机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法
聚类算法
概述
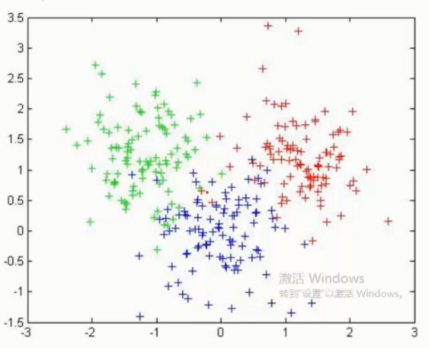
无监督问题 手中无标签
聚类 将相似的东西分到一组
难点 如何 评估, 如何 调参
基本概念
要得到的簇的个数 - 需要指定 K 值
质心 - 均值, 即向量各维度取平均
距离的度量 - 常用 欧几里得距离 和 余弦线相似度 ( 先标准化 )
优化目标 - 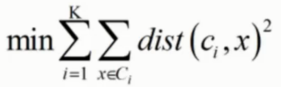
需求每个簇中的点, 到质心的距离尽可能的加和最小, 从而得到最优
K - MEANS 算法
工作流程
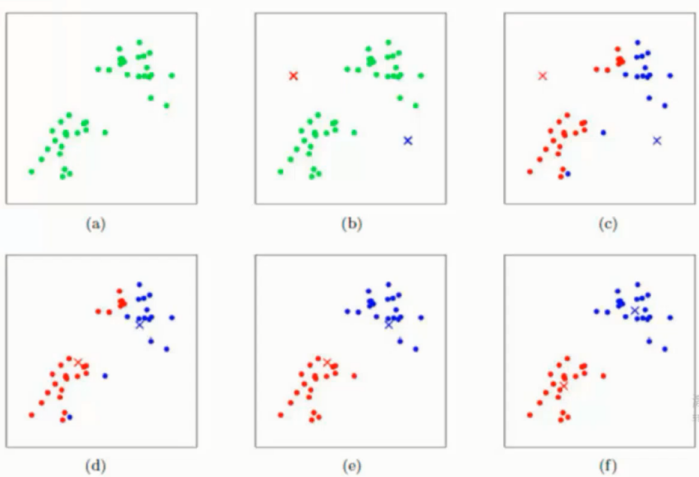
- (a) 初始图
- (b) 在指定了 K 值之后, 会在图中初始化两个点 红点, 蓝点( 随机质心 ) 这里 K 指定为 2
- (c) 然后对图中的每一个点计算是分别到红点以及蓝点的距离, 谁短就算谁的
- (d) 重新将红色蓝色区域计算质心
- (e) 根据重新计算的质心, 再次遍历所有点计算到两个新质点的距离对比划分
- (f) 按照之前的套路再次更新质点
就这样不断的更新下去, 直到所有的样本点都不再发生变化的时候则表示划分成功
优势
简单快速, 适合常规数据集
劣势
K 值难以决定
复杂度与样本呈线性关系
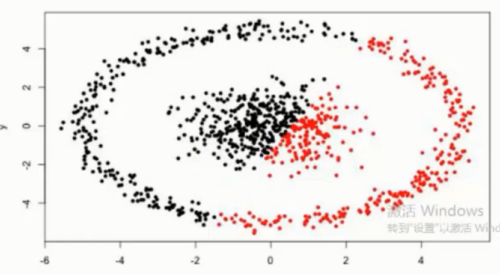
很难发现任意形状的簇 , 如下图
非常依赖初始点, 如果初始点设定很不好会影响迭代次数甚至无法达到最优解
实际操作很不稳定, 需要多次设定初始点进行操作对比
图像压缩实例
将彩色 三通道 RGB 0~255 的青取值压缩成 单通道 0~128 的取值

解压缩
DBSCAN 算法
基本概念
核心对象
若某个点的密度达到算法设定的阈值则其为核心点 ( 即 r 邻域内点的数量不小于 minPts )
即这点画一个半径为 r 的圆, 圆内的点的数量不小于我们设定的最小数量, 这个点就是核心点
€ - 领域的距离阈值
设定的半径 r, 就是上面画圈用的半径
