mysql数据库学习
1,服务端和客户端
MySQL 包括服务端和客户端,服务端是MySQL server,客户端包括命令行客户端和图形用户客户端;
命令行客户端:mysql,mysqladmin,mysqldump (都存在于C:\programs\MySQL\MySQL Sever n.n\bin或自定义安装目录下,配置环境变量后可直接在cmd启动)
图形用户客户端:MySQL Adminstrator, MySQL Query Browser, phpMyAdmin及其他软件等
2,命令行客户端
2.1 mysql: 向MySQL Sever发送用户输入的命令,并显示MySQL Sever返回的结果。
a,连接MySQL Sever : mysql -u root -p

命令参数 :-p(小写)表示需要密码登陆MySQL Server; -h computername 远程MySQL Server的电脑host名;-protocol = name 远程连接协议;-P(大写),连接端口 号,默认3306; -default-character-set=name 设置mysql和MySQL Server之间的数据格式; databasename 可以指定连接的数据库。
示例命令 : mysql -u root -p -h hostname -default-character-set=utf8 databsename


b, show databases; 显示所有数据库
use dbname; 进入数据库dbname
show tables; 显示该数据库的所有表格
c,其他常用命令(尽量以冒号结尾)

\h; 或者 help;

2.2 mysqladmin:执行一些管理任务,创建和删除数据库,修改密码等。

2.3 mysqldump : 用来进行数据备份等
备份命令

(将数据库mybbs1备份到文件blogback.sql)

下面命令利用备份文件恢复数据库
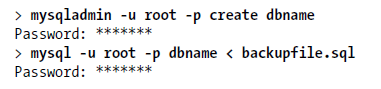
或者如下命令:
use dbname;
source /home/zack/backfile.sql;
3.数据库表设计(数据类型)
Interger 整数: TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT, SERIAL

Floating-point number 浮点数: FLOAT, DOUBLE

Fixed-point number 定点数: DECIMAL

Date and time 日期和时间: DATE, TIME, DATETIME, TIMESTAMP


日期格式验证设置: (DATE)

Character string 字符窜:CHAR, VARCHAR, TEXT

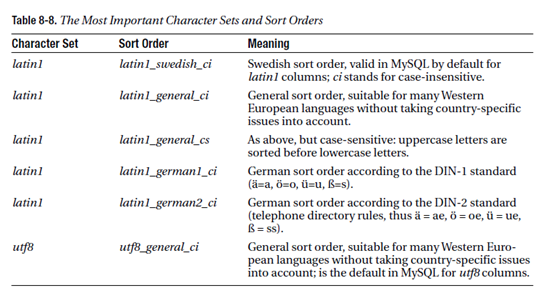
字符串格式设置和排序方式设置: 对于类型为字符串的列,可以设置字符格式和排序方式
CHARACTER SET charatcterset_name
COLLATE order_name
常见字符格式和排序方式
Binary data 二进制数据:BIT, TINYBLOB, BLOB, MEDIUM BLOB, LONGBLOB
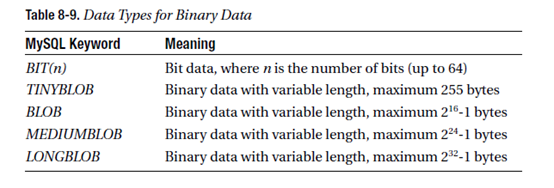
其他数据类型:ENUM, SET, GEOMETRY, POINT

