Java SE 核心 II【Collection 集合框架】
Collection集合框架
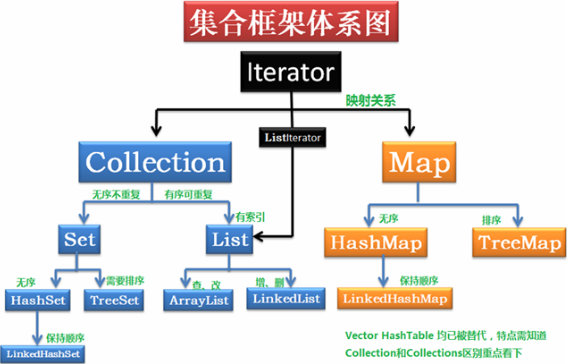
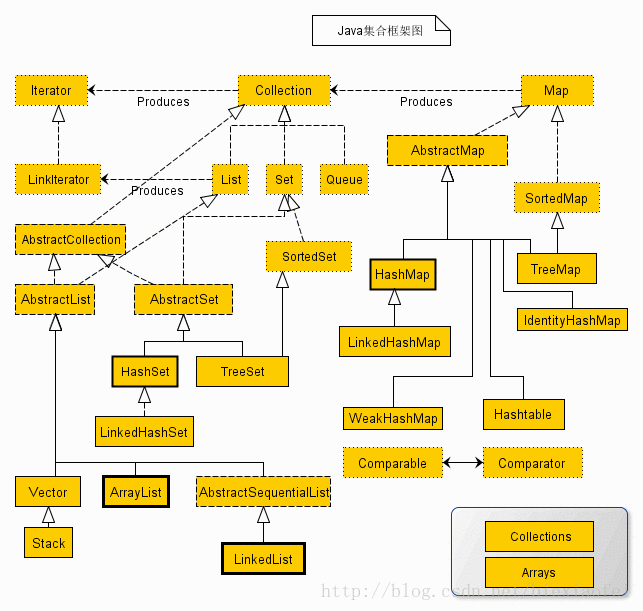
在实际开发中,需要将使用的对象存储于特定数据结构的容器中。而 JDK 提供了这样的容器——集合框架,集合框架中包含了一系列不同数据结构(线性表、查找表)的实现类。
集合的引入:
数组的优势:是一种简单的线性序列,可以快速地访问数组元素,效率高。如果从效率和类型检查的角度讲,数组是最好的。
数组的劣势:不灵活。容量需要事先定义好,不能随着需求的变化而扩容。
1)Collection 常用方法:
①int size():返回包含对象个数。 ②boolean isEmpty():返回是否为空。
③boolean contains(Object o):判断是否包含指定对象。
④void clear():清空集合。 ⑤boolean add(E e):向集合中添加对象。
⑥boolean remove(Object o):从集合中删除对象。
⑦boolean addAll(Collection<? extends E > c):另一个集合中的所有元素添加到集合
⑧boolean removeAll(Collection<?> c):删除集合中与另外一个集合中相同的原素
⑨Iterator<E> iterator():返回该集合的对应的迭代器
2)Collection 和 Collentions 的区别
Collection 是 java.util 下的接口,它是各种集合的父接口,继承于它的接口主要有 Set和 List;
Collections 是个 java.util 下的类,是针对集合的帮助类,提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
1、List集合的实现类(ArrayList、LinkedList和Vector)
List 接口是 Collection 的子接口,用于定义线性表数据结构,元素可重复、有序的;可以将 List 理解为存放对象的数组,只不过元素个数可以动态的增加或减少。
1)List 接口的两个常见的实现类:ArrayList 和 LinkedList,分别用动态数组和链表的方式实现了 List 接口。List、ArrayList 和 LinkedList 均处于 java.util 包下。
2)可以认为 ArrayList 和 LinkedList 的方法在逻辑上完全一样,只是在性能上有一定的差别,ArrayList 更适合于随机访问,而 LinkedList 更适合于插入和删除,在性能要求不是特别苛刻的情形下可以忽略这个差别。
List接口常用的实现类有3个:ArrayList、LinkedList和Vector。
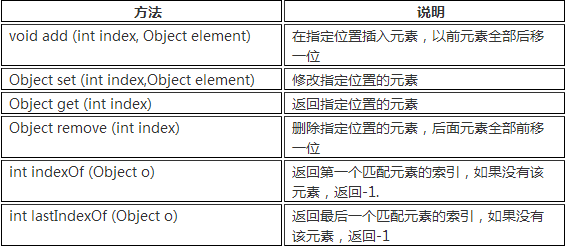
ArrayList查询效率高,增删效率低,线程不安全。我们一般使用它
package boom.collection; import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator; /**
* 测试collection接口的方法 List接口
*
* @author Administrator
*
*/
public class ListTest { public static void main(String[] args) {
//test01();
//test02();
test03(); } /**
* 集合带索引顺序的相关方法
*/
public static void test03() {
List<String> list = new ArrayList<>(); // 添加元素
list.add("京东");
list.add("阿里");
list.add("腾讯");
list.add("百度");
System.out.println(list);// [京东, 阿里, 腾讯, 百度] // 在指定索引位置插入新元素:index[0]
list.add(0, "网易");
System.out.println(list);// [网易, 京东, 阿里, 腾讯, 百度] // 移除指定位置的元素:index[3]
list.remove(3);
System.out.println(list);// [网易, 京东, 阿里, 百度] // 指定位置更改元素:index[0]
list.set(0,"Google");
System.out.println(list);// [Google, 京东, 阿里, 百度]
// 获得更改的元素
System.out.println(list.get(0));// Google list.add("阿里");
System.out.println(list);// [Google, 京东, 阿里, 百度, 阿里]
// 顺序查找(角标0开始)指定的元素下标
System.out.println(list.indexOf("阿里"));// 2
// 从后往前找
