2.06_Python网络爬虫_正则表达式
一:爬虫的四个主要步骤
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (过滤和匹配我们需要的数据,去掉没用的数据)
- 处理数据(按照我们想要的方式存储和使用)
二:什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
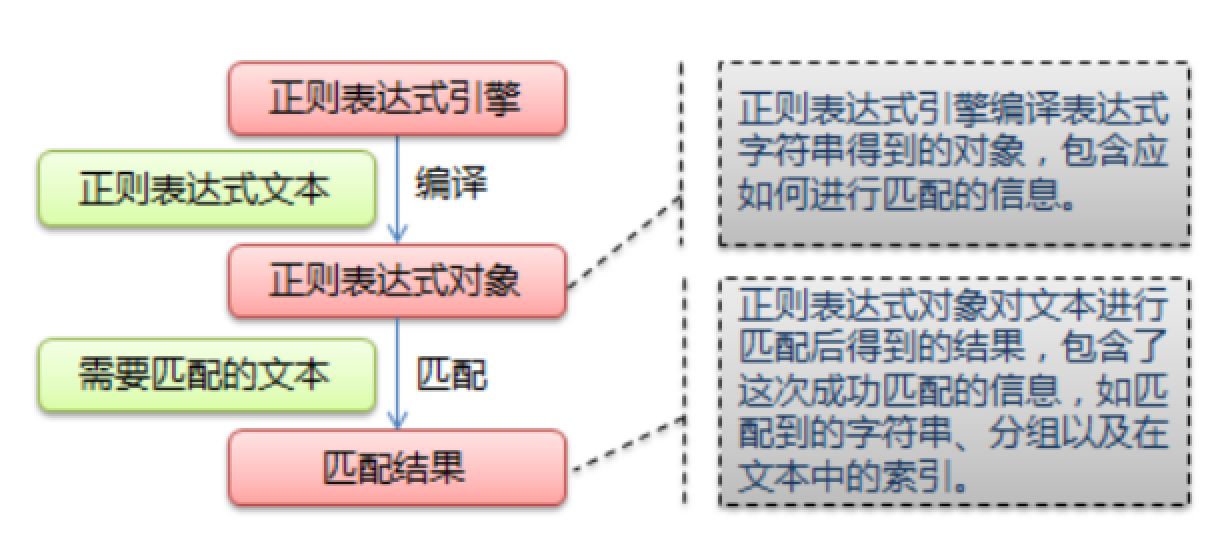
一:正则表达式匹配规则
正则表达式相关注解
(1)数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,
总是尝试匹配尽可能少的字符。
注:我们一般使用非贪婪模式来提取。
贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
示例一 : 源字符串:abbbc
- 使用贪婪的数量词的正则表达式
ab*,匹配结果: abbb。*决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。
- 使用非贪婪的数量词的正则表达式
ab*?,匹配结果: a。即使前面有
*,但是?决定了尽可能少匹配 b,所以没有 b。
示例二 : 源字符串:aa<div>test1</div>bb<div>test2</div>cc
使用贪婪的数量词的正则表达式:
<div>.*</div>匹配结果:
<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个“
</div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个“</div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“<div>test1</div>bb<div>test2</div>”
使用非贪婪的数量词的正则表达式:
<div>.*?</div>匹配结果:
<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个“
</div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“<div>test1</div>”。
(2)反斜杠问题
与大多数编程语言相 同,正则表达式里使用”\”作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”\”,那么使用编程语言表示的正则表达式里将需要4个
反 斜杠”\\\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\\”表示。同样,匹配一个数字的”\\d”可以写成r”\d”。有了原生字符串,妈妈也不用担心是
不是漏写了反斜杠,写出来的表达式也更直观勒。
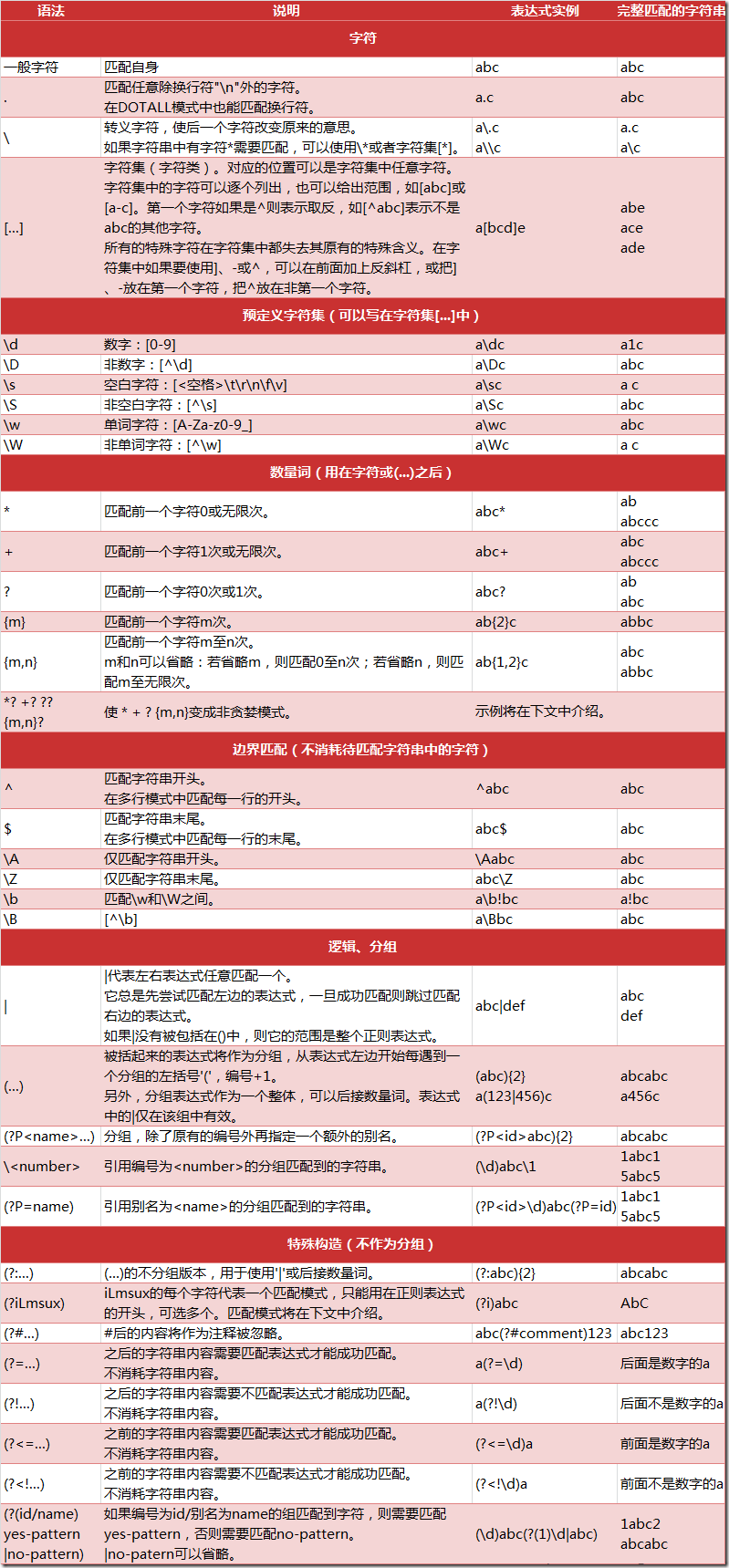
二:Python 的 re 模块
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用Python里的原生字符串对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
re 模块的一般使用步骤如下:
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。- 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re
# 将正则表达式编译成 Pattern 对象,注意\d+前面的r的意思是“原生字符串”
pattern = re.compile(r'\d+')
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:Pattern可以理解为一个匹配模式
match 方法:从起始位置开始查找,一次匹配
search 方法:从任何位置开始查找,一次匹配
findall 方法:全部匹配,返回列表
finditer 方法:全部匹配,返回迭代器
split 方法:分割字符串,返回列表
sub 方法:替换
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,
match 方法默认匹配字符串的头部。当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字 >>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None >>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None >>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0> >>> m.group(0) # 可省略 0
''
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
再看看一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web') >>> print m # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8> >>> m.group(0) # 返回匹配成功的整个子串
'Hello World' >>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11) >>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello' >>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5) >>> m.group(2) # 返回第二个分组匹配成功的子串
