HashMap原理探究
一、写随笔的原因:HashMap我们在平时都会用,一般面试题也都会问,借此篇文章分析下HashMap(基于JDK1.8)的源码。
二、具体的内容:
1.简介:
HashMap在基于数组+链表来实现的,能在查询和修改方便继承了数组的线性查找和链表的寻址修改。
2.工作原理:
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,计算并返回的hashCode是用于找到Map数组的bucket位置来储存Node 对象。这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Node 。如下图:
3.对照源码分析:
首先HashMap类里面有个Node<K,V>静态内部类,里面包含四个属性:hash,calue,value,next代码如下(主要看有注释的那四行,其他可以忽略):
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // 根据key值计算出的hash值
final K key; // 写入的key值
V value; // 写入的value值
Node<K,V> next; // 用于指向链表的下一层
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
接下来看一下put方法的源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
这里的hash(key)是计算出key所对应的hash值,继续看putVal()方法:
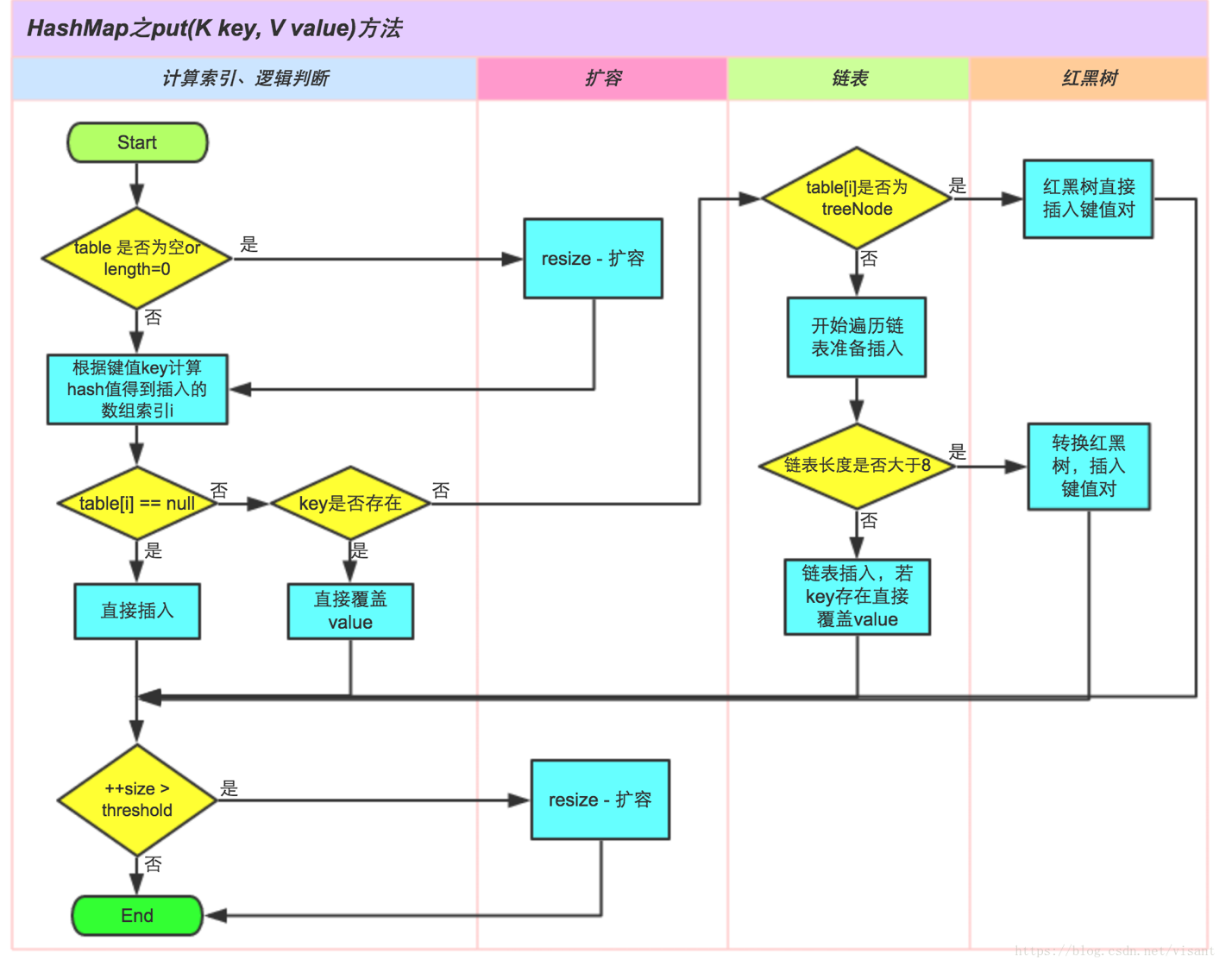
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; // 这里的tab就是table,后三行会赋值,下面我会直接说table而不是tab
Node<K,V> p; // p就是table[i],后面也会赋值的
int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // table是否为空或者长度为0
n = (tab = resize()).length; //满足则调用resize()方法扩容
if ((p = tab[i = (n - 1) & hash]) == null) // 计算出索引i,如果table[i] == null
tab[i] = newNode(hash, key, value, null); // 直接插入
else { // 如果table[i] !=null
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //判断key是否存在了
e = p; //满足则直接覆盖旧值
else if (p instanceof TreeNode) // key不存在,继续判断是否table[i]是否是TreeNode(红黑树结构)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //满足则在红黑树中插入键值对
else { // 不是红黑树结构
// 开始遍历表,并且插入
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) //如果链表长度大于等于8
treeifyBin(tab, hash); // 链表转化为红黑树
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) // 如果链表中存在相同的key,直接覆盖旧值
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // 容量达到阀值