System.out.println(list.lastIndexOf("阿里"));// } /**
* ArrayList_操作多个List_并集和交集及两个list之间操作元素
*/
public static void test02() {
List<String> list01 = new ArrayList<String>();
list01.add("AAA");
list01.add("BBB");
list01.add("CCC"); List<String> list02 = new ArrayList<String>();
list02.add("DDD");
list02.add("CCC");
list02.add("EEE"); // 打印list01集合元素内容
System.out.println(list01); // [AAA, BBB, CCC] // 把list02集合里所有的元素都添加到list01集合里:在末尾进行添加
list01.addAll(list02);
System.out.println(list01); // [AAA, BBB, CCC, DDD, CCC, EEE] // 把list02集合里的所有元素添加到01集合里指定的位置,根据索引
list01.addAll(2, list02);
System.out.println(list01);// [AAA, BBB, DDD, CCC, EEE, CCC, DDD, CCC, EEE] // 01集合里是否包含02集合的所有元素 :true or false
System.out.println(list01.contains(list02)); // false // 先进行打印,方便看效果
System.out.println("list01:"+list01); // list01:[AAA, BBB, DDD, CCC, EEE, CCC, DDD, CCC, EEE]
System.out.println("list02:"+list02); // list02:[DDD, CCC, EEE] //移除集合01和集合02中都包含的元素,返回01集合
//list01.removeAll(list02);
//System.out.println(list01);// [AAA, BBB] // 取本集合01和集合02中都包含的元素,移除非交集元素,返回01集合
list01.retainAll(list02);
System.out.println(list01); // [DDD, CCC, EEE, CCC, DDD, CCC, EEE] } /**
* List接口常用方法
*/
public static void test01() {
List<String> list = new ArrayList<String>();
// 判断集合是否为空
System.out.println(list.isEmpty());// true // 添加add,按下标顺序添加
list.add("国产001");
list.add("国产002");
list.add("国产003"); System.out.println(list.isEmpty());// false // 打印 list自动调用toString方法
System.out.println(list.toString()); // [国产001, 国产002, 国产003]
System.out.println("集合的长度:" + list.size());// 集合的长度:3 // 指定位置索引添加元素
list.add(0, "new");// 在下标0的位置添加新元素 "new"
System.out.println(list); // [new, 国产001, 国产002, 国产003] // 移除
list.remove(0);// 移除下标为0的元素
System.out.println(list);// [国产001, 国产002, 国产003] // 根据下标修改某个元素的值
// index[1]的位置更改为 "改"
list.set(1, "改");
System.out.println(list);// [国产001, 改, 国产003] // 测试集合是否包含指定的元素:true or false
System.out.println("是否包含指定元素:" + list.contains("国产"));// false
System.out.println("是否包含指定元素:" + list.contains("国产003"));// true // 清空集合所有的元素
list.clear();
System.out.println("清空所有元素:" + list); // 清空所有元素:[] }
}
ListTest Code
运行效果参照图: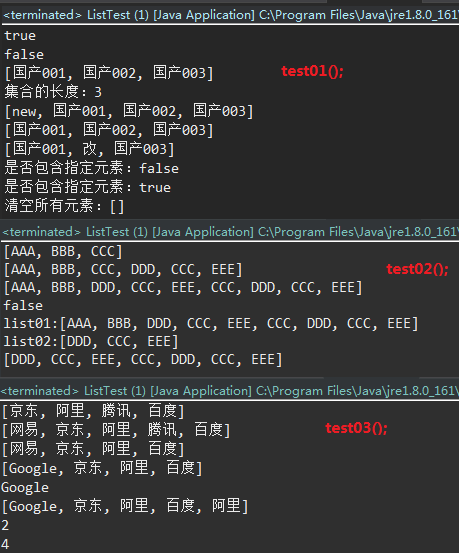
ArrayList_底层JDK源码解读
ArrayList:底层是用可变长度数组实现的存储。
特点:查询效率高,增删效率低,线程不安全。
1、数组长度是有限的,而ArrayList是可以存放任意数量的对象,长度不受限制。
2、那么它是怎么实现的呢?