可用选项和属性
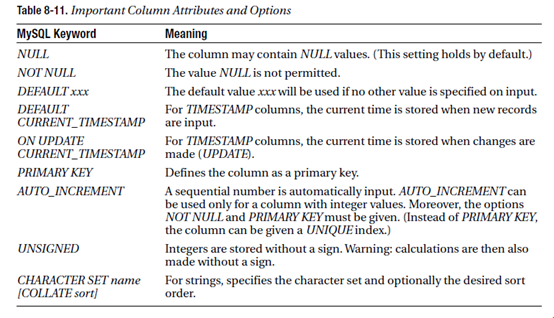
4,sql语句 (structured query language)
Data manipulate language(DML): SELECT, UPDATE, DELETE, INSERT
Data definition language(DDL): CREATE TABLE, ALTER TABLE, DROP TABLE
Data control language(DCL): GRANT, REVOKE
4.1 Data definition language(DDL):创建数据库,数据表,改变数据表设计和删除表等
创建数据库:
CREATE DATABASE mydb; (或者用mysqladmin: mysqladmin -u root -p create mydb)
CREATE DATABASE IF NOT EXISTS mydb;(存在时不会报错,显示一条警告,通过SHOW WARNINGS;可以看到具体警告内容)
CREATE DATABASE mydb DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
(设置数据库默认数据格式,以及排序方式;COLLATE, 限定字符窜的排序比较,以_ci 表示大小写不敏感,以_cs 表示大小写敏感,以_bin表示用编码值进行比较)
改变数据库编码格式:ALTER DATABASE dbname CHARACTER SET gbk
查看数据库格式:
SHOW CREATE DATABASE dbname; 查看数据库创建时的格式
进入数据库:
USE mydb;
SELECT DATABASE(); 查看当前进入的数据库
创建表格:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbname(
colname1 coltype coloptions referrence,
colname2 coltype coloptions referrence,
[index1, index2],
[KEY],
[PRIMARY KEY]
)[ENGINE=MyISAM|InnoDB|Heap][DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci]
示例:

(CONSTRAINT titles_ibfk_1 FOREIGN KEY : CONSTRAINT给该外键约束条件起名字titles_ibfk_1,方便后面删除, 不起名时可以不用CONSTRAINT)
通过查找的数据创建表格:
CREATE TABLE newtable SELECT * FROM titles WHERE publID=1;
数据库表格间复制

查看表格:
SHOW CREATE TABLE tbname;
DESC tbname;
SHOW COLUMNS FORM titles;
创建索引(create index):
下面命令给titles表中的title列增加索引 (索引名称为idxtitle),有三种方式如下:
1,创建表格时指定:
CREATE TABLE titles(
title varchar(100),
publID INT,
INDEX idxtitle (title)
);
2,创建索引:
CREATE INDEX idxtitle ON titles(title);
3,修改表设计,添加索引
ALTER TABLE titles ADD INDEX idxtitle (title);
改变表格设计(ALTER TABLE):
增加列:ALTER TABLE tablename ADD newcol coltype coloption [FIRST | AFTER existingcol];
改变列: ALTER TABLE tablename CHANGE oldcolname newcolname coltype coloptions;
删除列; ALTER TABLE tablename DROP colname;
增加索引:ALTER TABLE tablename ADD PRIMARY KEY (indexcols..);
ALTER TABLE tablename ADD INDEX [indexname] (indexcols..);
ALTER TABLE tablename ADD UNIQUE [indexname] (indexcols..);
ALTER TABLE tablename ADD FULLTEXT [indexname] (indexcols..);
删除索引:ALTER TABLE tablename DROP PRIMARY KEY ;
ALTER TABLE tablename DROP INDEX [indexname] ;
ALTER TABLE tablename DROP FOREIGN KEY [indexname] ;
增加外键关系:ALTER TABLE tablename ADD FOREIGN KEY [idxname] (column1) REFERENCES table2 (column2);
改变表格字符格式: ALTER TABLE tablename CONVERT TO CHARACTER SET charsetname;
改变表格类型(引擎):ALTER tablename TABLE ENGINE typename;
删除数据库或表格:DROP TABLE tablename;
DROP DATABASE dbname;
DROP DATABASE IF EXISTS dbname;
show commands :返回该用户权限下能得到的所有数据(数据库和表格)
https://www.cnblogs.com/SQL888/p/5750161.html

show create table tbname; 显示数据表结构
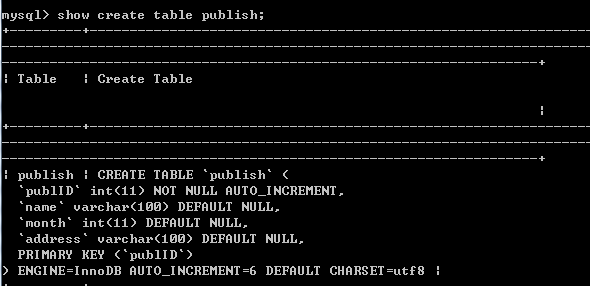
查看当前的数据格式设置:

