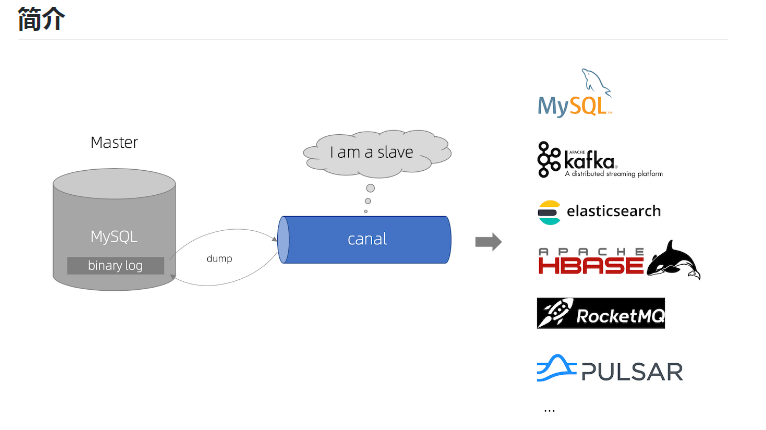
Canal——增量同步MySQL数据到ElasticSearch
1.准备
1.1.组件
JDK:1.8版本及以上;
ElasticSearch:6.x版本,目前貌似不支持7.x版本;
Kibana:6.x版本;
Canal.deployer:1.1.4
Canal.Adapter:1.1.4
1.2.配置
- 需要先开启MySQL的 binlog 写入功能,配置 binlog-format 为 ROW 模式
找到my.cnf文件,我的目录是/etc/my.cnf,添加以下配置:
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id= # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复

然后重启mysql,用以下命令检查一下binlog是否正确启动:
mysql> show variables like 'log_bin%';
+---------------------------------+----------------------------------+
| Variable_name | Value |
+---------------------------------+----------------------------------+
| log_bin | ON |
| log_bin_basename | /data/mysql/data/mysql-bin |
| log_bin_index | /data/mysql/data/mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
+---------------------------------+----------------------------------+
rows in set (0.00 sec)
mysql> show variables like 'binlog_format%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
row in set (0.00 sec)
- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'Aa123456.';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
2.安装
2.1.ElasticSearch
安装配置方法:https://www.cnblogs.com/caoweixiong/p/11826295.html
2.2.canal.deployer
2.2.1.下载解压
直接下载 访问:https://github.com/alibaba/canal/releases ,会列出所有历史的发布版本包 下载方式,比如以1.1.4版本为例子:
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gz 自己编译
git clone git@github.com:alibaba/canal.git
cd canal;
mvn clean install -Dmaven.test.skip -Denv=release
编译完成后,会在根目录下产生target/canal.deployer-$version.tar.gz
mkdir /usr/local/canal
tar zxvf canal.deployer-1.1..tar.gz -C /usr/local/canal
解压完成后,进入 /usr/local/canal目录,可以看到如下结构:
2.2.2.配置
- 配置server
cd /usr/local/canal/conf
vi canal.properties
标红的需要我们重点关注的,也是平常修改最多的参数:
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip = #运行canal-server服务的主机IP,可以不用配置,他会自动绑定一个本机的IP
canal.port = 11111 #canal-server监听的端口(TCP模式下,非TCP模式不监听1111端口)
canal.metrics.pull.port = 11112 #canal-server metrics.pull监听的端口
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 # canal admin config
#canal.admin.manager = 127.0.0.1:
canal.admin.port =
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 canal.zkServers = #集群模式下要配置zookeeper进行协调配置,单机模式可以不用配置
# flush data to zk
canal.zookeeper.flush.period =
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = tcp #canal-server运行的模式,TCP模式就是直连客户端,不经过中间件。kafka和mq是消息队列的模式
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir} #存放数据的路径
canal.file.flush.period =
## memory store RingBuffer size, should be Math.pow(,n)
canal.instance.memory.buffer.size =
## memory store RingBuffer used memory unit size , default 1kb #下面是一些系统参数的配置,包括内存、网络等
canal.instance.memory.buffer.memunit =
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true ## detecing config #这里是心跳检查的配置,做HA时会用到
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select
canal.instance.detecting.interval.time =
canal.instance.detecting.retry.threshold =
canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size =
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = # network config
canal.instance.network.receiveBufferSize =
canal.instance.network.sendBufferSize =
canal.instance.network.soTimeout = # binlog filter config #binlog过滤的配置,指定过滤那些SQL
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false # binlog format/image check #binlog格式检测,使用ROW模式,非ROW模式也不会报错,但是同步不到数据
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation
canal.instance.get.ddl.isolation = false # parallel parser config
canal.instance.parser.parallel = true #并行解析配置,如果是单个CPU就把下面这个true改为false
