java集合(List,Set,Map)详细总结
一,集合的由来:
数组是长度是固定的,当添加的元素超过数组的长度时需要对数组重新定义,太麻烦了,java内部给我们提供了集合类,能存储任意对象,长度是可以改变的,随着元素的增加而增加,随着元素的减少而减少。
1.1.1,数组与集合的区别:
数组既可以存储引用数组类型,又可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地值。 集合只能存储引用数据类型(对象),集合中也可以存储基本数据类型,但是在存储的时候会自动装箱变成对象。
1.2.1,集合的结构:
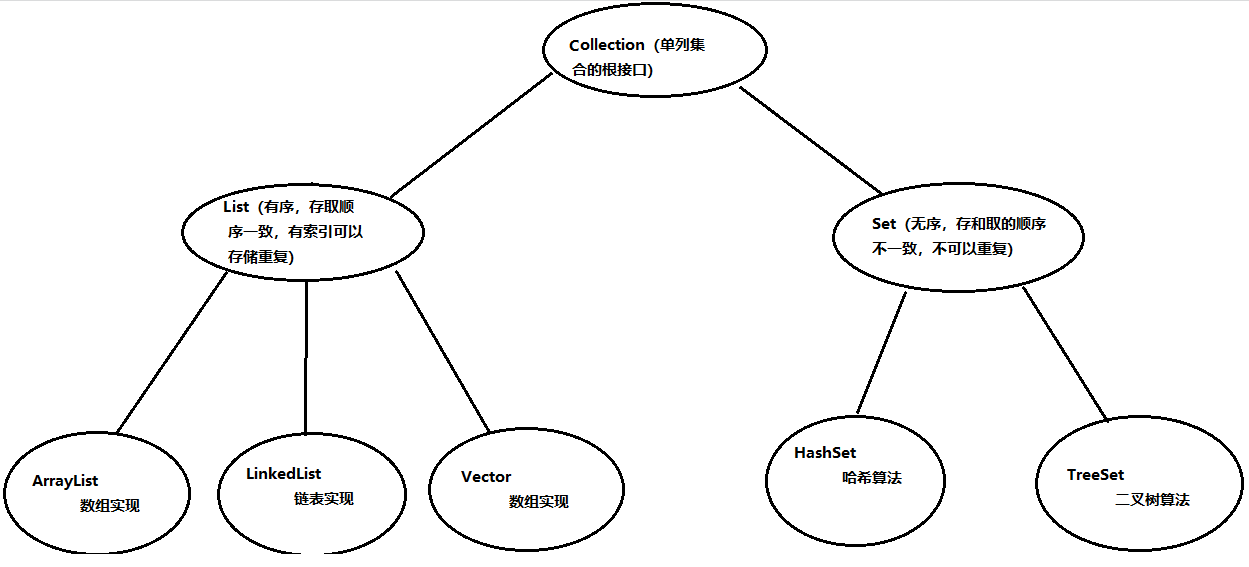
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
├Set
│├SortedSet
│├TreeSet
│└HashSet
├Map
│├Hashtable
│├HashMap
│└WeakHashMap
Collection接口介绍:
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
Iterator it = collection.iterator(); // 获得一个迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一个元素
}
迭代器原理:
迭代器是对集合进行遍历,而每一个集合内部的存储结构都是不同的,所以每一个集合存和取都是不一样,那么就需要在每一个类中定义hasNext()和next()方法,这样做是可以的,但是会让整个集合体系过于臃肿,迭代器是将这样的方法向上抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做的好处有二,第一规定了整个集合体系的遍历方式都是hasNext()和next()方法,第二,代码有底层内部实现,使用者不用管怎么实现的,会用即可
1.2.2,List介绍:
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
和下面要提到的Set不同,List允许有相同的元素。
除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,返回一个ListIterator接口,和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
实现List接口的常用类有LinkedList,ArrayList,Vector和Stack。
//List数据遍历,以及基本操作
List list =new ArrayList();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.set(2, "a"); //根据索引,往2索引Set一个值
System.out.println(list.get(2)); //根据索引获取结果
Object remove = list.remove(100); //删除索引,将删除的元素返回
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i)); //获取索引中的值
}
}
1.2.3,LinkedList介绍:
LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可 被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
//LinkedList的基本使用
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.addFirst("a");
list.addFirst("b");
list.addFirst("c"); //添加数据先进先出的模式
list.addFirst("d");
list.addLast("e"); //往尾部添加数据
// System.out.println(list); //查看全部数据
System.out.println(list.getFirst()); //查看头部数据
System.out.println(list.getLast()); //查看尾部数据
System.out.println(list.removeFirst()); //删除头部添加的数据
System.out.println(list.removeLast()); //删除尾部添加的数据
System.out.println(list.get(1));
System.out.println(list);
1.2.4,ArrayList介绍:
ArrayList实现了可变大小的数组。
它允许所有元素,包括null。ArrayList没有同步。
size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。 当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
public static void main(String[] args) {
ArrayList list=new ArrayList();
list.add(new Student("jy",17)); //数据添加
list.add(new Student("jy",17));
list.add(new Student("jj",171));
list.add(new Student("jj",171));
//list.add(5, new Student("jj",171));// 在集合的某一个位置添加对象
// list.addAll(2, list2); // 在集合的某一个位置添加一个集合
// list.remove(2); //根据索引删除
//list.set(2, new Student("jj",171)); //修改
//Object[] array = list.toArray(); //转数组
//使用迭代器
Iterator it=list.iterator();
it=list.iterator();
//遍历集合
while (it.hasNext()) {
Student type = (Student) it.next();
System.out.println("name:"+ type.getName() + "---> Age:" + type.getAge());
}
}
1.2.5,Vector介绍:
