关于LSTM的输入和训练过程的理解
1.训练的话一般一批一批训练,即让batch_size 个样本同时训练;
2.每个样本又包含从该样本往后的连续seq_len个样本(如seq_len=15),seq_len也就是LSTM中cell的个数;
3.每个样本又包含inpute_dim个维度的特征(如input_dim=7)
因此,输入层的输入数据通常先要reshape:
x= np.reshape(x, (batch_size , seq_len, input_dim))
(友情提示:每个cell共享参数!!!)
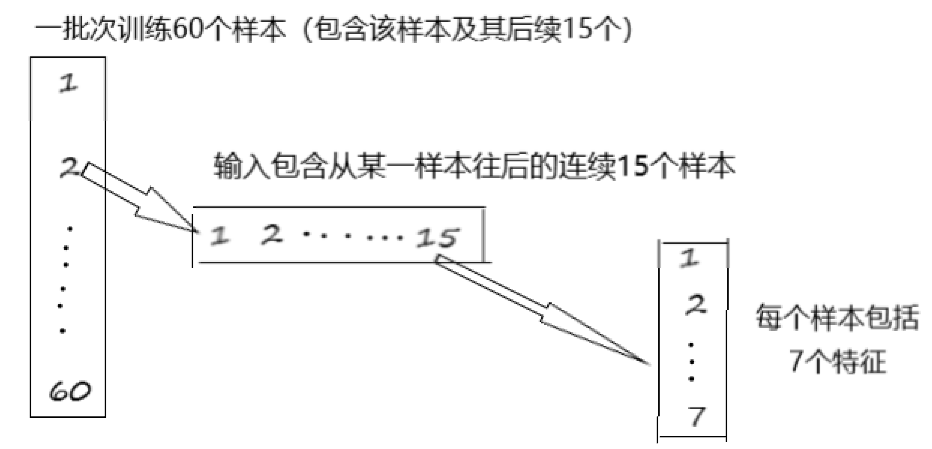
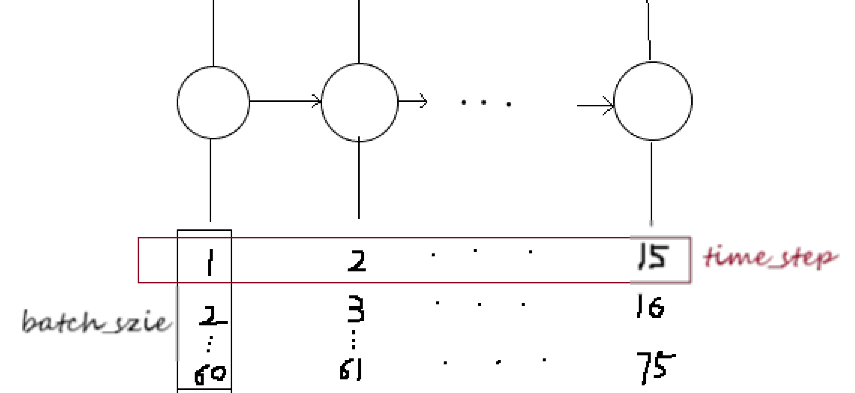
举个例子:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
#在这里做数据加载,还是使用那个MNIST的数据,以one_hot的方式加载数据,记得目录可以改成之前已经下载完成的目录
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True) '''
MNIST的数据是一个28*28的图像,这里RNN测试,把他看成一行行的序列(28维度(28长的sequence)*28行)
''' # RNN学习时使用的参数
learning_rate = 0.001
training_iters = 100000
batch_size = 128
display_step = 10 # 神经网络的参数
n_input = 28 # 输入层的n
n_steps = 28 # 28长度
n_hidden = 128 # 隐含层的特征数
n_classes = 10 # 输出的数量,因为是分类问题,0~9个数字,这里一共有10个 # 构建tensorflow的输入X的placeholder
x = tf.placeholder("float", [None, n_steps, n_input])
# tensorflow里的LSTM需要两倍于n_hidden的长度的状态,一个state和一个cell
# Tensorflow LSTM cell requires 2x n_hidden length (state & cell)
istate = tf.placeholder("float", [None, 2 * n_hidden])
# 输出Y
y = tf.placeholder("float", [None, n_classes]) # 随机初始化每一层的权值和偏置
weights = {
'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'hidden': tf.Variable(tf.random_normal([n_hidden])),
'out': tf.Variable(tf.random_normal([n_classes]))
} '''
构建RNN
'''
def RNN(_X, _istate, _weights, _biases):
# 规整输入的数据
_X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size _X = tf.reshape(_X, [-1, n_input]) # (n_steps*batch_size, n_input)
# 输入层到隐含层,第一次是直接运算
_X = tf.matmul(_X, _weights['hidden']) + _biases['hidden']
# 之后使用LSTM
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0)
# 28长度的sequence,所以是需要分解位28次
_X = tf.split(0, n_steps, _X) # n_steps * (batch_size, n_hidden)
# 开始跑RNN那部分
outputs, states = tf.nn.rnn(lstm_cell, _X, initial_state=_istate) # 输出层
return tf.matmul(outputs[-1], _weights['out']) + _biases['out'] pred = RNN(x, istate, weights, biases) # 定义损失和优化方法,其中算是为softmax交叉熵,优化方法为Adam
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # Softmax loss
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer # 进行模型的评估,argmax是取出取值最大的那一个的标签作为输出
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # 初始化
init = tf.initialize_all_variables() # 开始运行
with tf.Session() as sess:
sess.run(init)
step = 1
# 持续迭代
while step * batch_size < training_iters:
# 随机抽出这一次迭代训练时用的数据
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 对数据进行处理,使得其符合输入
batch_xs = batch_xs.reshape((batch_size, n_steps, n_input))
# 迭代
sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
# 在特定的迭代回合进行数据的输出
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys,
istate: np.zeros((batch_size, 2 * n_hidden))})
print "Iter " + str(step * batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + \
", Training Accuracy= " + "{:.5f}".format(acc)
step += 1
print "Optimization Finished!"
