MLE vs MAP: the connection between Maximum Likelihood and Maximum A Posteriori Estimation
Reference:MLE vs MAP.
Maximum Likelihood Estimation (MLE) and Maximum A Posteriori (MAP), are both a method for estimating some variable in the setting of probability distributions or graphical models. They are similar, as they compute a single estimate, instead of a full distribution.
MLE, as we, who have already indulge ourselves in Machine Learning, would be familiar with this method. Sometimes, we even use it without knowing it. Take for example, when fitting a Gaussian to our dataset, we immediately take the sample mean and sample variance, and use it as the parameter of our Gaussian. This is MLE, as, if we take the derivative of the Gaussian function with respect to the mean and variance, and maximizing it (i.e. setting the derivative to zero), what we get is functions that are calculating sample mean and sample variance. Another example, most of the optimization in Machine Learning and Deep Learning (neural net, etc), could be interpreted as MLE.
Speaking in more abstract term, let’s say we have a likelihood function P(X|θ)P(X|θ). Then, the MLE for θ , the parameter we want to infer, is:
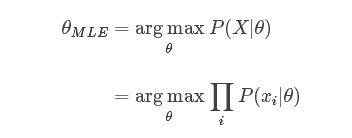
As taking a product of some numbers less than 1 would approaching 0 as the number of those numbers goes to infinity, it would be not practical to compute, because of computation underflow. Hence, we will instead work in the log space, as logarithm is monotonically increasing, so maximizing a function is equal to maximizing the log of that function.

To use this framework, we just need to derive the log likelihood of our model, then maximizing it with regard of θ using our favorite optimization algorithm like Gradient Descent.
Up to this point, we now understand what does MLE do. From here, we could draw a parallel line with MAP estimation.
MAP usually comes up in Bayesian setting. Because, as the name suggests, it works on a posterior distribution, not only the likelihood.
Recall, with Bayes’ rule, we could get the posterior as a product of likelihood and prior:

We are ignoring the normalizing constant as we are strictly speaking about optimization here, so proportionality is sufficient.
If we replace the likelihood in the MLE formula above with the posterior, we get:
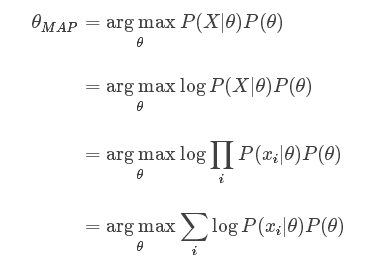
Comparing both MLE and MAP equation, the only thing differs is the inclusion of prior P(θ) in MAP, otherwise they are identical. What it means is that, the likelihood is now weighted with some weight coming from the prior.
Let’s consider what if we use the simplest prior in our MAP estimation, i.e. uniform prior. This means, we assign equal weights everywhere, on all possible values of the θ. The implication is that the likelihood equivalently weighted by some constants. Being constant, we could be ignored from our MAP equation, as it will not contribute to the maximization.
Let’s be more concrete, let’s say we could assign six possible values into θ . Now, our prior P(θ) is 1/6 everywhere in the distribution. And consequently, we could ignore that constant in our MAP estimation.

