Lucence简单学习---1
package cn.itheima.lucene; import java.io.File;
import java.util.ArrayList;
import java.util.List; import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; public class IndexManagerTest {
@Test
public void testIndexCreate() throws Exception{
//创建文档列表,保存多个Docuemnt
List<Document> docList = new ArrayList<Document>(); //指定文件所在目录
File dir = new File("E:\\01传智课程\\黑28期0523\\Lucene&Solr\\01.参考资料\\searchsource");
//循环文件夹取出文件
for(File file : dir.listFiles()){
//文件名称
String fileName = file.getName();
//文件内容
String fileContext = FileUtils.readFileToString(file);
//文件大小
Long fileSize = FileUtils.sizeOf(file); //文档对象,文件系统中的一个文件就是一个Docuemnt对象
Document doc = new Document(); //第一个参数:域名
//第二个参数:域值
//第三个参数:是否存储,是为yes,不存储为no
/*TextField nameFiled = new TextField("fileName", fileName, Store.YES);
TextField contextFiled = new TextField("fileContext", fileContext, Store.YES);
TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);*/ //是否分词:要,因为它要索引,并且它不是一个整体,分词有意义
//是否索引:要,因为要通过它来进行搜索
//是否存储:要,因为要直接在页面上显示
TextField nameFiled = new TextField("fileName", fileName, Store.YES); //是否分词: 要,因为要根据内容进行搜索,并且它分词有意义
//是否索引: 要,因为要根据它进行搜索
//是否存储: 可以要也可以不要,不存储搜索完内容就提取不出来
TextField contextFiled = new TextField("fileContext", fileContext, Store.NO); //是否分词: 要, 因为数字要对比,搜索文档的时候可以搜大小, lunene内部对数字进行了分词算法
//是否索引: 要, 因为要根据大小进行搜索
//是否存储: 要, 因为要显示文档大小
LongField sizeFiled = new LongField("fileSize", fileSize, Store.YES); //将所有的域都存入文档中
doc.add(nameFiled);
doc.add(contextFiled);
doc.add(sizeFiled); //将文档存入文档集合中
docList.add(doc);
} //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
Analyzer analyzer = new IKAnalyzer();
//指定索引和文档存储的目录
Directory directory = FSDirectory.open(new File("E:\\dic"));
//创建写对象的初始化对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//创建索引和文档写对象
IndexWriter indexWriter = new IndexWriter(directory, config); //将文档加入到索引和文档的写对象中
for(Document doc : docList){
indexWriter.addDocument(doc);
}
//提交
indexWriter.commit();
//关闭流
indexWriter.close();
} @Test
public void testIndexDel() throws Exception{
//创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
Analyzer analyzer = new IKAnalyzer();
//指定索引和文档存储的目录
Directory directory = FSDirectory.open(new File("E:\\dic"));
//创建写对象的初始化对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//创建索引和文档写对象
IndexWriter indexWriter = new IndexWriter(directory, config); //删除所有
//indexWriter.deleteAll(); //根据名称进行删除
//Term词元,就是一个词, 第一个参数:域名, 第二个参数:要删除含有此关键词的数据
indexWriter.deleteDocuments(new Term("fileName", "apache")); //提交
indexWriter.commit();
//关闭
indexWriter.close();
} /**
* 更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象
* 如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象
* @throws Exception
*/
@Test
public void testIndexUpdate() throws Exception{
//创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
Analyzer analyzer = new IKAnalyzer();
//指定索引和文档存储的目录
Directory directory = FSDirectory.open(new File("E:\\dic"));
//创建写对象的初始化对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//创建索引和文档写对象
IndexWriter indexWriter = new IndexWriter(directory, config); //根据文件名称进行更新
Term term = new Term("fileName", "web");
//更新的对象
Document doc = new Document();
doc.add(new TextField("fileName", "xxxxxx", Store.YES));
doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO));
doc.add(new LongField("fileSize", 100L, Store.YES)); //更新