本质上就是通过定义新的更大的数组,将旧数组中的内容拷贝到新数组,来实现扩容。 ArrayList的Object数组初始化长度为10,如果我们存储满了这个数组,需要存储第11个对象,就会定义新的长度更大的数组,并将原数组内容和新的元素一起加入到新数组中。
LinkedList:底层用双向链表实现的存储。
特点:查询效率低,增删效率高,线程不安全。

Vector:Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”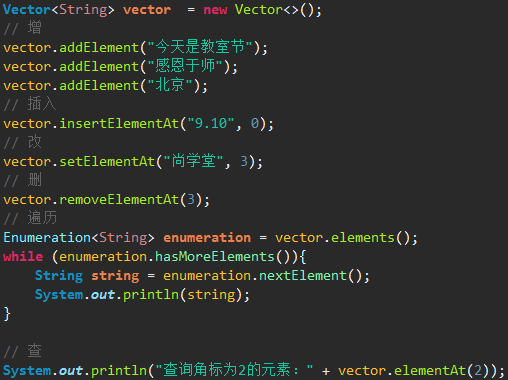
2、泛型
1)泛型是 JDK1.5 引入的新特性,泛型的本质是参数化类型。在类、接口、方法的定义过程中,所操作的数据类型为传入的指定参数类型。所有的集合类型都带有泛型参数,这样在创建集合时可以指定放入集合中的对象类型。同时,编译器会以此类型进行检查。
2)ArrayList 支持泛型,泛型尖括号里的符号可随便些,但通常大写 E。
3)迭代器也支持泛型,但是迭代器使用的泛型应该和它所迭代的集合的泛型类型一致!
4)泛型只支持引用类型,不支持基本类型,但可以使用对应的包装类
5)如果泛型不指定类型的话,默认为 Object 类型。
3、List 高级-数据结构:Queue 队列
队列(Queue)是常用的数据结构,可以将队列看成特殊的线性表,队列限制了对线性表的访问方式:只能从线性表的一端添加(offer)元素,从另一端取出(poll)元素。Queue接口:在包 java.util.Queue。
1)队列遵循先进先出原则:FIFO(First Input First Output)队列不支持插队,插队是不道德的。
2)JDK 中提供了 Queue 接口,同时使得 LinkedList 实现了该接口(选择 LinkedList 实现Queue 的原因在于 Queue经常要进行插入和删除的操作,而 LinkedList 在这方面效率较高)。
4、List 高级-数据结构:Deque 栈
栈(Deque)是常用的数据结构,是 Queue 队列的子接口,因此 LinkedList 也实现了 Deque接口。栈将双端队列限制为只能从一端入队和出队,对栈而言即是入栈和出栈。例如:子弹夹就是一种栈结构。在包 java.util.Deque 下。
1)栈遵循先进后出的原则:FILO(First Input Last Output)。
2)常用方法:
①push:压入,向栈中存入数据。
②pop:弹出,从栈中取出数据。
③peek:获取栈顶位置的元素,但不取出
5、Set集合的实现类(HashSet 和 TreeSet )
Set容器特点:无序、不可重复。无序指Set中的元素没有索引,我们只能遍历查找;不可重复指不允许加入重复的元素。更确切地讲,新元素如果和Set中某个元素通过equals()方法对比为true,则不能加入;甚至,Set中也只能放入一个null元素,不能多个。
1)HashSet 和 TreeSet 是 Set 集合的两个常见的实现类,分别用 hash 表和排序二叉树的方式实现了 Set 集合。HashSet 是使用散列算法实现 Set 的。
2)Set 集合没有 get(int index)方法,我们不能像使用 List 那样,根据下标获取元素。想获取元素需要使用 Iterator。
3)向集合添加元素也使用 add 方法,但是 add 方法不是向集合末尾追加元素,因为无序。
HashSet:采用哈希算法实现,底层实际是用HashMap实现的(HashSet本质就是一个简化版的HashMap),因此,查询效率和增删效率都比较高。
TreeSet:底层实际是用TreeMap实现的,内部维持了一个简化版的TreeMap,通过key来存储Set的元素。
(1) 由于是二叉树,需要对元素做内部排序。 如果要放入TreeSet中的类没有实现Comparable接口,则会抛出异常:java.lang.ClassCastException。