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。
Vector 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
和ArrayList不同,Vector中的操作是线程安全的。(Vector功能都不及ArrayList与LinkedList好用,了解就好)
public static void main(String[] args) {
Vector v = new Vector();
v.addElement("1");
v.addElement("11");
v.addElement("111");
v.addElement("1111");
v.addElement("11111");
Enumeration en =v.elements(); //获取枚举,遍历
while(en.hasMoreElements()){ //判断集合中是否有元素
System.out.println(en.nextElement()); //获取集合中的元素
}
}
1.3.1,总结:
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构)
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
Vector和ArrayList的区别:
Vector是线程安全的,效率低
ArrayList是线程不安全的,效率高
共同点:都是数组实现的
ArrayList和LinkedList的区别:
ArrayList底层是数组结果,查询和修改快
LinkedList底层是链表结构的,增和删比较快,查询和修改比较慢
List有三个儿子,我们到底使用谁呢?
查询多用ArrayList
增删多用LinkedList
如果都多ArrayList
二,Set介绍:
父接口 Collection
2.特点 唯一 无序(插入顺序跟遍历顺序不一致,没下标)
唯一:Set集合中不允许出现重复的元素,如果向Set集合中存储重复的元素是无效的,但不会报错
无序:Set集合不会维护集合中元素的插入顺序,即不存在下标或索引
3.Set接口中的功能方法 (Set接口中没有自有方法,全部继承自Collection接口)
4.凡是带有下标的方法都不支持
1.4.1,HashSet介绍:
我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象
如果没有哈希值相同的对象就直接存入集合
如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
HashSet<String> hs = new HashSet<String>(); //创建HashSet对象
boolean b1 = hs.add("a");
boolean b2 = hs.add("a"); //当向set集合中存储重复元素的时候返回为false
hs.add("a");
hs.add("b");
hs.add("c");
hs.add("d"); //HashSet的继承体系中有重写toString的方法
System.out.println(hs);
System.out.println(b1);
System.out.println(b2);
for (String string : hs) { //只要用迭代器的,就可以使用增强for循环遍历
System.out.println(string);
}
}
1.4.2,LinkedHashSet介绍:
底层是链表实现的,时Set集合唯一一个能保证怎么存就怎么取的集合对象
因为HashSet的子类,所以也是保证元素的唯一的,与HashSet的原理一样
public static void main(String[] args) {
LinkedHashSet<String> lhs = new LinkedHashSet<String>();
lhs.add("a");
lhs.add("aa");
lhs.add("aaa");
lhs.add("aaa");
lhs.add("a");
System.out.println(lhs);
}
1.4.3,TreeSet介绍:
TreeSet存储Integer类型的元素并遍历
当compareTo方法返回()的时候集合中只有一个元素
当compareTo方法返回正数的时候集合回怎么存就怎么取
当compareTo方法返回符数的时候集合回倒序存储
public static void main(String[] args) {
//按照字符串长度进行排序
TreeSet<String> ts = new TreeSet<String>(new ComareByLen());
ts.add("aaa"); //Comparator c = new Comparator();
ts.add("aa");
ts.add("aaaa");
ts.add("aaaaa");
System.out.println(ts);
}
class ComareByLen implements Comparator<String>{
@Override
public int compare(String o1, String o2) {
int num = o1.length() - o2.length(); //定义一个比较器
return num == 0 ? o1.compareTo(o2):num;
}
}
1.4.4,总结:
Set:存取无序,无所索引,不可以重复
HashSet:底层是哈希算法实现
LinkedHashset:底层是链表实现的,但是也是可以保证元素唯一,和Hashset原理一样
TreeSet:底层是二叉树算法实现
一般在开发中的时候不需要对存储元素进行排序,所以开发的时候大多HashSet,HaShSet的效率比较高
TreeSet在面试的时候问的比较多,问你集中排序方式,和集中排序方式的区别
并发修改异常:
1.在遍历一个集合时,如果需要删除一个数据,那么会容易出现并发修改异常
2.谁遍历,就让谁删除(例如在遍历Set的时候不允许删除Set(迭代器是单独一个线程,涉及到数据同步的问题),可以通过迭代器的remove方法来解决)
3.就必须使用原始的迭代器代码
三,Map介绍:
1.5.1,Map的子类介绍:
|--Hashtable底层是哈希表数据结构,是线程同步的。不可以存储null键,null值。
|--HashMap:底层是哈希表数据结构,是线程不同步的。可以存储null键,null值。替代了Hashtable.