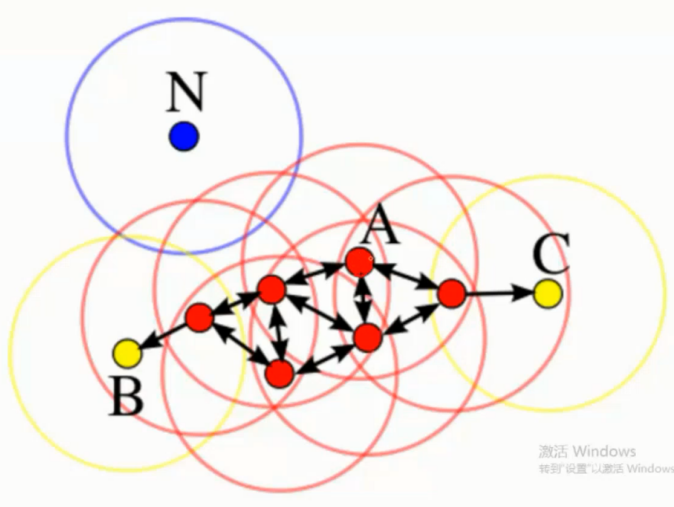
直接密度可达
若某点 p 在点 q 的 r 邻域内, 且 q 是核心点则 p-q 直接密度可达

密度可达
若有一个点的序列 q0.q1,.....qk, 对任意 qi - qi -1 是直接密度可达, 则称 q0 到 qk 密度可达
这实际上是直接密度可达的 '传播'

如图, q1 对 q0 是直接密度可达
q2 对 q1 是直接密度可达,
因此 尽管 q2 并不在 q0 的 r 半径的区域内
q2 还是可以通过 q1 对 q0 密度可达
密度相连
若从某核心点 p 出发, 点 q 和点 k 都是密度可达的, 则称点 q 和点 k 是 密度相连的
边界点
属于某一个类的非核心点, 不能发展下线了
噪声点
不属于任何一个类簇的点, 从任何一个核心点出发都是密度不可达

参数
参数 D 数据集
参数 € 指定半径
MinPts 密度阈值
流程
1. 标记所有的对象为 unvsited
2. 随机选择一个对象为 p 为 visited
3. if p 的 € 半径内的领域至少有 MinPts 个对象
3.1 创建一个 新簇 C 并把 这些对象添加到 N
3.2 for N 中的每个点 p
3.2.1 if p 是 unvsited :
3.2.1.1 标记 p 为 visited
3.2.1.2 if p 的 € 半径内的领域至少有 MinPts 个对象, 把这些对象添加到 N
3.2.1.3 if p 不是任何 簇的成员, 把 p 添加到 C
3.3 输出 C
4. 标记 p 为噪声
5. 为 unvsited 在创建新的 簇 C2
6. 不断循环直到所有的 对象都成为 visited
参数选择

优势
不需要指定 簇的个数
可以发现任意形状的簇
擅长找出离群点 ( 检测任务 )
两个参数就够了
劣势
高维度数据有些困难 ( 可以做降为 )
参数难以选择 ( 参数对结果的影响非常大 )
Sklearn 中效率很慢 ( 数据削减策略 )
聚类算法对比
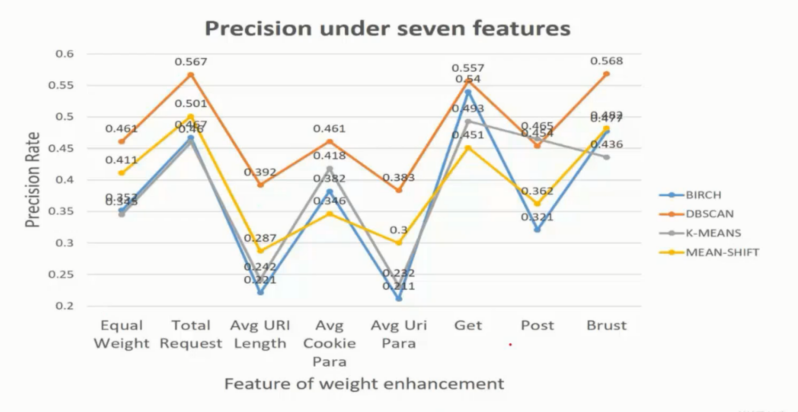