We are back at MLE equation again!
If we use different prior, say, a Gaussian, then our prior is not constant anymore, as depending on the region of the distribution, the probability is high or low, never always the same.
What we could conclude then, is that MLE is a special case of MAP, where the prior is uniform!
MLE vs MAP: the connection between Maximum Likelihood and Maximum A Posteriori Estimation的更多相关文章
- Maximum Likelihood及Maximum Likelihood Estimation
1.What is Maximum Likelihood? 极大似然是一种找到最可能解释一组观测数据的函数的方法. Maximum Likelihood is a way to find the mo ...
- 最大似然估计实例 | Fitting a Model by Maximum Likelihood (MLE)
参考:Fitting a Model by Maximum Likelihood 最大似然估计是用于估计模型参数的,首先我们必须选定一个模型,然后比对有给定的数据集,然后构建一个联合概率函数,因为给定 ...
- 机器学习的MLE和MAP:最大似然估计和最大后验估计
https://zhuanlan.zhihu.com/p/32480810 TLDR (or the take away) 频率学派 - Frequentist - Maximum Likelihoo ...
- Linear Regression and Maximum Likelihood Estimation
Imagination is an outcome of what you learned. If you can imagine the world, that means you have lea ...
- 似然函数 | 最大似然估计 | likelihood | maximum likelihood estimation | R代码
学贝叶斯方法时绕不过去的一个问题,现在系统地总结一下. 之前过于纠结字眼,似然和概率到底有什么区别?以及这一个奇妙的对等关系(其实连续才是f,离散就是p). 似然函数 | 似然值 wiki:在数理统计 ...
- [Bayes] Maximum Likelihood estimates for text classification
Naïve Bayes Classifier. We will use, specifically, the Bernoulli-Dirichlet model for text classifica ...
- 最大似然估计(Maximum Likelihood,ML)
先不要想其他的,首先要在大脑里形成概念! 最大似然估计是什么意思?呵呵,完全不懂字面意思,似然是个啥啊?其实似然是likelihood的文言翻译,就是可能性的意思,所以Maximum Likeliho ...
- MLE、MAP、贝叶斯三种估计框架
三个不同的估计框架. MLE最大似然估计:根据训练数据,选取最优模型,预测.观测值D,training data:先验为P(θ). MAP最大后验估计:后验概率. Bayesian贝叶斯估计:综合模型 ...
- Maximum Likelihood Method最大似然法
最大似然法,英文名称是Maximum Likelihood Method,在统计中应用很广.这个方法的思想最早由高斯提出来,后来由菲舍加以推广并命名. 最大似然法是要解决这样一个问题:给定一组数据和一 ...
随机推荐
- java运行环境搭建
java运行环境搭建 1.安装jdk下载和安装 1). java是Sun公司的产品,由于Sun公司被Oracle公司收购,因此jdk可以在Oracle的官网下载.网址:https://www.orac ...
- 【科普杂谈】IP地址子网划分
1.学习子网前的准备知识-什么是数制 现场讲解版 二进制和十进制的关系 二进制和十六进制的关系 16进制的每个位是2进制的4位 F=1111 二进制转16进制,按上面4位一组分开转 2.IP地 ...
- C++学习笔记-继承中的构造与析构
C++存在构造函数与析构函数,继承中也存在构造和析构函数.继承中的构造和析构函数与普通的构造析构有细微差别. 赋值兼容性原则 #include "iostream" using n ...
- 将其它部分jsp代码包含进一个jsp文件
<jsp:include page="文件路径/文件名.jsp" /> 将其它部分jsp代码包含进来.意义:将公共的部分代码抽出来,省略过多复制粘贴:只要改一个地方就O ...
- co源码
co模块整体包括三部分 对于几种参数类型的判断,主要判断是否object,array,promise,generator,generatorFunction这几种; 将几种不同的参数类型转换为prom ...
- 第六周课程总结&java实验报告四
第六周课程总结: 一.instanceof关键字 1.作用:在Java中可以使用instanceof关键字判断一个对象到底是哪个类的实例. 2.格式:对象 instanceof 类 -> 返回b ...
- 7.编写mapreduce案例
在写一个mapreduce类之前先添加依赖包 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&qu ...
- PTA(Basic Level)1033.旧键盘打字
旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现.现在给出应该输入的一段文字.以及坏掉的那些键,打出的结果文字会是怎样? 输入格式: 输入在 2 行中分别给出坏掉的那些键.以及应该输入 ...
- ASP.NET Core中使用Dapper
⒈添加 NuGet 包 Install-Package Dapper ⒉封装数据库类型 using System; using System.Collections.Generic; using Sy ...
- Servlet简单例子
一.项目结构 二.index.jsp <%@ page contentType="text/html; charset=utf-8" %> <html> & ...