(2) TreeSet中不能放入null元素。
6、Map集合的实现类(HashMap、TreeMap、HashTable、Properties等)
Map就是用来存储“键(key)-值(value) 对”的。 Map类中存储的“键值对”通过键来标识,所以Key 不能重复,但所保存的 Value 可以重复。
HashMap和HashTable
HashMap采用哈希算法实现,是Map接口最常用的实现类。 由于底层采用了哈希表存储数据,键不能重复,如果发生重复(是否重复通过equals方法),新的键值对会替换旧的键值对。
特点:HashMap在查找、删除、修改方面都有非常高的效率。
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashMap与HashTable的区别
1. HashMap:线程不安全,效率高。允许key或value为null。
2. HashTable:线程安全,效率低。不允许key或value为null。
TreeMap使用和底层原理_Comparable接口_HashTable特点(HashTable: 线程安全,效率低。不允许key或value为null。)
TreeMap是红黑二叉树的典型实现。我们打开TreeMap的源码,发现里面有一行核心代码:private transient Entry<K,V> root = null;
TreeMap和HashMap实现了同样的接口Map,用法对于调用者来说没有区别。HashMap效率高于TreeMap;在需要排序(comparable)的Map时才选用TreeMap。
Collection集合框架的总结:
1. Collection 表示一组对象,它是集中、收集的意思,就是把一些数据收集起来。
2. Collection接口的两个子接口:
1) List中的元素有顺序,可重复。常用的实现类有ArrayList、LinkedList和 vector。
Ø ArrayList特点:查询效率高,增删效率低,线程不安全。
Ø LinkedList特点:查询效率低,增删效率高,线程不安全。
Ø vector特点:线程安全,效率低,其它特征类似于ArrayList。
2) Set中的元素没有顺序,不可重复。常用的实现类有HashSet和TreeSet。
Ø HashSet特点:采用哈希算法实现,查询效率和增删效率都比较高。
Ø TreeSet特点:内部需要对存储的元素进行排序。因此,我们对应的类需要实现Comparable接口。才能根据compareTo()方法比较对象之间的大小,才能进行内部排序。
3. 实现Map接口的类用来存储键(key)-值(value) 对。Map 接口的实现类有HashMap和TreeMap等。Map类中存储的键-值对通过键来标识,所以键值不能重复。
4. Iterator对象称作迭代器,用以方便的实现对容器内元素的遍历操作。
5. 类 java.util.Collections 提供了对Set、List、Map操作的工具方法。
6. 如下情况,可能需要我们重写equals/hashCode方法:
1) 要将我们自定义的对象放入HashSet中处理。
2) 要将我们自定义的对象作为HashMap的key处理。
3) 放入Collection容器中的自定义对象后,可能会调用remove、contains等方法时。
7. JDK1.5以后增加了泛型。泛型的好处:
1) 向集合添加数据时保证数据安全。
2) 遍历集合元素时不需要强制转换。
Java SE 核心 II【Collection 集合框架】的更多相关文章
- JavaSE中Collection集合框架学习笔记(2)——拒绝重复内容的Set和支持队列操作的Queue
前言:俗话说“金三银四铜五”,不知道我要在这段时间找工作会不会很艰难.不管了,工作三年之后就当给自己放个暑假. 面试当中Collection(集合)是基础重点.我在网上看了几篇讲Collection的 ...