resize(); //扩容
afterNodeInsertion(evict); // 这个方法HashMap里面是空的,LinkedHashMap有实现方法,意思就是为了实现顺序插入
return null;
}
具体分析看下面的图:
接下来看一下gēt方法的源码:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value; //指定key 通过hash函数得到key的hash值
}
上面的内部getNode()方法是根据hash值,知道对应的Node,并返回。然后就可以获得到里面的value值了。
4.一些问题:
1.HashMap中的碰撞探测(collision detection)以及碰撞的解决方法:
当两个对象的hashcode相同时,它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用LinkedList存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在LinkedList中。这两个对象就算hashcode相同,但是它们可能并不相等。 那如何获取这两个对象的值呢?当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,遍历LinkedList直到找到值对象。找到bucket位置之后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生,提高效率。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。
2.解决 hash 冲突的常见方法
a. 链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
b. 开放定址法:即发生冲突时,去寻找下一个空的哈希地址。只要哈希表足够大,总能找到空的哈希地址。
c. 再哈希法:即发生冲突时,由其他的函数再计算一次哈希值。
d. 建立公共溢出区:将哈希表分为基本表和溢出表,发生冲突时,将冲突的元素放入溢出表。
HashMap 就是使用链地址法来解决冲突的(jdk8中采用平衡树来替代链表存储冲突的元素,但hash() 方法原理相同)。数组中的每一个单元都会指向一个链表,如果发生冲突,就将 put 进来的 K- V 插入到链表的尾部。
三、总结:
这次hashmap大概就分析到这里,总的来说java8对HashMap进行了一些修改,最大不同使用了红黑树。当我们查找时,根据hash值来定位到数组的具体下标,之后再顺着链表一个一个的查找,时间复杂度为O(n),当链表中的元素达到8以后会将链表转化为红黑树,时间复杂度则降为O(logN),提高了效率。
部分参考:https://blog.csdn.net/visant/article/details/80045154。
HashMap原理探究的更多相关文章
- [原] KVM 虚拟化原理探究(1)— overview
KVM 虚拟化原理探究- overview 标签(空格分隔): KVM 写在前面的话 本文不介绍kvm和qemu的基本安装操作,希望读者具有一定的KVM实践经验.同时希望借此系列博客,能够对KVM底层 ...
- [原] KVM 虚拟化原理探究 —— 目录
KVM 虚拟化原理探究 -- 目录 标签(空格分隔): KVM KVM 虚拟化原理探究(1)- overview KVM 虚拟化原理探究(2)- QEMU启动过程 KVM 虚拟化原理探究(3)- CP ...
- [原] KVM 虚拟化原理探究(6)— 块设备IO虚拟化
KVM 虚拟化原理探究(6)- 块设备IO虚拟化 标签(空格分隔): KVM [toc] 块设备IO虚拟化简介 上一篇文章讲到了网络IO虚拟化,作为另外一个重要的虚拟化资源,块设备IO的虚拟化也是同样 ...