关于数据格式设置:


4.2 Data manipulate language(DML): 对表格的增删改查
a, SELECT :从表格查找数据
SELECT * FROM table_name 查找所有数据
SELECT column_name FROM table_name 查找某一列数据
计算COUNT:
SELECT COUNT(column_name) FROM table_name 某一列的数据个数(行数)
SELECT COUNT(DISTINCT column_name) FROM table_name 某一列不重复的数据个数
SELECT COUNT(*) / COUNT(DINSTINCT column_name) FROM table_name 两数据相除
限定返回数量;
SELECT colname FROM tbname LIMIT 2 返回前两条数据
SELECT colname FROM tbname LIMIT 2, 2 返回第二条开始的前两条 (第三行和四行数据)
SELECT SQL_CALC_FOUND_ROWS column_name FROM table_name LIMIT 3 ; SELECT FOUND_ROWS();先咨询第一条命令返回前三条数据,再执行第二条 时能返回总行数 (相当于SELECT COUNT(*) FROM table_name )
排序:
SELECT colname FROM tbname ORDER BY colname;
SELECT colname FROM tbname ORDER BY colname DESC; 反序排列
条件查询:
SELECT authname FROM TABLE authors WHERE authname>=’M’ ; 名字开头字母介入L-Z
SELECT authname FROM TABLE authors WHERE authname LIKE ‘%er%’ ; ( % 匹配任意数量的字符串, 返回作者名字中包含er的
SELECT authname, authID FROM authors WHERE authID IN (2,7,12);
多表连接查询:
两张表连接 (两张表都有pubID)
SELECT title, publisher FROM titles, publishers WHERE titles.pubID = publishers.pubID
SELECT title, publisher FROM titles LEFT JOIN publishers ON titles.pubID = publishers.pubID
SELECT title, publisher FROM titles LEFT JOIN publishers USING (pubID)
三张表或多表查询:
titles表和authors表 之间为多对多关系,通过第三张表rel_title_author定义:SELECT title, authname FROM titles, rel_title_author, authors WHERE titles.titleID= rel_title_author.titleID AND authors. authID = rel_title_author. authID ORDER BY title
Publishers 和 titles 为一对多关系,Titles和authors 之间为多对多关系,通过第三张表rel_title_author定义,先通过publish和title联系,再通过rel_title_author和authors联系:SELECT DISTINCT publname, authname FROM publishers, titles, rel_title_author, authors WHERE titles.titleID= rel_title_author.titleID AND authors. authID = rel_title_author. authID AND titles.pubID = publishers.pubID ORDER BY publname, authname (DISTINCT 去除重复的数据记录)
Left join, Right join, Natural join: 连接表
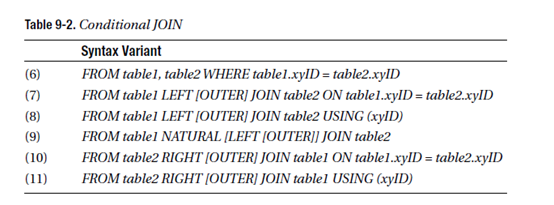
titles 表和publish表的数据如下,分别进行Left join, Right join, Natural join


Left join: 以table1 的数据列xyID为依据进行连接,如果table1中的行数较多时,table2用null补全; (以titles表的publID列数据为依据连接)
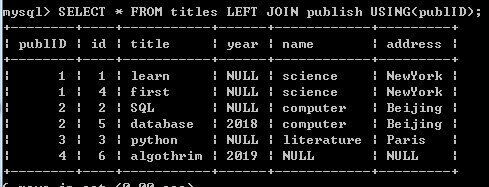
Right join: 以table2的数据列xyID,如果table2中的行数较多时,table1用null补全 (以publish表的publID列数据为依据连接)
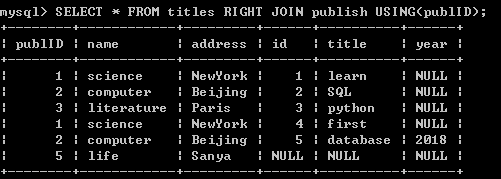
Natural join: 两张表有相同名称的数据列,将该列进行合并连接(数据类型不一致能转换时可以连接,不能转换时报错)