'World' >>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11) >>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World') >>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
------------------------------------------------------------------------------------------------------
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
让我们看看例子:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配
>>> m
<_sre.SRE_Match object at 0x10cc03ac0>
>>> m.group()
''
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
<_sre.SRE_Match object at 0x10cc03b28>
>>> m.group()
''
>>> m.span()
(13, 15)
再来看一个例子:
# -*- coding: utf-8 -*- import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 无法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 获得分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span() 执行结果: matching string: 123456
position: (6, 12)
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,我们需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
看看例子:
import re
pattern = re.compile(r'\d+') # 查找数字 result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10) print result1
print result2 执行结果: ['', '']
['', '']
再先看一个栗子:
# re_test.py import re #re模块提供一个方法叫compile模块,提供我们输入一个匹配的规则
#然后返回一个pattern实例,我们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*') #通过partten.findall()方法就能够全部匹配到我们得到的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15") #findall 以 列表形式 返回全部能匹配的子串给result
for item in result:
print item 运行结果: 123.141593
3.15
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
看看例子:
# -*- coding: utf-8 -*- import re
pattern = re.compile(r'\d+') result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10) print type(result_iter1)
print type(result_iter2) print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span()) print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
执行结果:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
看看例子:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
执行结果:
['a', 'b', 'c', 'd']
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
看看例子:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9_]
s = 'hello 123, hello 456' print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组 def func(m):
return 'hi' + ' ' + m.group(2) print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
执行结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
import re title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title) print result
注意到,我们在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
执行结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
使用正则爬去名言网的名言,只获取首页的10条数据

from urllib.request import urlopen