indexWriter.updateDocument(term, doc); //提交
indexWriter.commit();
//关闭
indexWriter.close();
}
}
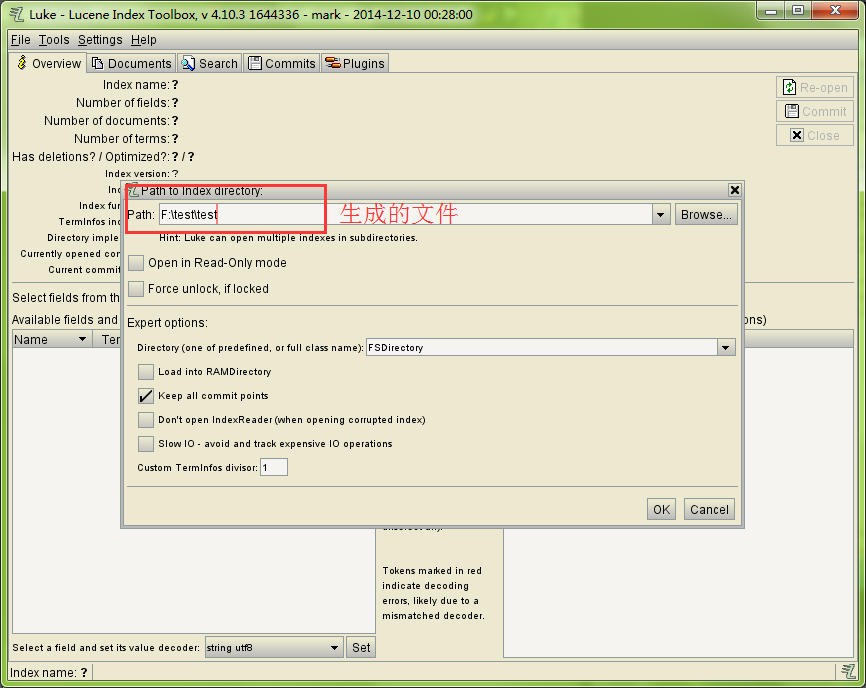
第一个test运行后会在指定目录生成文件。查看这些需要查看器
----------------------------------------------------------
package cn.itheima.lucene; import java.io.File; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; public class IndexSearchTest { @Test
public void testIndexSearch() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer();
//创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器
//默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索
QueryParser queryParser = new QueryParser("fileContext", analyzer);
//查询语法=域名:搜索的关键字
Query query = queryParser.parse("fileName:web"); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, );
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
} } @Test
public void testIndexTermQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //创建词元:就是词,
Term term = new Term("fileName", "apache");
//使用TermQuery查询,根据term对象进行查询
TermQuery termQuery = new TermQuery(term); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(termQuery, );
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} @Test
public void testNumericRangeQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //根据数字范围查询
//查询文件大小,大于100 小于1000的文章
//第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值
Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, );
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} @Test
public void testBooleanQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //布尔查询,就是可以根据多个条件组合进行查询
//文件名称包含apache的,并且文件大小大于等于100 小于等于1000字节的文章
BooleanQuery query = new BooleanQuery(); //根据数字范围查询
//查询文件大小,大于100 小于1000的文章
//第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值
Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //创建词元:就是词,
Term term = new Term("fileName", "apache");
//使用TermQuery查询,根据term对象进行查询
TermQuery termQuery = new TermQuery(term); //Occur是逻辑条件
//must相当于and关键字,是并且的意思
//should,相当于or关键字或者的意思
//must_not相当于not关键字, 非的意思
//注意:单独使用must_not 或者 独自使用must_not没有任何意义
query.add(termQuery, Occur.MUST);
query.add(numericQuery, Occur.MUST); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, );
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} @Test
public void testMathAllQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //查询所有文档
MatchAllDocsQuery query = new MatchAllDocsQuery(); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, );
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} @Test
public void testMultiFieldQueryParser() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); String [] fields = {"fileName","fileContext"};
//从文件名称和文件内容中查询,只有含有apache的就查出来
MultiFieldQueryParser multiQuery = new MultiFieldQueryParser(fields, analyzer);
//输入需要搜索的关键字
Query query = multiQuery.parse("apache"); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, );
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
}
}
-----------------------------------------------下面总结----------------------------------------------------
-------------------------------------------中文分词需要-------------------------------------------------
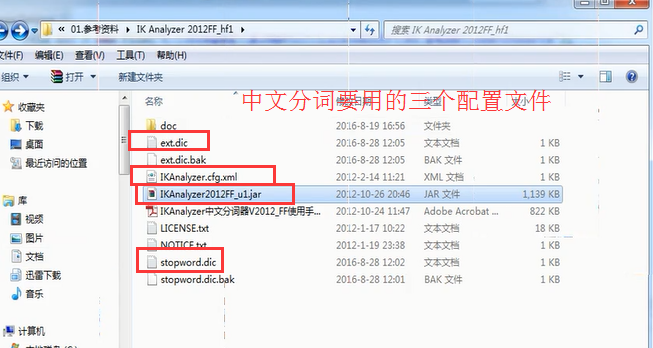

Lucence简单学习---1的更多相关文章
- Log4j简单学习笔记
log4j结构图: 结构图展现出了log4j的主结构.logger:表示记录器,即数据来源:appender:输出源,即输出方式(如:控制台.文件...)layout:输出布局 Logger机滤器:常 ...