查询结果连接:UNION, UNION ALL(UNION会自动去除重复的数据,UNION ALL 不去除)
将查询到的结果合并(一列中),也可以连接不同表的查询结果,但两张表必须有相同的列数,且数据类型相同或可以转换
SELECT * FROM authors WHERE authname LIKE ‘b%’ UNION SELECT * FROM authors WHERE authname LIKE ‘g%’
对每一个查询用括号,可以加一些其他选项命令(下面命令显示5行数据)
(SELECT * FROM tab1 ORDER BY col1 LIMIT 10) UNION (SELECT * FROM tab2 ORDER BY col2 LIMIT 10) ORDER BY authname LIMIT 5
分组查询:GROUP BY
聚集函数: COUNT, SUM, MIN, MAX
单表,按publID分组,查询每一个publID 对应的title数量: (COUNT(title) AS num :返回结果中,COUNT(title)这一列的名字为num)

跨表,按书籍类名来分类,并计算每一个类别下书籍总数(计算title)
SELECT catName, COUNT(title) AS numofitem FROM categories, titles WHERE titles.catID=categories.catID GROUP BY catName ORDER BY catName
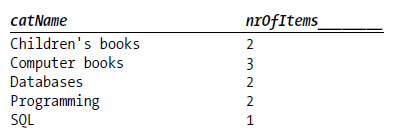
按多列分组 (GROUP BY for several columns),下面命令查找一种语言和一种书籍类别下的书籍数量


下面的命令,对于不含有书籍数据的书籍类别也进行了统计(left join的特性)
SELECT catName, COUNT(title) AS numofitem FROM categories LEFT JOIN ON titles.catID=categories.catID GROUP BY catName ORDER BY numofitem DESC
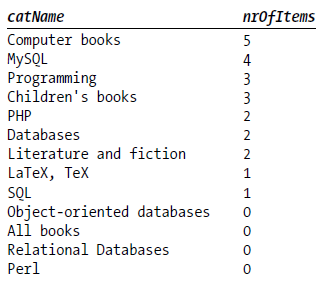
GROUP BY WITH ROLLUP: 对于没有的数据项用NULL填充
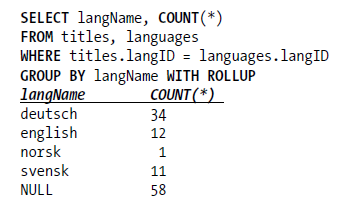
GROUP_CONCAT: 将多项数据(一对多)拼接到一列 (HAVING cnt>1 总数大于1的)
SELECT title, GROUP_CONCAT(authname ORDER BY authname SEPARATOR ‘,’) AS authors, COUNT(authors.authID) AS cnt FROM titles, rel_title_author, authors WHERE titles.titleID= rel_title_author.titleID. AND authors. authID = rel_title_author. authID GROUP by titles.titleID HAVING cnt>1 ORDER BY title


b, INSERT INTO :插入数据
INSERT INTO titles (title, year) VALUES (‘MySQL’, 2005)
插入所有数据时可以不带列标题(包括NULL,AUTO_INCREMENT):

对于NULL,DEFAULT, AUTO_INCREMENT 可以不插入:
CREATE TABLE person(id INT, name VARCHAR(16) DEFAULT 'ZACK');
INSERT INTO person(id) VALUES(i); (name会自动赋值)
插入多行数据
INSERT INTO table(column1, column2, column3) VALUES (1, 2, 3), (4, 5, 6), (7, 8, 9)
插入多对多或外键关系数据库,需要自己手动创建 (SELECT LAST_INSERT_ID()返回上次插入行数据的自增ID值)
下面命令,利用publID,在titles表中插入一行数据,建立外键关系,再利用authID,在rel_title_author表中插入三条数据,建立多对多关系