|--TreeMap:底层是二叉树结构,可以对map集合中的键进行指定顺序的排序。
1.5.2,Map与Collection的区别:
Map集合存储和Collection有着很大不同,
Collection一次存一个元素;Map一次存一对元素。
Collection是单列集合;Map是双列集合。
Map中的存储的一对元素:一个是键,一个是值,键与值之间有对应(映射)关系。
特点:要保证map集合中键的唯一性。
1.5.3,Map的方法大全:
1,添加。
put(key,value):当存储的键相同时,新的值会替换老的值,并将老值返回。如果键没有重复,返回null。
void putAll(Map);
2,删除。
void clear():清空
value remove(key) :删除指定键。
3,判断。
boolean isEmpty():
boolean containsKey(key):是否包含key
boolean containsValue(value) :是否包含value
4,取出。
int size():返回长度
value get(key) :通过指定键获取对应的值。如果返回null,可以判断该键不存在。当然有特殊情况,就是在hashmap集合中,是可以存储null键null值的。
Collection values():获取map集合中的所有的值。
5,想要获取map中的所有元素:
原理:map中是没有迭代器的,collection具备迭代器,只要将map集合转成Set集合,可以使用迭代器了。之所以转成set,是因为map集合具备着键的唯一性,其实set集合就来自于map,set集合底层其实用的就是map的方法。
★ 把map集合转成set的方法:
Set keySet();
Set entrySet();//取的是键和值的映射关系。
Entry就是Map接口中的内部接口;
为什么要定义在map内部呢?entry是访问键值关系的入口,是map的入口,访问的是map中的键值对。
---------------------------------------------------------
1.5.4,遍历Map的几种方式:
取出map集合中所有元素的方式一:keySet()方法。
可以将map集合中的键都取出存放到set集合中。对set集合进行迭代。迭代完成,再通过get方法对获取到的键进行值的获取。
Set keySet = map.keySet();
Iterator it = keySet.iterator();
while(it.hasNext()) {
Object key = it.next();
Object value = map.get(key);
System.out.println(key+":"+value);
}
--------------------------------------------------------
取出map集合中所有元素的方式二:entrySet()方法。
Set entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while(it.hasNext()) {
Map.Entry me = (Map.Entry)it.next();
System.out.println(me.getKey()+"::::"+me.getValue());
}
--------------------------------------------------------
1.5.5,使用集合的技巧:
看到Array就是数组结构,有角标,查询速度很快。
看到link就是链表结构:增删速度快,而且有特有方法。addFirst; addLast; removeFirst(); removeLast(); getFirst();getLast();
看到hash就是哈希表,就要想要哈希值,就要想到唯一性,就要想到存入到该结构的中的元素必须覆盖hashCode,equals方法。
看到tree就是二叉树,就要想到排序,就想要用到比较。
比较的两种方式:
一个是Comparable:覆盖compareTo方法;
一个是Comparator:覆盖compare方法。
LinkedHashSet,LinkedHashMap:这两个集合可以保证哈希表有存入顺序和取出顺序一致,保证哈希表有序。
1.5.6,集合什么时候用?
