深入理解hadoop之HDFS
深入理解hadoop之HDFS
刚刚才写完关于mapreduce的一篇博文,趁热打铁接下来聊聊HDFS。本博文参考资料为HADOOP权威指南第3版完版,博文如有错漏之处,敬请指正。
HDFS即Hadoop Distributed FileSystem,是hadoop旗舰机的文件系统。HDFS以流式数据访问模式来存储超大文件。有如下几个特点:超大文件;流式数据访问模式,即一次写入多次读取的访问模式;商用硬件,hadoop不需要运行在昂贵的商用硬件上面,对于庞大的集群来说,节点的故障概率是非常高的,而HDFS是为了让系统继续运行而不让用户感受到明显的中断;HDFS不适合地数据延迟的应用;不适宜大量的小文件;不支持多用户写入,任意修改文件的 操作。
一、HDFS的一些概念
1.block(块):文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,之前的版本中是64M。分块的好处有二:1.文件的大小可以大于网络中任意一个磁盘的容量;2.使用抽象块而非整个文件作为存储单元。
2.名称节点namenode,管理文件系统的命名空间,维护整个系统树以及整个系统树内的文件目录,这些信息就以镜像文件和编辑日志的形式存储在本地磁盘上。
3.数据节点DataNode,存储并检索数据块,定期向namenode发送它们存储的块的列表
4.DistributedFileSystem
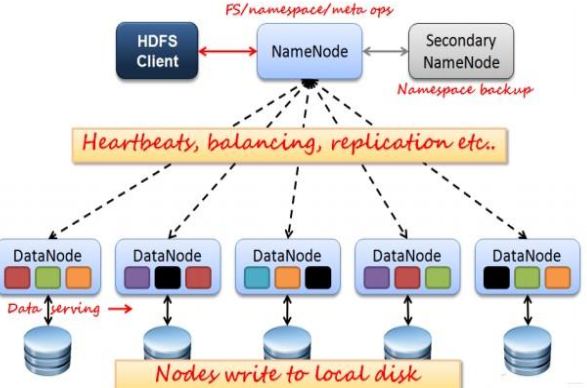
如上图所示, HDFS 也是按照 Master 和 Slave 的结构。分NameNode、 SecondaryNameNode、 DataNode 这几个角色。NameNode:是 Master 节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理 HDFS 的名称空间;SecondaryNameNode:是一个小弟,分担大哥 namenode的一部分工作量;是 NameNode 的冷备份;合并 fsimage 和fsedits 然后再发给 namenode。DataNode: Slave 节点,奴隶,干活的。负责存储 client 发来的数据块 block;执行数据块的读写操作。热备份: b 是 a 的热备份,如果 a 坏掉。那么 b 马上运行代替a 的工作。冷备份: b 是 a 的冷备份,如果 a 坏掉。那么 b 不能马上代替a 工作。但是 b 上存储 a 的一些信息,减少 a 坏掉之后的损失。fsimage:元数据镜像文件(文件系统的目录树。)edits:元数据的操作日志(针对文件系统做的修改操作记录)namenode 内存中存储的是=fsimage+edits。SecondaryNameNode 负责定时默认 1 小时,从namenode 上,获取 fsimage 和 edits 来进行合并,然后再发送给 namenode。减少 namenode 的工作量。
二、java API接口访问
在进行剖析HDFS文件系统读写之前,我们先来看看java API来访问hdfs的实例(hadoop2.x版本)。
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test; /**
* 完成hdfs操作
*/
public class TestHDFS {
/**
* 读取hdfs文件
*/
@Test
public void readFile() throws Exception{
//注册url流处理器工厂(hdfs)
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
URL url = new URL("hdfs://192.168.231.201:8020/user/centos/hadoop/index.html");
URLConnection conn = url.openConnection();
InputStream is = conn.getInputStream();
byte[] buf = new byte[is.available()];
is.read(buf);
is.close();
String str = new String(buf);
System.out.println(str);
} /**
* 通过hadoop API访问文件
*/
@Test
public void readFileByAPI() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.231.201:8020/");
FileSystem fs = FileSystem.get(conf) ;
Path p = new Path("/user/centos/hadoop/index.html");
FSDataInputStream fis = fs.open(p);
byte[] buf = new byte[];
int len = - ; ByteArrayOutputStream baos = new ByteArrayOutputStream();
while((len = fis.read(buf)) != -){
baos.write(buf, , len);
}
fis.close();
baos.close();
System.out.println(new String(baos.toByteArray()));
} /**
* 通过hadoop API访问文件
*/
@Test
public void readFileByAPI2() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.231.201:8020/");