import re def spider_quotes(): url = "http://quotes.toscrape.com"
response = urlopen(url)
html = response.read().decode("utf-8") # 获取 10 个 名言
quotes = re.findall('<span class="text" itemprop="text">(.*)</span>',html)
list_quotes = []
for quote in quotes:
# strip 从两边开始搜寻,只要发现某个字符在当前这个方法的范围内,统统去掉
list_quotes.append(quote.strip("“”")) # 获取 10 个名言的作者
list_authors = []
authors = re.findall('<small class="author" itemprop="author">(.*)</small>',html)
for author in authors:
list_authors.append(author) # 获取这10个名言的 标签
tags = re.findall('<div class="tags">(.*?)</div>',html,re.RegexFlag.DOTALL)
list_tags = []
for tag in tags:
temp_tags = re.findall('<a class="tag" href=".*">(.*)</a>',tag)
tags_t1 = []
for tag in temp_tags:
tags_t1.append(tag)
list_tags.append(",".join(tags_t1)) # 结果汇总
results = []
for i in range(len(list_quotes)):
results.append("\t".join([list_quotes[i],list_authors[i],list_tags[i]])) for result in results:
print(result) #调取方法
spider_quotes()
BeautifulSoup4解析器
如果正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Beautiful Soup,Beautiful Soup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、
Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
1. Beautiful Soup的简介
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,
所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就
不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
2. Beautiful Soup 安装
Beautiful Soup 3 目前已经停止开发,推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 import bs4 。所以这里我们用
的版本是 Beautiful Soup 4.3.2 (简称BS4),另外据说 BS4 对 Python3 的支持不够好,不过我用的是 Python2.7.7,如果有小伙伴用的是 Python3 版本,可以考虑下载
BS3 版本。如果你用的是新版的Debain或Ubuntu,那么可以通过系统的软件包管理来安装,不过它不是最新版本,目前是4.2.1版本
pip install beautifulsoup4如果想安装最新的版本,请直接下载安装包来手动安装,也是十分方便的方法。在这里我安装的是 Beautiful Soup 4.3.2
Beautiful Soup 3.2.1Beautiful Soup 4.3.2
下载完成之后解压
运行下面的命令即可完成安装
sudo python setup.py install
如下图所示,证明安装成功了
3. 解析器安装
pip install lxml
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
4. 开启Beautiful Soup 之旅
4.1:创建 Beautiful Soup 对象
#coding=utf-8
#首先必须要导入 bs4 库
from bs4 import BeautifulSoup html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p> <p class="story">...</p>
""" soup = BeautifulSoup(html_doc, 'html.parser')
#soup = BeautifulSoup(open('index.html')) #可以用本地 HTML 文件来创建对象
#格式化打印
print(soup.prettify()) # <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# The Dormouse's story
# </b>
# </p>
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">
# Elsie
# </a>
# ,
# <a class="sister" href="http://example.com/lacie" id="link2">
# Lacie
# </a>
# and
# <a class="sister" href="http://example.com/tillie" id="link2">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p class="story">