- [原] KVM 虚拟化原理探究(5)— 网络IO虚拟化
KVM 虚拟化原理探究(5)- 网络IO虚拟化 标签(空格分隔): KVM IO 虚拟化简介 前面的文章介绍了KVM的启动过程,CPU虚拟化,内存虚拟化原理.作为一个完整的风诺依曼计算机系统,必然有输 ...
- [原] KVM 虚拟化原理探究(4)— 内存虚拟化
KVM 虚拟化原理探究(4)- 内存虚拟化 标签(空格分隔): KVM 内存虚拟化简介 前一章介绍了CPU虚拟化的内容,这一章介绍一下KVM的内存虚拟化原理.可以说内存是除了CPU外最重要的组件,Gu ...
- [原] KVM 虚拟化原理探究(3)— CPU 虚拟化
KVM 虚拟化原理探究(3)- CPU 虚拟化 标签(空格分隔): KVM [TOC] CPU 虚拟化简介 上一篇文章笼统的介绍了一个虚拟机的诞生过程,从demo中也可以看到,运行一个虚拟机再也不需要 ...
- [原] KVM 虚拟化原理探究(2)— QEMU启动过程
KVM 虚拟化原理探究- QEMU启动过程 标签(空格分隔): KVM [TOC] 虚拟机启动过程 第一步,获取到kvm句柄 kvmfd = open("/dev/kvm", O_ ...
- 弱类型变量原理探究(转载 http://www.csdn.net/article/2014-09-15/2821685-exploring-of-the-php)
N首页> 云计算 [问底]王帅:深入PHP内核(一)——弱类型变量原理探究 发表于2014-09-19 09:00| 13055次阅读| 来源CSDN| 36 条评论| 作者王帅 问底PHP王帅 ...
- js事件底层原理探究
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
随机推荐
- stegsolve---图片隐写查看器
今天做CTF隐写术的题偶然发现一隐写图片查看的神器------stegsolve,分享给大家 stegsolve下载地址:http://www.caesum.com/handbook/Stegsolv ...
- MySQL 对 IP 字段的排序问题
MySQL 对 IP 字段的排序问题 问题描述 想对一张带有 IP 字段的表,对 IP 字段进行升序排序,方便查看每个段的 IP 信息. 表结构和表数据如下: SET NAMES utf8mb4; ; ...
- sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
httpclient-4.5.jar 定时发送http包,忽然有一天报错,http证书变更引起的. 之前的代码 try { CloseableHttpClient httpClient = build ...
- POJO是什么,javabean是什么,以及POJO与javabean的区别
POJO(Plain Ordinary Java Object)简单的Java对象,实际就是普通JavaBeans,是为了避免和EJB混淆所创造的简称.使用POJO名称是为了避免和EJB混淆起来, 而 ...
- Visual Studio 展开和折叠代码快捷键
每个cs文件代码太多,总数找不到方法.每次都是手动一个一个方法折叠手疼,赶紧搜索折叠展开快捷键. Ctrl + M + O: 折叠所有方法 Ctrl + M + M: 折叠或者展开当前方法 Ctr ...
- 【HANA系列】【第六篇】SAP HANA XS使用JavaScript(JS)调用存储过程(Procedures)
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第六篇]SAP HANA XS ...
- Pytorch修改ResNet模型全连接层进行直接训练
之前在用预训练的ResNet的模型进行迁移训练时,是固定除最后一层的前面层权重,然后把全连接层输出改为自己需要的数目,进行最后一层的训练,那么现在假如想要只是把 最后一层的输出改一下,不需要加载前面层 ...
- 【神经网络与深度学习】如何在Caffe中配置每一个层的结构
如何在Caffe中配置每一个层的结构 最近刚在电脑上装好Caffe,由于神经网络中有不同的层结构,不同类型的层又有不同的参数,所有就根据Caffe官网的说明文档做了一个简单的总结. 1. Vision ...
- 修改iframe内元素的样式
$('iframe').load(function () { var x = document.getElementsByTagName('iframe')[0]; var y = (x.cont ...
- nginx集群+mysql数据同步
mysql集群配置在网站负载均衡中是必不可少的: 首先说下我个人准备的负载均衡方式: 1.通过nginx方向代理来将服务器压力分散到各个服务器上: 2.每个服务器中代码逻辑一样: 3.通过使用redi ...