FileSystem fs = FileSystem.get(conf) ;
ByteArrayOutputStream baos = new ByteArrayOutputStream();
Path p = new Path("/user/centos/hadoop/index.html");
FSDataInputStream fis = fs.open(p);
IOUtils.copyBytes(fis, baos, );
System.out.println(new String(baos.toByteArray()));
} /**
* mkdir
*/
@Test
public void mkdir() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.231.201:8020/");
FileSystem fs = FileSystem.get(conf) ;
fs.mkdirs(new Path("/user/centos/myhadoop"));
} /**
* putFile
*/
@Test
public void putFile() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.231.201:8020/");
FileSystem fs = FileSystem.get(conf) ;
FSDataOutputStream out = fs.create(new Path("/user/centos/myhadoop/a.txt"));
out.write("helloworld".getBytes());
out.close();
} /**
* removeFile
*/
@Test
public void removeFile() throws Exception{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.231.201:8020/");
FileSystem fs = FileSystem.get(conf) ;
Path p = new Path("/user/centos/myhadoop");
fs.delete(p, true);
}
}
三、HDFS剖析文件读取
1.客户端首先通过FileSystem客户端的Open()方法来打开要进行读取的文件,然后DistributedFileSystem通过使用RPC来调用namenode以确定文件起始块的位置对于每一个块,namenode存有该块副本的datanode 的地址,DistributedFileSystem类返回一个FSDataInputStream对象给client并进行数据的读取,接下来客户端通过输入流来对这些数据节点来反复调用read()方法,第一个block读取完毕之后,寻找下一个block的最佳datanode,来读取数据,最后数据读取完毕关流,这些DataNode根据与客户端的距离来进行排序。具体过程如下图1:

(图1客户端读取HDFS数据)
2.在读数据过程中,如果与Datanode的通信发生错误,DFSInputStream对象会尝试从下一个最佳节点读取数据,并且记住该失败节点, 后续Block的读取不会再连接该节点 读取一个Block之后,DFSInputStram会进行检验和验证,如果Block损坏,尝试从其他节点读取数据,并且将损坏的block汇报给Namenode。 客户端连接哪个datanode获取数据,是由namenode来指导的,这样可以支持大量并发的客户端请求,namenode尽可能将流量均匀分布到整个集群。Block的位置信息是存储在namenode的内存中,因此相应位置请求非常高效,不会成为瓶颈。
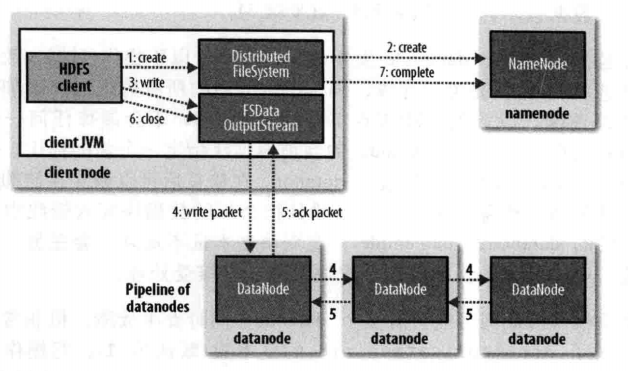
四、HDFS剖析文件写入
1.对于文件写入的过程,我们要了解的是创建文件,写入文件,最后关闭文件。
2.客户端通过DistributedFileSystem来调用create函数来创建新的文件;namenode来检查该文件是否存在以及是否有权限来创建该文件,检查通过就会创建文件,否则就会抛出异常,DisTributedFileSystem向客户端返回一个FSDataOutputStream对象,由此客户端就可以开始写入数据;客户端写入数据时DFSOutputStream将数据分为一个个的数据包,并将其写入数据队列,DataStreamer处理数据队列,根据DataNode列表的要求namenode来分配合适的新块来存储数据副本,这些节点存放同一个Block的副本,构成一个管道。 DataStreamer将packet写入到管道的第一个节点,第一个节点存放好packet之后,转发给下一个节点,下一个节点存放 之后继续往下传递。DFSOutputStream同时维护一个ack queue队列,等待来自datanode确认消息。当管道上的所有datanode都确认之后,packet从ack队列中移除;数据写入完毕,客户端close输出流。
暂时写这么多吧,写累了,休息下。
深入理解hadoop之HDFS的更多相关文章
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
- Hadoop基础-HDFS的读取与写入过程
Hadoop基础-HDFS的读取与写入过程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了了解客户端及与之交互的HDFS,NameNode和DataNode之间的数据流是什么样 ...