c,UPDATE SET:更改数据记录
UPDATE tablename SET column1=value1, column2=value2 WHERE columnID=n (没有WHERE语句时column1, column2两列所有数据都更改)
UPDATE语句中支持简单的计算: UPDATE titles SET price=price*1.05;
d,DELETE FROM: 删除数据记录
DELETE FROM titles WHERE titleID=8 (没有where时整张表数据会被删除,保留表定义和index) (删除整张表 DROP titles)
多表关联删除:
仅删除titles表数据

titles, rel_title_author,authors三张表数据都删除

若上面两条命令在删除时报错:外键关联约束。 则其相应的解决方法如下:
方法一:先设置 SET FOREIGN_KEY_CHECKS=0, 然后执行上述删除命令,最后再设置SET FOREIGN_KEY_CHECKS=1
方式二:在定义外键时设置约束规则, ON DELETE CASCADE (关联数据会自动删除)

delete结合LIMIT使用
仅删除排序后的第一条数据:DELETE FROM authors ORDER BY authname DESC LIMIT 1
删除和更新时的外键约束:RESTRICT (默认), NO ACTION, CASCADE, SET NULL
RESTRICT/ NO ACTION: 当外键约束关系设置为RESTRICT/ NO ACTION时,删除或更新主表中的外键记录时,不允许删除
CASCADE:删除或更新主表中的外键记录时,外键关系所在子表的对应记录也删除
SET NULL:删除或更新主表中的外键记录时,外键关系所在子表的对应记录设置为NULL(要求该字段允许设置为NULL)
5,常见函数使用
5.1 字符窜处理函数
CONCAT(str1, ' ', str2): 将字符窜str1 和 str2 用指定的符号连接起来
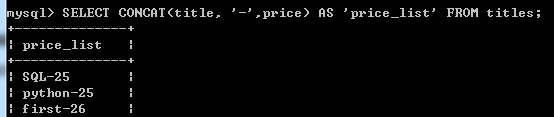
SUBSTR(string, pos, n) 截取返回的string中pos到n的字符串:SELECT SUBSTR(title, 1, 10) FROM titles;
IF(a, b , c) : a=true时返回b,否则返回c
SELECT IF(CHAR_LENGTH(title)>30,CONCAT(LEFT(title, 20), '&',RIGHT(title,5)), title) FROM titles AS shorttitle
(CHAR_LENGTH(): 返回字符个数; LENGTH(): 返回字节数; LEFT(title, 20): 从最左边开始,返回20个字符; RIGHT(title,5):从最右边开始,返回5个字符)
case分支

CONVERT(string using charset):改变字符串的数据格式, SELECT CONVERT(title USING utf8) FROM titles
下面两条命令为表格增加一列title_utf8,数据和title相同,格式不同

5.2 日期和时间:
下面Ts 列为TIMESTAMP或 DATETIME数据类型时,命令都适用
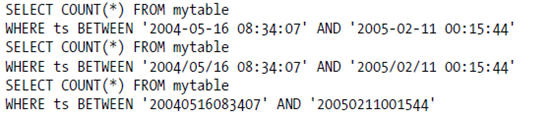
MONTH(), YEAR()函数返回TIMESTAMP, DATETIME数据的年月, SELECT COUNT(*), MONTH(ts) AS m FROM titles WHERE YEAR(ts)=2018 GROUP BY m;
DATE_FORMAT()函数,格式化日期, SELECT COUNT(*), DATE_FORMAT(ts,'%Y-%M') AS ym FROM titles WHERE YEAR(ts)=2018 GROUP BY ym;
日期和时间计算:

