目标检测 — one-stage检测(一)
总结的很好:https://www.cnblogs.com/guoyaohua/p/8994246.html
目前主流的目标检测算法主要是基于深度学习模型,其可以分成两大类:two-stage检测算法;one-stage检测算法。本文主要介绍第二类检测算法。
目标检测模型的主要性能指标是检测准确度和速度,对于准确度,目标检测要考虑物体的定位准确性,而不单单是分类准确度。一般情况下,two-stage算法在准确度上有优势,而one-stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进。
one-stage检测算法,其不需要region proposal阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度,比较典型的算法如YOLO,SSD,Retina-Net。
1、YOLO(15)
将物体检测任务当做回归问题(regression problem)来处理,直接通过整张图片的所有像素得到bounding box的坐标、box中包含物体的置信度和class probabilities。通过YOLO,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置。
YOLO模型相对于之前的物体检测方法有多个优点:
1、YOLO检测物体非常快。 因为没有复杂的检测流程,只需要将图像输入到神经网络就可以得到检测结果,YOLO可以非常快的完成物体检测任务。标准版本的YOLO在Titan X 的 GPU 上能达到45 FPS。更快的Fast YOLO检测速度可以达到155 FPS。而且,YOLO的mAP是之前其他实时物体检测系统的两倍以上。
2、YOLO可以很好的避免背景错误,产生false positives。 不像其他物体检测系统使用了滑窗或region proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时都能够看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。和Fast-R-CNN相比,YOLO的背景错误不到Fast-R-CNN的一半。
3、YOLO可以学到物体的泛化特征。 当YOLO在自然图像上做训练,在艺术作品上做测试时,YOLO表现的性能比DPM、R-CNN等之前的物体检测系统要好很多。因为YOLO可以学习到高度泛化的特征,从而迁移到其他领域。
尽管YOLO有这些优点,它也有一些缺点:
1、YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
2、 YOLO容易产生物体的定位错误。
3、YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)
如图所示,使用YOLO来检测物体,其流程是非常简单明了的:
1、将图像resize到448 * 448作为神经网络的输入
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制,筛选Boxes
YOLO直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。直接通过整张图片的所有像素得到bounding box的坐标、box中包含物体的置信度和class probabilities。通过YOLO,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置。


网络设计:
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代Goolenet的 inception modules )。
(1)YOLO将输入图像划分为S*S的网格,某个物体落在这个网格中,该网格就负责预测这个物体,并且每个网格只预测一种object;
(2)每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息。每一个bounding box包含5个值:x,y,w,h和confidence。公式如下,其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。

(3)每一个网格还要预测 C 个 conditional class probability(条件类别概率):Pr(Classi|Object),记为C类,当类别数为20时,一个网格的输出30个信息。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个张量。注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
(4)测试时,每个网格预测的class信息和bounding box预测的confidence信息得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
2、YOLO-v2(16)
1、通过一系列的方法提升准确率。
(1)Batch Normalization:对所有的conv层采用BN能够让网络更好的收敛,同时可以替代掉一些其他形式的regularization,而且可以去掉防止overfitting的dropout层而不会出现过拟合。
(2)High resolution classifier:YOLO从224*224增加到了448*448,这就意味着网络需要适应新的输入分辨率,使用448*448图片对网络微调。
(3) Convolutional With Anchor Boxes:预测偏移(offsets) 而不是直接预测坐标(coordinates) 能够简化问题,让网络更加容易学习,所以去除全连接层,利用Anchor Boxes预测BB。
在设置anchor 的比例时,相比于直接手工的设计比例,先用k-means聚类对原训练集进行聚类后再设置比例,能够获得更好的IOU,因为这相当于增加了一些先验信息。而获得更好的IOU,则有助于网络的训练。而在k-means选择现在度量距离的时候,并不是直接选择欧氏距离,而是选择 d(box, centroid) = 1 – IOU(box, centoid), 因为我们关心的是IOU,这无关于box的大小,而欧氏距离会受box大小的影响。最终选择k =5.