DBSCAN 是有着绝对大的优势比起其他的算法, 其他三个算法中值得一提的是 BIRCH 的增量更新的速度是最快的, 对于结果最高要求的话还是推荐 DBSCAN 对于速度要求的话就 BIRCH 好了
聚类练习实例
数据集
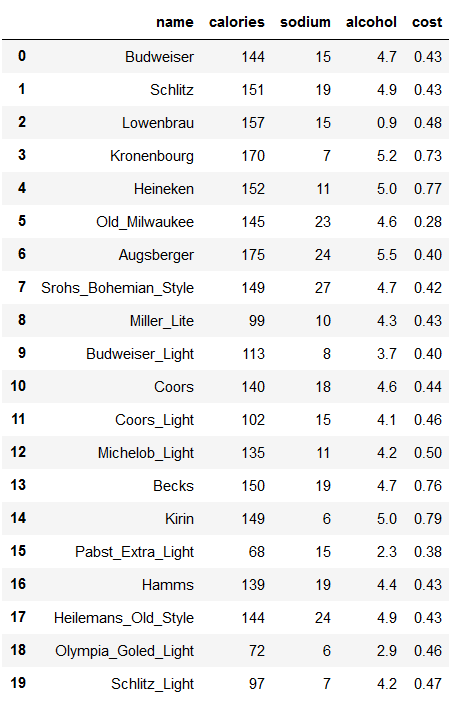
# beer dataset
import pandas as pd
beer = pd.read_csv('data.txt', sep=' ')
beer
X = beer[["calories","sodium","alcohol","cost"]]
KMeans 算法
模型
训练两个模型做对比, 只需要指定堆的数量即可
from sklearn.cluster import KMeans km = KMeans(n_clusters=3).fit(X)
km2 = KMeans(n_clusters=2).fit(X)
数据展示
训练完后就可以拿到标签, 这里因为指定了三个类别, 因此 取值为 0,1,2
km.labels_
array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 2, 0, 0, 2, 1])
方便查看重新组合一下数据
beer['cluster'] = km.labels_
beer['cluster2'] = km2.labels_
beer.sort_values('cluster')
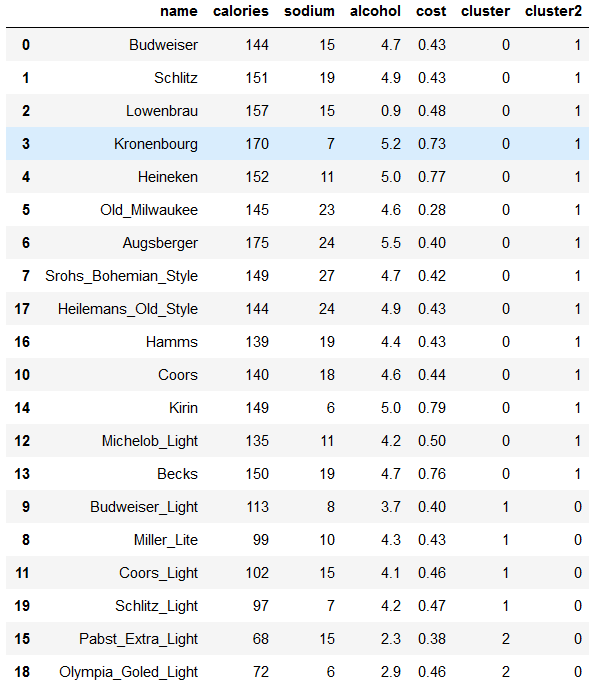
查看数据的均值
beer.groupby("cluster").mean()
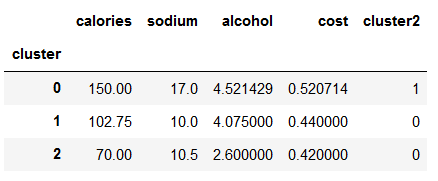
取出中心点位置
centers = beer.groupby("cluster").mean().reset_index()
画图展示
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14
import numpy as np
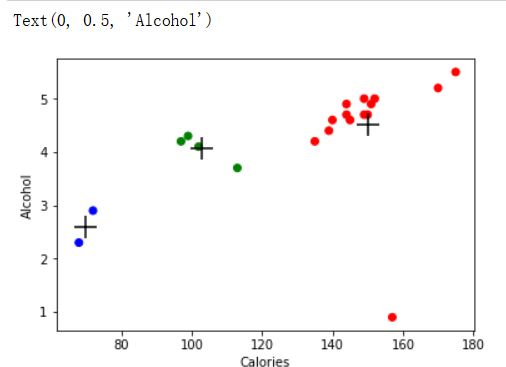