## concurrent thread number, default % available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize =
## disruptor ringbuffer size, must be power of
canal.instance.parser.parallelBufferSize = # table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default hour
canal.instance.tsdb.snapshot.interval =
# purge snapshot expire , default hour( days)
canal.instance.tsdb.snapshot.expire = # aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey = #################################################
######### destinations #############
#################################################
canal.destinations = example #canal-server创建的实例,在这里指定你要创建的实例的名字,比如test1,test2等,逗号隔开
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml ##################################################
######### MQ #############
##################################################
canal.mq.servers = 127.0.0.1:
canal.mq.retries =
canal.mq.batchSize =
canal.mq.maxRequestSize =
canal.mq.lingerMs =
canal.mq.bufferMemory =
canal.mq.canalBatchSize =
canal.mq.canalGetTimeout =
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace = ##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"
- 配置example
在根配置文件中创建了实例名称之后,需要在根配置的同级目录下创建该实例目录,canal-server为我们提供了一个示例的实例配置,因此我们可以直接复制该示例,举个例子吧:根配置配置了如下实例:
[root@aliyun conf]# vim canal.properties
...
canal.destinations = user_order,delivery_info
... 我们需要在根配置的同级目录下创建这两个实例
[root@aliyun conf]# pwd
/usr/local/canal-server/conf
[root@aliyun conf]# cp -a example/ user_order
[root@aliyun conf]# cp -a example/ delivery_info
这里只举例1个example的配置:
vi /usr/local/canal/conf/example/instance.properties
标红的需要我们重点关注的,也是平常修改最多的参数:
###################################################
mysql serverId , v1.0.26+ will autoGencanal.instance.mysql.slaveId=11
# enable gtid use true/false
canal.instance.gtidon=false # position info
canal.instance.master.address=172.16.10.26:3306 #指定要读取binlog的MySQL的IP地址和端口
canal.instance.master.journal.name= #从指定的binlog文件开始读取数据
canal.instance.master.position= #指定偏移量,做过主从复制的应该都理解这两个参数。
#tips:binlog和偏移量也可以不指定,则canal-server会从当前的位置开始读取。我建议不设置
canal.instance.master.timestamp=
canal.instance.master.gtid= # rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId= # table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#这几个参数是设置高可用配置的,可以配置mysql从库的信息
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid= # username/password
canal.instance.dbUsername=canal #指定连接mysql的用户密码
canal.instance.dbPassword=Aa123456.
canal.instance.connectionCharset = UTF-8 #字符集
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex
#canal.instance.filter.regex=.*\\..*
canal.instance.filter.regex=risk.canal,risk.cwx #这个是比较重要的参数,匹配库表白名单,比如我只要test库的user表的增量数据,则这样写 test.user
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=
# hash partition config
#canal.mq.partitionsNum=
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
2.2.3.启动
bin/startup.sh
- 查看 server 日志
vi logs/canal/canal.log
-- ::27.967 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## start the canal server.
-- ::28.113 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[10.1.29.120:]
-- ::28.210 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## the canal server is running now ......
- 查看 instance 的日志
vi logs/example/example.log
-- ::45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
-- ::45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
-- ::45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for -example
-- ::45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful....