# ...
# </p>
# </body>
# </html>
几个简单的浏览结构化数据的方法:
soup.title
# <title>The Dormouse's story</title> soup.title.name
# u'title' soup.title.string
# u'The Dormouse's story' soup.title.parent.name
# u'head' soup.p
# <p class="title"><b>The Dormouse's story</b></p> soup.p['class']
# u'title' soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a> soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
从文档中找到所有<a>标签的链接:
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
从文档中获取所有文字内容:
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
使用BeautifulSoup4获取名言网首页数据
from urllib.equest import urlopen
from bs4 import BeautifulSoup url = "http://quotes.toscrape.com"
response = urlopen(url) # 初始化一个bs实例
# 对应的response对象的解析器, 最常用的解析方式,就是默认的 html.parser
bs = BeautifulSoup(response, "html.parser") # 获取10个名言
spans = bs.select("span.text")
list_quotes = []
for span in spans:
span_text = span.text
list_quotes.append(span_text.strip("“”")) # 获取10个名言的作者
authors = bs.select("small")
list_authors = []
for author in authors:
author_text = author.text
list_authors.append(author_text) # 获取这10个名言的标签
divs = bs.select("div.tags")
list_tags = []
for div in divs:
tag_text = div.select("a.tag")
tag_list = [ tag_a.text for tag_a in tag_text]
list_tags.append(",".join(tag_list)) #结果汇总
results = []
for i in range(len(list_quotes)):
results.append("\t".join([list_quotes[i],list_authors[i],list_tags[i]])) for result in results:
print(result)
注意:初始化时,加上解析器类型,常用解析器如下:

2.06_Python网络爬虫_正则表达式的更多相关文章
- [Python] 网络爬虫和正则表达式学习总结
以前在学校做科研都是直接利用网上共享的一些数据,就像我们经常说的dataset.beachmark等等.但是,对于实际的工业需求来说,爬取网络的数据是必须的并且是首要的.最近在国内一家互联网公司实习, ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- Java 正则表达式_网络爬虫
首先 需要了解 一些 关于 网络爬虫的 基本知识: 网络爬虫: 所谓的 爬虫 就是一个 应用 程序, 这个 应用 程序 会 获取 网络中的 指定信息(网页 数据). 例如百度: 启动 这个 爬虫 程序 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- iOS开发——网络使用技术OC篇&网络爬虫-使用正则表达式抓取网络数据
网络爬虫-使用正则表达式抓取网络数据 关于网络数据抓取不仅仅在iOS开发中有,其他开发中也有,也叫网络爬虫,大致分为两种方式实现 1:正则表达 2:利用其他语言的工具包:java/Python 先来看 ...
- JAVA基础学习之IP简述使用、反射、正则表达式操作、网络爬虫、可变参数、了解和入门注解的应用、使用Eclipse的Debug功能(7)
1.IP简述使用//获取本地主机ip地址对象.InetAddress ip = InetAddress.getLocalHost();//获取其他主机的ip地址对象.ip = InetAddress. ...
- 黑马程序员——JAVA基础之正则表达式,网络爬虫
------Java培训.Android培训.iOS培训..Net培训.期待与您交流! ------- 正则表达式: 概念:用于操作字符串的符合一定规则的表达式 特点:用于一些特定的符号来表示一些代码 ...
- Python 网络爬虫 009 (编程) 通过正则表达式来获取一个网页中的所有的URL链接,并下载这些URL链接的源代码
通过 正则表达式 来获取一个网页中的所有的 URL链接,并下载这些 URL链接 的源代码 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 ...
- python网络爬虫之解析网页的正则表达式(爬取4k动漫图片)[三]
前言 hello,大家好 本章可是一个重中之重,因为我们今天是要爬取一个图片而不是一个网页或是一个json 所以我们也就不用用到selenium模块了,当然有兴趣的同学也一样可以使用selenium去 ...
随机推荐
- Packages window(包窗口)
使用Unity Package Manager(在Unity的顶层菜单中:Window > Package Manager)查看可以安装或已安装在Project中的软件包.此外,您可以使用此窗口 ...
- 十步学习法 -- 来自<<软技能>>一书的学习方法论
<<软技能>>第三篇“学习”,作者讲述了自己的学习方法:十步学习法.下面我用编程语言的方式来介绍. 十步学习法 伪代码介绍 # **这一步的目的不是要掌握整个主题,而是对相关内 ...
- Fabric docker-compose volumes配置解析
chaincode: container_name: chaincode image: hyperledger/fabric-ccenv tty: true environment: - GOPATH ...
- 最新 58集团java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.58集团等10家互联网公司的校招Offer,因为某些自身原因最终选择了58集团.6.7月主要是做系统复习.项目复盘.Leet ...
- 最新 拼多多java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.拼多多等10家互联网公司的校招Offer,因为某些自身原因最终选择了拼多多.6.7月主要是做系统复习.项目复盘.LeetCo ...
- Vue的作用域插槽
一.通常情况下都是父组件传递数据给子组件进行展示的(无法改变子组件的展示方式):而作用域插槽允许子组件通过slot向父组件传递数据,类似React中的“以函数为子组件”,由父组件决定渲染的内容(包含绑 ...
- mysql根据时间统计数据语句
select FROM_UNIXTIME(`createtime`, '%Y年%m月%d日')as retm,count(*) as num from `user` GROUP BY retm se ...
- redis数据库安装
一. 简单介绍: REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统. Redis是一个开源的使用A ...
- JS实现级联菜单
是首先应该添加两个下拉列表并设置id属性来方便操作: <select id="country"> <option>国家</option> < ...
- 关于SpringMVC中的转发与重定向的说明
写的非常详细,参看该地址:https://www.zifangsky.cn/661.html 总结: 1.请求转发:url地址不变,可带参数,如?username=forward 2.请求重定向:ur ...