colors = np.array(['red', 'green', 'blue', 'yellow'])
plt.scatter(beer["calories"], beer["alcohol"],c=colors[beer["cluster"]])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")
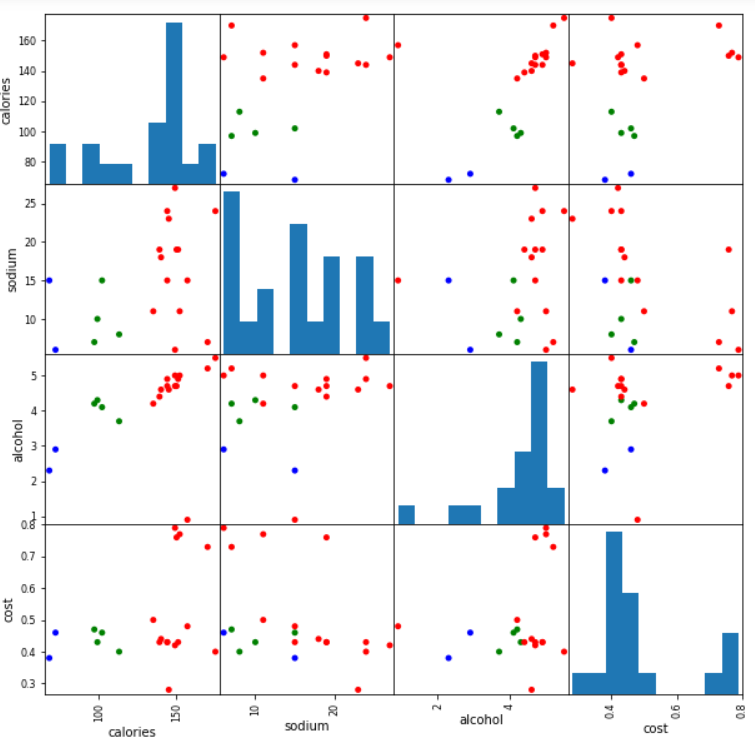
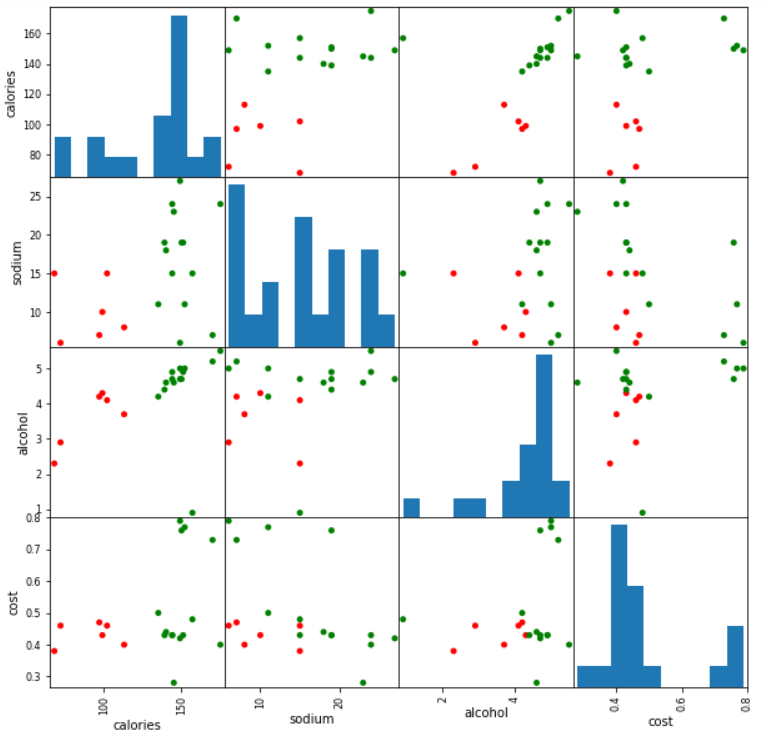
混淆矩阵展示 所有的特征之间的关系展示
from pandas.plotting import scatter_matrix
%matplotlib inline cluster_centers = km.cluster_centers_ cluster_centers_2 = km2.cluster_centers_
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=100, alpha=1, c=colors[beer["cluster"]], figsize=(10,10))
plt.suptitle("With 3 centroids initialized")
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=100, alpha=1, c=colors[beer["cluster2"]], figsize=(10,10))
plt.suptitle("With 2 centroids initialized")
两个簇的混淆矩阵
标准化处理
在 sklearn 中的 预处理模块中使用标准化方法将数据处理一下
将原来的数据浮动大小转变成差不多的大小, 从而消除数值之间的差异性
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled
array([[ 0.38791334, 0.00779468, 0.43380786, -0.45682969],
[ 0.6250656 , 0.63136906, 0.62241997, -0.45682969],