- 关闭
bin/stop.sh
2.3.canal.adapter
2.3.1.下载解压
访问:https://github.com/alibaba/canal/releases ,会列出所有历史的发布版本包 下载方式,比如以1.1.4版本为例子:
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.adapter-1.1.4.tar.gz
mkdir /usr/local/canal-adapter
tar zxvf canal.adapter-1.1..tar.gz -C /usr/local/canal-adapter
2.3.2.配置
- adapter配置
cd /usr/local/canal-adapter
vim conf/application.yml
标红的需要我们重点关注的,也是平常修改最多的参数:
server:
port:
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+
default-property-inclusion: non_null canal.conf:
mode: tcp #模式
canalServerHost: 127.0.0.1:11111 #指定canal-server的地址和端口
# zookeeperHosts: slave1:
# mqServers: 127.0.0.1: #or rocketmq
# flatMessage: true
batchSize:
syncBatchSize:
retries:
timeout:
accessKey:
secretKey:
srcDataSources: #数据源配置,从哪里获取数据
defaultDS: #指定一个名字,在ES的配置中会用到,唯一
url: jdbc:mysql://172.16.10.26:3306/risk?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name #指定在canal-server配置的实例
groups:
- groupId: g1 #默认就好,组标识
outerAdapters:
- name: logger
# - name: rdb
# key: mysql1
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password:
# - name: rdb
# key: oracle1
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost::XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password:
# threads:
# commitSize:
# - name: hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort:
# zookeeper.znode.parent: /hbase
- name: es #输出到哪里,指定es
hosts: 172.16.99.2:40265 #指定es的地址,注意端口为es的传输端口9300
properties:
# mode: transport # or rest
# security.auth: test: # only used for rest mode
cluster.name: log-es-cluster #指定es的集群名称
- es配置
[root@aliyun es]# pwd
/usr/local/canal-adapter/conf/es
[root@aliyun es]# ll
total
-rwxrwxrwx root root Apr : biz_order.yml #这三个配置文件是自带的,可以删除,不过最好不要删除,因为可以参考他的格式
-rwxrwxrwx root root Apr : customer.yml
-rwxrwxrwx root root Apr : mytest_user.yml
创建canal.yml文件:
cp customer.yml canal.yml
vim conf/es/canal.yml
标红的需要我们重点关注的,也是平常修改最多的参数:
dataSourceKey: defaultDS #指定数据源,这个值和adapter的application.yml文件中配置的srcDataSources值对应。
destination: example #指定canal-server中配置的某个实例的名字,注意:我们可能配置多个实例,你要清楚的知道每个实例收集的是那些数据,不要瞎搞。
groupId: g1 #组ID,默认就好
esMapping: #ES的mapping(映射)
_index: canal #要同步到的ES的索引名称(自定义),需要自己在ES上创建哦!
_type: _doc #ES索引的类型名称(自定义)
_id: _id #ES标示文档的唯一标示,通常对应数据表中的主键ID字段,注意我这里写成的是"_id",有个下划线哦!