(4)Direct location prediction:约束位置预测,相对于网格左上角点的位置偏移。
(5)Fine-Grained Features:跨层连接,YOLO则还是采用13x13 的feature map上,但另外增加了一个passthrough layer 将一个earlier layer at 26x26 resolution 连接到 最末端的13x13的 feature map上。具体是,类似于ResNet的 identitymappings,将 26x26x512的feature map 转换成 13x13x2048的feature map. 最终提高1%的性能。
(6)Multi-Scale Training:网络是一个权值共享的网络,但是输入的图片大小可以是{320, 352, …, 608} ,训练时每10个batches 随机选取一种size。这样使得模型不需要固定一种输入尺寸,选取小尺寸时,可以获得更快的速度,大尺寸可以获得更高的精度。十分灵活。
2、提升速度
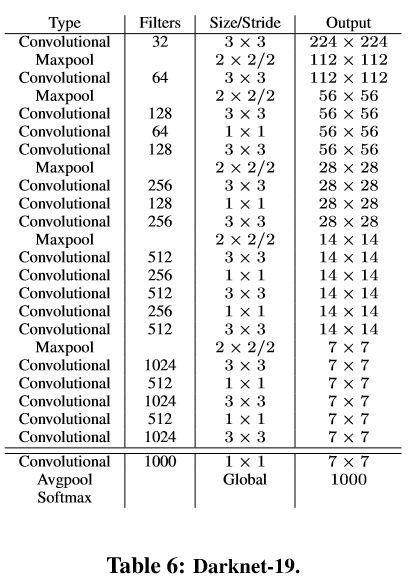
(1)model–Darknet19,有19个卷积层和5个maxpooling层,基本采用3x3 filter 和 每次pooling后通道数加倍的方法;
(2)采用data augmentation,随机裁剪,旋转,以及色调,饱和度和曝光偏移。
(3)去掉原网络最后一个卷积层,增加了三个 3 * 3 (1024 filters)的卷积层,并且在每一个卷积层后面跟一个1 * 1的卷积层,输出维度是检测所需数量。
3、YOLO-v3(18)
相比第二版本的改进点:使用残差模型和采用FPN架构(多尺度预测,特征金字塔网络 )。
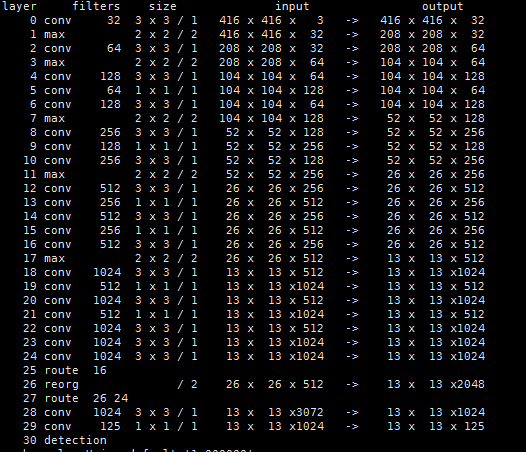
(1)特征提取器是一个残差模型,因为包含53个卷积层,所以称为Darknet-53,从网络结构上看,相比Darknet-19网络使用了残差单元,所以可以构建得更深。
(2)采用了3个尺度的特征图预测(当输入为416*416 时): (13*13),(26*26),(52*52),其中红色部分为各个尺度特征图的检测结果。YOLOv3每个位置使用3个先验框,一共三个尺度特征图,所以使用k-means得到9个先验框,并将其划分到3个尺度特征图上,尺度更大的特征图使用更小的先验框,和SSD类似。
- 尺度1: 在基础网络之后添加一些卷积层再输出box信息.
- 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.
- 尺度3: 与尺度2类似,使用了32x32大小的特征图.
(3)Softmax可被独立的多个logistic分类器替代,且准确率不会下降。分类损失采用binary cross-entropy loss。
优点:
快速,pipline简单,背景误检率低,通用性强。
YOLO V3对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。 但相比RCNN系列物体检测方法,YOLO V3具有以下缺点:
缺点:
识别物体位置精准性差,召回率低。
在每个网格中预测两个bbox这种约束方式减少了对同一目标的多次检测(R-CNN使用的region proposal方式重叠较多),相比R-CNN使用Selective Search产生2000个proposal(RCNN测试时每张超过40秒),YOLO仅使用7x7x2个。


参考博客:https://blog.csdn.net/xiaohu2022/article/details/79600037
http://www.voidcn.com/article/p-ksgrxafo-w.html
https://blog.csdn.net/hysteric314/article/details/53909408
https://www.cnblogs.com/makefile/p/YOLOv3.html © 康行天下
目标检测 — one-stage检测(一)的更多相关文章
- 目标检测之单步检测(Single Shot detectors)
目标检测之单步检测(Single Shot detectors) 前言 像RCNN,fast RCNN,faster RCNN,这类检测方法都需要先通过一些方法得到候选区域,然后对这些候选区使用高质量 ...
- 带你读AI论文丨用于目标检测的高斯检测框与ProbIoU
摘要:本文解读了<Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection&g ...