[ 0.82833896, 0.00779468, -3.14982226, -0.10269815],
[ 1.26876459, -1.23935408, 0.90533814, 1.66795955],
[ 0.65894449, -0.6157797 , 0.71672602, 1.95126478],
[ 0.42179223, 1.25494344, 0.3395018 , -1.5192243 ],
[ 1.43815906, 1.41083704, 1.1882563 , -0.66930861],
[ 0.55730781, 1.87851782, 0.43380786, -0.52765599],
[-1.1366369 , -0.7716733 , 0.05658363, -0.45682969],
[-0.66233238, -1.08346049, -0.5092527 , -0.66930861],
[ 0.25239776, 0.47547547, 0.3395018 , -0.38600338],
[-1.03500022, 0.00779468, -0.13202848, -0.24435076],
[ 0.08300329, -0.6157797 , -0.03772242, 0.03895447],
[ 0.59118671, 0.63136906, 0.43380786, 1.88043848],
[ 0.55730781, -1.39524768, 0.71672602, 2.0929174 ],
[-2.18688263, 0.00779468, -1.82953748, -0.81096123],
[ 0.21851887, 0.63136906, 0.15088969, -0.45682969],
[ 0.38791334, 1.41083704, 0.62241997, -0.45682969],
[-2.05136705, -1.39524768, -1.26370115, -0.24435076],
[-1.20439469, -1.23935408, -0.03772242, -0.17352445]])