#pk: id #如果不需要_id, 则需要指定一个属性为主键属性
sql: "select t.id as _id, t.name, t.sex, t.age, t.amount, t.email, t.occur_time from canal t" #这里就是数据表中的每个字段到ES索引中叫什么名字的sql映射,注意映射到es中的每个字段都要是唯一的,不能重复。
#etlCondition: "where t.occur_time>='{0}'"
commitBatch: 3000
sql映射文件写完之后,要去ES上面创建对应的索引和映射,映射要求要和sql文件的映射保持一致,即sql映射中有的字段在ES的索引映射中必须要有,否则同步会报字段错误,导致失败。
2.3.3.创建mysql表和es索引
CREATE TABLE `canal` (
id int() NOT NULL AUTO_INCREMENT,
name varchar() NULL COMMENT '名称',
sex varchar() NULL COMMENT '性别',
age int NULL COMMENT '年龄',
amount decimal(,) NULL COMMENT '资产',
email varchar() NULL COMMENT '邮箱',
occur_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT= DEFAULT CHARSET=utf8;
{
"mappings": {
"_doc": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"sex": {
"type": "text"
},
"age": {
"type": "long"
},
"amount": {
"type": "text"
},
"email": {
"type": "text"
},
"occur_time": {
"type": "date"
}
}
}
}
}
2.3.4.启动
cd /usr/local/canal-adapter