当存储的是一个元素时,就用Collection。当存储对象之间存在着映射关系时,就使用Map集合。
保证唯一,就用Set。不保证唯一,就用List。
------------------------------------------------------------------------------------------------
Collections:它的出现给集合操作提供了更多的功能。这个类不需要创建对象,内部提供的都是静态方法。
静态方法:
Collections.sort(list);//list集合进行元素的自然顺序排序。
Collections.sort(list,new ComparatorByLen());//按指定的比较器方法排序。
class ComparatorByLen implements Comparator<String>{
public int compare(String s1,String s2){
int temp = s1.length()-s2.length();
return temp==0?s1.compareTo(s2):temp;
}
}
Collections.max(list); //返回list中字典顺序最大的元素。
int index = Collections.binarySearch(list,"zz");//二分查找,返回角标。
Collections.reverseOrder();//逆向反转排序。
Collections.shuffle(list);//随机对list中的元素进行位置的置换。
将非同步集合转成同步集合的方法:Collections中的 XXX synchronizedXXX(XXX);
List synchronizedList(list);
Map synchronizedMap(map);
原理:定义一个类,将集合所有的方法加同一把锁后返回。
1.5.7,Collection 和 Collections的区别:
Collections是个java.util下的类,是针对集合类的一个工具类,提供一系列静态方法,实现对集合的查找、排序、替换、线程安全化(将非同步的集合转换成同步的)等操作。
Collection是个java.util下的接口,它是各种集合结构的父接口,继承于它的接口主要有Set和List,提供了关于集合的一些操作,如插入、删除、判断一个元素是否其成员、遍历等。
-------------------------------------------------------
Arrays:
用于操作数组对象的工具类,里面都是静态方法。
asList方法:将数组转换成list集合。
String[] arr = {"abc","kk","qq"};
List<String> list = Arrays.asList(arr);//将arr数组转成list集合。
将数组转换成集合,有什么好处呢?用aslist方法,将数组变成集合;
可以通过list集合中的方法来操作数组中的元素:isEmpty()、contains、indexOf、set;
注意(局限性):数组是固定长度,不可以使用集合对象增加或者删除等,会改变数组长度的功能方法。比如add、remove、clear。(会报不支持操作异常UnsupportedOperationException);
如果数组中存储的引用数据类型,直接作为集合的元素可以直接用集合方法操作。
如果数组中存储的是基本数据类型,asList会将数组实体作为集合元素存在。
集合变数组:用的是Collection接口中的方法:toArray();
如果给toArray传递的指定类型的数据长度小于了集合的size,那么toArray方法,会自定再创建一个该类型的数据,长度为集合的size。
如果传递的指定的类型的数组的长度大于了集合的size,那么toArray方法,就不会创建新数组,直接使用该数组即可,并将集合中的元素存储到数组中,其他为存储元素的位置默认值null。
所以,在传递指定类型数组时,最好的方式就是指定的长度和size相等的数组。
将集合变成数组后有什么好处?
限定了对集合中的元素进行增删操作,只要获取这些元素即可。
java集合(List,Set,Map)详细总结的更多相关文章
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 10 Hashtable详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 15 Map总结
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 08 Map架构
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 06 Stack详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 05 Vector详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 04 LinkedList详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java集合框架总结—超详细-适合面试
Java集合框架总结—超详细-适合面试 一.精简: A.概念汇总 1.Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口, ...
随机推荐
- string类的总结
一.string类头文件:#include <string>;using namespace std; 二.string类方法: 1.获取string的字符串长度:size(),size返 ...
- SqlServer获取当前日期
1. 获取当前日期 select GETDATE() 格式化: ) ---- :: 2. 获取当前年 --2017 3.获取当前月 --05或5 4.获取当前日期 --07或7 select DAY ...
- IDEA 使用LiveEdit插件
第一步: 第二步: 第三步: 第四步: 等待下载完成 第五步: 第六步: 第七步: 配置tomcat时注意选择chrome浏览器,并勾选右边的多选框 完成之后,就可以启动项目了,然后可以改变html代 ...
- 【三】材质反射属性模型BRDF
双向反射分布函数(BRDF:Bidirecitonal Reflectance Distribution Function) 用来描述物体表面对光的反射性质 预备知识 BRDF的定义和性质 BRDF模 ...
- Error from server (NotFound): the server could not find the requested resource (get services http:heapster:)
kubectl top pod --all-namespaces Error from server (NotFound): the server could not find the request ...
- jquery unload方法 语法
jquery unload方法 语法 作用:当用户离开页面时,会发生 unload 事件.具体来说,当发生以下情况时,会发出 unload 事件:点击某个离开页面的链接在地址栏中键入了新的 URL使用 ...
- 51 Nod 1636 教育改革(dp)
1636 教育改革 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 20 难度:3级算法题 收藏 关注 最近A学校正在实施教育改革. 一个学年由n天 ...
- FZU - 2103 Bin & Jing in wonderland
FZU - 2103 Bin & Jing in wonderland 题目大意:有n个礼物,每次得到第i个礼物的概率是p[i],一个人一共得到了k个礼物,然后按编号排序后挑选出r个编号最大的 ...
- delphi将一个list中包含的元素,从另一个中删除,如果在另一个中存在的话
Function StrList_Del(StrList,DelStrList:String):String; //将DelStrList中包含的元素,从Strlist中删除,如果在Strlist中存 ...
- numpy中np.max() 和 np.maximum() 的区别
np.max(a, axis=None, out=None, keepdims=False) # 接收一个参数a # 取a 在 axis方向上的最大值 np.maximum(x, y) # 接收两个参 ...