- OPENCV图像特征点检测与FAST检测算法
前面描述角点检测的时候说到,角点其实也是一种图像特征点,对于一张图像来说,特征点分为三种形式包括边缘,焦点和斑点,在OPENCV中,加上角点检测,总共提供了以下的图像特征点检测方法 FAST SURF ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- JavaScript浏览器检测之客户端检测
客户端检测一共分为三种,分别为:能力检测.怪癖检测和用户代理检测,通过这三种检测方案,我们可以充分的了解当前浏览器所处系统.所支持的语法.所具有的特殊性能. 一.能力检测: 能力检测又称作为特性检测, ...
- unity3d 赛车游戏——复位点检测优化、反向检测、圈数检测、赛道长度计算
接着上一篇文章说 因为代码简短且思路简单 所以我就把这几个功能汇总为一篇文章 因为我之前就是做游戏外挂的 经过验证核实,**飞车的复位点检测.圈数检测就是以下的方法实现的 至于反向检测和赛道长度计算, ...
- 离群点检测与序列数据异常检测以及异常检测大杀器-iForest
1. 异常检测简介 异常检测,它的任务是发现与大部分其他对象不同的对象,我们称为异常对象.异常检测算法已经广泛应用于电信.互联网和信用卡的诈骗检测.贷款审批.电子商务.网络入侵和天气预报等领域.这些异 ...
- 人脸检测的harr检测函数
眼球追踪需要对人脸进行识别,然后再对人眼进行识别,判断人眼张合度,进而判断疲劳... 解析:人脸检测的harr检测函数使用方法 代码理解: 利用训练集,检测出脸部,画出框 void CAviTestD ...
- 24V低压检测电路 - 低压检测电压(转)
24V低压检测电路 - 低压检测电压 参考: ADC采样工作原理详解 使用单片机的ADC采集电阻的分压 问题: 当ADC采集两个电阻分压后的电压的时候,ADC转换出来的电压值和万用表量出来的不一样差异 ...
- [DeeplearningAI笔记]卷积神经网络3.1-3.5目标定位/特征点检测/目标检测/滑动窗口的卷积神经网络实现/YOLO算法
4.3目标检测 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.1目标定位 对象定位localization和目标检测detection 判断图像中的对象是不是汽车--Image clas ...
随机推荐
- 【Leetcode_easy】690. Employee Importance
problem 690. Employee Importance 题意:所有下属和自己的重要度之和,所有下属包括下属的下属即直接下属和间接下属. solution:DFS; /* // Employe ...
- conda换源
装完Anaconda后,建议更新所有的包,因为以后使用很可能会报错. 而更新的时候conda的官方源在美国,不换源就非常蓝瘦,有生之年够呛了. 换源: conda config --add chann ...
- Unity与Android刘海屏适配
本周学习Unity与Android刘海屏适配 关于刘海屏适配部分 网上有很多教程 这里只是做一下整理 https://blog.csdn.net/xj1009420846/article/detail ...
- CMake生成VS2010工程相对路径和绝对路径问题说明
CMake生成VS2010工程相对路径和绝对路径问题说明 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 主要是使用CMake生成的VS2010的工程,最好不 ...
- 不使用局部变量和for循环或其它循环打印出如m=19,n=2結果为2 4 8 16 16 8 4 2形式的串
需求:不使用局部变量和for循环或其它循环打印形如:2 4 8 16 16 8 4 2 这样的串 代码MainTest.java package com.szp.study.javase.specia ...
- oracle数据库数据转储最好方式(数据库表、数据结构和数据一并导出)
导入:使用plsql:Tools --> Import Tables --> SQL Inserts 得到的为sql文件,在转储的过程中当导入另一个库的时候老是报 “表或视图不存在” ...
- Centos中阿里云yum源配置
centos中阿里云yum源配置 1.首先备份系统自带yum源配置文件/etc/yum.repos.d/CentOS-Base.repo mv /etc/yum.repos.d/CentOS-Base ...
- postman带Token测试接口
首先打开postman.是这样的界面 我们的需求是这样的.实现登录之后返回token.然后请求其他接口时在header头中带上token信息. OK.接下来我们这样操作: 现在登录没有操作token. ...
- T100——错误信息提示传入参数显示
LET l_str1 = l_xccc.xccc901LET l_str2 = l_inat015LET l_str = l_str1.trim(),'|',l_str2.trim() CALL cl ...
- php 获取某个月的周一
今天有个朋友问了一个问题,最后解决了下,先整理记下来,后面用到了再说 function getMonday($month = ''){ if(empty($month)){ $month = date ...