./bin/startup.sh
查看日志:
cat logs/adapter/adapter.log
2.4.Kibana
安装配置方法:https://www.cnblogs.com/caoweixiong/p/11826655.html
3.验证
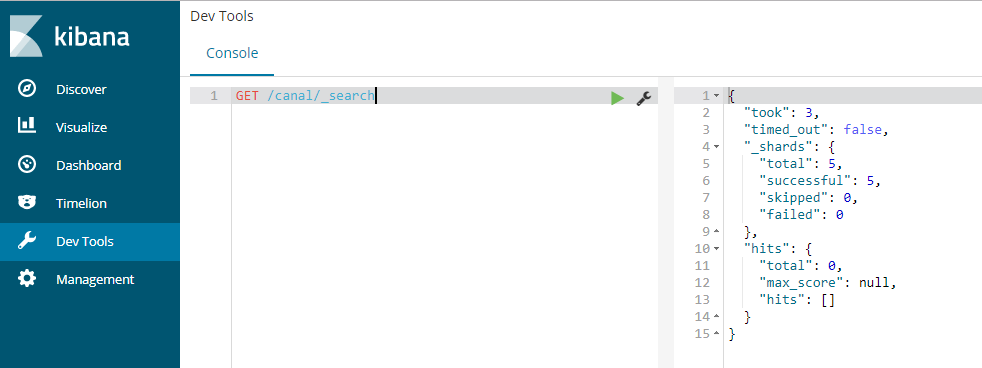
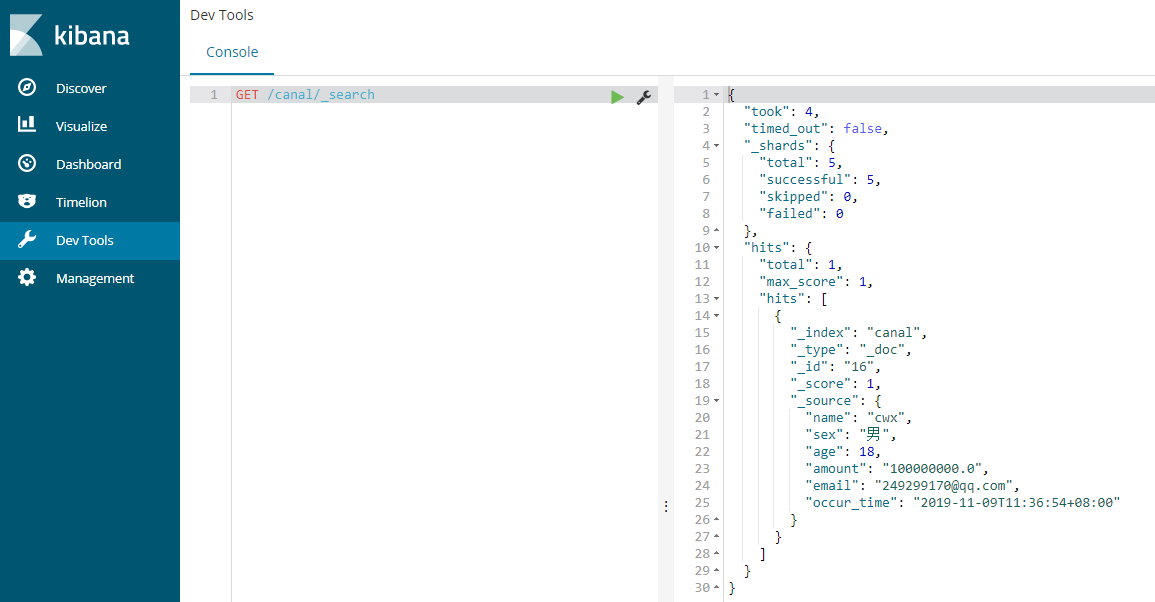
- 没有数据时:
- 插入1条数据:
insert into canal(id,name,sex,age,amount,email,occur_time) values(null,'cwx','男',,,'249299170@qq.com',now());

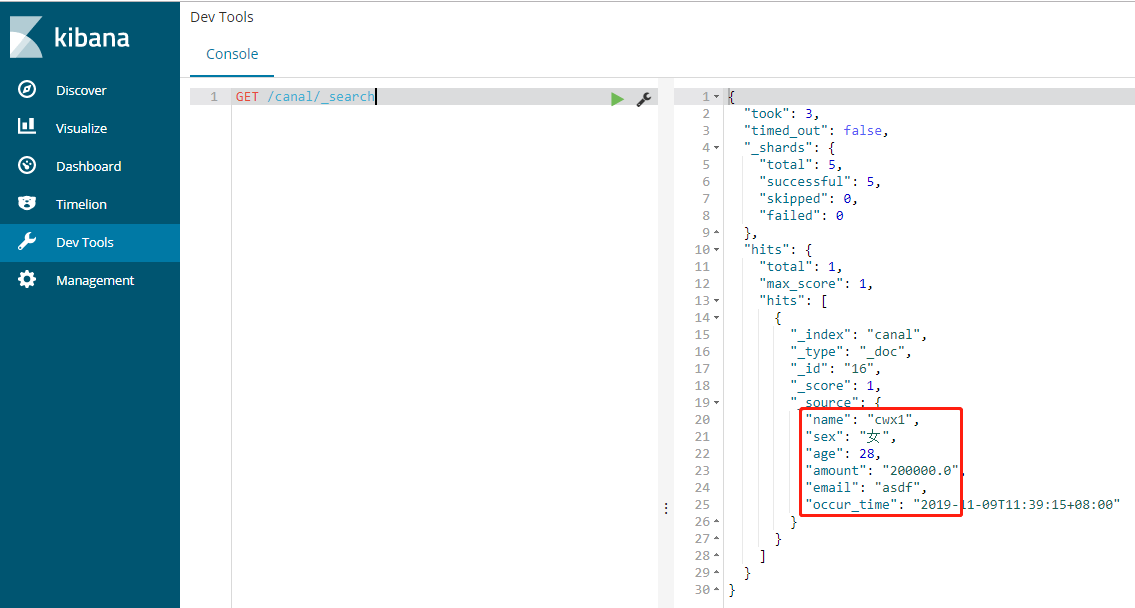
- 更新1条数据:
update canal set name='cwx1',sex='女',age=,amount=,email='asdf',occur_time=now() where id=;

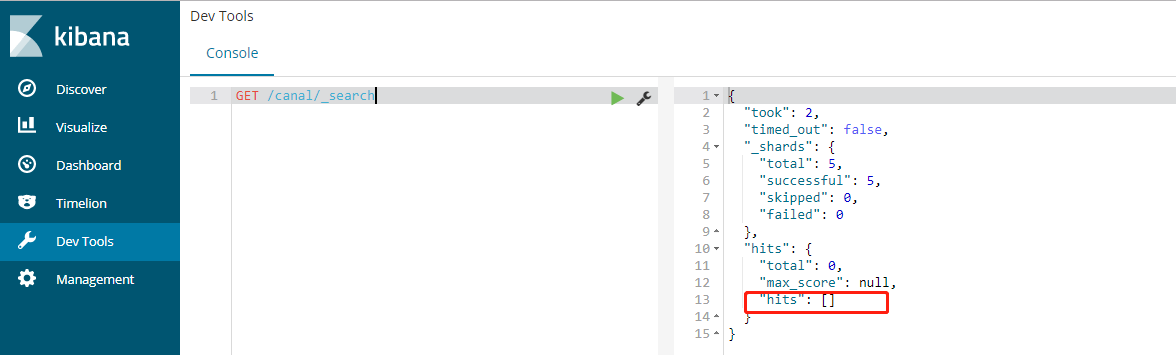
- 删除1条数据:
delete from canal where id=;

4.总结
4.1.全量更新不能实现,但是增删改都是可以的;
4.2.一定要提前创建好es索引;
4.3.es配置的是tcp端口,比如默认的9300;
4.4.目前es貌似支持6.x版本,不支持7.x版本;
Canal——增量同步MySQL数据到ElasticSearch的更多相关文章
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- 实战ELK(6)使用logstash同步mysql数据到ElasticSearch
一.准备 1.mysql 我这里准备了个数据库mysqlEs,表User 结构如下 添加几条记录 2.创建elasticsearch索引 curl -XPUT 'localhost:9200/user ...