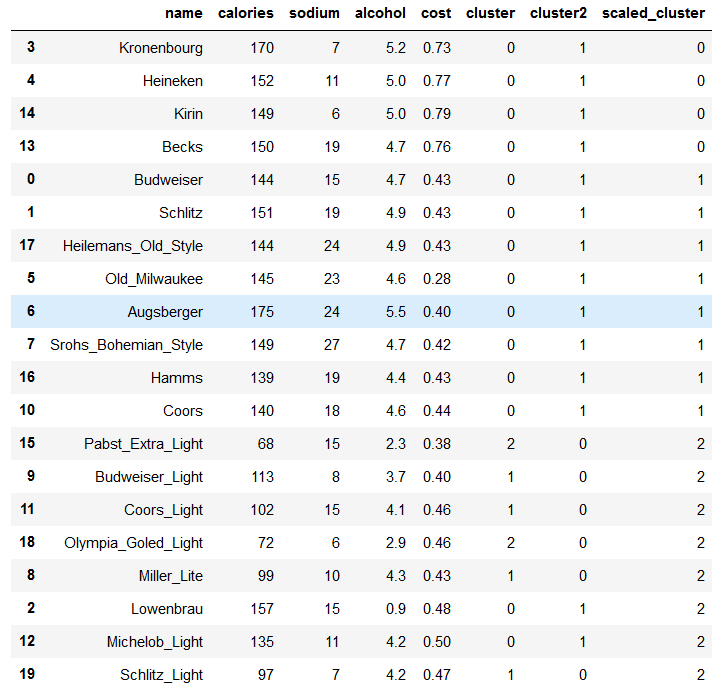
km = KMeans(n_clusters=3).fit(X_scaled)
beer["scaled_cluster"] = km.labels_
beer.sort_values("scaled_cluster")
聚类评估 - 轮廓系数
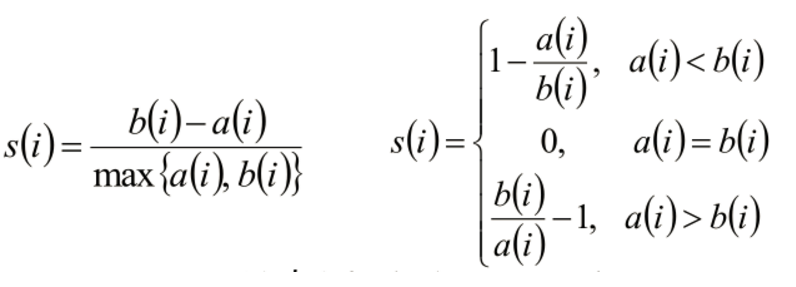
- 计算样本i到同簇其他样本的平均距离ai
- ai 越小,说明样本i越应该被聚类到该簇
- 将ai 称为样本i的簇内不相似度
- 计算样本i到其他某簇Cj 的所有样本的平均距离bij
- bi 越大, 表示离其他簇越远
- 称为样本i与簇Cj 的不相似度
- 定义为样本i的簇间不相似度:bi =min{bi1, bi2, ..., bik}
- si接近1,则说明样本i聚类合理
- si接近-1,则说明样本i更应该分类到另外的簇
- 若si 近似为0,则说明样本i在两个簇的边界上
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaled_cluster)
score = metrics.silhouette_score(X,beer.cluster)
print(score_scaled, score)
结果做了标准化的结果居然比没做标准化结果的更差了. 所以标准化有时候也需要取舍
0.1797806808940007 0.6731775046455796
参数选择
K 参数的不知道怎么选那就利用上面的评测分别评测一遍试下
scores = []
for k in range(2,20):
labels = KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X, labels)
scores.append(score) scores
[0.6917656034079486,
0.6731775046455796,
0.5857040721127795,
0.422548733517202,