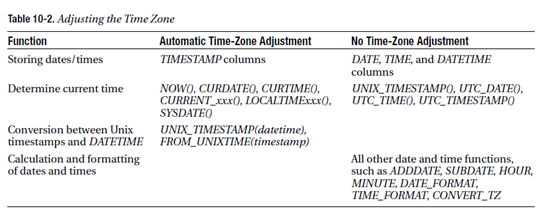
时区:
6.sql练习题
http://www.cnblogs.com/wupeiqi/p/5748496.html
mysql数据库学习的更多相关文章
- MySQL数据库学习笔记(十二)----开源工具DbUtils的使用(数据库的增删改查)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- MySQL数据库学习笔记(十)----JDBC事务处理、封装JDBC工具类
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- MySQL数据库学习笔记(九)----JDBC的ResultSet接口(查询操作)、PreparedStatement接口重构增删改查(含SQL注入的解释)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/4 ...
- Mysql数据库学习笔记之数据库索引(index)
什么是索引: SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间. 聚集索引:该索引中键值的逻辑顺序决定了表中相应行的物 ...
- MySQL数据库学习: 01 —— 数据库的概述
壹 概述 一 了解SQL 1.1 数据库基础 1.1.1 什么是数据库 数据库(database)保存有组织的数据的容器(通常是一个文件或一组文件). 易混淆:人们常常用“数据库”这个词语来代表他们使 ...
- MYSQL数据库学习笔记1
MYSQL数据库学习笔记1 数据库概念 关系数据库 常见数据库软件 SQL SQL的概念 SQL语言分类 数据库操作 创建数据库 查看数据库的定义 删除数据库 修改数据库 创建表 数据类型 约束 ...
- mysql数据库学习目录
前面的话 对于前端工程师来说,数据库并不是主要技能点,但是基本的增删改查操作还是需要了解的.小火柴将mysql数据库的学习记录整理如下 目录 前端学数据库之基础操作 前端学数据库之数据类型 前端学数 ...
- mysql数据库学习(一)--基础
一.简介 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 R ...
- MySQL数据库学习笔记<一>
MySQL基本概念以及简单操作 一.MySQL MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系 ...
- mysql数据库学习小结
数据库的学习可以从以下几个层次了解掌握,这样思路清晰后后面不管怎么变化都可以随时应变: 1.mysql基础知识 2.操作数据库的方法,增 删 改 查 3.jdbc连接数据库,工作原理 难点重点,如:P ...
随机推荐
- 使用百度echarts仿雪球分时图(三)
这章节将完成我们的分时图,并使用真实的数据来进行展示分时图. 一天的交易时间段分为上午的09:30~11:30,下午的13:00~15:00两个时间段,因为分时间段的关系,数据是不连续的,所以会先分为 ...
- requests模块发送数据
通过json dumps发送 import requests import json def agent(): """ 执行命令采集硬件信息 将执行的信息发送给API : ...
- asp.net 自动检测缓存内容是否变化
1 使用cache.Insert方法时,新建一个System.Web.Caching.CacheDependency对象,告诉缓存,当缓存的内容发生变化时,将删除缓存,并重新缓存 using Syst ...
- 【坑】Spring中抽象父类属性注入,子类调用父类方法使用父类注入属性
运行环境 idea 2017.1.1 spring 3.2.9.RELEASE 需求背景 需要实现一个功能,该功能有2个场景A.B,大同小异 抽象一个抽象基类Base,实现了基本相同的方法BaseMe ...
- Django ORM常用的字段和参数
ORM 常用字段 AutoField int自增列,必须填入参数 primary_key=True.当model中如果没有自增列,则自动会创建一个列名为id的列. IntegerField 一个整数类 ...
- linux基础1_文件类型、拓展名、目录配置
命令ls -l,显示的第一个属性代表了这个档案的档案类型 [d]:目录 [-]:普通文件 [l]:连接文件 [b]:存储数据以供系统访问的接口设备 [c]:串行接口的端口设备,例如键盘.鼠标 [s]: ...
- SQL Server 排序规则的影响
目录 SQL Server 排序规则 影响 效果演示 更改数据库排序规则 服务器级排序规则 数据库级排序规则 列级排序规则 查询时指定规则 建议 使用 Unicode 数据类型 使用二进制排序规则 [ ...
- 异步函数Demo
private static async Task<String> IssueClientRequestAsync(string serverName, string message) { ...
- React给state赋值的两种写法
如果你看过React的官方文档,就会对怎么给局部state赋值有一定的了解.如下代码: class Test extends React.Component { constructor(props) ...
- sql server 安装
第一次安装sql server是2016版本,因为[win7-64版系统配置比较低],所以不成功. 第二次安装2012版,在[数据库引擎配置]的时候,选择的是[添加当前用户],以及后续需要添加用户的时 ...