# 载入测试集进行测试
test_len = 256
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label,
istate: np.zeros((test_len, 2 * n_hidden))}
关于LSTM的输入和训练过程的理解的更多相关文章
- (原)torch的训练过程
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6221622.html 参考网址: http://ju.outofmemory.cn/entry/284 ...
- 深度残差网(deep residual networks)的训练过程
这里介绍一种深度残差网(deep residual networks)的训练过程: 1.通过下面的地址下载基于python的训练代码: https://github.com/dnlcrl/deep-r ...
- mxnet的训练过程——从python到C++
mxnet的训练过程--从python到C++ mxnet(github-mxnet)的python接口相当完善,我们可以完全不看C++的代码就能直接训练模型,如果我们要学习它的C++的代码,从pyt ...
- 09 使用Tensorboard查看训练过程
打开Python Shell,执行以下代码: import tensorflow as tf import numpy as np #输入数据 x_data = np.linspace(-1,1,30 ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- 如何打开tensorboard观测训练过程
TensorBoard是TensorFlow下的一个可视化的工具,能够帮助研究者们可视化训练大规模神经网络过程中出现的复杂且不好理解的运算,展示训练过程中绘制的图像.网络结构等. 最近本人在学习这方面 ...
- TensorFlow之tf.nn.dropout():防止模型训练过程中的过拟合问题
一:适用范围: tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层 二:原理: dropout就是在不同的训练过程中随机扔掉一部分神经元.也就是让 ...
- tensorflow笔记:模型的保存与训练过程可视化
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- 深度学习笔记之关于基本思想、浅层学习、Neural Network和训练过程(三)
不多说,直接上干货! 五.Deep Learning的基本思想 假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表示为: I =>S1=>S2=>….. ...
随机推荐
- Linux命令的详解
cat /etc/passwd文件中的每个用户都有一个对应的记录行,记录着这个用户的一下基本属性.该文件对所有用户可读. /etc/shadow 文件正如他 ...
- 微信&QQ中打开网页提示“已停止访问该网页”是怎么回事?
背景 大家是不是经常会遇到这种情况,分享出去的网页链接在微信里或者QQ里打开会提示“已停止访问该网页”,当大家看到这种的提示的时候就说明你访问的网页已经被腾讯拦截了. 当大家遇到以上这种情况的时候要怎 ...
- sql sever 触发器的概念和使用
触发器简介: 触发器是一种特殊的存储过程,它的执行不是由程序调用,也不是手动执行,而是由事件来触发.触发器是当对某一个表进行操作.例如:update.insert.delete这些操作的时候,系统会自 ...
- 24 | MySQL是怎么保证主备一致的?
在前面的文章中,我不止一次地和你提到了binlog,大家知道binlog可以用来归档,也可以用来做主备同步,但它的内容是什么样的呢?为什么备库执行了binlog就可以跟主库保持一致了呢?今天我就正式地 ...
- java 标准日期格式
public static void main(String[] argv) { // 使用默认时区和语言环境获得一个日历 Calendar cale = Calendar.getInstance() ...
- a=(1,)b=(1),c=(“1”) 分别是什么类型的数据
(1,)– tuple; (“1”) – str; (1) – int; >>> (2,)(2,)>>> (2)2>>> ("6&quo ...
- Spring Cloud Gateway(四):路由定义定位器 RouteDefinitionLocator
本文基于 spring cloud gateway 2.0.1 1.简介 RouteDefinitionLocator 是路由定义定位器的顶级接口,它的主要作用就是读取路由的配置信息(org.spri ...
- (转)glances用法
借鉴:https://www.ibm.com/developerworks/cn/linux/1304_caoyq_glances/index.html glances 可以为 Unix 和 Linu ...
- WebRTC MediaStream接口
MediaStream API旨在方便地从用户本地摄像机和麦克风访问媒体流.getUserMedia()方法是访问本机输入设备的主要方式. API有几个关键点: 1. 实时视频或音频以流对象的形式表示 ...
- Linux用户组
1.介绍 类似于角色,系统可以对有共性的多个用户进行统一的管理 2.增加组 groupadd 组名 3.删除组 groupdel 组名 4.增加用户时直接为用户指定组 useradd -g 用 ...