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
- 介绍hadoop中的hadoop和hdfs命令
有些hive安装文档提到了hdfs dfs -mkdir ,也就是说hdfs也是可以用的,但在2.8.0中已经不那么处理了,之所以还可以使用,是为了向下兼容. 本文简要介绍一下有关的命令,以便对had ...
- 深入理解hadoop之机架感知
深入理解hadoop之机架感知 机架感知 hadoop的replication为3,机架感知的策略为: 第一个block副本放在和client所在的datanode里(如果client不在集群范围内, ...
- Hadoop 基石HDFS 一文了解文件存储系统
@ 目录 前言:浅谈Hadoop Hadoop的发展历程 1.1 Hadoop产生背景 1.引入HDFS设计 1.1 HDFS主要特性 2.HDFS体系结构 HDFS工作流程机制 1.各个节点是如何互 ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
随机推荐
- pytorch-Alexnet 网络
Alexnet网络结构, 相比于LeNet,Alexnet加入了激活层Relu, 以及dropout层 第一层网络结构: 11x11x3x96, 步长为4, padding=2 第二层网络结构: 5x ...
- RoP
RoPS特征提取 RoPS为Rotational Projection Statistics的简写,即旋转投影统计特征.RoPS特征具有对点云旋转和平移(即姿态变化)的不变性,具备很强的鉴别力以及对噪 ...
- 前端知识点回顾——Javascript篇(三)
数组的冒泡.选择和插入排序法 冒泡排序法(从小到大) function bubble(arr){ for(let i = 0 ;i<arr.length-1;i++){ for(let j = ...
- NetUtils网络连接工具类
import android.app.Activity; import android.content.ComponentName; import android.content.Context; i ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_5-08 断路器监控仪表参数
笔记 8.断路器监控仪表参数讲解和模拟熔断 简介:讲解 断路器监控仪表盘参数和模拟熔断 1.sse server-send-event推送到前端 资料:https://github.com/ ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_5-06 高级篇幅之深入源码
笔记 6.高级篇幅之深入源码剖析Hystrix降级策略和调整 简介:源码分析Hystrix降级策略和调整 1.查看默认讲解策略 HystrixCommandProperties ...
- MATLAB学习(三)元素访问和常用代数运算
>> A=[1,2;3,4],B=[0,2;4,5] A = 1 2 3 4 B = 0 2 4 5 >> C=A>=B C = 1 1 0 0 >> D=A ...
- mySQL的简单安装和配置
MySQL的安装和配置 1.去官网下载mysql-5.6.29-winx64.zip包.地址: http://dev.mysql.com/downloads/mysql/5.6.html 2,把安装包 ...
- Chrome浏览器界面截图
常常出现这么一个场景: 网页比较长,需要滚动屏幕才能看完整.这时候如需截屏,则比较麻烦. 如下为解决方法: 推荐Chrome浏览器: 按F12打开调试页面,同时按下ctrl + shift + p, ...
- Git安装以及配置SSH Key——Windows
安装 安装 Git 官网下载一个Windows版本的Git. 然后一直下一步即可,如下图 环境变量自动配好的,可以去检查一下环境变量中PATH中有没有Git的环境变量 然后在桌面右击鼠标,选择Git ...