0.39888288049162546,
0.43776116697963124,
0.38946337473125997,
0.39746405172426014,
0.3915697409245163,
0.32472080133848924,
0.3459775237127248,
0.31221439248428434,
0.30707782144770296,
0.2736836031737978,
0.2849514001174898,
0.23498077333071996,
0.1588091017496281,
0.08423051380151177]
可见 k = 2 的时候 0.69 是最高的
画图展示更加直观
plt.plot(list(range(2,20)), scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Sihouette Score")

DBSCAN 算法
对于不规则的更推荐 DBSCAN 算法, 但是简单的数据集上可能还不如 KMEANS
创建模型
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=10, min_samples=2).fit(X)
取出分类结果
labels = db.labels_
组合数据
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
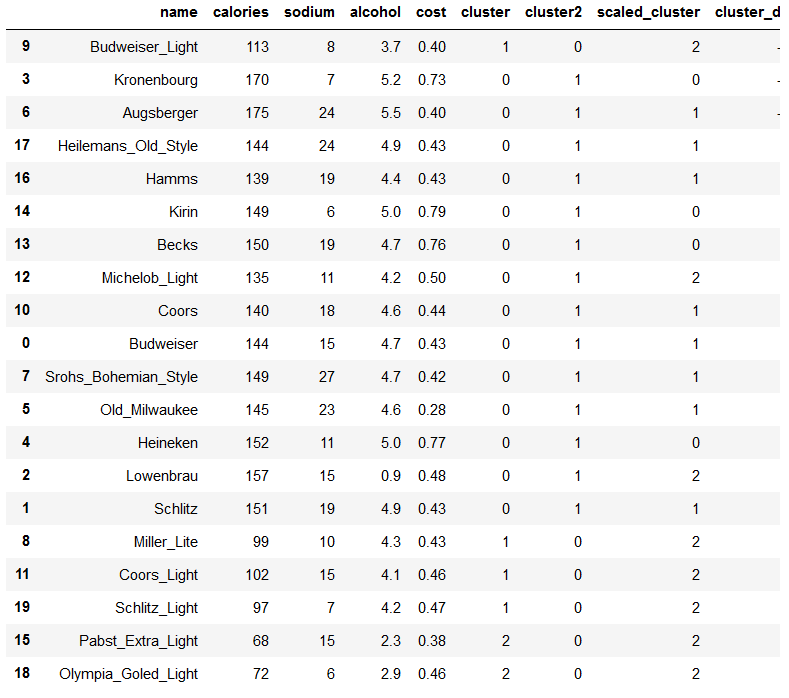
查看数据
beer.groupby('cluster_db').mean()
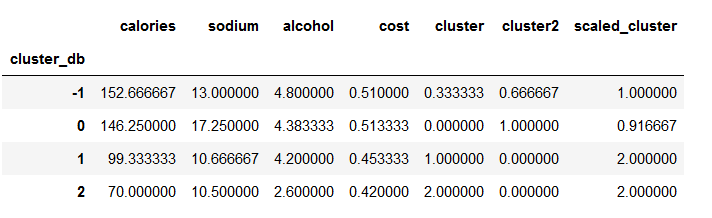
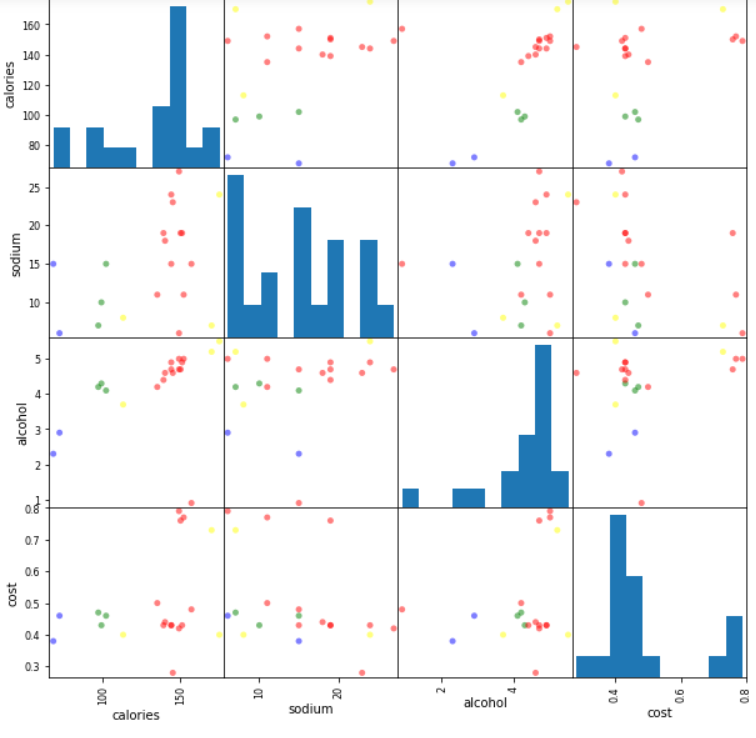
画图展示
scatter_matrix(X, c=colors[beer.cluster_db], figsize=(10,10), s=100)
机器学习 - 算法 - 聚类算法 K-MEANS / DBSCAN算法的更多相关文章
- 理解KNN算法中的k值-knn算法中的k到底指的是什么 ?