- 同步mysql数据到ElasticSearch的最佳实践
Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据.ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全 ...
- Elasticsearch--Logstash定时同步MySQL数据到Elasticsearch
新地址体验:http://www.zhouhong.icu/post/139 一.Logstash介绍 Logstash是elastic技术栈中的一个技术.它是一个数据采集引擎,可以从数据库采集数据到 ...
- 【记录】ELK之logstash同步mysql数据到Elasticsearch ,配置文件详解
本文出处:https://my.oschina.net/xiaowangqiongyou/blog/1812708#comments 截取部分内容以便学习 input { jdbc { # mysql ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- 10.Solr4.10.3数据导入(DIH全量增量同步Mysql数据)
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.创建MySQL数据 create database solr; use solr; DROP TABLE ...
随机推荐
- RxJava事件流变换者--操作符
对于Rxjava来说,操作符是它的一个非常重要的概念,如官网: 而上节上也贴了一下都有哪些操作符,其实还不少,所以有必要仔细学习一下关于操作符这块的东东,那操作符在Rxjava中扮演着什么样的角色呢, ...
- 自定义ViewGroup基础巩固2---onMeasure()学习及综合实现圆形菜单
上次对自定义ViewGroup中的onLayout()方法进行了基础巩固[http://www.cnblogs.com/webor2006/p/7507284.html],对于熟知自定义ViewGro ...
- git的安装和简单使用
目前windows版本的git有几种实现,但我们选择msysgit发行版,这是目前做得兼容性最好的. 下载地址: http://code.google.com/p/msysgit/downloads/ ...
- [原创]在Windows平台使用msvc(cl.exe) + vscode编写和调试C/C++代码
1.在.vscode目录下,新建以下几个配置文件,当然也可以通过vscode命令自动生成,如果你已有这些文件直接修改即可. c_cpp_properties.json(代码提示): { "c ...
- JavaScript教程——数据类型概述
简介 JavaScript 语言的每一个值,都属于某一种数据类型.JavaScript 的数据类型,共有六种.(ES6 又新增了第七种 Symbol 类型的值,本教程不涉及.) 数值(number): ...
- hdu4786 Fibonacci Tree[最小生成树]【结论题】
一道结论题:如果最小生成树和最大生成树之间存在fib数,成立.不存在或者不连通则不成立.由于是01图,所以这个区间内的任何生成树都存在. 证明:数学归纳?如果一棵树没有办法再用非树边0边替代1边了,那 ...
- deferred shading , tile deferred, cluster forward 对tranparent支持问题的思考
cluster对 trans的支持我大概理解了 http://efficientshading.com/wp-content/uploads/tiled_shading_siggraph_2012.p ...
- URAL 2052 Physical Education(数位DP)
题目链接:https://vjudge.net/contest/254142#problem/G 参考题解:https://blog.csdn.net/zearot/article/details/4 ...
- [AngularJS] Decorator pattern for code reuse
Imaging you have a large application, inside this large application you have many small individual a ...
- 配置NFS共享
NFS(网络文件系统)-------> linux与linux平台 服务器端: 1.安装软件nfs-utils(服务:nfs-server) 2.创建共享目录:mkdir /nfs_dir 3. ...