- JavaSE中Collection集合框架学习笔记(3)——遍历对象的Iterator和收集对象后的排序
前言:暑期应该开始了,因为小区对面的小学这两天早上都没有像以往那样一到七八点钟就人声喧闹.车水马龙. 前两篇文章介绍了Collection框架的主要接口和常用类,例如List.Set.Queue,和A ...
- JAVA基础第五章-集合框架Map篇
业内经常说的一句话是不要重复造轮子,但是有时候,只有自己造一个轮子了,才会深刻明白什么样的轮子适合山路,什么样的轮子适合平地! 我将会持续更新java基础知识,欢迎关注. 往期章节: JAVA基础第一 ...
- Collection 集合框架
1. Collection 集合框架:在实际开发中,传统的容器(数组)在进行增.删等操作算法和具体业务耦合在一起,会增加程序的开发难度:这时JDK提供了这样的容器---Collection 集合框架, ...
- java se系列(十二)集合
1.集合 1.1.什么是集合 存储对象的容器,面向对象语言对事物的体现,都是以对象的形式来体现的,所以为了方便对多个对象的操作,存储对象,集合是存储对象最常用的一种方式.集合的出现就是为了持有对象.集 ...
- Collection集合框架与Iterator迭代器
集合框架 集合Collection概述 集合是Java中提供的一种容器,可以用来存储多个数据 集合与数组的区别: 数组的长度固定,集合的长度可变 数组中存储的是同一类型的元素,可以存储基本数据类型值, ...
- Java基础知识强化之集合框架笔记76:ConcurrentHashMap之 ConcurrentHashMap简介
1. ConcurrentHashMap简介: ConcurrentHashMap是一个线程安全的Hash Table,它的主要功能是提供了一组和Hashtable功能相同但是线程安全的方法.Conc ...
- Java SE 核心 I
Java SE 核心 I 1.Object类 在 Java 继承体系中,java.lang.Object 类位于顶端(是所有对象的直接或间接父类).如果一个类没有写 extends 关键字声明其父类, ...
- JAVA基础第四章-集合框架Collection篇
业内经常说的一句话是不要重复造轮子,但是有时候,只有自己造一个轮子了,才会深刻明白什么样的轮子适合山路,什么样的轮子适合平地! 我将会持续更新java基础知识,欢迎关注. 往期章节: JAVA基础第一 ...
随机推荐
- ssm整合的springmvc.xml的配置
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...
- Centos7.2 MQTT的学习之Mosquitto搭建&集群搭建&使用
下载安装包http://mosquitto.org/files/source/ 安装依赖yum install -y gcc gcc-c++ libstdc++-develyum install -y ...
- ActionScript的for循环
actionscript支持的for循环有三种形式: 1.for(初始值;条件;递增) 例如: for(var x:int=1;x<=10;x++) trace(x); trace()会把结果输 ...
- Protel99SE推荐使用英文版
Protel99SE的汉化版功能并不全,最好还是用英文原版,功能是最齐全的.用英文版的软件其实也不难,有限的几个词,习惯就好了.
- python之理解装饰器
装饰器是修改其他函数的函数.好处是可以让你的函数更简洁. 一步步理解这个概念: 一.一切皆对象. def hi(name="yasoob"): return "hi &q ...
- 深入理解JVM(二)JVM内存模型
一.前言 上文讲过了虚拟机的内存划分,即,我们将内存分为线程共享和线程私有. 线程共享的即java堆,和方法区.java堆大家可能都不会陌生:而方法区中包含了常量池,他也被称为永久代.通常方法区也会被 ...
- MySQL知识篇-SQL1
1 SQL是什么? 答:是结构话语言,是一种操作关系型数据库的语言. 2 SQL语言分类? SQL语言 说明 举例 DDL 数据定义语言 create drop DML 数据操作语言 insert ...
- 【VS开发】使用CTabView分割多页卡窗口
一般书中介绍的是使用CSplitterWnd来拆分窗口实现多视图,CSplitterWnd中的CreateClient可以保存其创建的pCreateContext指针,以便子视图共享Document. ...
- 解决 ThinkPHP 5 把控制器下的文件夹当做控制器输出的问题
目录结构: application/home/controller/user_info/User.php 输入路由:/home/user_info/user/index 看样子没毛病,但会报错: 这是 ...
- SpringBoot消息队列之-rabbitMQ
一.概述 1.在大多应用中,我们系统之间需要进行异步通信,即异步消息. 2.异步消息中两个重要概念:消息代理(message broker)和目的地(destination) 当消息发送者发送消息以后 ...