2019-11-09 20:11:26为方便自己收藏学习,转载博文from:https://blog.csdn.net/llhwx/article/details/102652798 knn算法是指对 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 31(1).密度聚类---DBSCAN算法
密度聚类density-based clustering假设聚类结构能够通过样本分布的紧密程度确定. 密度聚类算法从样本的密度的角度来考察样本之间的可连接性,并基于可连接样本的不断扩张聚类簇,从而获得 ...
- DBscan算法及其Python实现
DBSCAN简介: 1.简介 DBSCAN 算法是一种基于密度的空间聚类算法.该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其它空间对象)的数目不小于某一给定阀值.DBS ...
- 机器学习--聚类系列--DBSCAN算法
DBSCAN算法 基本概念:(Density-Based Spatial Clustering of Applications with Noise) 核心对象:若某个点的密度达到算法设定的阈值则其为 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 聚类算法——DBSCAN算法原理及公式
聚类的定义 聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小.聚类算法是无监督的算法. 常见的相似度计算方法 闵可夫斯基距离M ...
随机推荐
- redis高可用之sentinel哨兵
一,单实例模式 当系统中只有一台redis运行时,一旦该redis挂了,会导致整个系统无法运行. 二,主从模式 由于单台redis出现单点故障,就会导致整个系统不可用,所以想到的办法自然就是备份.当一 ...
- js基础知识1
本博客转自某不知名程序员 1. JavaScript基础分为三个部分: ECMAScript:JavaScript的语法标准.包括变量.表达式.运算符.函数.if语句.for语句等. DOM:操作网页 ...
- 【基础搜索】poj-2676-Sudoku(数独)--求补全九宫格的一种合理方案
数独 时限:2000 MS 内存限制:65536K 提交材料共计: 22682 接受: 10675 特别法官 描述 数独是一个非常简单的任务.一个9行9列的正方形表被分成9个较小的3x ...
- python访问aws-S3服务
创建本地 AWS 凭证文件 登录 AWS 管理控制台 并通过以下网址打开 IAM 控制台 https://console.amazonaws.cn/iam/. 创建一个新用户,其权限仅限于您希望您的代 ...
- AJAX学习笔记——同源策略
同源策略 同源策略,所有浏览器都实行这个政策 最初,它的含义是指,A 网页设置的 Cookie,B 网页不能打开,除非这两个网页"同源".所谓"同源"指的是&q ...
- Vue Router 使用方法
安装 直接下载 / CDN https://unpkg.com/vue-router/dist/vue-router.js Unpkg.com 提供了基于 NPM 的 CDN 链接.上面的链接会一直指 ...
- php数据类型之浮点型
所谓浮点类型,可以理解为:我们数学里面的小数. [注意]关于精度.取值范围和科学型声明不是学习的重点.因为此块在实际开发中用的特别少.我们将此块的知识点的学习标注为,了解级别.直线电机滑台 声明方式分 ...
- web+页面支持批量下载吗
一.此方法火狐有些版本是不支持的 window.location.href = 'https://*****.oss-cn-**.aliyuncs.com/*********';二.为了解决火狐有些版 ...
- luogu 2152
SuperGcd 二进制算法 1. A = B, Gcd(A, B) = A; 2. A,B为偶数, Gcd(A, B) = 2 * Gcd(A / 2, B / 2); 3. A 为偶数, B 为 ...
- CUDA编程前言
GPU架构 GPU特别适用于 密集计算,高度可并行计算,图形学 晶体管主要被用于 执行计算,而不是缓存数据,控制指令流 GPU计算的历史 2001/2002 -- 研究人员把GPU当做数据并行协处理器 ...