍 GPUImage是一个基于OpenGL ES 2.0的开源的图像处理库,作者是Brad Larson.GPUImage将OpenGL ES封装为简洁的Objective-C或Swift接口, ...
- 【Distributed】网站跨域解决方案
一.概述 1.1 什么是网站跨域 1.2 网站跨域报错案例 二.五种网站跨域解决方案 三.使用JSONP解决网站跨域[1] 3.1 前端代码 3.2 后端代码 四.使用设置响应头允许跨域[2] 4.1 ...
- 《浏览器工作原理与实践》 <12>栈空间和堆空间:数据是如何存储的?
对于前端开发者来说,JavaScript 的内存机制是一个不被经常提及的概念 ,因此很容易被忽视.特别是一些非计算机专业的同学,对内存机制可能没有非常清晰的认识,甚至有些同学根本就不知道 JavaSc ...