- shiro简单学习的简单总结
权限和我有很大渊源. 培训时候的最后一个项目是OA,权限那块却不知如何入手,最后以不是我写的那个模块应付面试. 最开始的是使用session装载用户登录信息,使用简单权限拦截器做到权限控制,利用资源文 ...
- CentOS 简单学习 firewalld的使用
1. centos7 开始 使用firewalld 代替了 iptables 命令工具为 firewall-cmd 帮助信息非常长,简单放到文末 2. 简单使用 首先开启 httpd 一般都自带安装了 ...
- Windows 下 Docker 的简单学习使用过程之一 dockertoolbox
1. Windows 下面运行 Docker 的两个主要工具1): Docker for Windows2): DockerToolbox区别:Docker For Windows 可以理解为是新一代 ...
- 在MVC中实现和网站不同服务器的批量文件下载以及NPOI下载数据到Excel的简单学习
嘿嘿,我来啦,最近忙啦几天,使用MVC把应该实现的一些功能实现了,说起来做项目,实属感觉蛮好的,即可以学习新的东西,又可以增加自己之前知道的知识的巩固,不得不说是双丰收啊,其实这周来就开始面对下载在挣 ...
- Linux——帮助命令简单学习笔记
Linux帮助命令简单学习笔记: 一: 命令名称:man 命令英文原意:manual 命令所在路径:/usr/bin/man 执行权限:所有用户 语法:man [命令或配置文件] 功能描述:获得帮助信 ...
- OI数学 简单学习笔记
基本上只是整理了一下框架,具体的学习给出了个人认为比较好的博客的链接. PART1 数论部分 最大公约数 对于正整数x,y,最大的能同时整除它们的数称为最大公约数 常用的:\(lcm(x,y)=xy\ ...
- mongodb,redis简单学习
2.mongodb安装配置简单学习 配置好数据库路径就可以mongo命令执行交互操作了:先将服务器开起来:在开个cmd执行交互操作 ...
- html css的简单学习(三)
html css的简单学习(三) 前端开发工具:Dreamweaver.Hbuilder.WebStorm.Sublime.PhpStorm...=========================== ...
随机推荐
- java——jdbc调用存储过程
1,加载驱动: 2,获取连接 3,设置参数 4,执行: 5,释放连接 普通jdbc的执行过程: conn.prepareCall() 上面是一个调用存储过程的示例.
- 洛谷 P2765 魔术球问题 (dinic求最大流,最小边覆盖)
P2765 魔术球问题 题目描述 «问题描述: 假设有n根柱子,现要按下述规则在这n根柱子中依次放入编号为1,2,3,...的球. (1)每次只能在某根柱子的最上面放球. (2)在同一根柱子中,任何2 ...
- Java 类的重载/匿名类的使用/可变形参
/** *1.类的方法的重载 *2.匿名类对象的传递和引用 *3.可变个数的形参(格式:1/对于方法的形参: 数据类型...形参名 * 2/可变个数的形参与同名的方法之间构成重载 * 3/可变个数的形 ...
- 为什么说Redis是单线程的以及Redis为什么这么块
一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到什么是“二八定律”.什么是“热数据和冷数据”,复杂一点的会问到缓存雪崩.缓存穿透.缓存预热.缓存更新.缓存降级等问题,这些看似 ...
- Mybayis的项目使用的Mapping文件使用总结参考(一)
作者:longgangbai 以前用过ibatis2,但是听说ibatis3有较大的性能提升,而且设计也更合理,他不兼容ibatis2.尽管ibatis3还是beta10的状态,但还是打算直接使用ib ...
- mysql锁定单个表的方法
mysql锁定单个表的方法mysql>lock table userstat read;mysql>unlock tables; 本文来自ChinaUnix博客,如果查看原文请点:http ...
- 洛谷P1233 木棍加工【单调栈】
题目:https://www.luogu.org/problemnew/show/P1233 题意: 有n根木棍,每根木棍有长度和宽度. 现在要求按某种顺序加工木棍,如果前一根木棍的长度和宽度都大于现 ...
- 【AndroidStudio-添加RecyclerView包】 AndroidStudio添加v7包中的RecyclerView
关于AndroidStudio如何添加v7包中的RecyclerView? 左侧Project视图,在External Libraries下找到appcompat-v7包 右击appcompat-v7 ...
- 互联网上最可怕的搜索引擎:shodan
互联网上最可怕的搜索引擎:shodan 介绍:http://tech.qq.com/a/20130410/000013.htm
- 洛谷P3935 Calculation [数论分块]
题目传送门 格式难调,题面就不放了. 分析: 实际上这个就是这道题的升级版,没什么可讲的,数论分块搞就是了. Code: //It is made by HolseLee on 18th Jul 20 ...